构建AI智能体:二十九、Text2SQL:告别繁琐SQL!用大模型自助生成数据报表
一、解决痛点
如今数字经济飞速发展,数据已成为企业的核心资产。然而,大多数企业在数据利用方面面临着一个突出的矛盾:数据量呈指数级增长,但专业数据分析师资源却严重匮乏。业务人员往往需要等待数天甚至数周才能获得一个简单的数据查询结果,严重影响了决策效率和市场响应速度。
传统数据查询流程的痛点:
- 沟通成本高昂:业务人员需向数据团队反复解释需求,双方对指标定义和理解常有偏差
- 技术门槛限制:非技术人员无法直接访问数据,完全依赖技术团队支持
- 响应周期漫长:简单查询也需要走完整的需求评审、开发、测试流程
- 资源分配不合理:数据工程师花费大量时间处理重复性的简单查询,无法专注于高价值的数据架构和复杂分析工作
早期的解决方案包括可视化BI工具和SQL查询界面优化,但这些方案仍需要用户具备一定的数据知识和技能。真正的突破来自于自然语言处理技术,特别是大型语言模型的发展,使Text2SQL技术从实验室走向实用阶段。
Text2SQL技术通过将自然语言转换为结构化查询语言(SQL),彻底改变了数据访问方式。这项技术不仅能够理解用户意图,还能生成符合语法规范、可高效执行的数据库查询,让业务人员直接用日常语言与数据库"对话"。实现Text2SQL技术后,企业能够建立真正的自助式数据分析平台,将数据团队从重复劳动中解放出来,同时赋予业务人员直接探索数据的能力,大幅提升数据驱动决策的效率和广度。

二、什么是Text2SQL
1. 基础定义
Text2SQL是自然语言处理(NLP)与数据库管理系统的交叉领域技术,其主要任务是将用户输入的自然语言问题转换为符合语法规范、可正确执行的SQL查询语句。这个过程涉及多个子任务:
- 自然语言理解:解析用户查询的语义结构,识别意图、实体和条件
- 模式映射:将自然语言中的概念映射到数据库中的表、列和关系
- SQL生成:构建符合目标数据库方言的正确语法结构
- 查询优化:确保生成的SQL在执行时具有良好性能
2. 核心处理过程
2.1 语义理解
自然语言中存在大量歧义和模糊表达,如"显示最新数据"中的"最新"可能指时间最新或ID最大。
解决方案:
- 利用上下文对话历史澄清意图,提供选项让用户确认,或采用最合理的默认解释。
2.2 模式对齐
将自然语言中的提及正确关联到数据库表结构,如用户说"客户数量"需要映射到customer表的id列。
解决方案:
- 基于字符串相似度的匹配(Levenshtein距离、Jaccard相似度)
- 基于嵌入的语义匹配(Sentence-BERT、USE等)
- 联合学习表结构和自然语言表示
2.3 SQL语法检测
确保生成的SQL符合目标数据库的语法规范,特别是复杂查询涉及多表连接、子查询、聚合函数等。
解决方案:
- 采用语法约束解码,确保生成过程中不违反SQL语法规则
- 使用中间表示(如抽象语法树)作为桥梁
- 基于执行的反馈循环,通过验证执行结果改进生成质量
2.4 查询效率优化
避免生成性能低下的SQL,如缺少索引的全表扫描、不必要的嵌套查询等。
解决方案:
- 在提示词中嵌入性能最佳实践
- 后优化处理,对生成的SQL进行重写和优化
- 与数据库优化器结合,提供执行计划反馈
三、Text2SQL的核心组件
一个完整的Text2SQL系统包含以下核心组件:
1. 自然语言理解模块
- 意图识别:判断用户想要查询什么
- 实体提取:识别查询中的关键概念和条件
- 语义解析:理解查询的深层含义
2. schema管理模块
class SchemaManager:def __init__(self, db_config):self.db_config = db_configself.connection = Noneself.schema_metadata = Nonedef fetch_metadata(self):# 获取数据库表结构信息passdef build_vector_index(self):# 将表结构向量化用于快速检索passSchema管理模块是Text2SQL系统的"大脑"和"词典",承担着将数据库物理结构转化为语言模型可理解的知识体系的关键任务。
元数据采集与解析:
- 表级元数据采集包括获取表名称、表注释、存储引擎类型、行数估算、创建时间等基本信息。特别是表注释,往往包含了业务人员能够理解的概念描述,是自然语言映射的重要桥梁。
- 字段级元数据采集则更加细致,包括字段名称、数据类型、是否允许为空、默认值、字段注释、是否主键、是否唯一约束等。数据类型信息帮助模型理解如何构建合适的查询条件(比如字符串需要引号,数字则不需要),而约束信息则影响连接查询的构建方式。
- 索引信息采集让系统了解查询性能特征,哪些字段建立了索引,是什么类型的索引,这有助于生成更高效的SQL语句。
- 关系发现是元数据采集的高级阶段,通过分析外键约束、字段命名模式(如user_id通常关联users表)、甚至数据值的分布特征来推断表之间的关联关系。
知识表示与向量化:
- 结构化文档生成将技术性的元数据转换为自然语言描述。例如,将"users表有id(int主键)、name(varchar)、email(varchar唯一)"转换为"用户表存储用户基本信息,包含用户ID(数字类型,唯一标识符)、姓名(字符串类型)、邮箱(字符串类型,唯一不可重复)"。
- 多层次表示创建不同粒度的schema描述:表级别的概要描述、字段级别的详细说明、关系级别的连接路径描述。这种分层表示允许系统根据查询复杂度选择适当的信息粒度。
- 向量化嵌入使用文本嵌入模型将schema描述转换为高维向量,使得语义相似的schema元素在向量空间中位置接近。当用户查询"客户信息"时,与customers表、client表相关的向量会被优先检索到。
语义检索与上下文构建:
- 查询扩展与重写对用户原始查询进行同义词扩展、概念泛化等处理,提高检索召回率。如"消费者"扩展为"客户、用户、购买者"。
- 相关性排序不仅考虑语义相似度,还结合字段重要性(如主键字段优先)、使用频率等因素对检索结果进行排序。
- 上下文构建将检索到的相关schema信息组织成清晰的提示词内容,通常包括表结构描述、字段说明、关系路径建议等,为语言模型提供充足的背景知识。
版本管理与变更同步:
- 变更检测定期或实时监测数据库结构变化,捕捉表/字段的增删改操作。
- 增量更新只更新发生变化部分的向量表示,避免全量重建的开销。
- 版本回溯维护schema历史版本,确保基于旧版本schema生成的查询仍然可以正确执行和理解。
Schema管理模块是Text2SQL系统中最具技术深度和业务价值的组件之一。它不仅仅是一个被动的元数据存储库,而是一个主动的知识管理和语义理解系统。优秀的Schema管理能够显著提升Text2SQL系统的准确性和用户体验,真正实现从"技术语言"到"业务语言"的平滑转换。
3. SQL生成模块
- 提示词工程:设计有效的系统提示词
- 模型推理:调用大模型生成SQL
- 后处理:对生成的SQL进行验证和优化
4. 执行与返回模块
- 查询执行:在数据库上运行生成的SQL
- 结果处理:格式化查询结果
