GPT 系列论文1-2 两阶段半监督 + zero-shot prompt
GPT,GPT-2,GPT-3 论文精读【论文精读】--B站
GPT前三和 Transformer还有BERT 时间轴。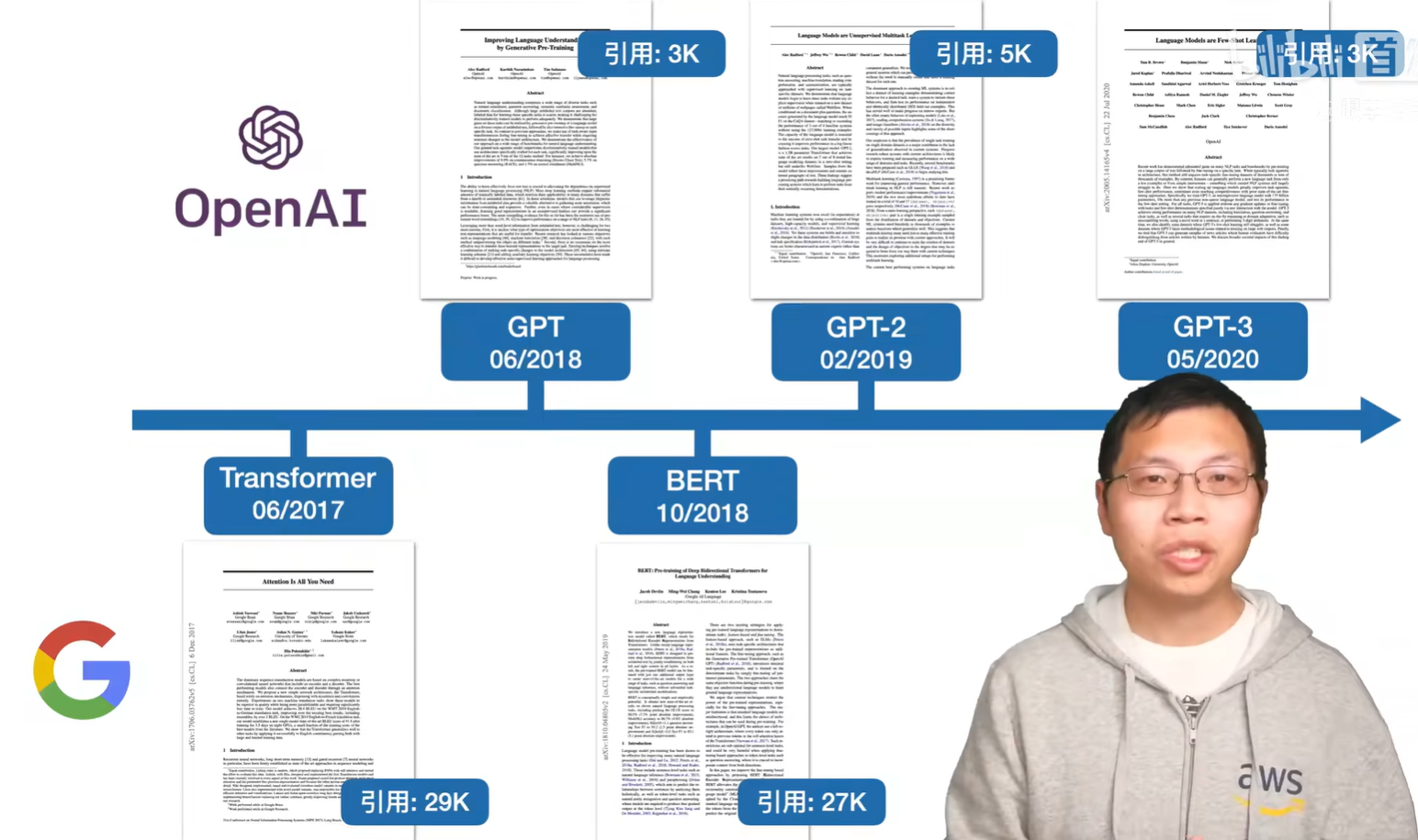
GPT把Transformer的解码器 在大量无标号文本数据上 训练预训练模型,再在子任务微调得到每个任务需要的分类器。
BERT把Transformer的编码器 相比gpt1更大的数据集预训练,在BERT-base后还出了BERT-large.
