设计模式--装饰器模式
装饰器模式,最常用的设计模式之一
这是一个新的工程。我们有一个类叫做 `HistorySet`,它带有一个泛型参数,表示集合中的元素类型。这个集合既像普通的 `Set` 一样支持增删改查,又能在元素被 `remove` 掉的时候保留历史记录。
我们先思考如何实现这个功能。既然它是一个 `Set`,我们可以直接实现 `Set<E>` 接口,然后实现其中的所有方法。不过我们重点关注的是 `remove` 方法——如何在删除元素的同时,记录下被删除的元素?
我们可以用一个 `List<E>` 来保存这些被删除的元素,比如命名为 `removedList`。当一个元素成功从集合中移除后,我们就把这个元素添加到 `removedList` 中。
public class HistorySet<E> implements Set<E> {List<E> removeList = new ArrayList<>();@Overridepublic int size() {return 0;}@Overridepublic boolean isEmpty() {return false;}@Overridepublic boolean contains(Object o) {return false;}@Overridepublic Iterator<E> iterator() {return null;}@Overridepublic Object[] toArray() {return null;}@Overridepublic boolean remove(Object e){return false;}@Override public boolean containsAll(Collecction<?> c){return false;}@Overridepublic void clear(){}@Overridepublic String toString(){return hashSet.toString() +" remove list: " + removeList;}
}现在的问题是:如何实现 `Set` 接口的其他方法?如果我们有一个已经实现了 `Set` 接口的类(比如 `HashSet`),能不能把所有功能都委托给它来完成,而我们只需要在关键的地方(如 `remove`)做增强处理?
答案是可以的。我们在 `HistorySet` 内部持有一个 `Set<E>` 的实例,比如
private Set<E> hashSet =new HashSet<>();
这样,`size()` 就直接返回 `hashSet.size()`,`isEmpty()` 返回 `hashSet.isEmpty()`,`add()` 直接调用 `hashSet.add()`,其他方法也都交给这个内部的 `HashSet` 去完成。
唯独 `remove` 方法我们需要特殊处理。因为 `remove` 有返回值:如果返回 `true`,说明元素确实被移除了;如果返回 `false`,说明元素原本就不在集合中,无需处理。因此,我们先调用 `hashSet.remove(o)`,判断返回值:
@Override
public boolean remove(Object o) {if(hashSet.remove(o)){removeList.add((E)o);return true;}return false;
}
注意这里有个泛型问题:`remove` 参数是 `Object` 类型,而我们要存入 `List<E>`,所以需要强制类型转换。在实际使用中应确保类型安全。
接下来我们写一个测试的 `main` 函数。创建一个 `HistorySet<Integer>` 实例,可以用 `Set<Integer>` 多态引用:
public class Main {public static void main(String[] args) {Set<String> set = new HistorySet<>();set.add("1");set.add("2");set.add("3");set.add("4");set.remove("4");set.remove("4");set.remove("5");set.remove("1");System.out.println(set);}
}然后我们打印这个 `set`。但我们还没写 `toString()` 方法,已经补上
[2,3] remove list : [4,1]
运行后输出显示:当前集合中有 2 和 3,被删除的元素是 4 和 1,而 5 因为从未存在过,所以没有被记录。
我们再回头看这个 `HistorySet` 类。我们实现了 `Set` 接口,但我们自己并没有真正实现任何 `Set` 的逻辑,而是把所有操作都交给了内部的 `HashSet`。这说明我们其实并不依赖 `HashSet`,只要是 `Set` 的实现都可以。
那如果我们希望底层是有序的 `Set`(比如 `TreeSet`),怎么办?我们可以让用户在构造时传入一个 `Set` 实例,而不是固定使用 `HashSet`。private Set<E> hashSet =new TreeSet<>();
于是我们修改构造函数:
```java
public HistorySet(Set<E> delegate) {
this.delegate = delegate;
}
```
这个 `delegate` 就是被代理的对象。我们在创建 `HistorySet` 时传入一个 `HashSet` 或 `TreeSet` 都可以:
public HistorySet(Set<E> hashSet) {this.delegate = hashSet;
}List<E> removeList = new ArrayList<>();
private final Set<E> delegate;这样,`HistorySet` 的职责就非常清晰:它只是一个“包装器”,只增强 `remove` 功能,其余所有行为都由代理对象完成。
这就是**装饰器模式**的核心思想:通过包装一个对象,在不改变其原有功能的前提下,增加新的行为或功能。
更进一步,既然 `HistorySet` 本身也是一个 `Set`,那我们能不能把它再包装一次?比如:装饰的historyset作为set进一步放到historyset中,记录分别remove的系统;
public class Main {public static void main(String[] args) {Set<String> historySet = new HistorySet<>(new HashSet<>());Set<String> set = new HistorySet<>(historySet);set.add("1");set.add("2");set.add("3");set.add("4");set.remove("4");set.remove("4");set.remove("5");set.remove("1");System.out.println(set);}
}这时,`doubleHistorySet` 内部嵌套了两个 `HistorySet`。每次成功删除一个元素,两个包装器都会记录一次。运行测试后可以看到,两个 `removedList` 都记录了相同的删除操作。
【2,3】remove list :[4,1] remove list :[4,1]
这说明装饰器可以层层叠加,形成“装饰链”。
我们来看一个 JDK 中的经典例子:`Collections.synchronizedCollection(Collection<T> c)`。它接收一个 `Collection`,返回一个线程安全的包装版本。
Collection<Object> objects =Collections.synchronizedCollection(new ArrayList<>());
点进去看源码,它返回的是 `SynchronizedCollection`,这个类实现了 `Collection`,内部持有一个 `Collection` 对象(称为 `c`),所有方法都委托给 `c` 执行,比如:
```java
public int size() {
synchronized (mutex) { return c.size(); }
}
public boolean isEmpty() {
synchronized (mutex) { return c.isEmpty(); }
}
```
唯一的区别是,每个方法都加了 `synchronized` 锁,锁的是一个互斥对象 `mutex`(通常是 `this`)。这样就实现了线程安全。
但要注意:单个方法是线程安全的,但多个方法的组合操作不是原子的。比如:
```java
if (collection.isEmpty()) {
collection.add(item); // 这不是原子操作!