- 错误处理:处理执行过程中的异常
5. 安全与权限控制
企业级应用必须考虑安全性:
- SQL注入防护:使用参数化查询,避免字符串拼接
- 权限继承:执行SQL时继承应用程序的数据库权限
- 查询限制:设置超时时间、返回行数限制
- 审计日志:记录所有查询用于审计和优化
四、大语言模型选择
1. 闭源模型选项
OpenAI GPT系列:
- GPT-3.5-turbo:成本效益最佳,响应速度快
- GPT-4:处理复杂查询能力更强,但成本较高
国内大模型:
- 通义千问:阿里云开发,中文优化良好
- 文心一言:百度开发,与企业服务集成紧密
2. 开源模型选项
Qwen系列:
- Qwen-7B/14B:参数量适中,中文能力突出
- Qwen-72B:接近GPT-3.5水平,需要较多计算资源
其他选择:
- ChatGLM3-6B:支持函数调用,双语能力均衡
- CodeLlama:专为代码生成优化,SQL能力强劲
3. 选择策略
选择模型时需要考虑多个因素:
- 数据敏感性:敏感数据优先选择本地部署的开源模型
- 查询复杂度:简单查询可用较小模型,复杂查询需要更强能力
- 成本预算:API调用按量付费 vs 自建基础设施的固定成本
- Function Calling支持:不是所有的模型都支持Function Calling,选择前需要考量是否有计划使用
- 技术支持:团队的技术能力与模型要求的匹配程度
五、Text2SQL 集成 Function Calling 示例
Function Calling 是大语言模型与外部系统交互的一种标准化方式。在 Text2SQL 场景中,它允许我们将复杂的 SQL 生成任务分解为两个清晰的步骤:
- 大模型理解用户意图并决定需要调用什么函数
- 应用程序接收结构化的函数参数并执行实际查询
优势与特点:
- 安全性: 通过Function Calling,应用程序控制最终执行的SQL,可以添加权限检查和SQL注入防护
- 可靠性: 大模型只需要生成结构化的参数,不需要生成完整的SQL语句,减少错误
- 灵活性: 可以轻松扩展支持更多的数据库操作和函数
- 可解释性: 可以记录大模型的思考过程和生成的参数,便于调试和优化
这种方法比直接让大模型生成 SQL 更加安全、可控和可靠。
1. 示例代码
1.1 主要流程
- 用户输入自然语言查询(如"显示所有用户的姓名和所在城市")
- 系统将查询和数据库结构信息发送给Qwen-Plus模型
- 模型理解查询意图,生成函数调用(包括SQL语句)
- 系统解析函数调用,提取SQL语句
- 执行SQL查询(在实际应用中连接真实数据库)
- 返回查询结果给用户
下面是对上述代码的详细解释,涵盖了每个部分的功能和作用:
1.2 导入依赖库
import dashscope
from dashscope import Generation
import json
import os - dashscope: 阿里云通义千问的Python SDK,用于调用大语言模型API
- Generation: 专门用于生成式AI任务的模块
- json: 用于解析和生成JSON格式数据
- os: 用于访问操作系统功能,如环境变量
1.3 API密钥设置
# 设置通义千问API密钥
dashscope.api_key = os.environ.get('DASHSCOPE_API_KEY')- 从环境变量DASHSCOPE_API_KEY中获取API密钥
- 这种方式比硬编码在代码中更安全,便于在不同环境中切换密钥
- 使用前需要先设置环境变量
1.4 函数定义
# 定义可用的函数
functions = [{"name": "execute_sql_query","description": "执行SQL查询并返回结果","parameters": {"type": "object","properties": {"sql": {"type": "string","description": "要执行的SQL查询语句"}},"required": ["sql"]}}
]- 定义了大模型可以调用的函数列表
- name: 函数名称,大模型会根据这个名称决定调用哪个函数
- description: 函数描述,帮助大模型理解函数的用途
- parameters: 定义函数需要的参数
- type: 参数类型,这里是object(对象)
- properties: 定义对象的属性
- required: 指定哪些参数是必需的
1.5 数据库结构信息
# 模拟的数据库表结构信息
database_schema = """
数据库中有以下表:
1. 用户表(users): 包含id, name, email, city字段
2. 订单表(orders): 包含id, user_id, product, amount, order_date字段
3. 产品表(products): 包含id, name, price, category字段
"""- 提供数据库的结构信息,帮助大模型理解可用的表和字段
- 在实际应用中,这通常会从数据库系统表中动态获取
- 包含表名、字段名和简单的描述,帮助大模型生成准确的SQL
1.6 主函数:text_to_sql
def text_to_sql(user_query):"""将自然语言转换为SQL并执行"""try:# 调用通义千问Qwen-Plus模型,支持Function Callingresponse = Generation.call(model='qwen-plus',messages=[{"role": "system", "content": f"你是一个SQL专家。请根据以下数据库结构生成SQL查询:\n{database_schema}"},{"role": "user", "content": user_query}],functions=functions,result_format='message')- 这是核心函数,负责处理用户查询
- 使用try-except块处理可能的API调用错误
- 调用Generation.call方法与Qwen-Plus模型交互
- model='qwen-plus': 指定使用Qwen-Plus模型,该模型支持Function Calling
- messages: 包含对话历史的消息列表
- system角色: 设置模型的角色和行为准则
- user角色: 用户的实际查询
- functions=functions: 传递可用的函数定义
- result_format='message': 指定响应格式为消息格式
# 解析模型响应message = response.output.choices[0].message# 检查是否要求调用函数if hasattr(message, 'function_call') and message.function_call:function_name = message.function_call.namefunction_args = json.loads(message.function_call.arguments)# 执行相应的函数if function_name == "execute_sql_query":return execute_sql_query(function_args["sql"])- 解析API响应,获取第一条消息
- 检查响应中是否包含函数调用
