数据结构与算法-树和二叉树-二叉树的存储结构(Binary Tree)
树和二叉树的内容比较多,分成两次来发
4 树和二叉树(Tree and Binary Tree)
4.1 树和二叉树的定义
4.1.1 树的定义
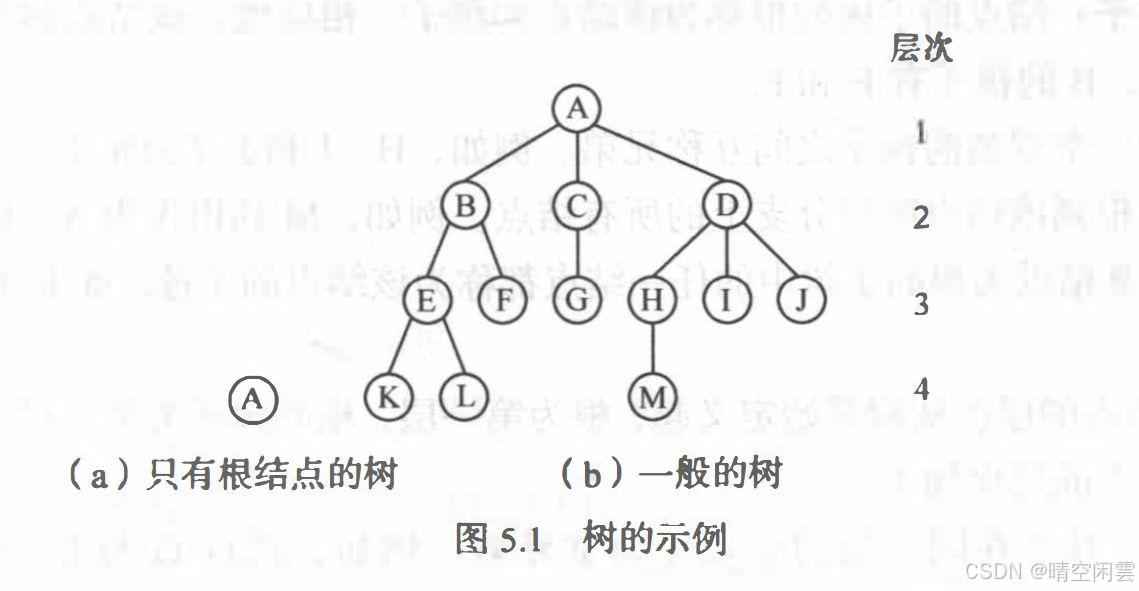
树(Tree)是 n(n>=0)个结点的有限集,它或为空树(n=0)、 或为非空树。
对于非空树:
- 且仅有一个称之为根的结点;
- 根结点以外的其余结点可分为 m(m>0)个互不相交的有限集 T1T_{1}T1 ,T2T_{2}T2,…,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
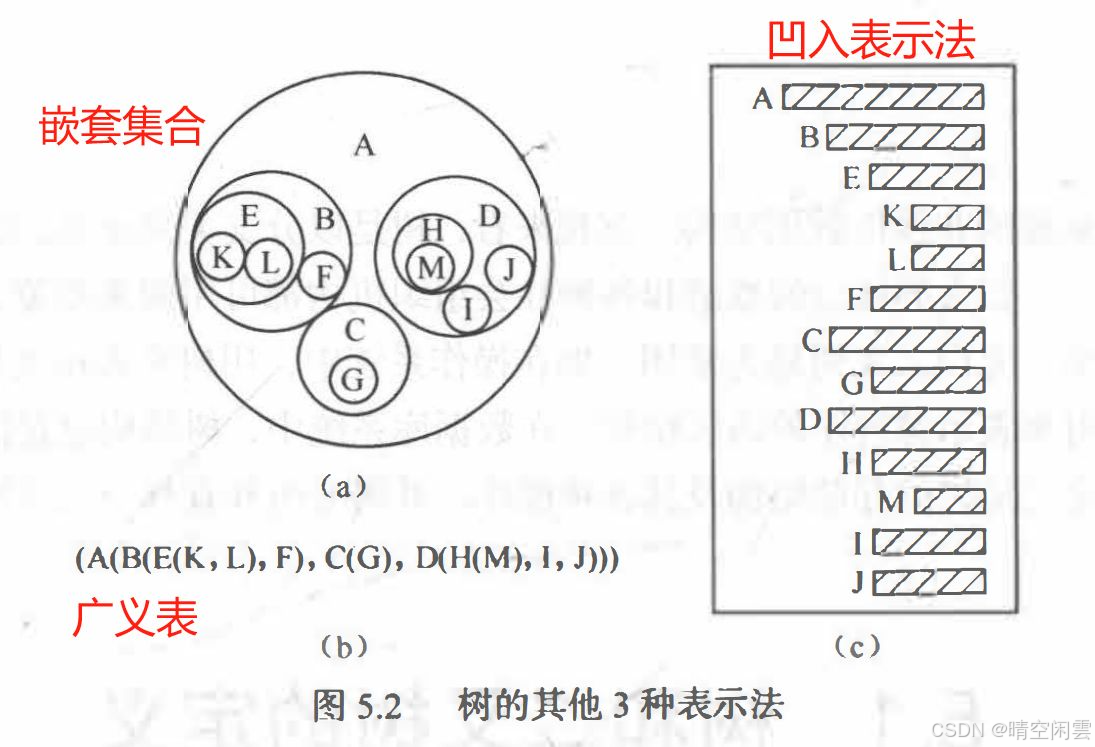
树的其他表现形式:
4.1.2 树的基本术语
关于基本术语,书上是用文字表述不好理解,视频提供了图示进行说明,更加清晰。另外我参考了一些其他资料,发现一个图描述的也很清晰。
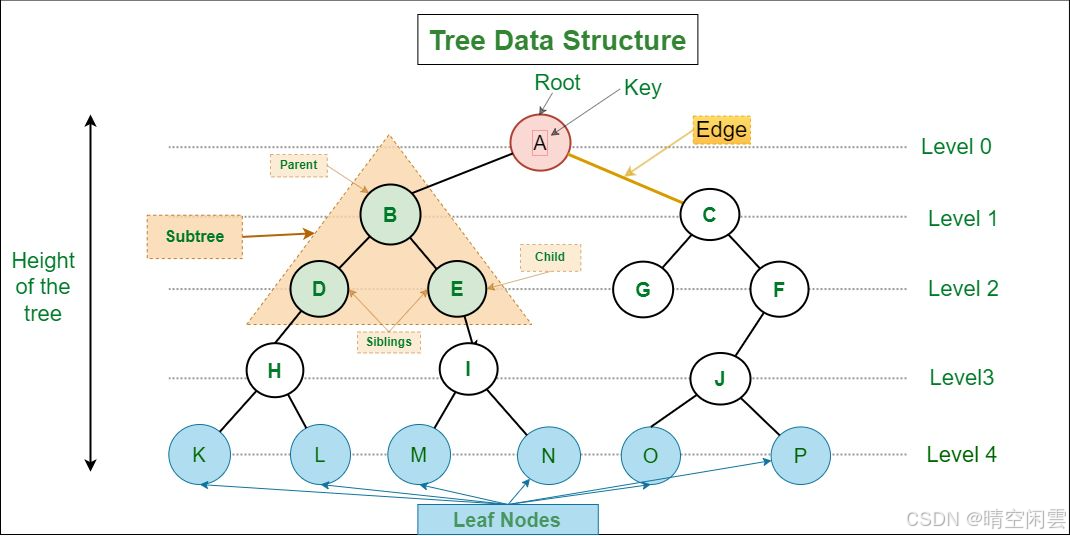
图片来源:Data Structures: A Brief Review for Beginners
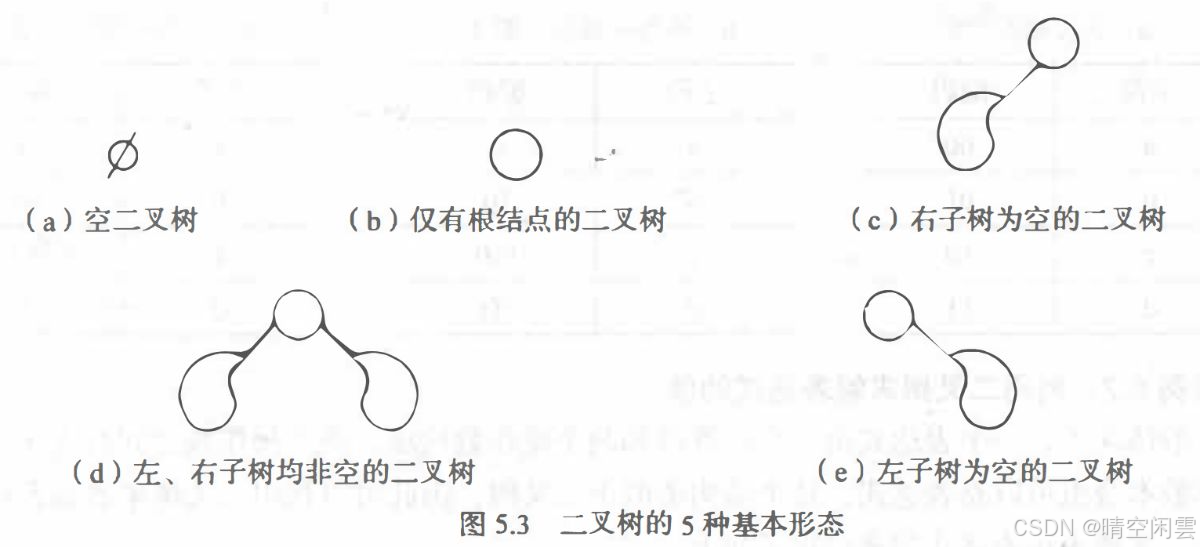
4.1.3 二叉树的定义
二叉树(Binary Tree)是 n(n>=0) 个结点所构成的集合,它或为空树(n =0), 或为非空树。
对于非空树T:
- 有且仅有一 个称之为根的结点;
- 除根结点以外的其余结点分为两个互不相交的子集 T1T_{1}T1 和 T2T_{2}T2, 分别称为T的左子树和右子树,且 T1T_{1}T1 和 T2T_{2}T2 本身又都是二叉树。
和树的区别主要就是:子树最多两棵,分为左右子树。
两种特殊的二叉树:满二叉树和完全二叉树。
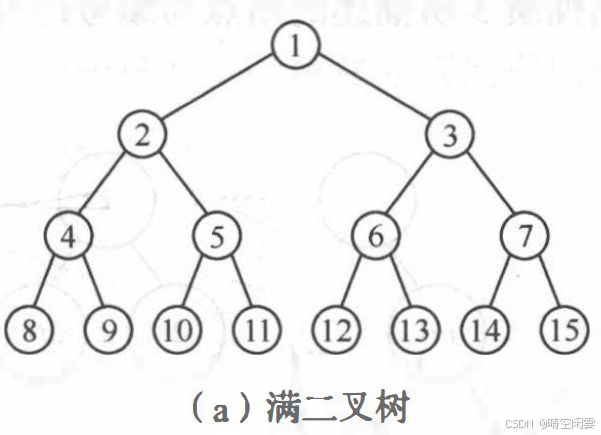
满二叉树:满二叉树:深度为 KKK 且含有 2k−12^k - 12k−1 个结点的二叉树,下图所示是一棵深度为 4 的满二叉树。
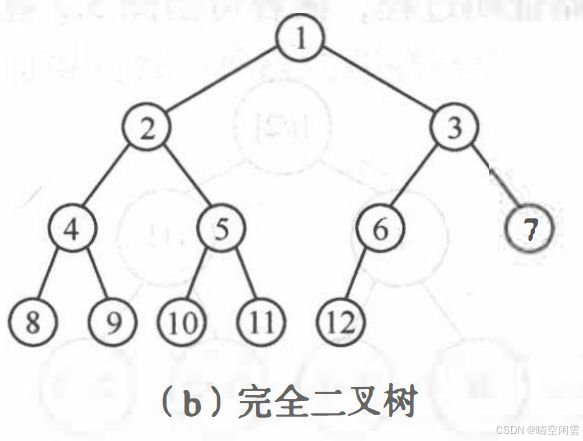
完全二叉树:深度为 KKK 的, 有 nnn 个结点的二叉树, 当且仅当其 每一个结点都与深度为 KKK 的满二叉树中编号从 111 至 nnn 的结点一一对应时, 称之为完全二叉树,下图所示为一棵深度为4的完全二叉树。
4.2 顺序二叉树(Sequence Binary Tree)
顺序存储结构:采用数组进行存储。
#define MAXTSIZE 100 // 二叉树的最大结点数
typedef TElemType SqBiTree[MAXTSIZE]; // 顺序存储二叉树的数组类型
SqBiTree bt;
顺序存储结构使用一组地址连续的存储单元来存储数据元素,为了能够在存储结构中反映出结点之间的逻辑关系,必须将二叉树中的结点依照一定的规律安排在这组单元中。
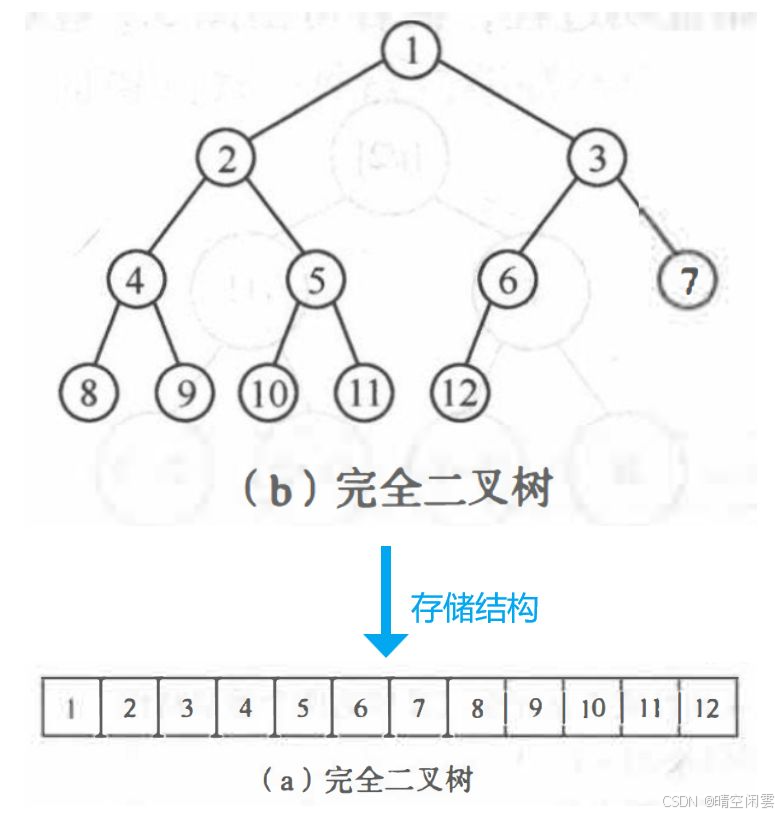
对于完全二叉树,只要从根起按层序存储即可,依次自上而下、自左至右存储结点元素。即将完全二叉树上编号为 i 的结点元素存储在如上定义的一维数组中下标为 i-1 的分量中。
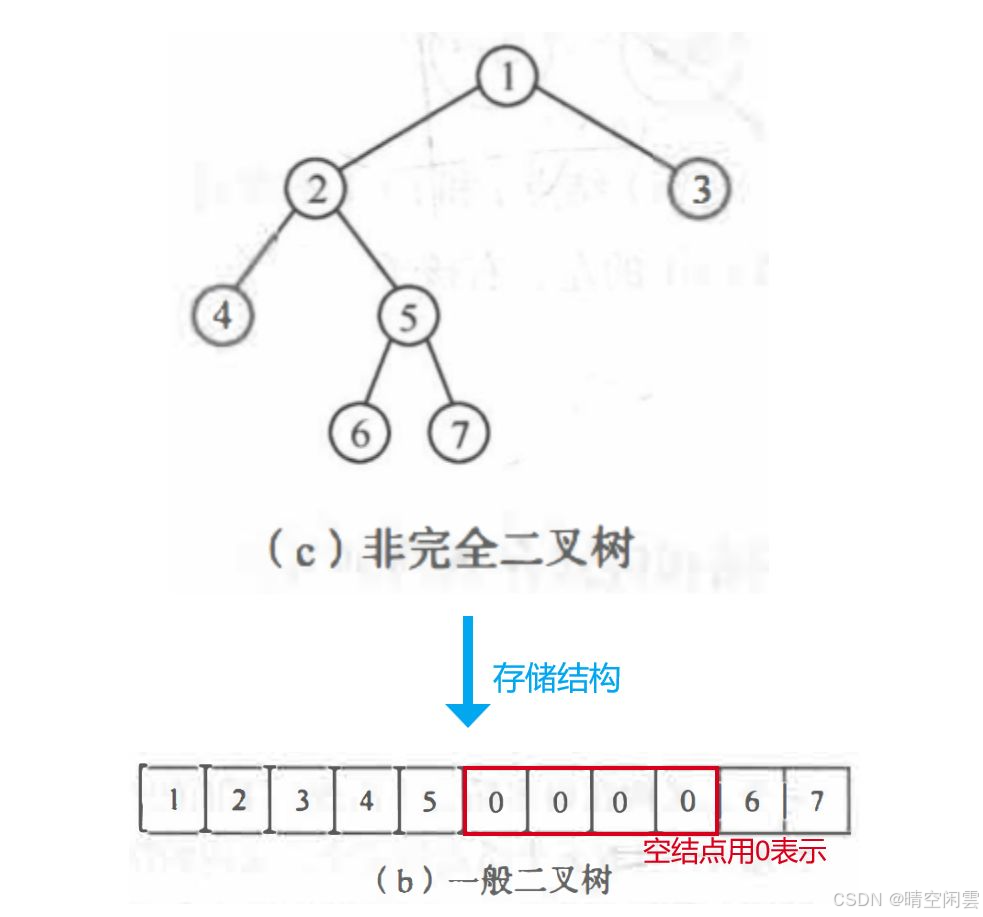
对于一般二叉树,则应将其每个结点与完全二叉树上的结点相对照,存储在一维数组的相应分量中,以 0 表示不存在此结点。
顺序存储结构仅适用于完全二叉树。因为, 在最坏的情况下, 一个深度为 KKK 且只有 KKK 个结点的单支树(树中不存在度为 222 的结点)却需要长度为 2k−12^k-12k−1 的一维数组。这造成了存储空间的极大浪费, 所以对于一般二叉树,更适合采取下面的链式存储结构。
关于顺序存储结构方面,书上和视频没有没有提供代码实现,可能正是太浪费存储空间的原因。
我自己尝试编写了一下代码,也不难实现。假定每个结点存储的是字符(char),因此结构如下:
// 二叉树的顺序存储表示法
#define MAXTSIZE 100 // 二叉树的最大结点数
typedef char TElemType; // 结点类型可以根据需要修改为其他类型
typedef TElemType SqBiTree[MAXTSIZE]; // 顺序存储二叉树的数组类型
创建上面提到的完全二叉树:依次给每个数组元素赋值即可。
// 示例:创建一个完全的二叉树// A// / \ // B C// / \ / \// D E F G// / \ / \ /// H I J K LSqBiTree bt;bt[0] = 'A'; // 根节点bt[1] = 'B'; // 左子节点bt[2] = 'C'; // 右子节点bt[3] = 'D'; // B的左子节点bt[4] = 'E'; // B的右子节点bt[5] = 'F'; // C的左子节点bt[6] = 'G'; // C的右子节点bt[7] = 'H'; // D的左子节点bt[8] = 'I'; // D的右子节点bt[9] = 'J'; // E的左子节点bt[10] = 'K'; // E的右子节点bt[11] = 'L'; // F的左子节点
