从ASID入手学习MySQL的事务机制
文章目录
-
目录
前言
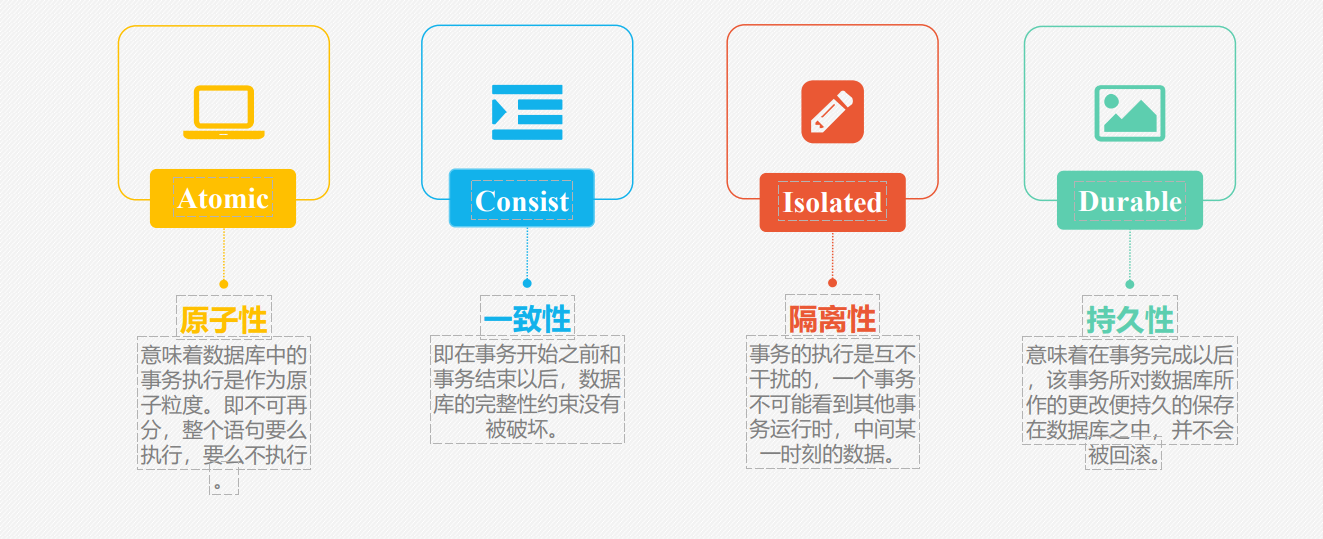
一、事务的四大特性(ACID)
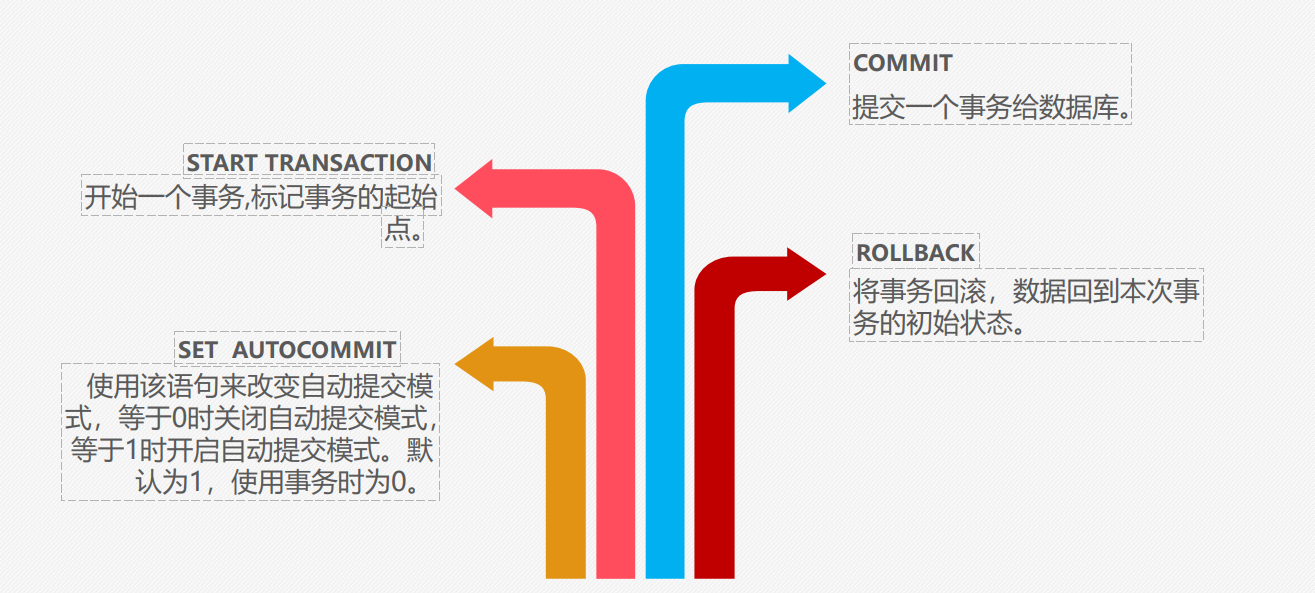
二、事务的生命周期(SQL 操作)
1. 开启事务
2. 提交事务(永久生效)
3. 回滚事务(放弃所有操作)
4. 保存点(部分回滚)
三、事务的隔离级别(解决并发问题)
关键概念解释:
MySQL 的默认隔离级别:
四、事务的实现原理(核心日志)
1. redo log(重做日志)—— 保障持久性
2. undo log(回滚日志)—— 保障原子性
五、注意事项
总结:
前言
当我们在后端开发中,几乎所有涉及 “关键业务数据” 的场景(比如电商订单创建、金融转账、支付对账),都绕不开一个核心诉求 ——数据一致性。想象这样一个场景:用户下单支付时,系统扣减了用户余额,却因网络波动导致订单状态未更新;或是并发下单时,多笔请求同时修改库存,最终出现 “超卖” 漏洞。这些问题的根源,往往是缺乏对数据库操作的 “原子性控制”—— 而 MySQL 的事务机制,正是解决这类问题的 “底层保障”。
所以 对于开发者而言,我们或许知道 “用 START TRANSACTION 开启事务,COMMIT 提交、ROLLBACK 回滚”,但面对 “为什么事务能保证不丢数据?”“并发时脏读、幻读怎么解决?”“InnoDB 的 redo log 和 undo log 到底起什么作用?” 这类深层问题时,很多人可能只停留在 “知其然” 的阶段。尤其是在高并发业务中,不当的事务隔离级别选择、未优化的长事务,可能会引发锁等待、性能瓶颈甚至数据异常,这些都需要我们深入理解事务的底层逻辑才能规避。
我本篇文章将从 “事务的核心价值” 切入,一步步拆解 ACID 特性的实现原理、4 种隔离级别的差异与适用场景、InnoDB 引擎如何通过 redo/undo log 保障事务安全,同时结合实战中的常见问题(如长事务风险、隔离级别选择)给出建议。无论你是刚接触数据库的新手,还是需要解决并发问题的资深开发者,希望通过这篇文章,能让你彻底搞懂 MySQL 事务机制的 “底层逻辑” 与 “实战用法”,让业务代码中的数据操作更可靠、更高效。
首先呢,MySQL 的事务机制是数据库保证数据一致性的核心手段,它将一组 SQL 操作封装成一个不可分割的执行单元 —— 要么全部成功执行(提交),要么全部失败(回滚),避免因部分操作成功、部分失败导致的数据混乱(如转账时 “扣钱成功但收钱失败”)。