gpt1<BERT-base<BERT-large<gpt2 发现适合zero-shot
gpt3相比gpt2 数据和模型都翻100倍 暴力出奇迹。
gpt decoder-only 训练难度 出成果难度更大(openai团队想做强人工智能)
谷歌研究组:Transformer原始目标机器翻译 序列翻译;
BERT 像计算机视觉先训练一个预训练模型,再做微调出子任务的成果 这套思路搬到NLP
那时候的研究者更倾向于用BERT 进一步优化技术 因为容易跑起来,同样参数规模下 BERT效果好于gpt,gpt decoder-only 太难训练 也更适合生成式的任务。
目录
GPT1 - 两阶段半监督训练
1. 摘要
2. Introduction
3. Related Work
4. Framework 架构
GPT1 -> GPT2中间 BERT的冲击
GPT2 - 零样本能力 + prompt
GPT1 - 两阶段半监督训练
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
1. 摘要
-
核心问题: NLU任务多样与特定任务标注数据稀缺之间的矛盾。
-
任务多样: 列举了文本蕴含、问答、语义相似性、文档分类等,说明NLU不是一个单一任务,而是一个涵盖众多任务的广阔领域。Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification.
-
数据矛盾: 互联网上有海量的无标签文本数据(Unlabeled Text),但为每个特定任务人工标注足够多的训练数据(Labeled Data)成本极高,非常稀缺。Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately.
-
-
后果: 这种数据稀缺使得传统的判别式模型(Discriminatively Trained Models,例如直接训练一个文本分类器)难以在这些任务上取得出色的性能。因为它们严重依赖于大量高质量的标注数据。
提出了一个两阶段的训练范式:
-
生成式预训练 (Generative Pre-training):
-
方法: 在一个大规模、多样化的无标签文本语料库上训练一个语言模型(Language Model)。We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text
-
目的: 语言模型的训练目标是根据上文预测下一个词。通过这个过程,模型可以学习到丰富的语言知识、世界知识、语法结构、常识等,形成一个高质量的通用文本表征(Universal Text Representations)。这相当于让模型打下了深厚的语言基础。
-
-
判别式微调 (Discriminative Fine-tuning):
-
方法: 在预训练好的模型基础上,针对特定的下游任务(如情感分析、问答等),使用相对少量的标注数据进行有监督的微调。followed by discriminative fine-tuning on each specific task.
-
目的: 将预训练阶段学到的通用知识迁移(Transfer)到具体任务上,使模型能快速适应新任务并达到高性能。
-
这种预训练+微调的思想 在CV中很早就流行使用,但在NLP中一直没有,因为NLP没有 ImageNet 那样100w张图片的数据集(图片中信息比较多 一张图片信息<->十个句子信息)
之前NLP大量没有标号的文本的工作:word2vec词嵌入
GPT方法与之前工作的关键区别和优势: 通用模型-多任务
-
任务感知的输入转换 (Task-aware Input Transformations): 这是实现统一架构的关键。对于不同的任务(如分类、蕴含、相似度比较),它们所需的输入格式是不同的。GPT通过一个简单的转换规则,将不同任务的输入都重构为一个序列(Sequence)的形式,以便能够被同一个预训练模型处理。In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer
-
例如: 对于文本蕴含任务,可以将前提(Premise)和假设(Hypothesis)用
Delimtoken连接起来:[Premise] $ [Hypothesis]。对于文本分类任务,可以直接输入文本。模型只需要在微调时学习一个新增的线性输出层,来理解这些特定格式并做出预测。
-
-
最小化架构更改 (Minimal Changes): 整个方法(预训练+微调)对模型的主干架构(Transformer Decoder)几乎没有改动。模型在不同任务间切换时,只需要修改输入格式和最后的输出层,而不需要为每个任务设计一个特定的模型结构。这体现了其“通用性”和“灵活性”。while requiring minimal changes to the model architecture.