- hasattr(message, 'function_call'): 检查消息是否有function_call属性
- message.function_call.arguments: 获取函数调用的参数(JSON字符串)
- json.loads(): 将JSON字符串解析为Python字典
- 根据函数名称调用相应的处理函数
else:# 如果没有函数调用,尝试直接提取SQLsql = extract_sql_from_text(message.content)if sql:return execute_sql_query(sql, "从模型响应中提取SQL")else:return "未能生成合适的SQL查询"except Exception as e:return f"API调用失败: {str(e)}"- 备选方案:如果模型没有返回函数调用,尝试从文本响应中提取SQL
- 异常处理:捕获并返回API调用过程中可能出现的错误
1.7 SQL提取函数
def extract_sql_from_text(text):"""从文本中提取SQL语句"""import re# 查找SELECT语句select_pattern = r"SELECT\s+.*?FROM\s+.*?(?:WHERE\s+.*?)?(?:ORDER BY\s+.*?)?(?:LIMIT\s+.*?)?;?"matches = re.findall(select_pattern, text, re.IGNORECASE | re.DOTALL)if matches:return matches[0].strip()# 查找其他类型的SQL语句other_patterns = [r"INSERT INTO\s+.*?VALUES\s*\(.*?\);?",r"UPDATE\s+.*?SET\s+.*?WHERE\s+.*?;?",r"DELETE FROM\s+.*?WHERE\s+.*?;?"]for pattern in other_patterns:matches = re.findall(pattern, text, re.IGNORECASE | re.DOTALL)if matches:return matches[0].strip()return None- 使用正则表达式从文本中提取SQL语句
- select_pattern: 匹配SELECT语句的模式
- other_patterns: 匹配INSERT、UPDATE、DELETE语句的模式
- re.IGNORECASE: 忽略大小写
- re.DOTALL: 让.匹配包括换行符在内的所有字符
- 如果找到匹配的SQL语句,返回第一个匹配项并去除首尾空白
1.8 SQL执行函数
def execute_sql_query(sql, thought=""):"""执行SQL查询的函数"""# 在实际应用中,这里会连接真实数据库执行查询# 这里只是返回模拟结果print(f"思考过程: {thought}")print(f"执行的SQL: {sql}")# 模拟不同查询的结果sql_lower = sql.lower()if "select name, city from users" in sql_lower:return [{"name": "张三", "city": "北京"},{"name": "李四", "city": "上海"},{"name": "王五", "city": "广州"}]# ... 其他条件判断- 模拟执行SQL查询并返回结果
- 在实际应用中,这里会连接真实数据库(如MySQL、PostgreSQL等)
- 根据SQL语句的内容返回不同的模拟结果
- 打印思考过程和生成的SQL,便于调试和理解模型的工作原理
1.9 测试代码
# 测试示例
if __name__ == "__main__":# 示例查询queries = ["显示所有用户的姓名和所在城市","查询订单中的产品和数量","删除所有测试用户","显示所有产品名称和价格","查询北京的用户"]for query in queries:print(f"\n{'='*50}")print(f"用户查询: {query}")result = text_to_sql(query)print(f"查询结果: {result}")print(f"{'='*50}") - 当直接运行脚本时执行的代码
- 提供多个示例查询,测试系统的不同功能
- 遍历查询列表,对每个查询调用text_to_sql函数
- 格式化输出结果,便于阅读
2. 输出结果
==================================================
用户查询: 显示所有用户的姓名和所在城市
思考过程: {"role": "assistant", "content": "", "function_call": {"name": "execute_sql_query", "arguments": "{\"sql\": \"SELECT name, city FROM users;\"}"}}
执行的SQL: SELECT name, city FROM users;
查询结果: [{'name': '张三', 'city': '北京'}, {'name': '李四', 'city': '上海'}, {'name': '王五', 'city': '广州'}]
====================================================================================================
用户查询: 查询订单中的产品和数量
思考过程: {"role": "assistant", "content": "", "function_call": {"name": "execute_sql_query", "arguments": "{\"sql\": \"SELECT product, amount FROM orders;\"}"}}
执行的SQL: SELECT product, amount FROM orders;
查询结果: [{'product': '笔记本电脑', 'amount': 2}, {'product': '智能手机', 'amount': 5}, {'product': '平板电脑', 'amount': 3}]
====================================================================================================
用户查询: 删除所有测试用户
查询结果: API调用失败: 'function_call'