创建一般二叉树:同上。
// 创建一个一般的二叉树SqBiTree bt2;// A// / \ // B C// / \ // D E// / \// J Kbt2[0] = 'A'; // 根节点bt2[1] = 'B'; // 左子节点bt2[2] = 'C'; // 右子节点bt2[3] = 'D'; // B的左子节点bt2[4] = 'E'; // B的右子节点bt2[5] = '0'; // C的左子节点(空)bt2[6] = '0'; // C的右子节点(空)bt2[7] = '0'; // D的左子节点(空)bt2[8] = '0'; // D的右子节点(空)bt2[9] = 'J'; // E的左子节点bt2[10] = 'K'; // E的右子节点
4.3 链式二叉树(Linked Binary Tree)
由二叉树的定义得知,二叉树的结点由一个数据元素和分别指向其左、 右子树的两个分支构成,则表示二叉树的链表中的结点至少包含 3 个域:数据域和左、 右指针域。另外为了便于找到结点的双亲, 还可在结点结构中增加一个指向其双亲结点的指针域。

利用这两种结点结构所得二叉树的存储结构分别称之为二叉链表和三叉链表。
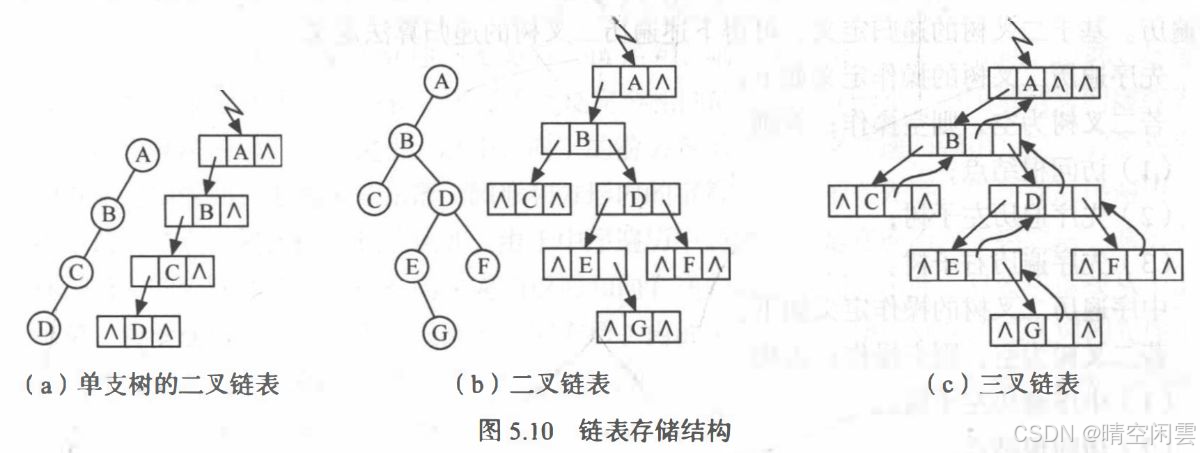
链式二叉树的存储结构代码实现:
// 二叉树的链式存储表示法
typedef char TElemType; // 结点类型可以根据需要修改为其他类型
typedef struct BiTNode
{TElemType data; // 结点数据struct BiTNode *lchild; // 左子结点指针struct BiTNode *rchild; // 右子结点指针
} BiTNode, *BiTree; // BiTree是指向BiTNode的指针类型
4.3.1 遍历二叉树(traversing binary tree)
正常来讲,一种数据结构一般都是先建立出来,然后才能进行遍历、查找、计算个数等操作,如前面的顺序表、链表、栈、队列等,但是因为二叉树不是线性的,要创建出来就要遍历每个结点,因此遍历算法就是基础了,所以教程先介绍了遍历的算法,后面才介绍创建、计算深度等操作。这个在我一开始学习的时候有点晕,到后面才理解了。
遍历算法从根和左右结点的访问顺序可以分成3种:先(根) 序遍历、中(根) 序遍历和后(根)序遍历。视频教程中称为根左右、左根右、左右根,我觉得更加容易记。因为三种方式的思路非常接近,就是什么时候访问结点有差异,所以书中只介绍了中序遍历的代码实现,另外两个类似。
另外中序遍历算法分成 中序遍历递归算法 和 中序遍历非递归算法,书本和视频教程都介绍了,再加上一种 层次遍历算法,书中只是提了一下,视频教程有详细介绍,所以下面总共实现了这3种算法。
1. 中序遍历递归算法
【算法步骤】
若二叉树为空,则空操作;否则:
- 中序遍历左子树;
- 访问根结点;
- 中序遍历右子树。
【代码实现】
// 中序遍历二叉树
void InOrderTraverse(BiTree T)
{if (T == NULL)return; // 如果结点为空,直接返回InOrderTraverse(T->lchild); // 递归访问左子树printf("%c", T->data); // 访问当前结点InOrderTraverse(T->rchild); // 递归访问右子树
}
代码非常简洁,也不难理解,逻辑大概如下图,视频教程中有动画演示了访问结点的过程,非常清晰易懂。
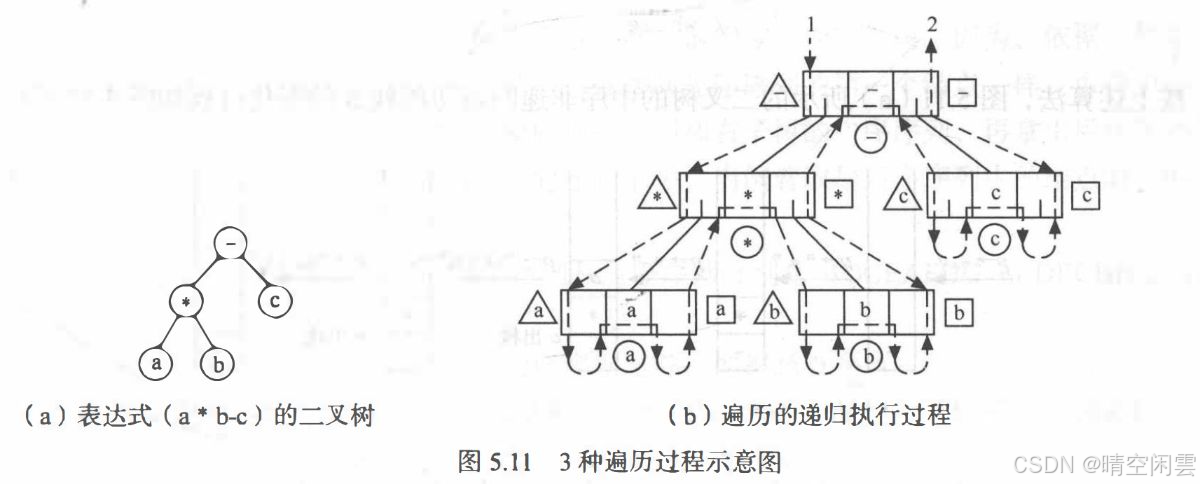
构造上图的左边的树,并中序遍历打印:
// 书本图5.11的二叉树// -// / \ // * c// / \ // a bBiTree root = (BiTree)malloc(sizeof(BiTNode));root->data = '-'; // 根结点root->lchild = (BiTNode *)malloc(sizeof(BiTNode));root->lchild->data = '*'; // 左子结点root->lchild->lchild = (BiTNode *)malloc(sizeof(BiTNode));root->lchild->lchild->data = 'a'; // 左子结点root->lchild->lchild->lchild = NULL; // a的左子结点为空root->lchild->lchild->rchild = NULL; // a的右子结点为空root->lchild->rchild = (BiTNode *)malloc(sizeof(BiTNode));root->lchild->rchild->data = 'b'; // 右子结点root->lchild->rchild->lchild = NULL; // b的左子结点为空root->lchild->rchild->rchild = NULL; // b的右子结点为空root->rchild = (BiTNode *)malloc(sizeof(BiTNode));root->rchild->data = 'c'; // 右子结点root->rchild->lchild = NULL; // c的左子结点为空root->rchild->rchild = NULL; // c的右子结点为空// 中序遍历二叉树printf("\nIn-order traversal of the binary tree: ");InOrderTraverse(root); // 打印 a*b-c
【算法分析】
书中提到每个结点的访问次数是1次,视频中提到每个结点的经过次数是3次(视频教程中有动画演示了这个流程),一开始我有点迷糊,后面就想清楚了,书中说的是结点本身的值,视频中说的包含了左右指针域和值。不管怎么理解,在考虑算法复杂度的时候常数项可以忽略,因此算法复杂度是 O(n) 。
中序遍历的递归算法实现后,我接着编写了先序和后序,代码如下,实践后发现3种方式确实非常类似。
// 中序遍历二叉树
void InOrderTraverse(BiTree T)
{if (T == NULL)return; // 如果结点为空,直接返回InOrderTraverse(T->lchild); // 递归访问左子树printf("%c", T->data); // 访问当前结点InOrderTraverse(T->rchild); // 递归访问右子树
}// 后续遍历二叉树
void PostOrderTraverse(BiTree T)
{if (T == NULL)return; // 如果结点为空,直接返回PostOrderTraverse(T->lchild); // 递归访问左子树PostOrderTraverse(T->rchild); // 递归访问右子树printf("%c", T->data); // 访问当前结点
}
2. 中序遍历的非递归算法
【算法步骤】
- 初始化一个空栈
s, 指针p指向根结点。 - 申请一个结点空间
q, 用来存放栈顶弹出的元素。 - 当
p非空或者栈S非空时,循环执行以下操作:- 如果
p非空,则将p进栈,p指向该结点的左孩子; - 如果
p为空,则 弹出栈顶元素并访间,将p指向该结点的右孩子。
- 如果
【代码实现】
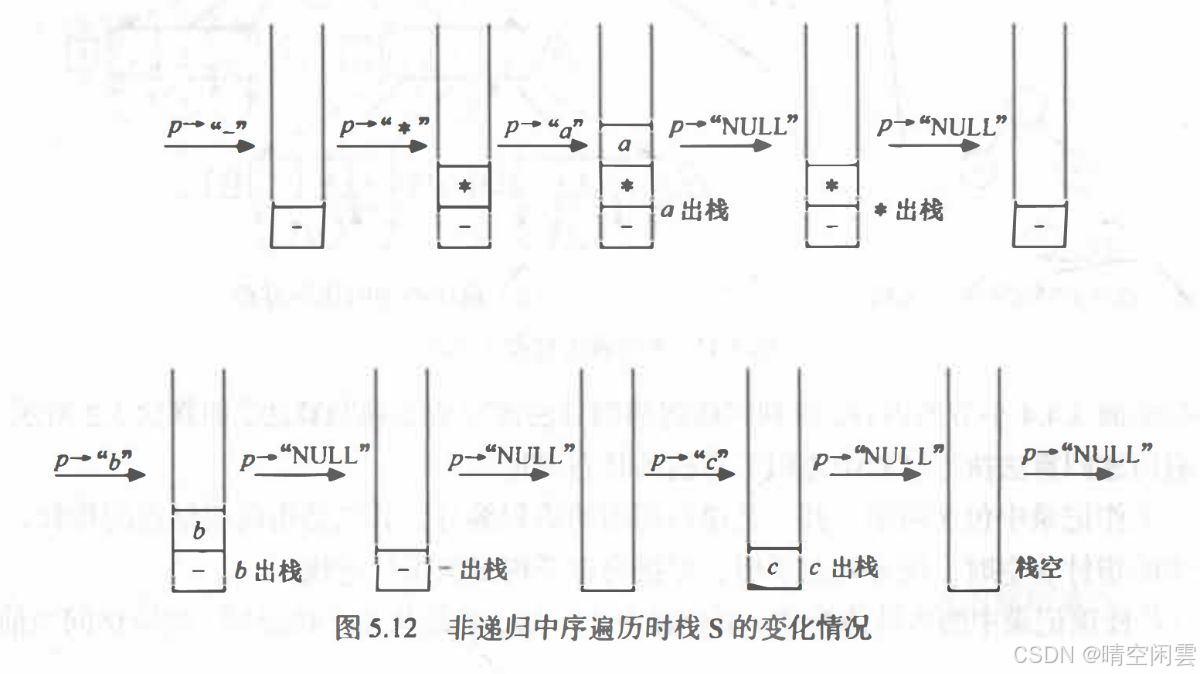
和书中不一样的是,为了代码能够运行,并且不需要引入之前的栈实现代码,我用一个数组实现了栈,当然用之前的顺序栈或者链栈当然也是可以,就是要把代码都移过来,比较麻烦。
// 中序遍历二叉树递归实现
void InOrderTraverseNonRecursive(BiTree T)
{BiTree stack[100]; // 假设栈的大小为100int top = -1; // 栈顶指针,-1表示栈为空BiTree p = T; // p用于指向当前当前结点,一开始指向根结点while (p != NULL || top != -1) // 当p不为空或栈不为空时继续循环{if (p != NULL) // p不为空{stack[++top] = p; // 将当前结点入栈p = p->lchild; // 移动到左子结点}else // p为空,因为while循环的条件成立,所以栈一定不为空。{p = stack[top--]; // 出栈printf("%c", p->data); // 访问当前结点p = p->rchild; // 移动到右子结点}} // while循环结束,表示遍历完成
}
运行的过程如下图所示:
【算法分析】
很显然每个结点只被访问一次,所以时间复杂度是 O(n) ,非递归算法需要引入一个额外的栈空间实现,空间为遍历过程中栈的最大容量,即树的深度,最坏情况下为 n, 则空间复杂度也为 O(n) 。
中序遍历的非递归算法实现后,接着试试先序和后序,先序发现差不多,只是修改了一下访问结点值的时机,代码如下:
// 先序遍历二叉树非递归实现
void PreOrderTraverseNonRecursive(BiTree T)
{BiTree stack[100]; // 假设栈的大小为100int top = -1; // 栈顶指针,-1表示栈为空BiTree p = T; // p用于指向当前结点,一开始指向根结点while (p != NULL || top != -1) // 当p不为空或栈不为空时继续循环{if (p != NULL) // p不为空{printf("%c", p->data); // 访问当前结点,根先访问stack[++top] = p; // 将当前结点入栈p = p->lchild; // 移动到左子结点}else // p为空,因为while循环的条件成立,所以栈一定不为空。{p = stack[top--]; // 出栈p = p->rchild; // 移动到右子结点}} // while循环结束,表示遍历完成