相对图像 文本对应的任务更多;之前的工作 需要对模型进行一些改变 来适应下游任务。
成果:Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task.一个通用的、与任务无关的模型的性能,竟然超过了那些为每个任务精心设计的专用模型。
2. Introduction
1. 研究背景与核心问题:深度学习在NLP的成功严重依赖大量人工标注数据,但获取这些数据成本高、效率低,限制了模型在缺少标注资源领域的应用。
解决方向: 研究如何从原始文本(raw text) 中有效学习,以减少对监督学习的依赖
2. 现有方法的成就与局限:像Word2Vec、GloVe这样的预训练词向量已被证明能有效提升NLP任务性能。这证明了无监督学习的有效性。但词向量只能捕获词级别的信息,无法捕捉更复杂的短语、句子、段落级别的语义和语法信息。面临两大挑战:
-
如何定义优化目标 (What to learn?):First, it is unclear what type of optimization objectives are most effective at learning text representations that are useful for transfer. 什么才是学习高质量文本表征的最佳无监督训练目标?是语言模型、机器翻译还是语篇连贯?不同目标在不同任务上表现各异,没有定论。
-
迁移方法不统一 (How to transfer?): Second, there is no consensus on the most effective way to transfer these learned representations to the target task.如何将学到的表征有效迁移到下游任务?现有方法需要对模型架构进行任务特定的修改、使用复杂的多阶段训练策略或添加辅助学习目标。这种方法缺乏一致性,非常繁琐。
3.解决方案:半监督学习 核心两阶段:
-
无监督预训练 (Unsupervised Pre-training): 在大量无标签文本上,使用语言模型作为优化目标,学习神经网络的初始参数。(为什么选LM?因为它能很好地捕获语法、语义、常识,且数据获取容易)
-
有监督微调 (Supervised Fine-tuning): 使用下游任务的标注数据,在上述预训练模型的基础上进行有监督训练,使其适配特定任务。
目标: 学习一个通用的(universal) 表征,只需极少的改动就能迁移到各种任务上。
