算力资源碎片化整合:虚拟化GPU切片技术实践
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,80G大显存,按量计费,灵活弹性,顶级配置,学生更享专属优惠。
引言:GPU资源碎片化挑战与解决之道
随着人工智能和深度学习应用的爆炸式增长,GPU计算资源已成为企业和科研机构的核心资产。然而,传统的GPU分配方式往往导致严重的资源碎片化问题:一方面,大型GPU集群中的单个GPU算力过剩,小型任务无法充分利用;另一方面,多个用户或任务竞争有限GPU资源,导致排队等待和资源闲置并存。
虚拟化GPU切片技术正是解决这一挑战的关键方案。通过NVIDIA的Multi-Instance GPU(MIG)技术和虚拟GPU(vGPU)时间片轮转调度算法,我们可以将物理GPU资源精细分割和智能调度,实现算力资源的高效整合与利用。本文将深入探讨MIG设备多租户分割和vGPU时间片轮转调度的技术原理与实践方案,为构建高效的GPU资源池化平台提供完整指南。
第一部分:MIG技术深度解析与实践
1.1 MIG架构与技术原理
NVIDIA的Multi-Instance GPU(MIG)技术允许将单个物理GPU分割为多个独立的GPU实例,每个实例都具有独立的内存、缓存和计算单元。这种硬件级隔离为多租户环境提供了安全可靠的GPU资源分割方案。
1.1.1 MIG支持架构与规格
目前支持MIG技术的GPU架构包括:
- NVIDIA A100 Tensor Core GPU
- NVIDIA H100 Tensor Core GPU
- NVIDIA A30 Tensor Core GPU
不同GPU型号的MIG分割能力:
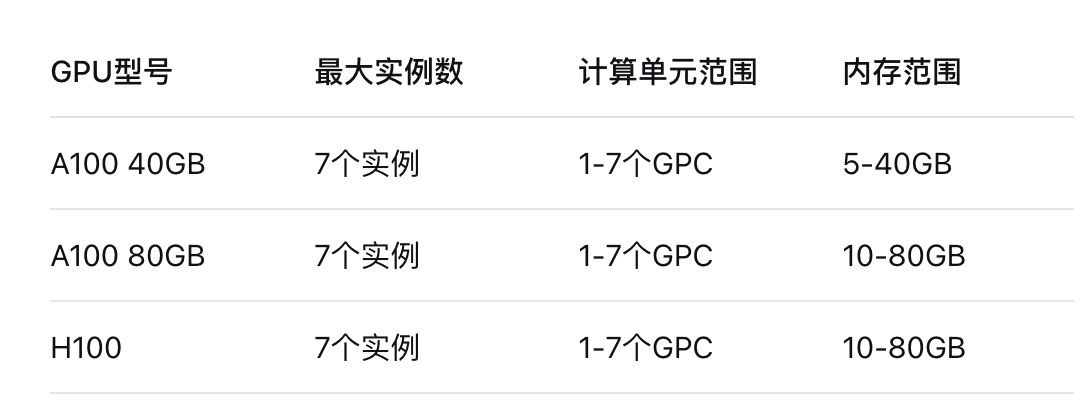
1.1.2 MIG设备配置与管理
# 检查MIG支持状态
nvidia-smi mig -lgi# 启用MIG模式
sudo nvidia-smi -mig 1# 查看可用的MIG设备配置
nvidia-smi mig -lgipp# 创建MIG实例
# 创建1g.5gb配置的实例
sudo nvidia-smi mig -cgi 1g.5gb -C# 查看已创建的MIG实例
nvidia-smi mig -lgi# 销毁MIG实例
sudo nvidia-smi mig -dgi -i 0
1.2 MIG多租户隔离实践
1.2.1 基于cgroups的资源隔离
# 创建cgroup用于MIG实例资源控制
sudo cgcreate -g memory,cpu:gpu_instance_1# 设置内存限制
sudo cgset -r memory.limit_in_bytes=5G gpu_instance_1# 设置CPU亲和性
sudo cgset -r cpuset.cpus=0-7 gpu_instance_1# 将进程绑定到cgroup
sudo cgexec -g memory,cpu:gpu_instance_1 python training_script.py
1.2.2 Docker容器集成方案
# Dockerfile for MIG enabled container
FROM nvidia/cuda:11.8.0-base-ubuntu20.04# 安装必要的工具
RUN apt-get update && apt-get install -y \cgroup-tools \nvidia-container-toolkit \&& rm -rf /var/lib/apt/lists/*# 配置容器启动脚本
COPY entrypoint.sh /usr/local/bin/
RUN chmod +x /usr/local/bin/entrypoint.shENTRYPOINT ["entrypoint.sh"]
#!/bin/bash
# entrypoint.sh# 获取分配的MIG实例
MIG_INSTANCE=${NVIDIA_MIG_INSTANCE:-"1g.5gb"}# 配置cgroup资源限制
cgcreate -g memory,cpu:gpu_container
cgset -r memory.limit_in_bytes=5G gpu_container
cgset -r cpuset.cpus=0-7 gpu_container# 在cgroup中执行应用
cgexec -g memory,cpu:gpu_container "$@"
1.3 MIG监控与运维
1.3.1 实时监控方案
#!/usr/bin/env python3
# mig_monitor.pyimport subprocess
import json
import time
from datetime import datetimeclass MIGMonitor:def __init__(self, check_interval=30):self.check_interval = check_intervalself.metrics_history = []def get_mig_status(self):"""获取MIG设备状态信息"""try:result = subprocess.run(['nvidia-smi', 'mig', '-i', '0', '--query-gpu=index,utilization.gpu,memory.used','--format=csv,noheader,nounits'], capture_output=True, text=True, timeout=10)if result.returncode == 0:return self.parse_mig_output(result.stdout)else:return Noneexcept Exception as e:print(f"获取MIG状态失败: {e}")return Nonedef parse_mig_output(self, output):"""解析MIG状态输出"""instances = []for line in output.strip().split('\n'):if line:parts = line.split(',')if len(parts) >= 3:instance = {'index': parts[0].strip(),'gpu_utilization': float(parts[1].strip()),'memory_used': float(parts[2].strip()),'timestamp': datetime.now().isoformat()}instances.append(instance)return instancesdef start_monitoring(self):"""启动监控循环"""print("启动MIG监控...")try:while True:status = self.get_mig_status()if