}
但是在编写后序时,发现有点不太一样,具体代码参考如下,这个代码稍微有点难理解,主要思路就是因为是 左右根 的访问顺序,所以当 p 为空的时候,要接着检测栈顶结点的右子节点,如果右子节点有或者没有被访问过,那要先访问右子节点,最后才能访问自己。
// 后序遍历二叉树递归实现
void PostOrderTraverseNonRecursive(BiTree T)
{BiTree stack[100]; // 假设栈的大小为100int top = -1; // 栈顶指针,-1表示栈为空BiTree p = T; // p用于指向当前结点,一开始指向根结点BiTree lastVisited = NULL; // 记录上一个访问的结点while (p != NULL || top != -1) // 当p不为空或栈不为空时继续循环{if (p != NULL) // p不为空{stack[++top] = p; // 将当前结点入栈p = p->lchild; // 移动到左子结点}else // p为空,因为while循环的条件成立,所以栈一定不为空。{BiTree peekNode = stack[top]; // 获取栈顶结点// 因为是 **左右根** 的访问顺序,所以要检测 peekNode 的右子结点if (peekNode->rchild == NULL || peekNode->rchild == lastVisited) // 如果右子结点为空或已经被访问过{printf("%c", peekNode->data); // 访问当前结点lastVisited = peekNode; // 更新上一个访问的结点top--; // 出栈}else{p = peekNode->rchild; // 移动到右子结点}}} // while循环结束,表示遍历完成
}
理解上可以参考这个二叉树,就容易理解了,访问的顺序应该时:DECBA 。
A\ B\ C/ \D E
3. 层次遍历算法
书中有提了一下这个算法,没有详细介绍,视频有详细介绍这个方法。这个算法也非常容易理解,就是从上到下、从左到右依次访问。
【算法步骤】
核心思路是使用一个队列,将结点和左右子结点依次入队,从而实现层次遍历。
- 根结点入队。
- 队列不为空时,进行循环处理:从队头取出一个结点
p进行访问。然后判断左右子结点。- 若左子结点不为空,则入队;
- 若左子结点不为空,则入队;
【代码实现】
和视频教程不同,我在这里用一个数组来模拟队列,这样代码简单易读。
// 层次遍历二叉树
void LevelOrderTraverse(BiTree T)
{if (T == NULL)return; // 如果结点为空,直接返回BiTree queue[100]; // 假设队列的大小为100int front = 0, rear = 0; // 队列的前端和后端指针queue[rear++] = T; // 将根结点入队while (front < rear) // 当队列不为空时继续循环{BiTree p = queue[front++]; // 出队printf("%c", p->data); // 访问当前结点if (p->lchild != NULL) // 如果左子结点不为空,将其入队queue[rear++] = p->lchild;if (p->rchild != NULL) // 如果右子结点不为空,将其入队queue[rear++] = p->rchild;} // while循环结束,表示遍历完成
}
【算法分析】
很显然,因为每个结点只访问了一次,算法复杂度时 O(n)。空间复杂度方面,因为需要一个队列临时保存结点,最坏的情况是保留最后一行的的结点加上上一行未访问的结点,参考下图,但最坏情况也不会超过n,所以空间复杂度也是 O(n)。
a/ \ a a/ \ / \ a a a a/ \ / \ a a a a // 最坏的情况就是最后一行4个,加上前面一行后面2个。
4.3.2 创建二叉树
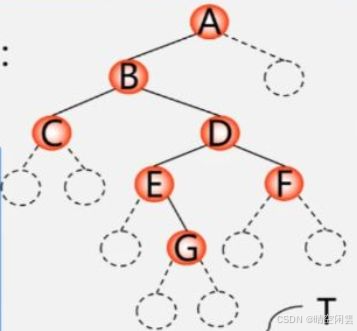
教程中的方式都是通过获取用户输入,然后创建二叉树,我实现的是直接通过一个字符串创建二叉树,形如:ABC##DE#G##F### 这样的字符串,图示如下:
【算法步骤】
- 根据序号
index获取每一个字符串中对应的字符ch。 - 如果
ch是一个#字符,则表明该二叉树为空树,即T为NULL; - 如果
ch是一个\0字符,则表明已经到字符串结尾,直接结束; - 否则执行以下操作:
- 申请一个结点空间
T; - 将
ch赋给T->data; - 序号
index加1,表示移动到下一个字符; - 递归创建
T的左子树; - 递归创建
T的右子树;
- 申请一个结点空间
【代码实现】
