SpringTask和XXL-job概述
在企业级应用中,定时任务用途广泛:报表/统计、缓存刷新、定期数据清理、批处理、消息重发、定时邮件/通知等。选择合适的调度技术会直接影响系统的可靠性、可维护性与运维成本。
-
当任务数量少、执行逻辑简单且只需单机运行时,使用 Spring Task 足矣;
-
当需要统一管理、分布式调度、任务分片、运行监控、失败重试、权限控制或运维人员可视化管理时,建议使用 XXL-Job 或类似分布式调度平台。
本文对比并介绍两种常见的定时/调度方案——Spring Task(Spring 自带的调度)与XXL-Job(开源分布式调度平台)。从概念、架构、实现、优缺点、典型配置、选型建议、最佳实践与常见坑等多角度进行详尽梳理,便于在实际项目中快速决策与落地。
一、Spring Task 概述
1.1 概念(底层实现原理)
Spring Task 是 Spring 框架提供的一套轻量级定时任务调度工具,主要基于:
-
JDK 的
ScheduledExecutorService(线程池调度器); -
Spring 的任务抽象(TaskScheduler、TaskExecutor 等)。
它的主要作用是:在 Spring 容器中,通过注解 @Scheduled 或 XML 配置来声明周期性任务,Spring Task 负责扫描、注册并调度这些任务。
简单来说,在方法上添加@Scheduled 注解,Spring会自动将这些方法注册到调度器中(本质是ScheduleExecutorService 或 Quartz 等实现),再由调度器按照 cron 间隔去触发执行。
底层实现原理:
(1)注解解析
-
Spring 在容器启动时,会通过
ScheduledAnnotationBeanPostProcessor这个后置处理器,扫描所有带@Scheduled注解的方法。 -
对于这些方法,Spring 会封装成 Runnable + Trigger,注册到任务调度器中。
(2)任务调度器
-
Spring 提供了
TaskScheduler接口,默认实现是ThreadPoolTaskScheduler; -
ThreadPoolTaskScheduler底层使用了 JDK 的ScheduledThreadPoolExecutor来执行任务,可通过配置Bean自定义线程池大小; -
默认是单线程执行,可以配置线程池大小调度多个任务,避免单线程阻塞。
@Configuration
@EnableScheduling
public class SchedulingConfig {@Beanpublic ThreadPoolTaskScheduler taskScheduler() {ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();scheduler.setPoolSize(10); // 设置线程池大小scheduler.setThreadNamePrefix("scheduled-task-");scheduler.setAwaitTerminationSeconds(60);scheduler.setWaitForTasksToCompleteOnShutdown(true);return scheduler;}
}
(3)Trigger 触发器
Spring Task 内部把调度逻辑抽象为 Trigger:
-
如果你用
@Scheduled(cron = "..."),Spring 会用CronTrigger来计算下一次触发时间; -
如果用
fixedRate或fixedDelay,Spring 会用PeriodicTrigger来实现。
Trigger 的作用就是:根据上次执行时间,计算下次应该什么时候触发。
(4)任务执行
-
调度器(
ScheduledThreadPoolExecutor)会不断检查 Trigger,判断是否该触发任务; -
一旦到达时间点,调度器就会提交 Runnable 到线程池中执行;
-
如果任务抛出异常,Spring 默认只是记录日志,不会重试(需要自行实现重试逻辑)。
1.2 核心特性
-
轻量级、零依赖
-
内置于 Spring 框架中,不需要引入额外组件或中间件。
-
只需在配置类上启用
@EnableScheduling,即可快速使用。
-
-
基于注解的声明式任务
使用@Scheduled注解即可定义定时任务,支持多种调度方式:-
fixedDelay(上一次执行结束后,间隔固定时间再次执行)。
-
fixedRate(上一次开始执行后,间隔固定时间再次执行);
-
Cron 表达式(精确到秒,灵活度高);
-
-
线程池支持
-
默认情况下所有任务运行在单线程中(可能出现任务阻塞)。
-
可通过配置
ThreadPoolTaskScheduler来支持并发执行,避免任务之间互相阻塞。
-
-
与 Spring 生态无缝集成
-
能与 Spring Bean、事务管理、Spring Data、Spring Boot 配置等无缝结合。
-
可以直接在 Service、Component 中编写定时任务方法。
-
-
支持异步执行
-
搭配
@Async注解,可以让任务在独立线程池中异步执行,提高并发能力。
-
-
简单易用
-
API 简洁,配置方式少;
-
适合快速开发小型定时任务,不需要学习额外的调度框架。
-
-
灵活配置
-
Cron 表达式支持灵活的时间调度策略;
-
可以结合 Spring Profile、配置文件动态开启或关闭任务。
-
1.3 常用注解和配置
1. 开启调度功能
在 Spring Boot / Spring 项目中,要启用定时任务功能,需要在配置类上添加:
@EnableScheduling
作用:开启 Spring 的调度能力,使 @Scheduled 注解生效。
2. 常用注解
2.1 @Scheduled
定义定时任务的核心注解,常见用法有三类:
(1)cron 表达式(最常用)
@Scheduled(cron = "0 0 1 * * ?")