一、事务的四大特性(ACID)
事务的核心价值由 ACID 四大特性保障,这是理解事务机制的基础:
| 特性 | 含义 | MySQL 如何保证 |
|---|---|---|
| 原子性(Atomicity) | 事务中的所有操作是一个整体,要么全部执行成功,要么全部失败回滚,无中间状态。 | 依赖undo log(回滚日志):记录操作的反向逻辑(如插入→删除、更新→恢复旧值),失败时通过 undo log 撤销已执行的操作。 |
| 一致性(Consistency) | 事务执行前后,数据库从一个 “合法状态” 切换到另一个 “合法状态”(数据符合业务规则)。 | 由原子性、隔离性、持久性共同保障,同时依赖业务逻辑(如转账时 “总金额不变”)。 |
| 隔离性(Isolation) | 多个事务并发执行时,彼此的操作互不干扰,仿佛在独立执行。 | 依赖锁机制(控制并发修改)和MVCC(多版本并发控制)(控制并发读取),通过 “隔离级别” 调整干扰程度。 |
| 持久性(Durability) | 事务提交后,修改会永久保存到数据库,即使系统崩溃也不会丢失。 | 依赖redo log(重做日志):事务执行时先写入 redo log(内存 + 磁盘),提交后确保日志持久化,崩溃后可通过 redo log 恢复。 |
二、事务的生命周期(SQL 操作)
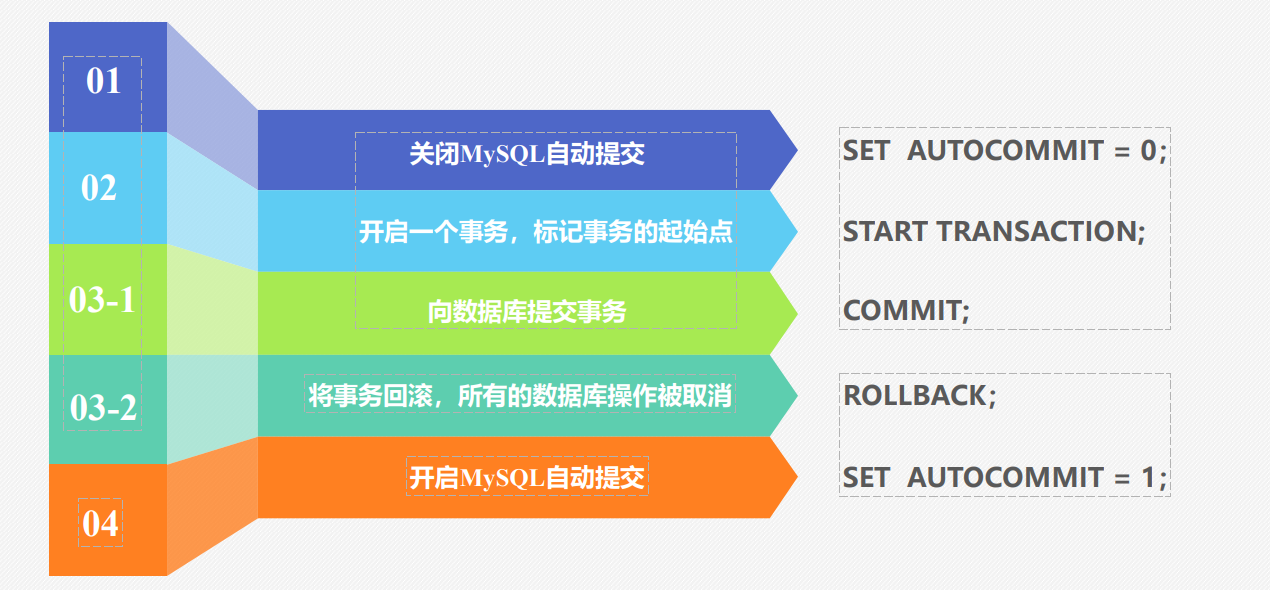
MySQL 中通过 SQL 命令手动控制事务的开始、提交、回滚,默认是 “自动提交模式”(每条 SQL 自动作为一个事务),可通过以下命令显式管理:
1. 开启事务
-- 方式1:显式开启
START TRANSACTION; -- 或 BEGIN;-- 方式2:关闭自动提交(后续SQL需手动提交)
SET autocommit = 0; -- 0:关闭自动提交;1:开启(默认)
2. 提交事务(永久生效)
COMMIT; -- 事务中所有操作生效,数据持久化
3. 回滚事务(放弃所有操作)
ROLLBACK; -- 撤销事务中所有已执行的操作,恢复到事务开始前的状态
4. 保存点(部分回滚)
复杂事务中可设置 “保存点”,回滚时可指定回滚到某个保存点(而非全部):
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1; -- 操作1
SAVEPOINT s1; -- 设置保存点s1