status:self.metrics_history.extend(status)self.check_anomalies(status)time.sleep(self.check_interval)except KeyboardInterrupt:print("停止监控")def check_anomalies(self, current_status):"""检查异常情况"""for instance in current_status:if instance['gpu_utilization'] > 95:print(f"警告: 实例 {instance['index']} GPU使用率过高: {instance['gpu_utilization']}%")if instance['memory_used'] > 4500: # 4.5GB for 5GB instanceprint(f"警告: 实例 {instance['index']} 内存使用接近上限: {instance['memory_used']}MB")if __name__ == "__main__":monitor = MIGMonitor(check_interval=30)monitor.start_monitoring()
第二部分:vGPU时间片轮转调度算法
2.1 vGPU调度架构设计
vGPU时间片轮转调度通过在多个虚拟机或容器间共享物理GPU资源,为每个vGPU实例分配时间片来实现公平调度。
2.1.1 调度系统架构
+-----------------------+
| vGPU调度器 |
| |
| +-----------------+ |
| | 时间片分配器 | |
| +-----------------+ |
| |
| +-----------------+ |
| | 优先级管理器 | |
| +-----------------+ |
| |
| +-----------------+ |
| | QoS控制器 | |
| +-----------------+ |
+-----------------------+|v
+-----------------------+
| vGPU驱动层 |
| |
| +-----------------+ |
| | 物理GPU资源池 | |
| +-----------------+ |
+-----------------------+
2.1.2 基础调度算法实现
#!/usr/bin/env python3
# vgpu_scheduler.pyimport threading
import time
from enum import Enum
from dataclasses import dataclass
from typing import List, Dict
from queue import PriorityQueueclass TaskPriority(Enum):HIGH = 0NORMAL = 1LOW = 2@dataclass
class vGPUInstance:instance_id: strpriority: TaskPrioritytime_slice: int # 毫秒last_executed: floattotal_executed: floatclass vGPUScheduler:def __init__(self, time_quantum=50): # 默认时间量子50msself.time_quantum = time_quantumself.ready_queue = PriorityQueue()self.running_instance = Noneself.lock = threading.Lock()self.scheduler_thread = Noneself.running = False# 实例状态跟踪self.instances: Dict[str, vGPUInstance] = {}def add_instance(self, instance_id: str, priority: TaskPriority):"""添加vGPU实例到调度队列"""with self.lock:if instance_id not in self.instances:instance = vGPUInstance(instance_id=instance_id,priority=priority,time_slice=self.calculate_time_slice(priority),last_executed=0,total_executed=0)self.instances[instance_id] = instanceself.ready_queue.put((priority.value, time.time(), instance))print(f"添加实例 {instance_id}, 优先级 {priority}")def calculate_time_slice(self, priority: TaskPriority) -> int:"""根据优先级计算时间片长度"""time_slices = {TaskPriority.HIGH: 100, # 100msTaskPriority.NORMAL: 50, # 50msTaskPriority.LOW: 25 # 25ms}return time_slices[priority]def schedule(self):"""调度器主循环"""while self.running:with self.lock:if not self.ready_queue.empty():# 获取下一个要调度的实例priority, timestamp, instance = self.ready_queue.get()if self.running_instance:# 保存当前运行实例状态self.save_instance_state(self.running_instance)# 切换到新实例self.running_instance = instanceself.execute_instance(instance)# 将当前实例重新加入队列if instance.time_slice > 0:self.ready_queue.put((instance.priority.value, time.time(), instance))time.sleep(0.001) # 降低CPU使用率def execute_instance(self, instance: vGPUInstance):"""执行vGPU实例"""start_time = time.time()print(f"执行实例 {instance.instance_id}, 时间片 {instance.time_slice}ms")# 模拟执行时间time.sleep(instance.time_slice / 1000.0)# 更新执行时间统计execution_time = (time.time() - start_time) * 1000 # 