如何在实际应用中平衡YOLOv12的算力需求和检测精度?
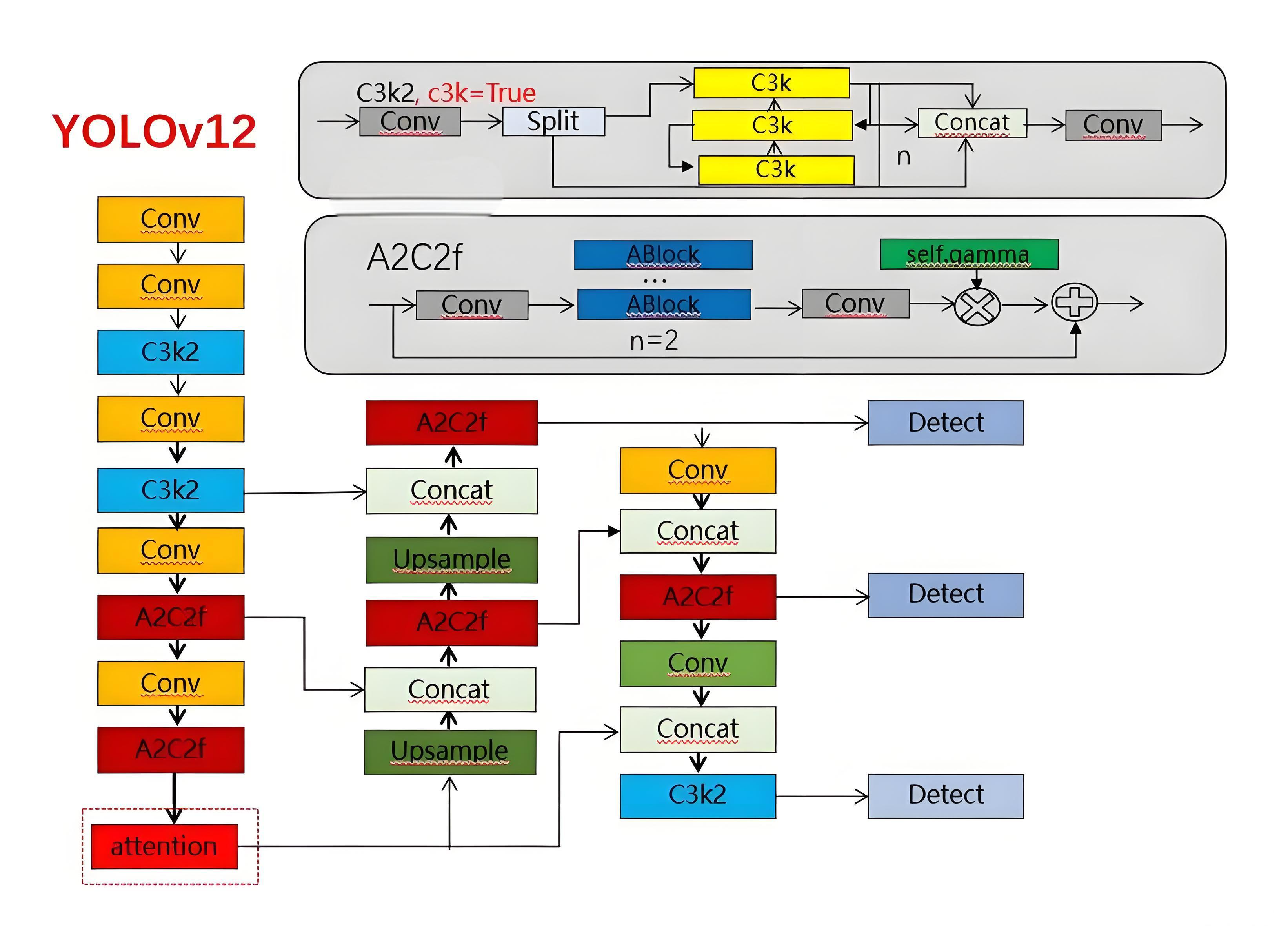
YOLO 的最新架构为 YOLOv12,其对算力的要求因模型版本、输入分辨率、硬件平台、推理精度等因素而有所不同。
输入分辨率越高,YOLOv12 的算力需求也越高。推理精度方面,采用 FP16、INT8 等低精度量化技术,可以在牺牲少量精度的前提下,大幅降低算力需求。硬件平台的计算能力也至关重要,GPU、NPU 等专用硬件相比 CPU 能更高效地运行 YOLOv12,提供更高的算力支持。
YOLOv12 包括 N、S、M、L、X 等多个版本,不同版本的算力需求存在差异。其中,YOLOv12-N 仅消耗 6.5G FLOPs 和 2.6M 参数,非常适用于对计算资源苛刻、但对检测精度要求相对有限的实时场景。YOLOv12-S 规模略大,为 21.4G FLOPs、9.3M 参数,在速度和精度之间达成了良好平衡。YOLOv12-M 的计算量为 67.5G FLOPs,参数为 20.2M,可在高精度与合理速度间取得良好兼顾。YOLOv12-L 与 YOLOv12-X 的 mAP 分别可达 53.7 和 55.2,计算量和推理延迟相应更高,适合对准确度要求极高的场景。
在实际应用中平衡 YOLOv12 的算力需求和检测精度,需要结合具体场景的硬件限制、精度要求、实时性需求等因素,通过模型选型、技术优化、策略调整等多维度手段实现。以下是具体方法:
1. 根据场景需求选择合适的模型版本
YOLOv12 设计了 N/S/M/L/X 等不同规模的模型,本身就是为了适配不同算力场景:
- 低算力场景(如边缘设备、嵌入式系统):选择轻量级版本(YOLOv12-N/S)。例如,YOLOv12-N 仅需 6.5G FLOPs,适合 CPU 或低端 NPU,可满足实时性要求(如移动端摄像头实时检测),但需接受对小目标或复杂场景的检测精度略低。
- 中等算力场景(如中端 GPU、边缘服务器):选择 YOLOv12-M,其 67.5G FLOPs 在精度(mAP 约 50+)和速度间取得平衡,适合工厂质检、无人机巡检等需要中等精度的场景。
- 高精度优先场景(如服务器、云端):选择 YOLOv12-L/X,尽管算力需求高达数百 G FLOPs,但能提供 53.7 + 的 mAP,适合对漏检、误检敏感的场景(如安防监控中的危险目标识别)。
- 初步实施可使用线上云服务器:如“智算云扉https://waas.aigate.cc/productService、算吧 https://www.suanba.cc/index”等租赁平台,支持按量计费。
2. 动态调整输入分辨率
YOLO 的算力需求与输入分辨率的平方成正比(如从 640×640 降至 480×480,算力需求可减少约 43%),但分辨率降低会影响小目标检测精度。实际应用中可:
- 根据目标大小调整:若检测目标以大目标为主(如交通监控中的车辆),可降低分辨率(如 480×480);若需检测小目标(如工业质检中的微小瑕疵),则需保持较高分辨率(如 640×640 或更大)。