====================================================================================================
用户查询: 显示所有产品名称和价格
思考过程: {"role": "assistant", "content": "", "function_call": {"name": "execute_sql_query", "arguments": "{\"sql\": \"SELECT name, price FROM products;\"}"}}
执行的SQL: SELECT name, price FROM products;
查询结果: [{'name': '笔记本电脑', 'price': 5999.0}, {'name': '智能手机', 'price': 3999.0}, {'name': '平板电脑', 'price': 2999.0}]
====================================================================================================
用户查询: 查询北京的用户
思考过程: {"role": "assistant", "content": "", "function_call": {"name": "execute_sql_query", "arguments": "{\"sql\": \"SELECT * FROM users WHERE city = '北
京';\"}"}}
执行的SQL: SELECT * FROM users WHERE city = '北京';
查询结果: [{'id': 1, 'name': '张三', 'email': 'zhangsan@example.com', 'city': '北京'}, {'id': 2, 'name': '李四', 'email': 'lisi@example.com', 'city': '上海'}, {'id': 3, 'name': '王五', 'email': 'wangwu@example.com', 'city': '广州'}]
==================================================六、Text2SQL 从本地MySql数据库读取
1. 示例代码
1.1 初始化设置
import os
import json
import pymysql
import dashscope
from dashscope import Generation# 设置通义千问API密钥
dashscope.api_key = os.environ.get('DASHSCOPE_API_KEY')- 导入必要的库:pymysql用于MySQL连接,dashscope用于调用通义千问API
- 从环境变量获取API密钥,提高安全性
1.2. 初始化数据库链接
# 数据库配置db_config = {"host": "localhost","user": "your_username","password": "your_password","database": "your_database","charset": "utf8mb4"}# 初始化Text2SQL系统text2sql = SimpleText2SQL(db_config)- host主机名,本机可以直接用locahost
- user数据库登录用户名
- password数据库登录密码
- database数据库名称
1.3. 数据库结构获取
def get_database_schema(self):"""获取数据库表结构信息"""try:connection = pymysql.connect(**self.db_config)schema = {}with connection.cursor() as cursor:# 获取所有表名cursor.execute("SHOW TABLES")tables = cursor.fetchall()for table in tables:table_name = table[0]schema[table_name] = {"columns": []}# 获取表的列信息cursor.execute(f"DESCRIBE {table_name}")columns = cursor.fetchall()- 使用SHOW TABLES获取所有表名
- 使用DESCRIBE table_name获取每个表的列信息
- 将结构信息存储在字典中供后续使用
1.4 SQL生成
def generate_sql(self, user_query):"""使用Qwen生成SQL查询"""if not self.schema_info:self.get_database_schema()# 构建schema描述schema_desc = "数据库表结构:\n"for table_name, table_info in self.schema_info.items():schema_desc += f"- {table_name}: "schema_desc += ", ".join([f"{col['name']}({col['type']})" for col in table_info["columns"]])schema_desc += "\n"# 构建提示词prompt = f"""你是一个SQL专家。请根据以下数据库结构,将用户的自然语言查询转换为MySQL SQL语句。{schema_desc}请只输出SQL语句,不要输出其他任何内容。用户查询: {user_query}SQL语句:"""- 动态构建数据库结构描述
- 创建清晰的提示词,指导模型生成正确的SQL
- 明确要求只输出SQL语句,简化结果解析
1.5 调用Qwen API
# 调用通义千问API
response = Generation.call(model='qwen-turbo', # 使用qwen-turbo以节省成本messages=[{'role': 'user', 'content': prompt}],temperature=0.1
)# 提取SQL语句
sql = response.output.choices[0].message.content.strip()- 此处使用qwen-turbo模型,模型按需选择
- 设置低温度值(0.1)确保输出的确定性
- 从API响应中提取SQL语句
1.6 执行查询与安全措施
def execute_query(self, sql):"""执行SQL查询并返回结果"""# 安全检查:只允许SELECT查询if not sql.lower().strip().startswith('select'):return {"error": "只允许执行SELECT查询"}try:connection = pymysql.connect(**self.db_config)with connection.cursor(pymysql.cursors.DictCursor) as cursor:cursor.execute(sql)results = cursor.fetchall()return results- 安全检查:确保只执行SELECT查询,防止数据修改