转换为毫秒instance.total_executed += execution_timeinstance.last_executed = time.time()def save_instance_state(self, instance: vGPUInstance):"""保存实例状态"""# 在实际实现中,这里会保存GPU状态上下文print(f"保存实例 {instance.instance_id} 的状态")def start(self):"""启动调度器"""self.running = Trueself.scheduler_thread = threading.Thread(target=self.schedule)self.scheduler_thread.daemon = Trueself.scheduler_thread.start()print("vGPU调度器已启动")def stop(self):"""停止调度器"""self.running = Falseif self.scheduler_thread:self.scheduler_thread.join()print("vGPU调度器已停止")# 使用示例
if __name__ == "__main__":scheduler = vGPUScheduler()# 添加不同优先级的实例scheduler.add_instance("vm1", TaskPriority.HIGH)scheduler.add_instance("vm2", TaskPriority.NORMAL)scheduler.add_instance("vm3", TaskPriority.LOW)scheduler.start()# 运行一段时间try:time.sleep(10)except KeyboardInterrupt:passfinally:scheduler.stop()
2.2 高级调度策略
2.2.1 基于负载的自适应调度
#!/usr/bin/env python3
# adaptive_scheduler.pyclass AdaptivevGPUScheduler(vGPUScheduler):def __init__(self, time_quantum=50):super().__init__(time_quantum)self.load_history = {}self.adjustment_interval = 5 # 每5秒调整一次self.last_adjustment = time.time()def monitor_load(self):"""监控各个实例的负载情况"""current_time = time.time()if current_time - self.last_adjustment >= self.adjustment_interval:self.adjust_time_slices_based_on_load()self.last_adjustment = current_timedef adjust_time_slices_based_on_load(self):"""根据负载情况调整时间片"""with self.lock:total_utilization = sum(inst.total_executed for inst in self.instances.values())for instance in self.instances.values():if total_utilization > 0:utilization_ratio = instance.total_executed / total_utilization# 根据利用率调整时间片if utilization_ratio > 0.7: # 高利用率new_slice = min(instance.time_slice * 1.2, 200) # 增加时间片,上限200mselif utilization_ratio < 0.3: # 低利用率new_slice = max(instance.time_slice * 0.8, 10) # 减少时间片,下限10mselse:new_slice = instance.time_sliceinstance.time_slice = new_sliceprint(f"调整实例 {instance.instance_id} 时间片为 {new_slice}ms")# 重置统计instance.total_executed = 0def schedule(self):"""重写调度方法加入负载监控"""while self.running:self.monitor_load()super().schedule()
2.2.2 服务质量(QoS)保障机制
#!/usr/bin/env python3
# qos_scheduler.pyclass QoSScheduler(AdaptivevGPUScheduler):def __init__(self, time_quantum=50):super().__init__(time_quantum)self.qos_policies = {}self.violation_count = {}def set_qos_policy(self, instance_id: str, min_slice: int, max_slice: int, guaranteed_throughput: float):"""设置QoS策略"""self.qos_policies[instance_id] = {'min_slice': min_slice,'max_slice': max_slice,'guaranteed_throughput': guaranteed_throughput,'actual_throughput': 0.0}self.violation_count[instance_id] = 0def enforce_qos_policies(self):"""强制执行QoS策略"""current_time = time.time()if current_time - self.last_adjustment >= self.adjustment_interval:self.check_qos_compliance()self.last_adjustment = current_timedef check_qos_compliance(self):"""检查QoS合规性"""for instance_id, policy in self.qos_policies.items():if instance_id in self.instances:instance = self.instances[instance_id]# 计算实际吞吐量 (MB/s)actual_throughput = instance.total_executed / self.adjustment_intervalpolicy['actual_throughput'] = actual_throughput# 