}
```
在多线程环境下,这个判断加添加的操作仍然可能出错,需要额外同步。
这是装饰器模式的又一应用:在不修改原始类的情况下,增加同步控制。
再看第三个例子:有一个 20MB 的 PDF 文件,我们需要一个字节一个字节地读取。我们使用 `FileInputStream`:
public class Main {public static void main(String[] args) {File file = new File("jvm.pdf");long l = Instant.now().toEpochMilli();try(FileInputStream fileInputStream = new FileInputStream(file)){while (true){int read = fileInputStream.read();if(read == -1){break;}}System.out.println("用时:" + (Instant.now().toEpochMilli() - l) + "毫秒");} catch (IOException e) {throw new RuntimeException(e);}}
}测试发现耗时约 8 秒。为什么这么慢?因为 `read()` 每次都是一次 I/O 操作,频繁的小数据读取效率极低。
我们思考:能不能加一个缓冲区?如果能从内存缓冲区读数据,就避免了频繁的 I/O。
于是我们创建一个类:`BufferedFileInputStream`,它也继承 `InputStream`,但内部包装了一个 `FileInputStream`:构造函数传递一下;
public class BufferedFileInputStream extends InputStream {private final byte[] buffer = new byte[8192];private final FileInputStream fileInputStream;public BufferedFileInputStream(FileInputStream fileInputStream){this.fileInputStream = fileInputStream;}@Overridepublic int read() throws IOException {return 0;}@Overridepublic void close() throws IOException {super.close();}
}重写 `read()` 方法:
@Override
public int read() throws IOException {if(buffCanRead()){return readFromBuffer();}refreshBuffer();if(!buffCanRead()){return -1;}return readFromBuffer();
}其中:
- `canReadFromBuffer()` 判断是否还能从缓冲区读取:`position < capacity`
- `refreshBuffer()` 调用 `fis.read(buffer)`,将数据读入缓冲区,更新 `capacity` 和 `position = 0`
- `readFromBuffer()` 返回 `buffer[position++] & 0xFF`(转为无符号 int)
public class Main {public static void main(String[] args) {File file = new File("jvm.pdf");long l = Instant.now().toEpochMilli();try (InputStream fileInputStream = new BufferedFileInputStream(new FileInputStream(file))) {while (true) {int read = fileInputStream.read();if (read == -1) {break;}}System.out.println("用时:" + (Instant.now().toEpochMilli() - l) + "毫秒");} catch (IOException e) {throw new RuntimeException(e);}}
}
public class BufferedFileInputStream extends InputStream {private final byte[] buffer = new byte[8192];private int position = -1;private int capacity = -1;private final FileInputStream fileInputStream;public BufferedFileInputStream(FileInputStream fileInputStream) {this.fileInputStream = fileInputStream;}@Overridepublic int read() throws IOException {if (buffCanRead()) {return readFromBuffer();}refreshBuffer();if (!buffCanRead()) {return -1;}return readFromBuffer();}private int readFromBuffer() {return buffer[position++] & 0xFF;}private void refreshBuffer() throws IOException {capacity = this.fileInputStream.read(buffer);position = 0;}