// 根据一个字符串,采用先序遍历的顺序创建二叉链表
// 字符串中的字符表示结点数据,'#'表示空结点。例如:ABC##DE#G##F###
void CreateBiTree(const char *preOrder, int *index, BiTree *T)
{char ch = preOrder[*index]; // 获取当前字符if (ch == '\0' || ch == '#') // '#'表示空结点{(*index)++;*T = NULL; // 设置当前结点为空return;}*T = (BiTree)malloc(sizeof(BiTNode)); // 创建新结点(*T)->data = preOrder[*index]; // 设置结点数据(*index)++; // 移动到下一个字符CreateBiTree(preOrder, index, &((*T)->lchild)); // 递归创建左子树CreateBiTree(preOrder, index, &((*T)->rchild)); // 递归创建右子树
}
此外为了方便打印出和提供的字符串一样的效果(带#),略微修改了一下先序遍历的函数,当树为 NULL 的时候,打印 # 字符。
// 先序遍历二叉树,空结点打印#
void PreOrderTraverseWithNull(BiTree T)
{if (T == NULL){printf("#"); // 空结点打印#return;}printf("%c", T->data); // 访问当前结点PreOrderTraverseWithNull(T->lchild); // 递归访问左子树PreOrderTraverseWithNull(T->rchild); // 递归访问右子树
}
调用示例:
// 创建二叉树const char *preOrder = "ABC##DE#G##F###"; // 先序遍历字符串int index = 0; // 用于跟踪当前字符位置BiTree T = NULL; // 新的二叉树指针CreateBiTree(preOrder, &index, &T); // 创建二叉树printf("\nCreated binary tree from pre-order string: ");PreOrderTraverseWithNull(T); // 先序遍历新创建的二叉树。如果前面没有错误,应该打印:ABC##DE#G##F###
【算法分析】
很显然,因为字符串中的每个字符只会遍历一次,所以算法复杂度是 O(n) 。
4.3.3 复制二叉树
复制二叉树的算法和创建二叉树的很类似。
【算法步骤】
如果是空树, 递归结束, 否则执行以下操作:
• 申请一个新结点空间, 复制根结点;
• 递归复制左子树;
• 递归复制右子树。
【代码实现】
// 复制二叉树
void CopyBiTree(BiTree T, BiTree *newTree)
{if (T == NULL){*newTree = NULL; // 如果结点为空,设置新树为空return; // 如果结点为空,返回NULL}*newTree = (BiTree)malloc(sizeof(BiTNode)); // 创建新结点(*newTree)->data = T->data; // 复制数据CopyBiTree(T->lchild, &((*newTree)->lchild)); // 递归复制左子树CopyBiTree(T->rchild, &((*newTree)->rchild)); // 递归复制右子树【算法分析】
每个结点只访问一次,所以算法复杂度是 O(n) 。
4.3.4 计算二叉树的深度
【算法步骤】
如果是空树,递归结束,深度为0,否则执行以下操作:
• 递归计算左子树的深度记为 m ;
• 递归计算右子树的深度记为 n ;
• 如果 m 大于 n ,二叉树的深度为 m+1 , 否则为 n+1 。
【代码实现】
// 计算二叉树的深度
int BiTreeDepth(BiTree T)
{if (T == NULL)return 0; // 如果结点为空,深度为0int m = BiTreeDepth(T->lchild); // 递归计算左子树深度int n = BiTreeDepth(T->rchild); // 递归计算右子树深度return (m > n ? m : n) + 1; // 返回最大深度加1
}
【算法分析】
每个结点只访问一次,所以算法复杂度是 O(n) 。
4.3.5 统计二叉树中结点的个数
【算法步骤】
如果是空树,递归结束,节点数为0,否则执行以下操作:
• 递归计算左子树的结点个数;
• 递归计算右子树的结点个数;
• 左右子树的结点个数和加上1就是树的结点个数。
【代码实现】
// 计算二叉树结点的个数
int BiTreeNodeCount(BiTree T)