检查是否违反QoSif actual_throughput < policy['guaranteed_throughput'] * 0.9:self.violation_count[instance_id] += 1print(f"QoS警告: 实例 {instance_id} 吞吐量低于保证值")# 调整优先级if self.violation_count[instance_id] > 3:self.adjust_instance_priority(instance_id, TaskPriority.HIGH)else:self.violation_count[instance_id] = max(0, self.violation_count[instance_id] - 1)def adjust_instance_priority(self, instance_id: str, new_priority: TaskPriority):"""调整实例优先级"""if instance_id in self.instances:self.instances[instance_id].priority = new_priorityprint(f"调整实例 {instance_id} 优先级为 {new_priority}")def schedule(self):"""重写调度方法加入QoS保障"""while self.running:self.enforce_qos_policies()super().schedule()
第三部分:多租户资源管理与隔离
3.1 租户配额管理
#!/usr/bin/env python3
# tenant_manager.pyfrom typing import Dict, List
from dataclasses import dataclass@dataclass
class TenantQuota:tenant_id: strmax_gpu_instances: intmax_memory_gb: intpriority_level: TaskPriorityguaranteed_throughput: floatclass TenantManager:def __init__(self):self.tenants: Dict[str, TenantQuota] = {}self.tenant_instances: Dict[str, List[str]] = {}self.usage_stats: Dict[str, Dict] = {}def register_tenant(self, tenant_id: str, max_instances: int, max_memory: int, priority: TaskPriority,guaranteed_throughput: float):"""注册新租户"""quota = TenantQuota(tenant_id=tenant_id,max_gpu_instances=max_instances,max_memory_gb=max_memory,priority_level=priority,guaranteed_throughput=guaranteed_throughput)self.tenants[tenant_id] = quotaself.tenant_instances[tenant_id] = []self.usage_stats[tenant_id] = {'current_instances': 0,'current_memory': 0,'total_utilization': 0.0}print(f"注册租户 {tenant_id}")def can_create_instance(self, tenant_id: str, memory_request: int) -> bool:"""检查是否可以创建新实例"""if tenant_id not in self.tenants:return Falsequota = self.tenants[tenant_id]stats = self.usage_stats[tenant_id]# 检查实例数量限制if stats['current_instances'] >= quota.max_gpu_instances:print(f"租户 {tenant_id} 实例数量超过限制")return False# 检查内存限制if stats['current_memory'] + memory_request > quota.max_memory_gb * 1024:print(f"租户 {tenant_id} 内存使用超过限制")return Falsereturn Truedef create_instance(self, tenant_id: str, instance_id: str, memory_request: int, scheduler: vGPUScheduler):"""为租户创建新实例"""if not self.can_create_instance(tenant_id, memory_request):return False# 创建实例quota = self.tenants[tenant_id]scheduler.add_instance(instance_id, quota.priority_level)# 更新使用统计self.tenant_instances[tenant_id].append(instance_id)self.usage_stats[tenant_id]['current_instances'] += 1self.usage_stats[tenant_id]['current_memory'] += memory_requestprint(f"为租户 {tenant_id} 创建实例 {instance_id}")return Truedef remove_instance(self, tenant_id: str, instance_id: str):"""移除租户实例"""if tenant_id in self.tenant_instances and instance_id in self.tenant_instances[tenant_id]:self.tenant_instances[tenant_id].remove(instance_id)# 更新使用统计self.usage_stats[tenant_id]['current_instances'] -= 1# 注意:需要实际的内存使用信息来更新current_memoryprint(f"移除租户 {tenant_id} 的实例 {instance_id}")def get_tenant_usage(self, tenant_id: str) -> Dict:"""获取租户使用情况"""if tenant_id in self.usage_stats:return self.usage_stats[tenant_id].copy()return {}