public void task() {
// 每天凌晨 1 点执行
}
直接在浏览器搜索“cron 表达式在线生成工具”,一大堆在线生成工具可供使用
比如:https://cron.qqe2.com/
(2)fixedRate(上次开始执行时间到下次开始时间的间隔)
@Scheduled(fixedRate = 5000)
public void task() {
// 每隔 5 秒触发一次(不管上一次是否完成)
}
(3)fixedDelay(上次结束执行时间到下次开始时间的间隔)
@Scheduled(fixedDelay = 5000)
public void task() {
// 上次执行结束 5 秒后再执行下一次
}
(4)initialDelay(首次延迟执行时间)
@Scheduled(initialDelay = 10000, fixedDelay = 5000)
public void task() {
// 第一次延迟 10 秒后执行,之后每次间隔 5 秒
}
2.2 @Async
SpringTask 默认是 单线程 执行,如果任务耗时过长,会阻塞后续任务。
可以结合异步执行来提升并发能力:
@EnableAsync // 开启异步任务支持
@EnableScheduling
@Configuration
public class ScheduleConfig {
}
@Scheduled(fixedRate = 5000)
@Async
public void asyncTask() {
// 在独立线程池中执行,不阻塞主线程
}
1.4 错误处理与重试
1.4.1 Spring Task 的默认行为
-
无内置重试机制:
当@Scheduled标注的方法抛出异常时,Spring Task 只会打印异常日志,不会自动重试。 -
不会阻塞下一次调度:
下次调度会按原计划执行(不论上一次是否失败)。 -
线程池影响:
如果使用单线程池,且任务执行耗时过长或抛出未捕获异常,可能会影响后续任务调度。
1.4.2 常见的错误处理方式
(1)方法内 try-catch
最简单的方式是自己捕获异常,并在业务逻辑里做有限重试:
@Scheduled(cron = "0 */5 * * * ?")
public void syncData() {try {callRemoteApi();} catch (Exception e) {log.error("任务失败,准备重试", e);for (int i = 0; i < 3; i++) {try {callRemoteApi();break; // 成功就跳出} catch (Exception ex) {log.error("第{}次重试失败", i + 1, ex);}}}
}
(2)使用 Spring Retry 框架
Spring 提供 spring-retry,可以在 @Scheduled 方法上添加 @Retryable 实现声明式重试:
@Scheduled(fixedRate = 5000)
@Retryable(value = Exception.class, maxAttempts = 3, backoff = @Backoff(delay = 2000)) // 每次间隔 2 秒
public void task() {log.info("执行任务...");throw new RuntimeException("异常");
}
配合 @EnableRetry 使用,失败时会自动重试。
(3)持久化失败任务(推荐)
对于关键业务,常见做法是:
-
记录失败任务到数据库(如写一条失败日志或任务表);
-
由另一个“补偿任务”定期扫描失败记录,重试执行;
-
或者直接将任务投递到消息队列(MQ),由消费者端做重试、死信队列、人工补偿。
1.5 场景实例
1.5.1 场景描述