- 动态分辨率策略:在推理时根据场景实时切换分辨率。例如,监控画面中无目标时用低分辨率(节省算力),检测到目标后自动提升分辨率(保证精度)。
3. 模型量化与压缩
通过轻量化技术在牺牲少量精度的前提下,大幅降低算力需求:
- 低精度量化:将 FP32 精度模型转为 FP16(半精度)或 INT8(整数精度),可减少 50%-75% 的内存占用和算力需求。YOLOv12 对量化兼容性较好,INT8 量化后精度通常仅下降 1-2 个 mAP,适合边缘设备(如 NVIDIA Jetson、华为昇腾 NPU)。
- 模型剪枝与蒸馏:剪枝移除冗余卷积核(如剪掉 30% 非关键权重),或用大模型(如 YOLOv12-X)蒸馏小模型(如 YOLOv12-S),在保持高精度的同时降低计算量。例如,剪枝后的 YOLOv12-S 算力可再降 20%,精度仅损失 0.5 mAP。
4. 硬件适配与加速
不同硬件的算力效率差异显著,选择适配的硬件可在相同精度下降低算力消耗:
- 专用芯片加速:优先使用 GPU(如 NVIDIA RTX 系列)、NPU(如手机端骁龙 NPU、边缘端地平线 J5)或 TPU,其对 YOLOv12 的卷积、池化等操作有专门优化,算力利用率比 CPU 高 10-100 倍。例如,YOLOv12-S 在 NVIDIA Jetson Nano(23 TOPS 算力)上可跑 30+ FPS,而在同功耗 CPU 上仅能跑 5 FPS。
- 推理引擎优化:使用 TensorRT(NVIDIA)、OpenVINO(Intel)等推理引擎,通过层融合、内存优化等技术加速 YOLOv12 推理,在不损失精度的情况下提升 2-5 倍速度(间接降低单位时间算力需求)。
5. 场景化后处理与任务简化
- 简化后处理:调整非极大值抑制(NMS)阈值(如从 0.5 调至 0.6),减少冗余计算;或移除对场景无关的类别(如检测交通目标时,删除 “动物” 类别),降低分类分支的算力消耗。
- 任务拆分:若场景允许,将复杂检测任务拆分为 “粗检测 + 细分类”。例如,先用 YOLOv12-N 快速定位目标区域,再对区域用轻量分类器细化识别,整体算力比直接用 YOLOv12-L 低 50% 以上。
6. 数据与训练策略优化
通过提升模型 “效率” 间接平衡算力与精度:
- 针对性数据增强:在训练时增加小目标、模糊目标的数据增强(如 Mosaic、MixUp),让轻量模型(如 YOLOv12-S)在低分辨率下也能保持对关键目标的检测能力。
- 迁移学习:基于预训练权重,用场景特定数据微调,可让小模型在特定场景下达到接近大模型的精度(如在工厂零件检测中,YOLOv12-S 微调后精度可能接近 YOLOv12-M 的原生水平)。

总结
平衡的核心逻辑是:“在满足场景核心需求的前提下,最小化算力消耗”。例如,实时性优先的场景(如自动驾驶)可牺牲 5% 精度换取 3 倍速度;精度优先的场景(如医疗影像检测)可接受更高算力和延迟。通过组合上述方法(如 “YOLOv12-S + INT8 量化 + 动态分辨率 + Jetson NPU”),可在大多数场景下实现算力与精度的最优平衡。