- 使用DictCursor返回字典形式的结果,更易处理
- 包含异常处理,确保数据库连接正确关闭
2. 输出结果
==================================================
用户查询: 显示所有用户
Qwen API响应: {"status_code": 200, "request_id": "05aeba62-9038-415d-be08-0b47a66e7463", "code": "", "message": "", "output": {"text": "SELECT * FROM users;", "finish_reason": "stop", "choices": null}, "usage": {"input_tokens": 497, "output_tokens": 5, "total_tokens": 502, "prompt_tokens_details": {"cached_tokens": 256}}}
生成的SQL: SELECT * FROM users;
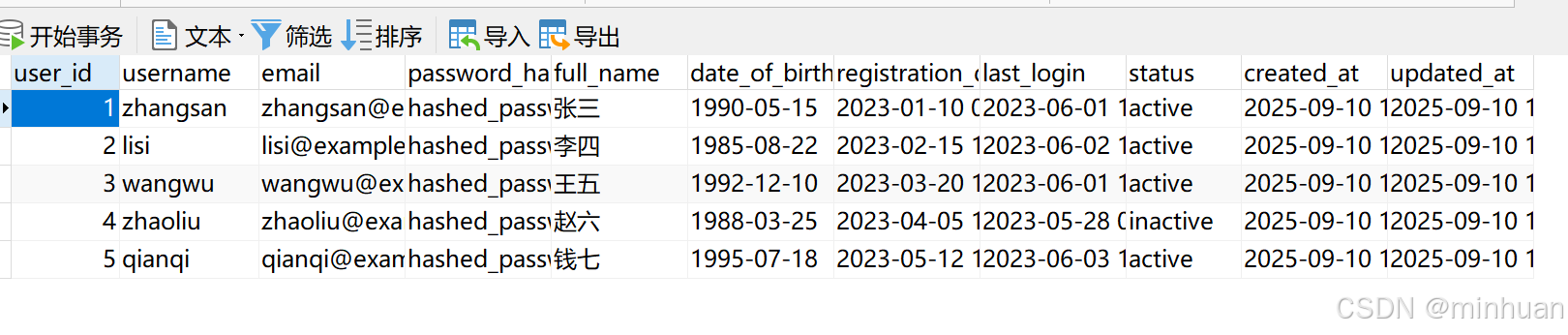
查询结果 (显示前5行):1. {'user_id': 1, 'username': 'zhangsan', 'email': 'zhangsan@example.com', 'password_hash': 'hashed_password_1', 'full_name': '张三', 'date_of_birth': datetime.date(1990, 5, 15), 'registration_date': datetime.datetime(2023, 1, 10, 9, 30), 'last_login': datetime.datetime(2023, 6, 1, 14, 25), 'status': 'active', 'created_at': datetime.datetime(2025, 9, 10, 11, 41, 23), 'updated_at': datetime.datetime(2025, 9, 10, 11, 41, 23)}2. {'user_id': 2, 'username': 'lisi', 'email': 'lisi@example.com', 'password_hash': 'hashed_password_2', 'full_name': '李四', 'date_of_birth': datetime.date(1985, 8, 22), 'registration_date': datetime.datetime(2023, 2, 15, 11, 20), 'last_login': datetime.datetime(2023, 6, 2, 10, 15), 'status': 'active', 'created_at': datetime.datetime(2025, 9, 10, 11, 41, 23), 'updated_at': datetime.datetime(2025, 9, 10, 11, 41, 23)}3. {'user_id': 3, 'username': 'wangwu', 'email': 'wangwu@example.com', 'password_hash': 'hashed_password_3', 'full_name': '王五', 'date_of_birth': datetime.date(1992, 12, 10), 'registration_date': datetime.datetime(2023, 3, 20, 14, 45), 'last_login': datetime.datetime(2023, 6, 1, 16, 30), 'status': 'active',
'created_at': datetime.datetime(2025, 9, 10, 11, 41, 23), 'updated_at': datetime.datetime(2025, 9, 10, 11, 41, 23)}4. {'user_id': 4, 'username': 'zhaoliu', 'email': 'zhaoliu@example.com', 'password_hash': 'hashed_password_4', 'full_name': '赵六', 'date_of_birth': datetime.date(1988, 3, 25), 'registration_date': datetime.datetime(2023, 4, 5, 10, 10), 'last_login': datetime.datetime(2023, 5, 28, 9, 45), 'status': 'inactive', 'created_at': datetime.datetime(2025, 9, 10, 11, 41, 23), 'updated_at': datetime.datetime(2025, 9, 10, 11, 41, 23)}5. {'user_id': 5, 'username': 'qianqi', 'email': 'qianqi@example.com', 'password_hash': 'hashed_password_5', 'full_name': '钱七', 'date_of_birth': datetime.date(1995, 7, 18), 'registration_date': datetime.datetime(2023, 5, 12, 16, 20), 'last_login': datetime.datetime(2023, 6, 3, 11, 30), 'status': 'active', 'created_at': datetime.datetime(2025, 9, 10, 11, 41, 23), 'updated_at': datetime.datetime(2025, 9, 10, 11, 41, 23)}
====================================================================================================
用户查询: 查询订单数量最多的前5个产品
