数据库的回表
目录
- 一、先明确:两种基础索引的区别
- 二、什么是回表?—— 用例子讲清楚
- 例子:以 MySQL InnoDB 表为例
- 场景1:不需要回表(覆盖索引)
- 场景2:需要回表(非覆盖索引)
- 三、回表的影响:性能损耗
- 四、如何避免回表?—— 覆盖索引优化
- 优化示例(基于上面的 `user` 表)
- 总结
- **思考:**
- 聚簇索引和覆盖索引的区别?
在数据库(尤其是 MySQL 等使用 B+ 树索引的数据库)中, 回表是一个与索引查询相关的核心概念,本质是“通过索引找到主键后,再去主键索引(聚簇索引)中查询完整数据行”的过程。要理解回表,需要先明确数据库中两种关键索引的结构差异,再结合查询场景分析。
一、先明确:两种基础索引的区别
回表的根源是 非主键索引(二级索引) 与 主键索引(聚簇索引) 存储的内容不同,这是理解回表的前提:
| 索引类型 | 核心作用 | 存储内容(以 InnoDB 为例) | 索引结构 |
|---|---|---|---|
| 主键索引 | 定位完整数据行 | 主键值 + 该行的所有字段数据(即“聚簇”了完整数据) | B+ 树(叶子节点是数据行) |
| 非主键索引 | 按非主键字段快速筛选 | 非主键字段值 + 对应的主键值(不存储完整数据) | B+ 树(叶子节点是主键) |
简单说:非主键索引只“记录了找到完整数据的‘钥匙’(主键)”,而完整数据只存在主键索引里。
二、什么是回表?—— 用例子讲清楚
当我们通过 非主键索引 查询数据时,如果查询的字段超出了非主键索引本身存储的内容(即需要“完整数据”或“非索引字段”),就必须通过索引叶子节点中的“主键”,再去主键索引中查询一次,这个“二次查询”的过程就是回表。
例子:以 MySQL InnoDB 表为例
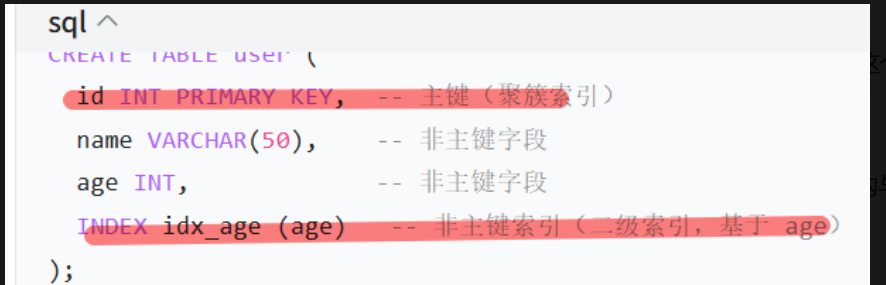
假设有一张 user 表,结构如下:
CREATE TABLE user (id INT PRIMARY KEY, -- 主键(聚簇索引)name VARCHAR(50), -- 非主键字段age INT, -- 非主键字段INDEX idx_age (age) -- 非主键索引(二级索引,基于 age)
);
插入几条数据:
| id | name | age |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 25 |
| 3 | 王五 | 20 |
场景1:不需要回表(覆盖索引)
如果查询的字段完全在非主键索引中(即“索引覆盖了查询需求”),就不需要回表:
-- 查询 age=20 的用户的 id 和 age(这两个字段都在 idx_age 索引中)
SELECT id, age FROM user WHERE age = 20;
执行过程:
- 遍历
idx_age索引(B+ 树),找到所有age=20的叶子节点; - 叶子节点中直接存储了
age和id,直接返回结果,无需再查其他索引。
场景2:需要回表(非覆盖索引)
如果查询的字段超出了非主键索引的范围(比如需要 name 字段,而 idx_age 中没有存储 name),就必须回表:
-- 查询 age=20 的用户的 id、name、age(name 不在 idx_age 索引中)
SELECT id, name, age FROM user WHERE age = 20;
执行过程:
- 遍历
idx_age索引,找到所有age=20的叶子节点,获取对应的主键id=1和id=3(这一步是“索引查询”); - 拿着这两个
id,分别去主键索引(聚簇索引)中查询对应的完整数据行(获取name等字段)(这一步就是“回表”); - 将两次查询的结果整合,返回最终数据。
三、回表的影响:性能损耗
回表本质是“两次 B+ 树查询”(先查非主键索引,再查主键索引),相比“一次查询”(比如直接用主键查询,或覆盖索引查询),会带来额外的性能损耗:
- 更多的磁盘 I/O(B+ 树查询需要读取磁盘页,两次查询意味着 twice I/O);
- 更高的查询延迟(尤其当非主键索引筛选出的结果集很大时,回表次数会成比例增加,性能损耗会急剧上升)。
四、如何避免回表?—— 覆盖索引优化
既然回表会损耗性能,优化思路就是让查询尽可能命中“覆盖索引”(即查询的字段都在非主键索引中),从而避免二次查询。
优化示例(基于上面的 user 表)
如果业务中经常需要“按 age 查询 name 和 id”,可以将 idx_age 升级为 联合索引,把 name 也包含进去:
-- 删除原单字段索引,创建 (age, name) 联合索引
DROP INDEX idx_age ON user;
CREATE INDEX idx_age_name ON user (age, name);
此时再执行查询:
SELECT id, name, age FROM user WHERE age = 20;
- 联合索引
idx_age_name的叶子节点存储了age、name和id(主键会自动包含在非主键索引中); - 查询的所有字段(
id、name、age)都在索引中,直接返回结果,无需回表,性能大幅提升。
总结
- 回表的本质:通过非主键索引找到主键后,再去主键索引查询完整数据的“二次查询”过程;
- 触发条件:查询字段超出非主键索引的存储范围(非覆盖索引查询);
- 核心影响:增加磁盘 I/O,降低查询性能;
- 优化方案:设计合理的覆盖索引(如联合索引),让查询字段都包含在索引中,避免回表。
注意:
这个主键索引为啥也叫聚簇索引?