4. 模型架构与迁移策略
选择了Transformer的解码器。原因:
-
注意力机制能更好地处理长程依赖。
-
提供更结构化的记忆。
-
为后续的迁移性能提供了坚实基础。
迁移策略 - 遍历式输入适配 (Traversal-style input adaptations): 实现最小化架构更改。对于不同的任务(如分类、蕴含、相似度),通过一个固定的规则,将结构化输入(如两个句子)重新排列成一个连续的令牌序列。这样,同一个预训练模型就能处理各种不同格式的任务输入。
3. Related Work
1. NLP领域的半监督学习 -- 超越传统的词级别信息迁移
-
早期方法: 利用无标签数据计算词/短语级统计特征,使用在无标签语料上训练的词嵌入(如Word2Vec),提升下游任务性能。但这类方法主要迁移的是词级别的语义信息。
-
本文定位: 捕获短语、句子等更高级别的语义信息。
2. 无监督预训练
目标:找到一个良好的模型参数初始化点。
之前用在图像分类、语音识别、机器翻译等领域,与本文最相似的工作是使用语言模型目标进行预训练,然后在监督任务上微调。
本文创新/差异:
-
模型架构: 前人使用LSTM,其长程依赖建模能力有限。我们使用Transformer,能捕获更长范围的语言学结构。
-
任务范围更大: 我们在更广泛的任务(如自然语言推理、故事补全)上验证了有效性。
-
迁移改动小: 其他方法将预训练模型的表示作为辅助特征,需要为每个任务引入大量新参数。而我们的方法在迁移时对模型架构的改动极小。
3. 辅助训练目标
-
早期方法: 通过引入多种辅助的NLP任务(如词性标注、语言模型等)来提升主任务的性能。
-
近期方法: 在目标任务的损失函数中直接加入语言模型等辅助目标。
-
本文对比: 我们的实验也使用了辅助目标(指微调阶段),但我们证明,无监督预训练本身已经学到了与下游任务相关的多种语言知识,这才是性能提升的关键。
4. Framework 架构
1. 无监督预训练 Unsupervised pre-training
语料库中 用前k个词预测下一个词 最大似然估计。

![]() 输入初始化。
输入初始化。

![]()
n层Transformer 解码器的块。语言模型自回归生成,掩码masked 只能看到它之前的词。
![]()
输出需要将维度 投影转换回去。乘以Token Embedding矩阵 We 的转置(权重绑定)+ softmax下一个词概率