在很多业务系统中,为了提高访问速度,会使用 缓存(如 Redis、Ehcache) 来存储热点数据。例如:
-
商品列表、商品详情缓存
-
用户权限信息缓存
-
配置参数缓存
缓存数据需要定期刷新,以保证数据的 时效性。如果数据更新频率不高,但查询量大,可以用 Spring Task 定时更新缓存。
示例场景:
-
系统每天凌晨 1 点刷新“商品分类列表缓存”,确保用户访问时拿到最新分类信息。
-
数据来源是数据库,刷新过程包括查询数据库、更新 Redis。
1.5.2 Spring Task 实现流程
-
配置线程池(避免任务阻塞影响其他任务)
-
开启调度功能
@EnableScheduling -
使用
@Scheduled定义任务,指定执行时间 -
在任务方法中查询数据库并更新缓存
1.5.3 示例代码(Redis 缓存更新)
// 配置线程池
@Configuration
@EnableScheduling
public class SchedulingConfig {@Beanpublic ThreadPoolTaskScheduler taskScheduler() {ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();scheduler.setPoolSize(5); // 同时可执行任务数量scheduler.setThreadNamePrefix("scheduled-task-");scheduler.setAwaitTerminationSeconds(60);scheduler.setWaitForTasksToCompleteOnShutdown(true);return scheduler;}
}// 业务任务类
@Component
public class CacheRefreshTask {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Autowiredprivate ProductService productService; // 查询商品数据的服务/*** 每天凌晨 1 点刷新商品分类缓存*/@Scheduled(cron = "0 0 1 * * ?")public void refreshProductCategoryCache() {System.out.println("开始刷新商品分类缓存: " + LocalDateTime.now());try {// 1. 查询数据库最新分类数据List<Category> categories = productService.getAllCategories();// 2. 更新 Redis 缓存redisTemplate.opsForValue().set("product:categories", categories);System.out.println("商品分类缓存刷新成功,数量:" + categories.size());} catch (Exception e) {// 错误日志System.err.println("刷新商品分类缓存失败: " + e.getMessage());}}
}
二、XXL-job 概述
2.1 介绍
首先,为啥会出现XXL-job,那肯定是SpringTask存在弊端或缺陷。主要原因是:SpringTask(基于 @Scheduled)是 本地任务调度器,所有定时任务都是由当前应用进程内的线程池来触发和执行的。当我们搭建服务集群或在多台机器上执行服务,SpringTask无法感知在哪台机器上执行,每个服务都有独立的Spring容器,导致SpringTask重复执行任务。
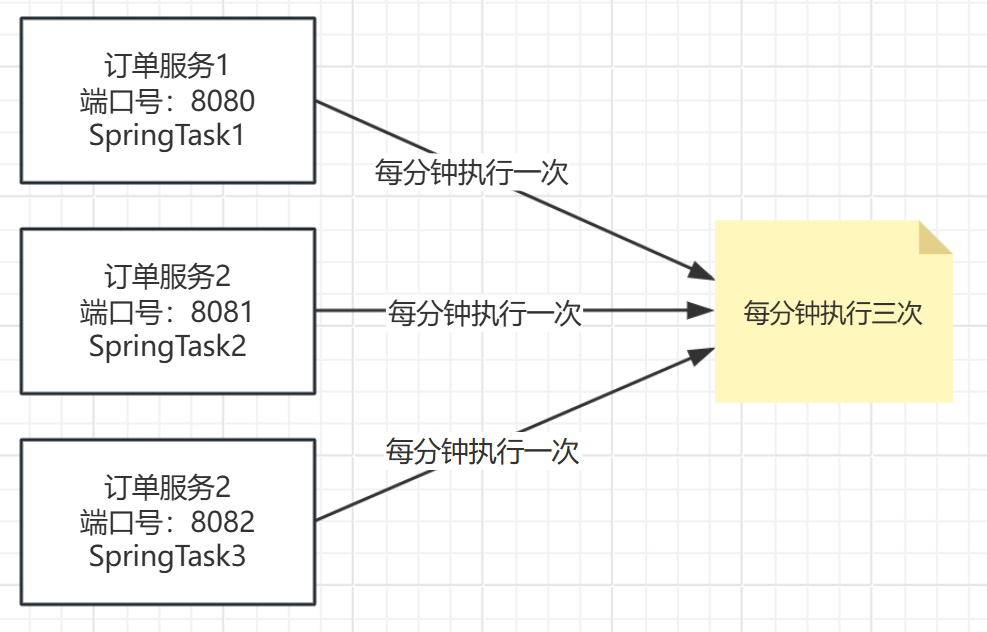
因此,XXL-job 闪亮登场!!!