{if (T == NULL)return 0; // 如果结点为空,结点个数为0return 1 + BiTreeNodeCount(T->lchild) + BiTreeNodeCount(T->rchild); // 当前结点加上左右子树的结点个数
}【算法分析】
每个结点只访问一次,所以算法复杂度是 O(n) 。
4.3.6 统计叶结点个数
书中还提到了一个算法,统计二叉树中叶结点(度为 0) 的个数,度为 1 的结点个数和度为 2 的结点个数,视频教程实现了叶子节点的个数计算,这里也先实现这个算法。
【算法步骤】
如果是空树,递归结束,叶结点数为0,否则执行以下操作:
• 递归计算左子树的叶结点个数;
• 递归计算右子树的叶结点个数;
• 返回左右子树的叶结点个数和。
【代码实现】
// 计算叶子结点的个数
int BiTreeLeafCount(BiTree T)
{if (T == NULL)return 0; // 如果结点为空,叶子结点个数为0if (T->lchild == NULL && T->rchild == NULL)return 1; // 如果当前结点是叶子结点,返回1return BiTreeLeafCount(T->lchild) + BiTreeLeafCount(T->rchild); // 递归计算左右子树的叶子结点个数
}
【算法分析】
每个结点只访问一次,所以算法复杂度是 O(n) 。
4.3.7 统计二叉树中度为0、1、2的结点个数
【算法步骤】
根据定义,二叉树的度只能有0、1、2三个值,因此可以考虑用一个长度为3的数组进行存储,其中索引为0、1、2的位置分别存储度为0、1、2的结点数量。
如果是空树,递归结束,否则执行以下操作:
• 计算该结点的度,对应的数组存储位置加1;
• 如果左子树不为空,则递归计算左子树;
• 如果右子树不为空,则递归计算右子树;
【代码实现】
// 计算二叉树中度为0、1、2的结点个数
void BiTreeCountGroupByDegree(BiTree T, int count[3])
{if (T == NULL)return; // 如果结点为空,直接返回int degree = 0;if (T->lchild != NULL)degree++;if (T->rchild != NULL)degree++;count[degree]++;if (T->lchild != NULL)BiTreeCountGroupByDegree(T->lchild, count); // 递归计算左子树的结点个数if (T->rchild != NULL)BiTreeCountGroupByDegree(T->rchild, count); // 递归计算右子树的结点个数
}
【算法分析】
每个结点只访问一次,所以算法复杂度是 O(n) 。
4.4 线索二叉树(Threaded Binary Tree)
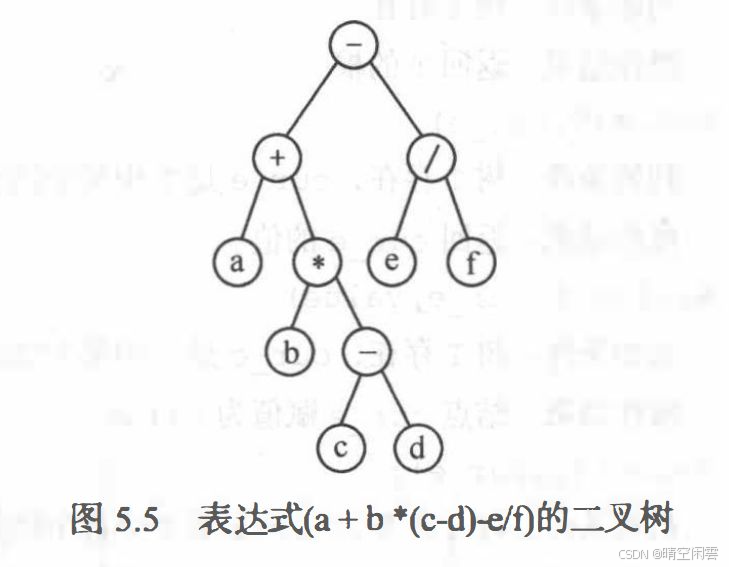
线索二叉树主要是为了解决查找结点的前驱和后继的问题。如下图的二叉树,如果中序遍历就是:a+b*c-d-e/f,c 的前驱就是 * ,后继就是 - 。
线索二叉树的存储结构:有 n 个结点的二叉链表中必定存在 n+1 个空链域,因此可以利用这些空链域来存放结点的前驱和后继信息。
为什么有 n+1 个空链域?
- 每个结点有
2个链域,一个指向左孩子,一个指向有孩子,因为总共有2n个链域。 - 除根节点外,每个结点都只有一个双亲结点,可以理解为占用一个双亲结点的链域,所以总计使用
n-1个链域。 - 剩余的空链域就是:
2n-(n-1) = n+1。
为了避免混淆,增加两个标志域 LTag 和 RTag :
LTag = 0,lchild指向该结点的左孩子;LTag = 1,lchild指向该结点的前驱线索;RTag = 0,rchild指向该结点的右孩子;RTag = 1,rchild指向该结点的后继线索;
存储结构代码如下:
// 线索二叉树的存储结构
typedef char TElemType; // 结点数据类型,可根据需要修改typedef enum
{Link, // Link=0:指向孩子,Thread=1:指向前驱/后继Thread // Thread=1:指向前驱/后继
} PointerTag;typedef struct BiThrNode
{TElemType data; // 数据域struct BiThrNode *lchild, *rchild; // 左右指针PointerTag LTag, RTag; // 左右线索标志
} BiThrNode, *BiThrTree;
4.4.1 构造线索二叉树
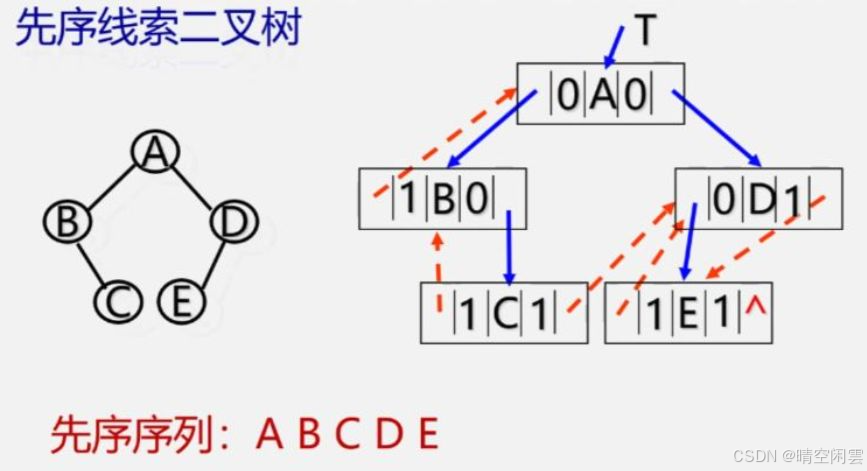
构造的方式同二叉树,也有先序、中序和后序三种方式,分别称为先序线索二叉树、中序线索二叉树和后序线索二叉树。
先序线索二叉树
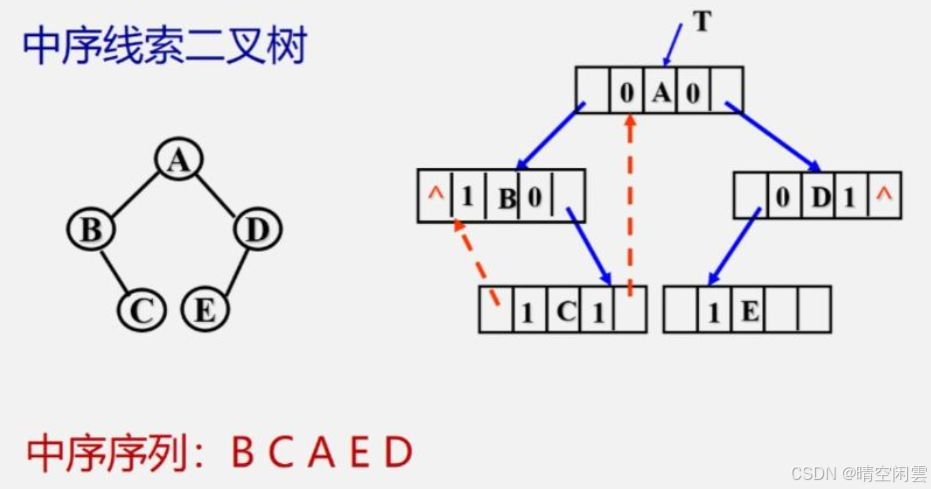
中序线索二叉树
后序线索二叉树
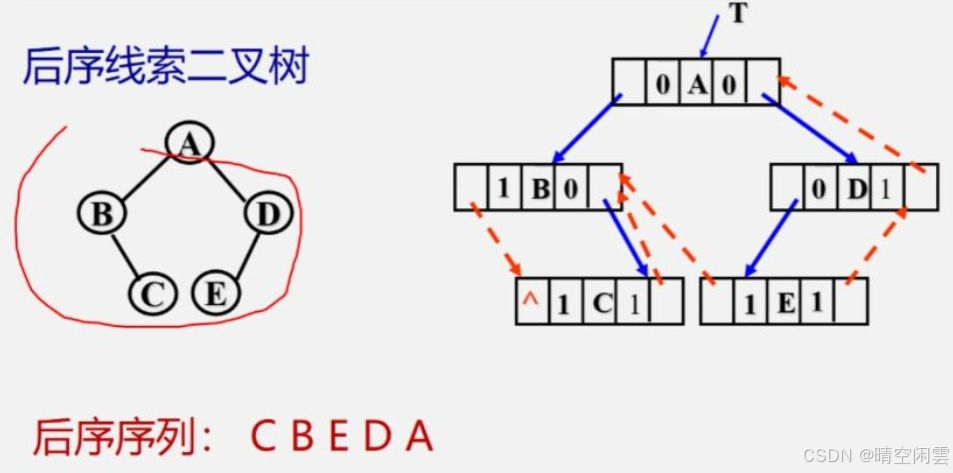