2. 有监督微调 Supervised fine-tuning
![]()
![]()
取最后一个Transformer块(final transformer block)对最后一个输入token(通常是[End]或分隔符token)产生的激活值(activation)hlmhlm。这个向量可以被看作是整个输入序列的浓缩的、上下文感知的语义表示。
线性层投影 乘以矩阵W转换维度(Wy : 线性输出层的权重 尺寸是 (模型隐藏层维度, 任务标签数量))
再进行 softmax + 交叉熵损失。
![]()
损失函数:不仅仅优化有监督目标L2,同时也优化预训练时的语言模型目标L1。(λ超参数)
-
主体参数共享: 预训练Transformer模型的所有参数都会在微调过程中继续更新。不需要为每个任务创建大部分的新参数,实现了“一套主体参数,适配多个任务”。
3. 任务特定输入转化Task-specific input transformations
使用特殊的分隔符(Delimiter tokens) 来连接不同的部分,并在序列首尾添加随机初始化的开始和结束标记([start], [end])。这些特殊标记的嵌入向量会在微调过程中学习。(特殊标记要和正常文本区分开)
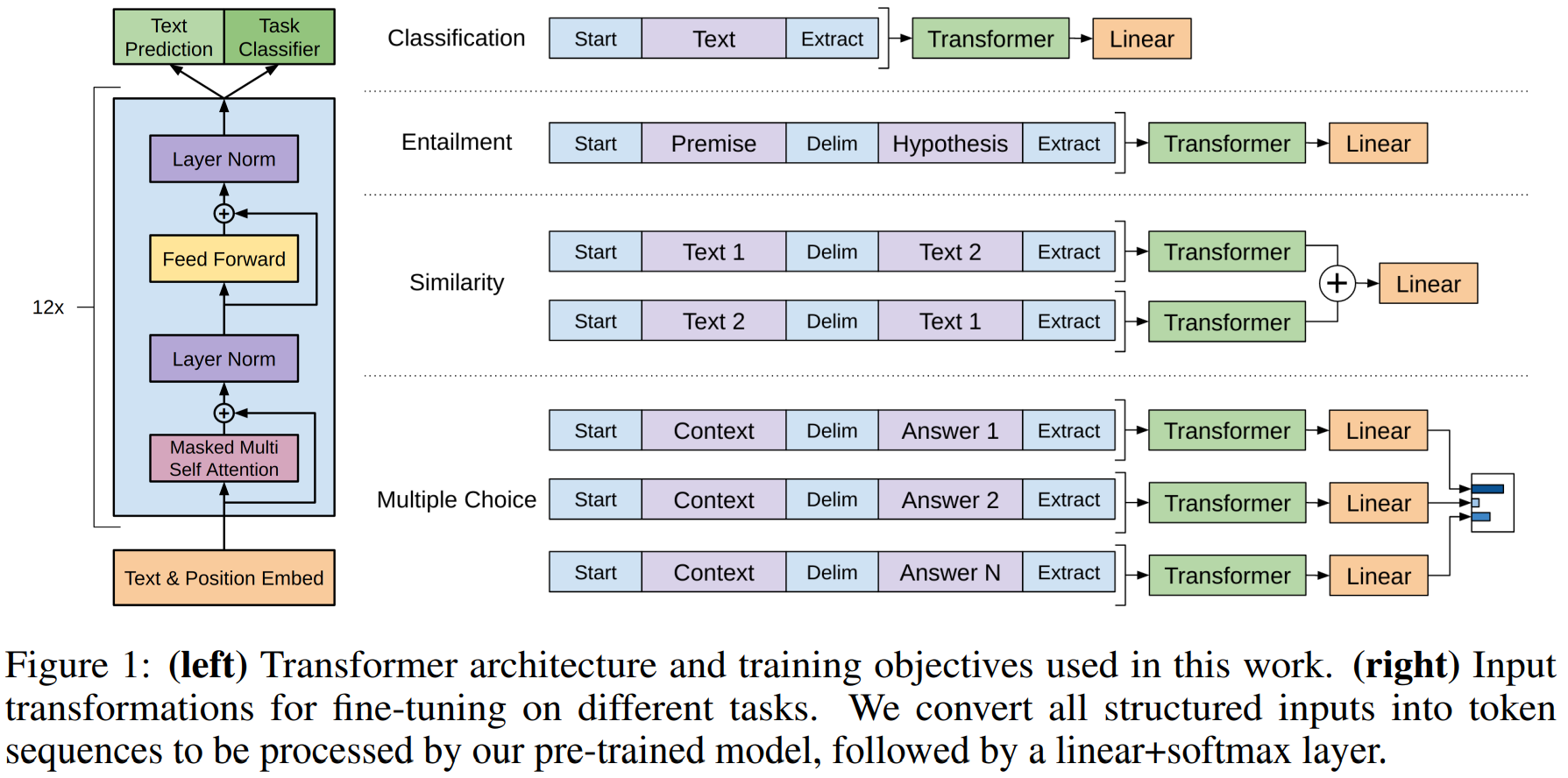
1. 分类: 前面放[Start] 后面放 抽取[Extract] 线性层转换为各个种类
2. 蕴含(Entailment) 判断前提(Premise)是否蕴含假设(Hypothesis)[start] p [delim] h [extract]
3. 语义相似度(Similarity) NLP中有文本去重的应用
-
输入特点: 两个句子
(句子1, 句子2)没有先后顺序之分(对称性)。句子1和句子2互换,标签不变。 -
转换规则: 为了体现这种对称性,模型需要同时看两种顺序 再加起来。
-
[start] 句子1 [delim] 句子2 [end] -
[start] 句子2 [delim] 句子1 [end]
-
4. 多选题 [start] z [delim] q [delim] ak [end] 分别每个选项正确率 再softmax
GPT1 -> GPT2中间 BERT的冲击
BERT-base 论文 相同数据规模比gpt1效果更好。
-
BERT: 双向编码器 (自编码)
-
目标: 掩码语言模型 (MLM),即随机遮盖输入中的一些词,然后让模型根据上下文(包括左右两侧的所有词) 来预测被遮盖的词。