Qwen API响应: {"status_code": 200, "request_id": "93bbb16a-41ca-4610-ab7a-95ddd483f2bd", "code": "", "message": "", "output": {"text": "SELECT p.product_id, p.product_name, COUNT(oi.order_item_id) AS order_count\nFROM products p\nJOIN order_items oi ON p.product_id = oi.product_id\nGROUP BY p.product_id, p.product_name\nORDER BY order_count DESC\nLIMIT 5;", "finish_reason": "stop", "choices": null}, "usage": {"input_tokens": 501, "output_tokens": 57, "total_tokens": 558, "prompt_tokens_details": {"cached_tokens": 0}}}
生成的SQL: SELECT p.product_id, p.product_name, COUNT(oi.order_item_id) AS order_count
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
GROUP BY p.product_id, p.product_name
ORDER BY order_count DESC
LIMIT 5;
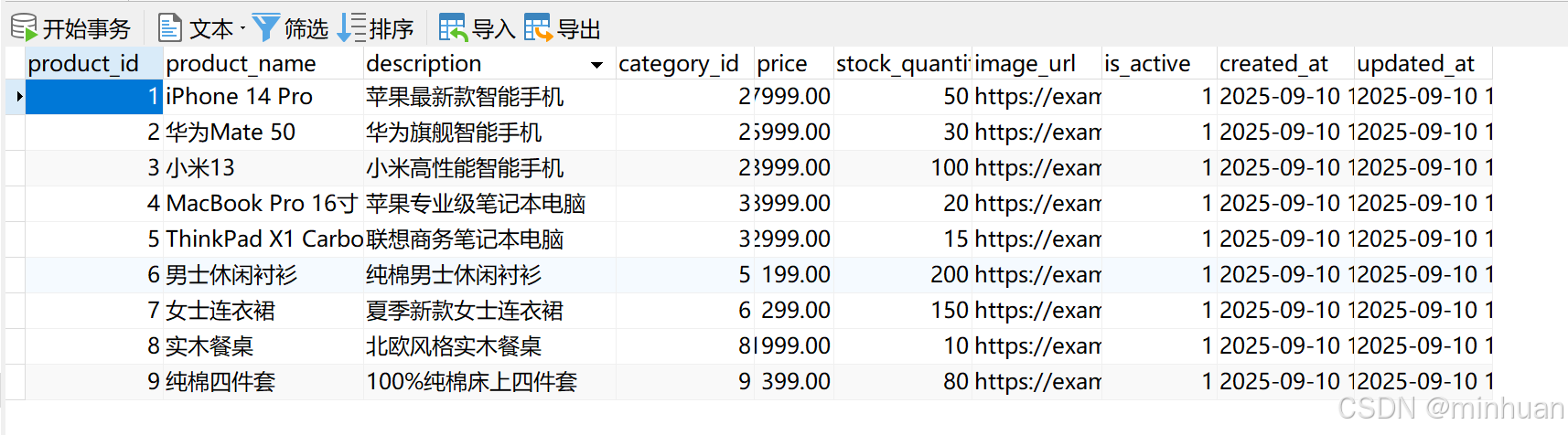
查询结果 (显示前5行):1. {'product_id': 6, 'product_name': '男士休闲衬衫', 'order_count': 2}2. {'product_id': 1, 'product_name': 'iPhone 14 Pro', 'order_count': 1}3. {'product_id': 2, 'product_name': '华为Mate 50', 'order_count': 1}4. {'product_id': 3, 'product_name': '小米13', 'order_count': 1}5. {'product_id': 7, 'product_name': '女士连衣裙', 'order_count': 1}
==================================================表数据参考:USERS (用户表)
products (产品表)
3. 执行流程
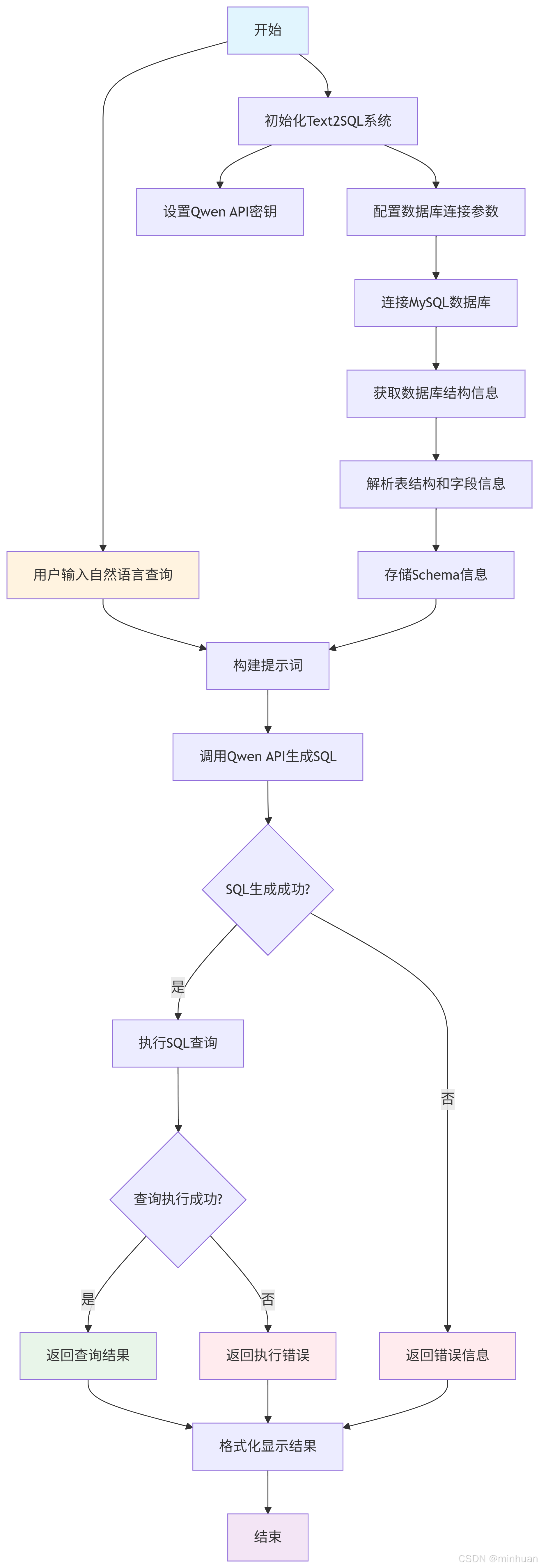
3.1 流程图
3.2 流程说明
1. 系统初始化
- 初始化Text2SQL系统:创建系统实例
- 配置数据库连接参数:设置MySQL数据库的主机、用户名、密码等信息
- 设置Qwen API密钥:配置通义千问API的访问密钥
2. 数据库结构获取
- 连接MySQL数据库:使用pymysql建立数据库连接
- 获取数据库结构信息:执行SHOW TABLES和DESCRIBE table_name查询
- 解析表结构和字段信息:提取表名、字段名、数据类型等信息
- 存储Schema信息:将数据库结构信息保存到内存中供后续使用
3. 查询处理
- 用户输入自然语言查询:接收用户提出的问题,如"显示所有用户"
- 构建提示词:将数据库结构信息和用户查询组合成适合Qwen模型的提示词
- 调用Qwen API生成SQL:向通义千问API发送请求,获取生成的SQL语句
4. 执行与结果处理
- SQL生成成功判断:检查API是否成功返回有效的SQL语句
- 执行SQL查询:在MySQL数据库上执行生成的SQL语句
- 查询执行成功判断:检查SQL执行是否成功
- 返回查询结果:将数据库查询结果返回给用户
- 返回错误信息:处理SQL生成或执行过程中的错误
- 格式化显示结果:将结果以用户友好的方式呈现
5. 异常处理流程
- SQL生成失败:当Qwen API无法生成有效的SQL时,直接返回错误信息
- 查询执行失败:当SQL执行出错时(如语法错误、权限问题等),返回执行错误信息
七、总结
Text2SQL 技术通过大语言模型的能力,打破了技术语言与业务需求之间的障碍,让数据查询变得更加直观和高效。这种技术不仅提升了数据使用的便利性,也让用户能够用日常语言与数据库交互,无需掌握专业的 SQL 语法。
随着大语言模型能力的不断提升,Schema管理模块的重要性将更加凸显。未来的发展方向包括更加智能的关系推理、基于实际查询模式的自适应优化、以及跨数据源的统一schema管理等。这个模块的成熟度将在很大程度上决定Text2SQL技术在企业环境中的落地效果和应用范围。
Text2SQL 集成 Function Calling 示例展示了如何将自然语言查询转换为数据库操作的核心原理。通过 Function Calling,我们可以让大模型专注于理解用户意图和生成结构化参数,而将实际的数据库操作交给应用程序控制,从而提高系统的安全性、可靠性和灵活性。
附录一:Text2SQL 集成 Function Calling完整代码
import dashscope
from dashscope import Generation
import json
import os# 设置通义千问API密钥
dashscope.api_key = os.environ.get('DASHSCOPE_API_KEY')# 定义可用的函数
functions = [{"name": "execute_sql_query","description": "执行SQL查询并返回结果","parameters": {"type": "object","properties": {"sql": {"type": "string","description": "要执行的SQL查询语句"}},"required": ["sql"]}}
]# 模拟的数据库表结构信息
database_schema = """
数据库中有以下表:
1. 用户表(users): 包含id, name, email, city字段
2. 订单表(orders): 包含id, user_id, product, amount, order_date字段
3. 产品表(products): 包含id, name, price, category字段