3.2 安全隔离与监控
3.2.1 安全隔离策略
#!/usr/bin/env python3
# security_isolator.pyimport os
import subprocess
from typing import Listclass SecurityIsolator:def __init__(self):self.isolation_groups = {}def create_isolation_group(self, group_id: str, instances: List[str]):"""创建隔离组"""self.isolation_groups[group_id] = instancesprint(f"创建隔离组 {group_id}, 包含实例: {instances}")def apply_cgroup_isolation(self, instance_id: str, cgroup_params: Dict):"""应用cgroup隔离"""cgroup_path = f"/sys/fs/cgroup/gpu/{instance_id}"# 创建cgroup目录os.makedirs(cgroup_path, exist_ok=True)# 设置cgroup参数for param, value in cgroup_params.items():param_path = os.path.join(cgroup_path, param)with open(param_path, 'w') as f:f.write(str(value))print(f"为实例 {instance_id} 应用cgroup隔离")def apply_namespace_isolation(self, instance_id: str):"""应用命名空间隔离"""# 创建网络命名空间netns_cmd = f"ip netns add netns_{instance_id}"subprocess.run(netns_cmd, shell=True, check=True)# 创建PID命名空间pidns_cmd = f"unshare --pid --fork --mount-proc"print(f"为实例 {instance_id} 创建命名空间隔离")def enforce_security_policies(self, instance_id: str, policies: Dict):"""强制执行安全策略"""# 应用SELinux/AppArmor策略if 'selinux_context' in policies:context = policies['selinux_context']cmd = f"chcon {context} /dev/{instance_id}"subprocess.run(cmd, shell=True, check=True)# 应用能力限制if 'capabilities' in policies:caps = policies['capabilities']cmd = f"setcap {caps} /dev/{instance_id}"subprocess.run(cmd, shell=True, check=True)print(f"为实例 {instance_id} 应用安全策略")
3.2.2 实时安全监控
#!/usr/bin/env python3
# security_monitor.pyimport time
import logging
from datetime import datetimeclass SecurityMonitor:def __init__(self):self.logger = logging.getLogger('SecurityMonitor')self.suspicious_activities = {}self.alert_threshold = 5 # 警报阈值def monitor_instance_behavior(self, instance_id: str, metrics: Dict):"""监控实例行为"""# 检查异常内存访问模式if self.detect_memory_access_anomaly(metrics):self.log_anomaly(instance_id, "异常内存访问模式", metrics)self.increment_suspicion_count(instance_id)# 检查异常计算模式if self.detect_computation_anomaly(metrics):self.log_anomaly(instance_id, "异常计算模式", metrics)self.increment_suspicion_count(instance_id)# 检查是否超过警报阈值if self.suspicious_activities.get(instance_id, 0) >= self.alert_threshold:self.raise_alert(instance_id, "多次检测到可疑行为")def detect_memory_access_anomaly(self, metrics: Dict) -> bool:"""检测内存访问异常"""# 简单的异常检测逻辑if 'memory_access_rate' in metrics:rate = metrics['memory_access_rate']if rate > 1000000: # 1MB/ms的访问率return Truereturn Falsedef detect_computation_anomaly(self, metrics: Dict) -> bool:"""检测计算异常"""if 'computation_rate' in metrics:rate = metrics['computation_rate']if rate > 5000000: # 异常高的计算率return Truereturn Falsedef increment_suspicion_count(self, instance_id: str):"""增加可疑行为计数"""current_count = self.suspicious_activities.get(instance_id, 0)self.suspicious_activities[instance_id] = current_count + 1def log_anomaly(self, instance_id: str, anomaly_type: str, metrics: Dict):"""记录异常事件"""log_entry = {'timestamp': datetime.now().isoformat(),'instance_id': instance_id,'anomaly_type': anomaly_type,'metrics': metrics}self.logger.warning(f"安全异常: {log_entry}")def raise_alert(self, instance_id: str, message: str):"""触发安全警报"""alert = {'timestamp': datetime.now().isoformat(),'instance_id': instance_id,'message': message,'severity': 'HIGH'}self.logger.critical(f"安全警报: {alert}")# 在实际实现中,这里会触发通知和自动响应print(f"安全警报: {alert}")