XXL-Job 是一个开源的分布式任务调度平台,面向企业级应用设计,主要用于解决定时任务在分布式环境下的调度、管理和运维问题。它提供了一个统一的调度中心,使企业可以方便地管理不同系统、不同服务中的定时任务,实现任务的集中管理和统一调度。
特点与定位
-
面向企业级调度
XXL-Job 可以处理大量的定时任务和复杂任务逻辑,适合在微服务或分布式环境中使用,帮助企业实现统一的任务调度和运维管理。 -
分布式任务调度
与单机定时任务不同,XXL-Job 支持将任务分配到多个服务节点执行,并保证任务在分布式环境下不会重复执行。 -
可视化管理
提供控制台和管理界面,运维人员可以方便地查看任务状态、执行日志、历史记录以及进行任务操作(新增、修改、暂停、触发等)。 -
高可靠性与扩展性
XXL-Job 可以在多实例、多节点环境下安全运行,通过调度策略和任务分片机制支持大规模任务调度,满足高并发和高可用需求。 -
灵活应用场景
适用于报表生成、数据同步、批处理、缓存刷新、消息重发等多种业务场景,可以统一管理企业内部的定时任务。
2.2 核心架构和组件
XXL-Job 的架构主要由 调度中心(Admin)、执行器(Executor)、注册/心跳机制、数据库和控制台 构成,整体采用集中调度 + 分布式执行的模式。
2.2.1 调度中心(Admin)
-
作用:整个 XXL-Job 的“大脑”,负责任务的统一管理、调度、监控和日志收集。
-
功能:
-
任务注册与管理(新增、修改、删除、暂停、触发);
-
调度决策(决定哪个 Executor 执行任务);
-
日志和执行记录持久化;
-
提供控制台 UI 供运维人员操作。
-
-
部署方式:通常单独部署,可以做集群部署来保证高可用。
2.2.2 执行器(Executor)
-
作用:任务的实际执行者,运行在业务应用或独立服务中。
-
功能:
-
接收调度中心的任务指令;
-
执行具体的业务逻辑(Handler 方法);
-
上报执行状态和日志给调度中心。
-
-
特点:
-
可以部署多实例,实现分布式执行;
-
支持任务分片、广播和单机任务模式;
-
通过注册/心跳机制向调度中心动态注册。
-
2.2.3 注册与心跳机制
-
作用:保证调度中心能够感知每个 Executor 的状态。
-
流程:
-
Executor 启动时向 Admin 注册自身信息;
-
Executor 定期发送心跳,告知自身存活状态和运行能力;
-
Admin 根据注册信息和心跳决定任务调度。
-
-
好处:
-
支持动态扩容或缩容 Executor 节点;
-
可以在节点故障时自动转移任务。
-
2.2.4 数据库
-
作用:持久化所有任务信息、执行日志、调度记录等。
-
内容:
-
任务表(存储任务配置和状态);
-
执行日志表(存储每次任务执行结果和输出日志);
-
调度历史表(记录触发时间、耗时、执行结果等)。
-
-
特点:
-
任务和日志持久化,支持任务回溯和审计;
-
数据库是 Admin 高可用部署的关键依赖。
-
2.3 调度、路由和任务类型
2.3.1 调度(Scheduling)
调度是 XXL-Job 的核心功能之一,用于控制任务 何时执行。
(1)调度方式
-
Cron 表达式:
-
最常用的调度方式,灵活支持秒、分、小时、日、月、周等组合。
-
示例:
0 0 1 * * ?→ 每天凌晨 1 点执行。
-
-
固定间隔(Fixed Rate / Fixed Delay):
-
Fixed Rate:上一次任务开始时间到下一次开始时间的间隔;
-
Fixed Delay:上一次任务结束时间到下一次开始时间的间隔。
-
(2)调度策略
-
Failover(故障转移):
-
当执行任务的 Executor 挂掉时,调度中心会将未完成任务分配给其他存活的 Executor 执行。
-
-
Misfire(错过补偿):
-
如果某次调度错过(如节点宕机),可以配置是否补偿执行,保证任务不会丢失。
-
2.3.2 路由(Routing)
路由机制决定 任务由哪个 Executor 节点执行。
(1)路由策略示例
- 第一个:选取执行器管理的注册地址列表中的第一个执行器来执行任务;
- 最后一个:选取执行器管理的注册地址列表中的最后一个执行器来执行任务;
- 轮询:依次选取执行器管理的注册地址列表中的执行器,周而复始。
- 随机:从执行器管理的注册地址列表中随机选取一个执行器来执行任务;