"""def text_to_sql(user_query):"""将自然语言转换为SQL并执行"""try:# 调用通义千问Qwen-Plus模型,支持Function Callingresponse = Generation.call(model='qwen-plus',messages=[{"role": "system", "content": f"你是一个SQL专家。请根据以下数据库结构生成SQL查询:\n{database_schema}"},{"role": "user", "content": user_query}],functions=functions,result_format='message')# 解析模型响应message = response.output.choices[0].messageprint(message)# 检查是否要求调用函数if hasattr(message, 'function_call') and message.function_call:# 检查function_call是对象还是字典if isinstance(message.function_call, dict):function_name = message.function_call.get('name')function_args = json.loads(message.function_call.get('arguments', '{}'))else:try:function_name = message.function_call.namefunction_args = json.loads(message.function_call.arguments)except AttributeError:# 如果访问属性失败,尝试使用字典方式访问function_name = message.function_call.get('name')function_args = json.loads(message.function_call.get('arguments', '{}'))# 执行相应的函数if function_name == "execute_sql_query":return execute_sql_query(function_args["sql"])else:# 如果没有函数调用,尝试直接提取SQLsql = extract_sql_from_text(message.content)if sql:return execute_sql_query(sql, "从模型响应中提取SQL")else:return "未能生成合适的SQL查询"except Exception as e:return f"API调用失败: {str(e)}"def extract_sql_from_text(text):"""从文本中提取SQL语句"""import re# 查找SELECT语句select_pattern = r"SELECT\s+.*?FROM\s+.*?(?:WHERE\s+.*?)?(?:ORDER BY\s+.*?)?(?:LIMIT\s+.*?)?;?"matches = re.findall(select_pattern, text, re.IGNORECASE | re.DOTALL)if matches:return matches[0].strip()# 查找其他类型的SQL语句other_patterns = [r"INSERT INTO\s+.*?VALUES\s*\(.*?\);?",r"UPDATE\s+.*?SET\s+.*?WHERE\s+.*?;?",r"DELETE FROM\s+.*?WHERE\s+.*?;?"]for pattern in other_patterns:matches = re.findall(pattern, text, re.IGNORECASE | re.DOTALL)if matches:return matches[0].strip()return Nonedef execute_sql_query(sql, thought=""):"""执行SQL查询的函数"""# 在实际应用中,这里会连接真实数据库执行查询# 这里只是返回模拟结果print(f"思考过程: {thought}")print(f"执行的SQL: {sql}")# 模拟不同查询的结果sql_lower = sql.lower()if "select name, city from users" in sql_lower:return [{"name": "张三", "city": "北京"},{"name": "李四", "city": "上海"},{"name": "王五", "city": "广州"}]elif "select product, amount from orders" in sql_lower:return [{"product": "笔记本电脑", "amount": 2},{"product": "智能手机", "amount": 5},{"product": "平板电脑", "amount": 3}]elif "select * from users" in sql_lower:return [{"id": 1, "name": "张三", "email": "zhangsan@example.com", "city": "北京"},{"id": 2, "name": "李四", "email": "lisi@example.com", "city": "上海"},{"id": 3, "name": "王五", "email": "wangwu@example.com", "city": "广州"}]elif "select name, price from products" in sql_lower:return [{"name": "笔记本电脑", "price": 5999.00},{"name": "智能手机", "price": 3999.00},{"name": "平板电脑", "price": 2999.00}]elif "delete" in sql_lower:return [{"message": "删除操作已执行", "rows_affected": 5}]elif "update" in sql_lower:return [{"message": "更新操作已执行", "rows_affected": 3}]elif "insert" in sql_lower:return [{"message": "插入操作已执行", "rows_affected": 1}]else:return [{"message": "查询执行成功", "rows_affected": 10}]# 测试示例
if __name__ == "__main__":# 示例查询queries = ["显示所有用户的姓名和所在城市","查询订单中的产品和数量","删除所有测试用户","显示所有产品名称和价格","查询北京的用户"]for query in queries:print(f"\n{'='*50}")print(f"用户查询: {query}")result = text_to_sql(query)print(f"查询结果: {result}")print(f"{'='*50}")附录二:Text2SQL 从本地MySql数据库读取完整代码
import os
import json
import pymysql
import dashscope
from dashscope import Generation# 设置通义千问API密钥