UPDATE account SET balance = balance + 100 WHERE id = 2; -- 操作2
ROLLBACK TO s1; -- 回滚到s1,仅撤销“操作2”,保留“操作1”
COMMIT; -- 最终仅“操作1”生效
三、事务的隔离级别(解决并发问题)
当多个事务同时操作同一批数据时,可能出现脏读、不可重复读、幻读等问题。MySQL 通过 “隔离级别” 控制这些问题的发生,SQL 标准定义了 4 种隔离级别,级别越高,一致性越强,但性能越低:
| 隔离级别 | 含义 | 解决的问题 | 未解决的问题 | MySQL 默认支持? |
|---|---|---|---|---|
| 读未提交(Read Uncommitted) | 一个事务可读取另一个未提交的事务的修改。 | 无 | 脏读、不可重复读、幻读 | 支持 |
| 读已提交(Read Committed) | 一个事务只能读取另一个已提交的事务的修改。 | 脏读 | 不可重复读、幻读 | 支持(如 Oracle 默认) |
| 可重复读(Repeatable Read) | 事务执行期间,多次读取同一数据的结果始终一致(不受其他事务影响)。 | 脏读、不可重复读 | 部分幻读(MySQL 已解决) | 支持(MySQL 默认) |
| 串行化(Serializable) | 事务串行执行(一个接一个),完全禁止并发。 | 所有问题(脏读、不可重复读、幻读) | 无,但性能极差 | 支持 |
关键概念解释:
-
脏读:事务 A 读取了事务 B 未提交的修改,若 B 回滚,A 读到的数据是 “无效的”。
例:B 扣减余额 100(未提交),A 读取到扣减后余额,随后 B 回滚,A 读到的是 “脏数据”。 -
不可重复读:事务 A 多次读取同一数据,期间事务 B 修改并提交了该数据,导致 A 两次读取结果不一致。
例:A 第一次读余额为 1000,B 修改为 800 并提交,A 第二次读变为 800,前后不一致。 -
幻读:事务 A 按条件读取数据,期间事务 B 新增 / 删除了符合条件的数据,导致 A 再次读取时 “多了 / 少了” 记录。
例:A 查询 “余额> 0” 的用户有 10 人,B 新增 1 个符合条件的用户并提交,A 再次查询变为 11 人,像出现了 “幻觉”。
MySQL 的默认隔离级别:
MySQL 默认使用可重复读(Repeatable Read),且通过 MVCC 机制解决了 “幻读”(与标准不同),是 “一致性” 和 “性能” 的平衡选择。
可通过以下命令查看 / 修改隔离级别:
-- 查看当前隔离级别
SELECT @@transaction_isolation;-- 修改隔离级别(会话级,仅当前连接有效)
SET TRANSACTION ISOLATION LEVEL 隔离级别名称; -- 如:SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
四、事务的实现原理(核心日志)
MySQL 的事务特性依赖两种关键日志实现,以 InnoDB 引擎为例:
1. redo log(重做日志)—— 保障持久性
- 作用:记录事务对数据的 “物理修改”(如 “某页某行修改为某值”),确保事务提交后即使崩溃,重启时能通过 redo log 恢复数据。
- 特点:先写入内存的 “redo log buffer”,再定期刷到磁盘的 “redo log file”(双写机制,防止部分写入),支持 “崩溃恢复”。
2. undo log(回滚日志)—— 保障原子性
- 作用:记录事务对数据的 “逻辑反向操作”(如插入→删除记录、更新→恢复旧值),事务回滚时通过 undo log 撤销已执行的操作。
- 特点:不仅用于回滚,还为 MVCC 提供 “多版本数据”(读取时可访问历史版本)。
五、注意事项
- 存储引擎支持:只有 InnoDB 引擎支持事务,MyISAM、Memory 等引擎不支持(需避免在这些引擎中使用事务)。
- 长事务风险:事务持续时间过长会占用锁资源,导致并发阻塞,还会使 undo log 膨胀(影响性能),应尽量缩短事务时间。
- 自动提交默认开启:默认情况下,每条 SQL 自动作为一个事务(执行后立即 COMMIT),需显式用
START TRANSACTION开启事务批量执行 SQL。
总结:
回顾全文,我们可以从三个维度梳理 MySQL 事务机制的核心逻辑:
1. 核心特性:ACID 是事务的 “契约”
2. 隔离级别:在 “一致性” 与 “性能” 间找平衡
3. 底层支撑:日志与引擎是事务的 “基石”
4. 实战启示:避开事务使用的 “坑”
最后:事务机制的本质是 “业务可靠性的兜底”
MySQL 事务机制看似是数据库的技术细节,实则是后端业务 “容错能力” 的底层保障。无论是避免支付时的 “扣钱不到账”,还是防止并发下单的 “库存超卖”,事务都在默默承担着 “数据守护者” 的角色。对于开发者而言,掌握事务的原理与实战技巧,不仅能解决当下的业务问题,更能在设计高可靠系统时,从 “数据层” 提前规避风险 —— 这正是深入理解 MySQL 事务机制的最终价值。