- 一致性 HASH:实现一致性 HASH 负载均衡算法;
- 最不经常使用:选择最近最少被调度的执行器执行任务(通过次数维度选取任务);
- 最近最久未使用:选择距离上次被调度时间最长的执行器执行任务(通过时间维度选取任务),有助于平衡各执行器的工作负载;
- 故障转移:在任务路由策略选择“故障转移”的情况下,如果执行器集群中的某一台机器出现故障,将会自动 Failover 切换到一台正常的执行器发送调度请求;
- 忙碌转移:当任务分配到某个执行器时,如果该执行器正处于忙碌状态(可能正在执行其他任务或资源紧张),则会尝试将任务转移到其他相对空闲的执行器上执行;
- 分片广播:选取执行器管理的注册地址列表中的所有地址,每个地址都执行一次任务。此策略适用于需要在多个执行器上同时执行相同任务的场景,例如数据同步或分布式计算等。
其中,轮询和分片广播比较常用。分片广播的原理:将一个大任务拆分成若干片,每片任务携带 分片索引(shardIndex) 和 总分片数(shardTotal),分配给不同 Executor 执行。
(2)路由特点
-
路由策略与任务类型密切相关;
-
可以动态调整 Executor 列表,无需停机。
2.3.3 任务类型(Job Type)
XXL-Job 支持多种任务类型,满足不同业务场景需求:
| 类型 | 描述 | 适用场景 |
|---|---|---|
| 单机任务(Single) | 每次调度只在一个 Executor 上执行 | 核心业务处理、避免重复操作 |
| 广播任务(Broadcast) | 每次调度在所有 Executor 上执行 | 缓存刷新、通知广播 |
| 分片任务(Sharding) | 将任务拆分成多片分配给不同 Executor 并行执行 | 大数据处理、批量计算 |
| 脚本任务(Script) | 直接执行 Shell / Python / 批处理脚本 | 系统运维、自动化脚本 |
| GLUE 动态任务 | 在控制台动态编写 Java 代码执行 | 快速调试或轻量业务逻辑 |
2.4 运维和监控能力
XXL-Job 不仅是分布式任务调度框架,还提供完善的 运维和监控功能,便于企业对任务执行进行统一管理和可视化运维。
2.4.1 可视化控制台(Web UI)
-
提供 全功能的管理界面,无需直接操作数据库或命令行。
-
功能包括:
-
任务管理:新增、修改、删除、暂停、恢复、手动触发任务。
-
任务状态查看:查看每个任务的当前状态(运行中、暂停、失败、成功)。
-
任务调度历史:查看任务执行的历史记录,包括执行时间、耗时、状态。
-
执行日志查看:支持实时和历史日志查看,便于排查问题。
-
权限管理:可以分配不同角色访问控制台,实现操作权限控制。
-
2.4.2 日志管理与追踪
-
执行日志持久化:
-
每次任务执行的详细信息都会写入数据库。
-
包含:任务触发时间、开始/结束时间、耗时、执行结果、异常信息。
-
-
日志查询:
-
可以按任务、时间、状态查询执行记录。
-
支持异常快速定位和问题复盘。
-
-
分片日志:
-
分片任务每个片的执行日志单独记录,便于分析各片执行情况。
-
2.4.3 任务运行监控
-
执行状态监控:
-
成功率统计:任务成功、失败的比例。
-
异常任务告警:通过控制台或邮件/钉钉等方式通知运维人员。
-
-
任务调度状态监控:
-
实时查看任务是否被正确触发。
-
支持监控任务调度是否被 Executor 正确接收和执行。
-
2.4.4 健康检查与告警
-
Executor 心跳:
-
Executor 定期向调度中心发送心跳,调度中心可感知节点存活状态。
-
如果某个 Executor 节点失效,调度中心可自动转移任务(Failover)。
-
-
任务执行异常告警:
-
支持邮件、钉钉、企业微信等多种通知方式。
-
对失败任务可配置重试策略或人工补偿。
-
2.4.5 任务管理与调度策略运维
-
动态调度:
-
可以在控制台修改任务的 cron 表达式或调度策略,无需重启服务。
-
-
任务分片与路由管理:
-
动态调整分片数和 Executor 列表,实现负载均衡。
-
-
任务暂停与恢复:
-
临时停止任务执行,完成维护后恢复。
-
2.4.6 高可用运维
-
调度中心集群部署:
-
可以多节点部署 Admin,实现高可用,避免单点故障。
-
-
数据库持久化:
-
任务信息和日志存储在数据库中,可实现持久化管理和审计。
-
2.5 常见配置和代码实例