dashscope.api_key = os.environ.get('DASHSCOPE_API_KEY')class SimpleText2SQL:def __init__(self, db_config):self.db_config = db_configself.schema_info = Nonedef get_database_schema(self):"""获取数据库表结构信息"""try:connection = pymysql.connect(**self.db_config)schema = {}with connection.cursor() as cursor:# 获取所有表名cursor.execute("SHOW TABLES")tables = cursor.fetchall()for table in tables:table_name = table[0]schema[table_name] = {"columns": []}# 获取表的列信息cursor.execute(f"DESCRIBE {table_name}")columns = cursor.fetchall()for col in columns:schema[table_name]["columns"].append({"name": col[0],"type": col[1],"nullable": col[2],"key": col[3],"default": col[4],"extra": col[5]})self.schema_info = schemareturn schemaexcept Exception as e:print(f"获取数据库结构失败: {str(e)}")return Nonefinally:if connection:connection.close()def generate_sql(self, user_query):"""使用Qwen生成SQL查询"""if not self.schema_info:self.get_database_schema()# 构建schema描述schema_desc = "数据库表结构:\n"for table_name, table_info in self.schema_info.items():schema_desc += f"- {table_name}: "schema_desc += ", ".join([f"{col['name']}({col['type']})" for col in table_info["columns"]])schema_desc += "\n"# 构建提示词prompt = f"""你是一个SQL专家。请根据以下数据库结构,将用户的自然语言查询转换为MySQL SQL语句。{schema_desc}请只输出SQL语句,不要输出其他任何内容。用户查询: {user_query}SQL语句:"""try:# 调用通义千问APIresponse = Generation.call(model='qwen-turbo', # 使用qwen-turbo以节省成本messages=[{'role': 'user', 'content': prompt}],temperature=0.1)print(f"Qwen API响应: {response}")# 检查API响应是否有效 or not response.output.choicesif not response or not hasattr(response, 'output') :print(f"API返回无效响应: {response}")return Nonetry:# 提取SQL语句# sql = response.output.choices[0].message.content.strip()sql = response.output.text.strip()# 清理SQL语句(移除可能的代码标记)if sql.startswith('```sql'):sql = sql[6:]if sql.startswith('```'):sql = sql[3:]if sql.endswith('```'):sql = sql[:-3]except Exception as e:print(f"解析API响应失败: {str(e)}")return Nonereturn sql.strip()except Exception as e:print(f"生成SQL失败: {str(e)}")return Nonedef execute_query(self, sql):"""执行SQL查询并返回结果"""# 安全检查:只允许SELECT查询if not sql.lower().strip().startswith('select'):return {"error": "只允许执行SELECT查询"}try:connection = pymysql.connect(**self.db_config)with connection.cursor(pymysql.cursors.DictCursor) as cursor:cursor.execute(sql)results = cursor.fetchall()return resultsexcept Exception as e:return {"error": f"执行查询失败: {str(e)}"}finally:if connection:connection.close()def query(self, user_query):"""处理用户查询的完整流程"""print(f"用户查询: {user_query}")# 生成SQLsql = self.generate_sql(user_query)if not sql:return {"error": "无法生成SQL语句"}print(f"生成的SQL: {sql}")# 执行查询result = self.execute_query(sql)return result# 使用示例
if __name__ == "__main__":# 数据库配置db_config = {"host": "localhost","user": "root","password": "Aa123456!","database": "ecommerce_db","charset": "utf8mb4"}# 初始化Text2SQL系统text2sql = SimpleText2SQL(db_config)# 示例查询queries = ["显示所有用户","查询订单数量最多的前5个产品","查找最近一个月注册的用户","统计每个城市的用户数量"]for query in queries:print("\n" + "="*50)result = text2sql.query(query)if "error" in result:print(f"错误: {result['error']}")else:print(f"查询结果 (显示前5行):")for i, row in enumerate(result[:5]):print(f" {i+1}. {row}")print("="*50)