书中只介绍了构造中序线索二叉树的方式,视频教程也提供了一个中序线索二叉树的练习,故这里也只实现中序线索二叉树。
1. 以结点p为根的子树中序线索化
【算法步骤】
如果 p 非空,左子树递归线索化。
- 如果
p的左孩子为空,则给p加上左线索,将其LTag置为1,让p的左孩子指针指向pre(前驱);否则将p的LTag置为0。 - 如果
pre的右孩子为空,则给pre加上右线索,将其RTag置为1,让pre的右孩子指针指向p(后继);否则将pre的RTag置为0。 - 将
pre指向刚访问过的结点p,即pre=p。 - 右子树递归线索化。
【代码实现】
// 全局变量,指向当前访问结点的前驱
BiThrTree pre = NULL;// 以结点p为根的子树中序线索化
void InThreading(BiThrTree p)
{if (p == NULL)return;InThreading(p->lchild); // 左子树递归线索化// 左孩子为空,建立前驱线索,指向上一个访问的结点。if (p->lchild == NULL){p->LTag = Thread;p->lchild = pre;}else{p->LTag = Link;}// 上一个访问的结点不为空,并且上一个访问的结点右孩子为空,则建立后继线索,指向当前结点。if (pre != NULL){if (pre->rchild == NULL){pre->RTag = Thread;pre->rchild = p;}else{pre->RTag = Link;}}pre = p; // 更新前驱InThreading(p->rchild); // 右子树递归线索化
}
以视频教程的练习进行测试,需要先用之前二叉树的方法构造出二叉树,而后再构造线索二叉树。
// 视频教程的二叉树,把这个二叉树改造成线索二叉树// A// / \ // B C// / \ / \// D E F G// / \// H Iconst char *preOrder = "ABDH##I##E##CF##G##"; // 先序遍历字符串,如果是中序遍历应该是:#H#D#I#B#E#A#F#C#G#int index = 0; // 用于跟踪当前字符位置BiThrTree T = NULL; // 新的二叉树指针CreateBiTree(preOrder, &index, &T); // 创建二叉树printf("\nCreated binary tree from pre-order string: ");PreOrderTraverseWithNull(T); // 先序遍历新创建的二叉树。如果前面没有错误,应该打印:ABDH##I##E##CF##G##printf("\nCreated binary tree from in-order string: ");InOrderTraverseWithNull(T); // 中序遍历新创建的二叉树。如果前面没有错误,应该打印:#H#D#I#B#E#A#F#C#G#,如果不打印空结点应为 HDIBEAFCGprintf("\n");// 二叉树改造为中序线索二叉树InThreading(T);
中序线索二叉树构造完成后结果如下图:
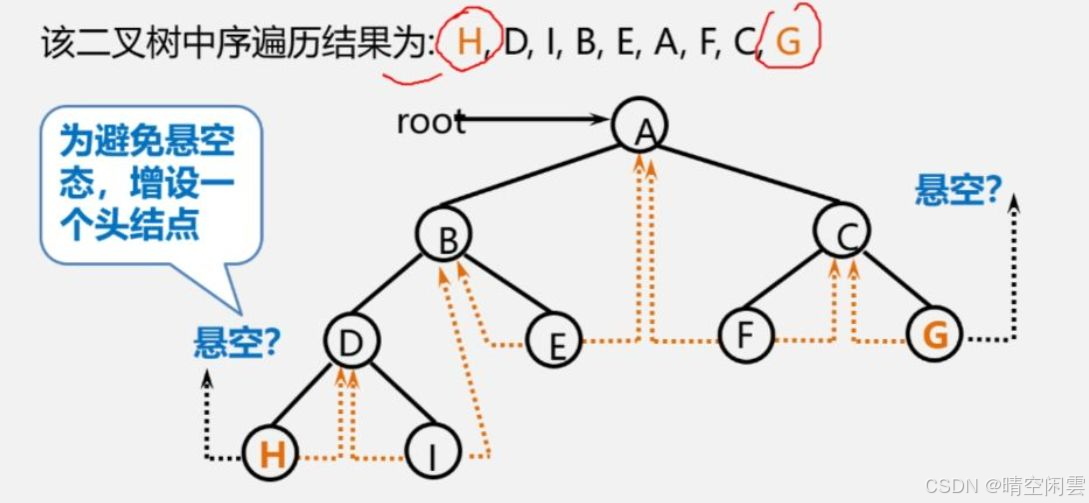
为了方便查看线索二叉树的情况,补上一个打印方法:
// 打印中序线索二叉树中的信息。
void PrintThreadInfo(BiThrTree T)
{if (T == NULL)return;// 中序遍历左子树,指向孩子类型的结点才需要递归遍历if (T->LTag == Link)PrintThreadInfo(T->lchild);// 打印当前结点及其前驱后继线索 或者 左右孩子printf("结点 %c: ", T->data);if (T->LTag == Thread)printf("前驱线索 -> %c, ", T->lchild ? T->lchild->data : '#');elseprintf("左孩子 -> %c, ", T->lchild ? T->lchild->data : '#');if (T->RTag == Thread)printf("后继线索 -> %c\n", T->rchild ? T->rchild->data : '#');elseprintf("右孩子 -> %c\n", T->rchild ? T->rchild->data : '#');// 中序遍历右子树,指向孩子类型的结点才需要递归遍历if (T->RTag == Link)PrintThreadInfo(T->rchild);
}
打印中序线索二叉树,打印结果可以和前面的图片比较,符合预期。
// 打印中序线索二叉树每个结点的前驱线索和后继线索
PrintThreadInfo(T);
/*
结点 H: 前驱线索 -> #, 后继线索 -> D
结点 D: 左孩子 -> H, 右孩子 -> I