2.5.1 调度中心(Admin)配置
(1)数据库配置
XXL-Job Admin 依赖数据库存储任务信息、执行日志和调度记录。常见配置(以 Spring Boot 为例):
spring:datasource:url: jdbc:mysql://localhost:3306/xxl_job?useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driver
(2)XXL-Job Admin 配置
xxl:job:admin:addresses: http://localhost:8080/xxl-job-admin # 调度中心地址
-
addresses:调度中心 URL,Executor 通过它注册。
-
Admin 项目启动后提供 Web 控制台,用于管理任务和监控日志。
2.5.2 执行器(Executor)配置
xxl:job:executor:appname: demo-executor # 执行器名称,必须唯一address: # 手动设置地址,可为空,默认自动注册ip: # 执行器所在机器 IP,可不填port: 9999 # 执行器端口logpath: /data/applogs/xxl-job/jobhandler # 日志存放路径logretentiondays: 30 # 日志保留天数admin:addresses: http://localhost:8080/xxl-job-admin
2.5.3 任务代码示例
@Component
public class DemoJob {@XxlJob("demoJobHandler") // handler 名称必须和调度中心一致public void demoJobHandler() throws Exception {System.out.println("XXL-Job demo 任务执行,时间:" + new Date());// 模拟任务逻辑Thread.sleep(2000);System.out.println("XXL-Job demo 任务执行完成");}
}
当设置分片广播的路由策略,可以获取分片总数和分片索引属性
@XxlJob("shardingDemoJobHandler")
public void shardingDemoJobHandler(XxlJobHelper.ShardingVO shardingVO) {int shardIndex = shardingVO.getIndex();int shardTotal = shardingVO.getTotal();System.out.println("分片任务执行,分片索引:" + shardIndex + ",总分片数:" + shardTotal);
}
三、Spring Task 和 XXL-job 的区别
| 对比维度 | Spring Task | XXL-Job |
|---|---|---|
| 基本定位 | 本地任务调度器,依赖 JVM 线程池,适合单体应用 | 企业级分布式任务调度平台,适合微服务/分布式环境 |
| 部署模式 | 单实例 / 单节点,任务只在本地执行 | 分布式,调度中心 + 执行器,可多实例部署,支持任务分片和广播 |
| 调度方式 | @Scheduled 注解,支持 cron、fixedRate、fixedDelay | Cron 表达式、分片任务、广播任务、脚本任务、动态任务等 |
| 分布式支持 | 不支持,分布式部署会导致重复执行 | 原生支持分布式,保证任务不会重复执行,可 Failover |
| 任务管理 | 任务由代码控制,修改需要重启或改代码 | 控制台可动态新增、修改、暂停、触发任务,无需重启 |
| 任务监控与日志 | 无集中监控,日志依赖本地系统或自定义实现 | 提供 Web 控制台,集中查看执行日志、历史记录和任务状态 |
| 错误处理与重试 | 需自己实现 try-catch 或使用 Spring Retry | 调度中心提供失败自动重试,支持补偿和告警 |
| 可扩展性 | 依赖 Spring 线程池,可通过 ThreadPoolTaskScheduler 扩展 | 支持任务分片、广播、Executor 扩容,适应大规模分布式环境 |
| 适用场景 | 单体应用定时任务、轻量级业务逻辑 | 企业级批处理、大数据计算、缓存刷新、消息分发等复杂任务调度 |