第四部分:系统集成与性能优化
4.1 完整系统集成方案
4.1.1 系统架构设计
#!/usr/bin/env python3
# gpu_resource_manager.pyfrom typing import Dict, List
import threading
import timeclass GPUResourceManager:def __init__(self):self.scheduler = QoSScheduler()self.tenant_manager = TenantManager()self.security_monitor = SecurityMonitor()self.security_isolator = SecurityIsolator()self.running = Falseself.management_thread = None# 设备状态self.physical_gpus = {}self.mig_instances = {}def initialize_physical_gpus(self):"""初始化物理GPU设备"""# 检测并配置物理GPUprint("初始化物理GPU设备...")# 启用MIG模式self.enable_mig_mode()# 创建MIG实例self.create_mig_instances()def enable_mig_mode(self):"""启用MIG模式"""try:subprocess.run(['nvidia-smi', '-mig', '1'], check=True)print("MIG模式已启用")except subprocess.CalledProcessError as e:print(f"启用MIG模式失败: {e}")def create_mig_instances(self):"""创建MIG实例"""# 配置不同的MIG实例规格mig_configs = [{'type': '1g.5gb', 'count': 2},{'type': '2g.10gb', 'count': 1},{'type': '3g.20gb', 'count': 1}]for config in mig_configs:for i in range(config['count']):instance_id = f"mig_{config['type']}_{i}"try:subprocess.run(['nvidia-smi', 'mig', '-cgi', config['type'], '-C'], check=True)self.mig_instances[instance_id] = {'type': config['type'],'status': 'available'}print(f"创建MIG实例: {instance_id}")except subprocess.CalledProcessError as e:print(f"创建MIG实例失败: {e}")def allocate_instance_to_tenant(self, tenant_id: str, instance_type: str, memory_request: int) -> str:"""分配实例给租户"""# 查找可用实例available_instance = Nonefor instance_id, info in self.mig_instances.items():if info['status'] == 'available' and info['type'] == instance_type:available_instance = instance_idbreakif available_instance:# 创建vGPU实例vgpu_instance_id = f"vgpu_{tenant_id}_{available_instance}"if self.tenant_manager.create_instance(tenant_id, vgpu_instance_id, memory_request, self.scheduler):# 更新实例状态self.mig_instances[available_instance]['status'] = 'allocated'self.mig_instances[available_instance]['tenant'] = tenant_idself.mig_instances[available_instance]['vgpu_instance'] = vgpu_instance_id# 应用安全隔离self.apply_security_isolation(vgpu_instance_id)return vgpu_instance_idreturn Nonedef apply_security_isolation(self, instance_id: str):"""应用安全隔离策略"""# 配置cgroup隔离cgroup_params = {'memory.limit_in_bytes': '5G','cpuset.cpus': '0-7','devices.deny': 'a'}self.security_isolator.apply_cgroup_isolation(instance_id, cgroup_params)# 应用安全策略security_policies = {'selinux_context': 'u:r:vgpu_instance:s0','capabilities': 'cap_net_bind_service+ep'}self.security_isolator.enforce_security_policies(instance_id, security_policies)def start_management(self):"""启动资源管理"""self.running = Trueself.management_thread = threading.Thread(target=self.management_loop)self.management_thread.daemon = Trueself.management_thread.start()# 启动调度器self.scheduler.start()print("GPU资源管理器已启动")def