在 MySQL 的 InnoDB 存储引擎中,主键索引也叫聚簇索引,这是因为其索引结构与数据行的存储紧密结合,数据按照主键的顺序进行物理存储,具有以下特点和原因:
索引结构与数据存储的关系
数据与索引一体化:InnoDB 存储引擎中,聚簇索引的 B + 树叶子节点上不仅存储了主键值,还存放了与该行记录相关的全部数据,也就是说,数据行和主键索引的叶子节点是紧密结合在一起的。相比之下,非聚簇索引(如上述例子中的idx_age索引)的叶子节点只存储了索引列的值以及对应的主键值(表 user 定义了 id 作为主键,那么 idx_age 索引叶子节点中存储的 “主键值”,指的就是每一行记录对应的 id 字段的值 。),不包含完整的数据行。
物理存储顺序:InnoDB 表中的数据是按照主键的顺序进行物理存储的。当表有主键时,InnoDB 会按照主键的顺序组织数据,将数据页按照主键值的大小顺序排列,这使得根据主键进行查询时,能够快速定位到数据页,提高查询效率。如果没有显式定义主键,InnoDB 会选择一个唯一的非空索引列作为聚簇索引,如果没有这样的列,它会自动生成一个隐藏的主键列来创建聚簇索引。
聚簇索引带来的优势
快速访问数据:对于基于主键的查询,通过聚簇索引可以直接获取到数据行,因为数据和主键索引紧密关联,减少了磁盘 I/O 操作。例如,执行SELECT * FROM user WHERE id = 5;,InnoDB 可以通过主键索引快速定位到对应的叶子节点,直接获取到整行数据。
范围查询高效:由于数据按照主键顺序存储,在进行范围查询(如SELECT * FROM user WHERE id BETWEEN 1 AND 10;)时,InnoDB 可以通过扫描连续的数据页,快速获取到满足条件的数据行,不需要进行额外的排序操作。
与非聚簇索引(二级索引)的对比
非聚簇索引查询过程: 当使用非聚簇索引(如上述idx_age索引)进行查询时,首先通过非聚簇索引的 B + 树找到对应的主键值,然后再利用主键值去聚簇索引中查找完整的数据行,这个过程就是回表操作。这意味着非聚簇索引的查询通常需要额外的 I/O 操作。
**聚簇索引的直接性:**而聚簇索引不需要这样的额外步骤,在查询包含主键列的结果集时,能够更高效地返回数据,因为数据和主键索引是 “聚簇” 在一起的。
总结来说,在 InnoDB 存储引擎里,主键索引被称为聚簇索引,是因为它将数据存储和索引结构融合在一起,数据按主键顺序排列,能有效提升基于主键查询和范围查询的效率,同时也和非聚簇索引的结构与查询过程形成了鲜明对比。
思考:
发生回表的几种情况?

如何避免回表?

聚簇索引和覆盖索引的区别?
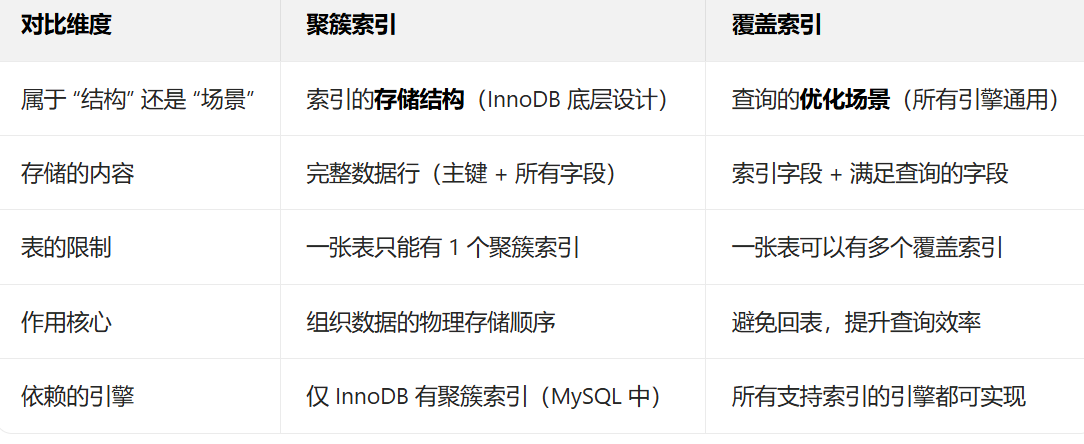
聚簇索引是 “InnoDB 中数据和主键索引绑定的存储方式”;
覆盖索引是 “查询字段被索引完全包含,不用回表的优化场景”。