结点 I: 前驱线索 -> D, 后继线索 -> B
结点 B: 左孩子 -> D, 右孩子 -> E
结点 E: 前驱线索 -> B, 后继线索 -> A
结点 A: 左孩子 -> B, 右孩子 -> C
结点 F: 前驱线索 -> A, 后继线索 -> C
结点 C: 左孩子 -> F, 右孩子 -> G
结点 G: 前驱线索 -> C, 右孩子 -> #
*/
【算法分析】
每个结点只访问一次,所以算法复杂度是 O(n) 。
2. 带头结点的二叉树中序线索化
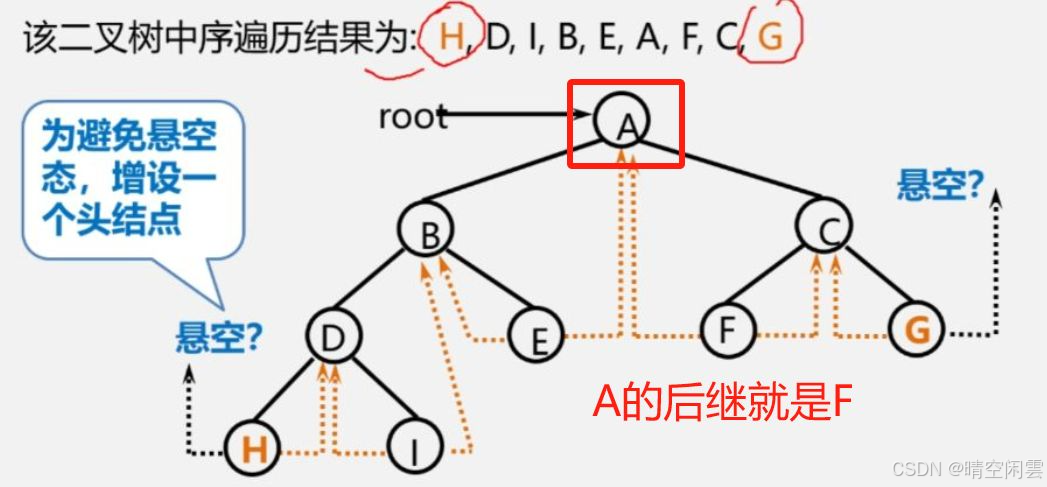
前面的线索二叉树 结点H的左指针 和 结点G的右指针 都是悬空的,为了避免指针悬空,可以增加一个头节点。前面的例子增加一个头节点示意图如下:
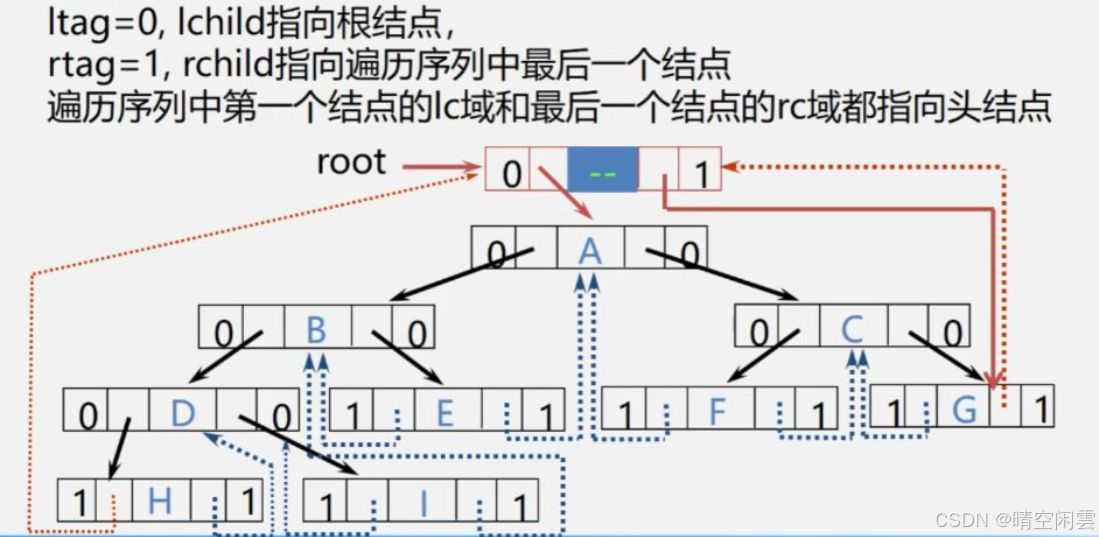
【算法步骤】
- 构造一个头结点,右指针先指向自己。
- 如果
T为空,那么头节点左指针指向自己,结束。 - 如果
T不为空,- 那么左指针指向
T树根,pre指向头结点; - 调用上面的二叉树线索化的方法进行线索化,执行完成后
pre指向最右结点。 - 最右结点
pre的右指针指向头节点; - 头结点的右指针指向最右结点
pre。
- 那么左指针指向
【代码实现】
// 带头结点的二叉树中序线索化
void InOrderThreading(BiThrTree *Thrt, BiThrTree T)
{// 中序遍历二叉树 T, 并将其中序线索化,Thrt指向头结点(*Thrt) = (BiThrTree)malloc(sizeof(BiThrNode)); // 建立头结点(*Thrt)->LTag = Link; // 头结点有左孩子,若树非空,则其左孩子为树根(*Thrt)->RTag = Thread; // 头结点的右孩子指针为 右线索(*Thrt)->rchild = *Thrt; // 初始化时右指针指向自己(*Thrt)->data = 'T'; // T表示我是头if (T == NULL) // 若树为空,则左指针也指向自己,结束{(*Thrt)->lchild = *Thrt;}else{(*Thrt)->lchild = T; // 头结点的左指针指向树根pre = (*Thrt); // 让pre指向头结点InThreading(T); // 对以T为根的二叉树进行中序线索化// 前面线索化结束后,pre为最右结点,pre的右线索指向头结点pre->rchild = *Thrt;pre->RTag = Thread;// 头结点的右线索指向最右结点(*Thrt)->rchild = pre;}
}
【算法分析】
同前面二叉树线索化的方法,算法复杂度是 O(n) 。
4.4.2 遍历线索二叉树
线索二叉树是为了解决查找前驱和后继进行设计的,那么怎么进行查找前驱和后继呢?
以中序线索二叉树为例进行说明。
-
找
p指针所指结点的前驱:- 若
p->LTag = 1,则p的左指针指示其前驱; - 若
p->LTag = 0,则说明p有左子树, 结点的前驱是遍历左子树时最后访间的一个结点(左子树中最右下的结点)。
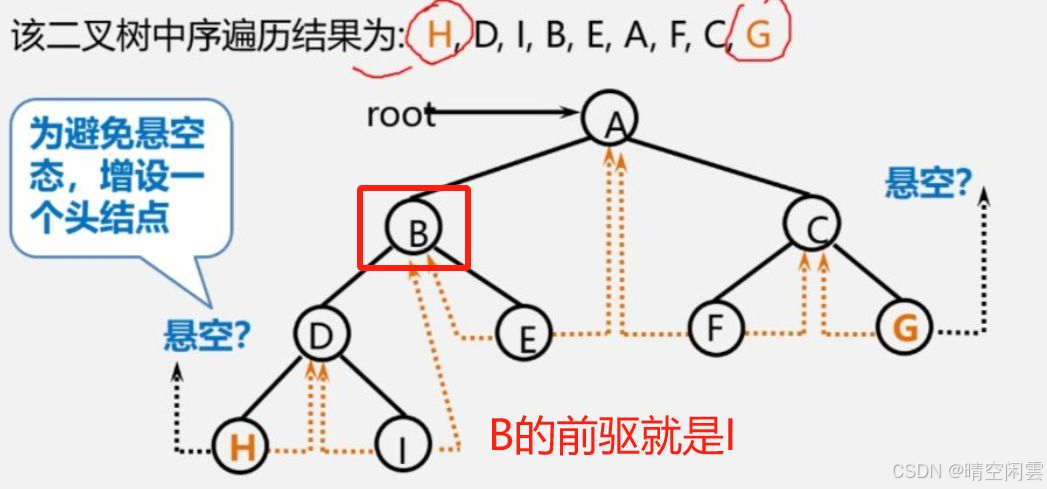
- 若
-
找
p指针所指结点的后继:- 若
p->RTag = 1,则p的右指针指示其后继; - 若
p->RTag = 0,则说明p有右子树。 根据中序遍历的规律可知, 结点的后继应是遍历其右子树时访间的第一个结点,即右子树中最左下的结点。
- 若
知道如何查找前驱和后继,就可以写出线索二叉树遍历的算法了。
【算法步骤】
- 指针
p指向根结点。 p为非空树或遍历未结束时,循环执行以下操作:- 沿左孩子向下,到达最左下结点
*p,它是中序的第一个结点;(上图就是H结点) - 访问
*p; - 沿右线索反复查找当前结点
*p的后继结点并访问后继结点,直至右线索为0或者遍历结束;(上图可以参考I和E结点) - 转向p的右子树。
- 沿左孩子向下,到达最左下结点
这个步骤参考前面的例子图示就非常容易理解了。
【代码实现】
// 从头结点开始,中序遍历线索二叉树
void InOrderTraverse_Thr(BiThrTree Thrt)
{BiThrTree p = Thrt->lchild; // p指向根结点while (p != Thrt) // 遍历到头结点结束{// 找到第一个要访问的结点(最左下)while (p->LTag == Link)p = p->lchild;// 访问当前结点printf("%c ", p->data);// 按线索找后继while (p->RTag == Thread && p->rchild != Thrt){p = p->rchild;printf("%c ", p->data);}// 移到右孩子p = p->rchild;}
}
【算法分析】
遍历线索二叉树,每个结点只访问一次,因此时间复杂度为 O(n),没有借助额外空间,空间复杂度为 O(1) 。