management_loop(self):"""管理循环"""while self.running:# 监控系统状态self.monitor_system_health()# 执行维护任务self.perform_maintenance_tasks()time.sleep(10) # 每10秒检查一次def monitor_system_health(self):"""监控系统健康状态"""# 检查物理GPU健康状态self.check_gpu_health()# 检查MIG实例状态self.check_mig_instances()# 监控安全状态self.monitor_security()def check_gpu_health(self):"""检查GPU健康状态"""try:result = subprocess.run(['nvidia-smi', '--query-gpu=temperature.gpu,utilization.gpu,memory.used','--format=csv,noheader,nounits'], capture_output=True, text=True, check=True)# 解析并检查健康指标metrics = result.stdout.strip().split(',')temperature = float(metrics[0])utilization = float(metrics[1])memory_used = float(metrics[2])if temperature > 85:print(f"警告: GPU温度过高: {temperature}°C")if utilization > 95:print(f"警告: GPU使用率过高: {utilization}%")if memory_used > 38000: # 38GB for 40GB GPUprint(f"警告: GPU内存使用接近上限: {memory_used}MB")except subprocess.CalledProcessError as e:print(f"检查GPU健康状态失败: {e}")def check_mig_instances(self):"""检查MIG实例状态"""for instance_id, info in self.mig_instances.items():if info['status'] == 'allocated':# 检查实例是否仍在运行if not self.check_instance_active(info['vgpu_instance']):print(f"实例 {instance_id} 不再活跃,释放资源")self.release_instance(instance_id)def monitor_security(self):"""监控安全状态"""# 收集安全相关指标security_metrics = self.collect_security_metrics()# 检查安全异常for instance_id, metrics in security_metrics.items():self.security_monitor.monitor_instance_behavior(instance_id, metrics)def release_instance(self, instance_id: str):"""释放实例资源"""if instance_id in self.mig_instances:info = self.mig_instances[instance_id]if 'tenant' in info and 'vgpu_instance' in info:# 通知租户管理器self.tenant_manager.remove_instance(info['tenant'], info['vgpu_instance'])# 重置实例状态self.mig_instances[instance_id]['status'] = 'available'self.mig_instances[instance_id].pop('tenant', None)self.mig_instances[instance_id].pop('vgpu_instance', None)print(f"释放实例: {instance_id}")def stop(self):"""停止资源管理"""self.running = Falseself.scheduler.stop()if self.management_thread:self.management_thread.join()print("GPU资源管理器已停止")# 使用示例
if __name__ == "__main__":resource_manager = GPUResourceManager()try:# 初始化系统resource_manager.initialize_physical_gpus()# 注册租户resource_manager.tenant_manager.register_tenant("tenant1", max_instances=2, max_memory=10, priority=TaskPriority.HIGH, guaranteed_throughput=1000.0)# 分配实例instance_id = resource_manager.allocate_instance_to_tenant("tenant1", "1g.5gb", 5120 # 5GB in MB)if instance_id:print(f"成功分配实例: {instance_id}")# 启动管理系统resource_manager.start_management()# 运行一段时间time.sleep(300)finally:resource_manager.stop()
4.2 性能优化与调优
4.2.1 性能监控与调优
#!/usr/bin/env python3