-
优势: 这种训练任务迫使模型从整个句子的全局信息中来理解每一个词的含义。因此,BERT产生的词表征是深度双向的,融合了完整的上下文信息,就像做完形填空。
-
几乎所有下游的自然语言理解任务(如文本分类、情感分析、问答、自然语言推理)都需要对整个句子的完整、双向的理解。BERT的预训练目标与这些下游任务的目标高度一致,因此其产生的表征天然更适合这些任务。


当你发现 你的工作被别人用更大的模型和数据集打败。
我也更多的数据训练 堆模型大小(军备竞赛)那这篇文章本身就没太多意思,工程味比较重。
可以换一个角度展现提升 比如说做更难的问题 如zero-shot的情况下 也能得到相近的结果。
GPT2 - 零样本能力 + prompt
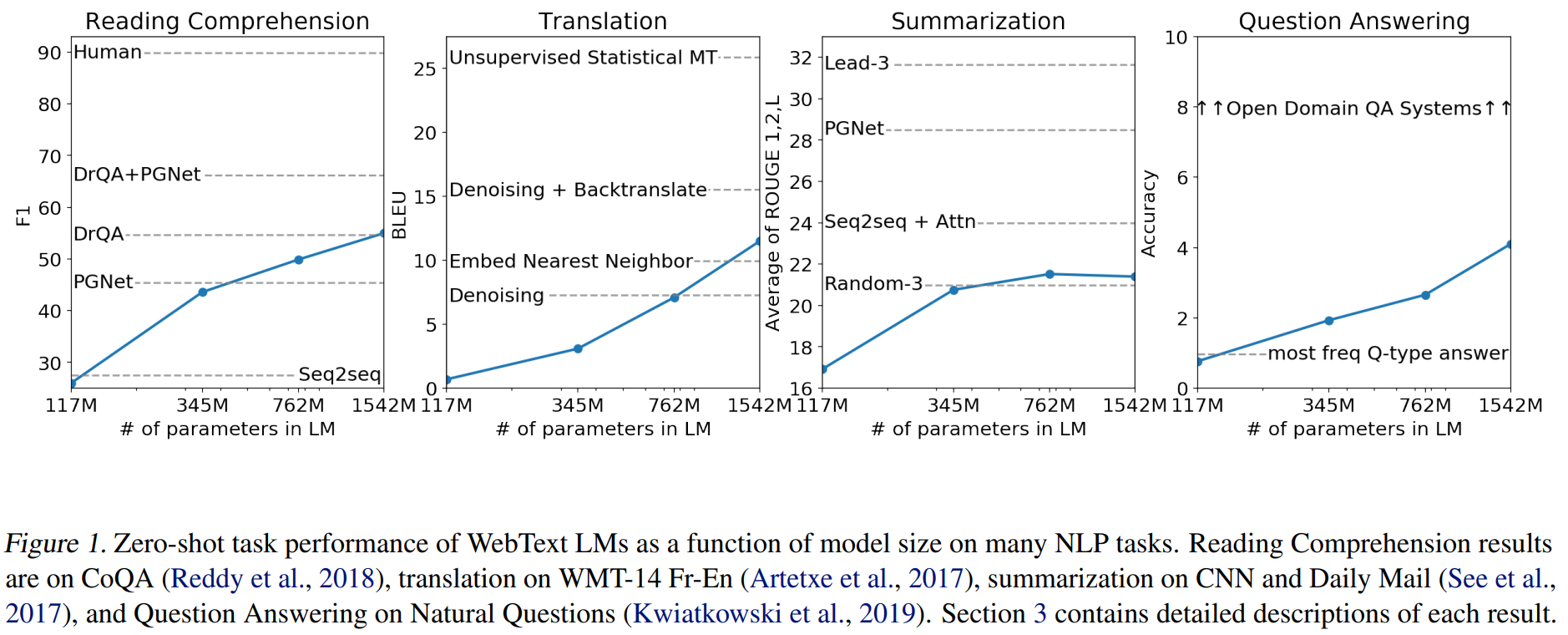
发现大规模语言模型本身具备零样本(Zero-shot)的多任务学习能力。
不进行特定任务的微调训练,通过自然语言描述或给出一个任务格式示例(prompt),衡量预训练模型本身是否已经从其海量训练数据学习到如何解决任务,检验的是模型的泛化能力和知识迁移能力。
Language Models are Unsupervised Multitask Learners 论文
https://openai.com/index/better-language-models/
一个新数据集 网页WebText;1.5B参数量;Common Crawl是一个爬取互联网的网页 Reddit是一个网络内容评级和讨论网站,构建WebText数据集。
比如法语翻译英语的例子,大模型是可以从WebText中学会的(因为其中可能有大量的网页信息例子 前一句法语,can be translated... 有相关有效信息)

-
模型在训练过程中,在没有任何明确监督(即没有使用任何任务特定的标注数据)的情况下,自动开始学习并掌握了多种NLP任务的能力。
-
意义: 这表明,当语言模型足够大、训练数据足够丰富和多样时,它可以通过无监督学习直接获得泛化的任务能力,而不再强制需要微调步骤。
gpt1在下游任务微调时 进行了任务特定输入转化,加特殊符号整理特定格式。模型在微调时 认识这些符号。
zero-shot 问题是 下游任务不能微调,那我特殊符号(预训练正常文本中没有的)模型不认识。
所以构建下游任务 不可以引入特殊符号。而是要以自然语言的形式(即为后来的prompt 提示词理解任务)
在不同任务上的表现,随着参数量的翻倍 性能还是在上升的。