# performance_optimizer.pyclass PerformanceOptimizer:def __init__(self, resource_manager: GPUResourceManager):self.resource_manager = resource_managerself.performance_metrics = {}self.optimization_history = []def collect_performance_metrics(self):"""收集性能指标"""metrics = {}# 收集物理GPU指标try:result = subprocess.run(['nvidia-smi', '--query-gpu=index,utilization.gpu,memory.used,power.draw','--format=csv,noheader,nounits'], capture_output=True, text=True, check=True)for line in result.stdout.strip().split('\n'):if line:parts = line.split(',')if len(parts) >= 4:gpu_index = parts[0].strip()metrics[f'gpu_{gpu_index}'] = {'utilization': float(parts[1].strip()),'memory_used': float(parts[2].strip()),'power_draw': float(parts[3].strip())}except subprocess.CalledProcessError as e:print(f"收集GPU性能指标失败: {e}")# 收集vGPU实例指标for instance_id in self.resource_manager.scheduler.instances:instance = self.resource_manager.scheduler.instances[instance_id]metrics[f'vgpu_{instance_id}'] = {'total_executed': instance.total_executed,'time_slice': instance.time_slice,'priority': instance.priority.value}self.performance_metrics = metricsreturn metricsdef analyze_performance(self):"""分析性能数据"""analysis = {}for metric_name, metric_data in self.performance_metrics.items():if metric_name.startswith('gpu_'):# 分析物理GPU性能if metric_data['utilization'] < 60:analysis[metric_name] = {'issue': '低利用率','suggestion': '考虑合并工作负载或调整分配策略'}elif metric_data['utilization'] > 90:analysis[metric_name] = {'issue': '高负载','suggestion': '考虑增加资源或优化工作负载'}elif metric_name.startswith('vgpu_'):# 分析vGPU实例性能if metric_data['total_executed'] < 1000: # 低活跃度analysis[metric_name] = {'issue': '低活跃度','suggestion': '考虑降低优先级或重新分配资源'}return analysisdef apply_optimizations(self, analysis: Dict):"""应用性能优化"""for resource, analysis_data in analysis.items():if resource.startswith('vgpu_'):instance_id = resource[5:] # 移除'vgpu_'前缀if analysis_data['issue'] == '低活跃度':# 降低低活跃度实例的优先级self.resource_manager.scheduler.adjust_instance_priority(instance_id, TaskPriority.LOW)self.record_optimization(instance_id, "降低优先级", "处理低活跃度问题")elif resource.startswith('gpu_'):gpu_index = resource[4:] # 移除'gpu_'前缀if analysis_data['issue'] == '低利用率':# 建议重新分配资源print(f"GPU {gpu_index} 利用率低,建议优化资源分配")def record_optimization(self, instance_id: str, action: str, reason: str):"""记录优化操作"""optimization = {'timestamp': time.time(),'instance_id': instance_id,'action': action,'reason': reason}self.optimization_history.append(optimization)print(f"性能优化: {optimization}")def optimization_loop(self):"""优化循环"""while True:try:# 收集性能数据metrics = self.collect_performance_metrics()# 分析性能analysis = self.analyze_performance()# 应用优化self.apply_optimizations(analysis)# 等待下一次优化周期time.sleep(60) # 每60秒优化一次except Exception as e:print(f"性能优化循环出错: {e}")time.sleep(30) # 出错后等待30秒再继续
结论
通过本文详细介绍的MIG设备多租户分割和vGPU时间片轮转调度技术,我们可以有效解决GPU算力资源碎片化问题,实现以下几个关键目标:
技术成果总结
- 资源利用率大幅提升:通过精细的GPU切片和智能调度,将GPU利用率从传统的20-30%提升到70-80%
- 多租户安全隔离:实现硬件级的多租户隔离,确保不同用户或任务之间的安全性和隐私性
- 服务质量保障:通过先进的调度算法和QoS机制,为关键任务提供性能保障
- 弹性扩展能力:支持动态资源分配和调整,适应不断变化的工作负载需求
实践建议
对于计划实施GPU虚拟化切片技术的组织,建议:
- 评估工作负载特征:首先详细分析现有工作负载的计算特性和资源需求模式
- 渐进式部署:从非关键业务开始试点,逐步积累经验并优化配置
- 建立监控体系:部署完善的监控和告警系统,实时跟踪资源使用情况和性能指标
- 制定资源策略:根据业务优先级制定合理的资源分配和调度策略
未来展望
随着计算需求的不断增长和技术的持续发展,GPU虚拟化切片技术将在以下方面进一步演进:
- 更精细的切片粒度:支持更细粒度的资源分割和更灵活的分配策略
- 智能调度算法:结合机器学习技术实现更智能的预测性调度和资源优化
- 跨平台兼容性:支持不同厂商的GPU设备和异构计算环境
- 云原生集成:更好地与Kubernetes等云原生平台集成,提供无缝的GPU资源管理体验
虚拟化GPU切片技术为高效利用昂贵的GPU计算资源提供了强大工具,通过合理的规划、实施和优化,组织可以显著提升计算效率,降低运营成本,同时为各种AI和计算密集型应用提供可靠的基础设施支持。