}为了实现这几个函数,我们先思考一个问题,Read from buffer,我们从这个buffer中拿到一个字节,那么我们应该拿取哪个位置的字节呢,于是我们可以用一个标记位去标记position,最开始可以是零,标记着我们现在读到了这个buffer的什么位置,那么第二个问题,假如我们现在有一个8192长度的buffer,但是我们的FileInputStream整个字节流都没有8192,那么我们这个buffer是填不满的,所以说我们不能直接把整个buffer一个一个地读取完毕,那么我们应该用一个容量capacity,我们初始化也是零,去标记着我们这个buffer到底有效读取长度是多少,而不能是一次性无脑把8192全都读完,那么我们可以看一下这个buffer的read方法,OK,那么现在我们来思考bufferCanRead,什么时候这个buffer是能读的呢,首先在初始化的时候,这个position和capacity都是零,那肯定是不能读取的,所以当capacity等于零的时候肯定是不能读的,返回false,OK,那如果capacity不是零,假如说现在的capacity是8192,我们的整个Buffer是填满的,那么当position走到了capacity的时候,那说明我们已经读到了最后一个字节,那么我们也不能再读了,所以position等于capacity的时候也是不能读的,也返回false,否则就返回true,返回true的时候说明什么呢,说明position在capacity之前,并且capacity大于position,说明我们的buffer是可以读的,好的,现在我们来填充第二个函数,refreshBuffer,首先我们调用refreshBuffer的时候,bufferCanRead一定是返回false的,所以我们可以直接忽略当前position和capacity的具体值,我们直接用内部的FileInputStream去读取,读取到这个buffer的字节数组中,返回的是一个length,表示这次读取真正读取了多少字节,那么我们可以直接用capacity等于这个数字,如果capacity等于零,那么bufferCanRead就会返回false,表示没有可读数据,如果它真正读取出了长度,那么读取出来是多少,我们的capacity就设为多少,这里有一个IOException,我们直接抛出去,因为我们的read方法也要抛出这个异常,交给上层处理就可以了,当我们修改了capacity的长度之后,我们要把position变成零,因为我们要重置这个position,让它从零开始读取,好的,现在我们来填充最后一个函数,readFromBuffer,这个函数就很简单了,直接return buffer[position],但是position在读取之后要自增一,所以是buffer[position++],OK,这里还有一个细节是buffer是一个字节数组,这个字节默认是有符号的,可能为负数,但是我们的返回值要求是0~255,所以我们要与上0xFF,也就是(byte & 0xFF),去掉符号位的影响,让其转换为无符号整数,这样的话,我们的整个BufferedFileInputStream就写完了,其实整个流程很简单,我们只是包装了一下这个FileInputStream,然后在它读取的时候,我们进行了一些buffer的拦截,如果buffer里面可以读的话,我们就从buffer里面读,如果buffer不可以读的话,我们就调用refreshBuffer去填充buffer,这样的话我们就极大地减少了真正的IO操作次数,那么我们来试一下,我们修改之后的这个BufferedFileInputStream,它到底有多快,我们之前用了八秒来读取整个文件,那么我们把它换成BufferedFileInputStream,然后在里面封装一个FileInputStream,把这个file传进去,我们整个是一个InputStream类,其他函数一行都不用变。
这样,我们用 `BufferedFileInputStream` 包装 `FileInputStream`,就能大幅提升性能。再次运行测试,时间从 8 秒降到 46ms,性能提升两个数量级。
我们还可以验证正确性:同时用原始 `FileInputStream` 和包装后的流读取,对比每次读取的字节是否一致。如果程序正常结束,说明我们的 `BufferedFileInputStream` 行为正确。
这就是为什么我们说 Java I/O 体系是装饰器模式的经典应用:`BufferedInputStream`、`DataInputStream`、`ObjectInputStream` 等都可以层层包装 `InputStream`,每个装饰器只负责自己的功能(缓冲、数据解析、对象序列化等),而原始流只负责读取字节。
最后留一个思考题:你能否在 `InputStream` 的基础上再装饰一层,用来记录 `read()` 方法被调用了多少次?下期我将用装饰器模式实战一个综合案例。
如果你想实现读取行数,我的建议是不要直接在BufferedFileInputStream直接写代码。 而是自己再定义一个CountFileInputStream 然后把BufferedFileInputStream传进来,这样能体现装饰器模式多层装饰的效果
为什么不直接继承: 1. 装饰器的功能可能依赖被装饰对象的特性,比如视频中的例子,需要让set有序,那只能包装TreeSet,HashSet满足不了需求。 2. 如果被装饰的对象是final就没办法继承 3. Java只能单一继承,如果你需要继承其他类那就做不到了。 4. 装饰器可以多次装饰,层级装饰,你可以发挥想象力各种封装组合,但是继承不可以。 5. 组合永远优于继承
实战部分
这是一个简单的 Spring Boot 工程,项目中只有一个依赖:`spring-boot-starter-web`,版本是 3.4.1。工程里有一个启动类、一个简单的 Controller,Controller 中只有一个 POST 请求接口,接收请求体(request body)的 JSON 数据,并原样返回。
代码非常简单:
/*** @author gongxuanzhangmelt@gmail.com**/
@RestController
@RequestMapping("/api")
public class MyController {@PostMappingpublic Map<String, Object> origin(@RequestBody Map<String, Object> json) {return json;}
}
@SpringBootApplication
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class);}
}我们启动项目,用工具发送一个请求,传入 `{"name": "tom", "age": 12}`,返回结果也是 `{"name": "tom", "age": 12}`,功能正常。
现在我们有一个新需求:希望在不修改原有逻辑的前提下,**自动为所有通过 `@RequestBody` 接收的 Map 类型数据添加一个时间戳字段**,比如返回结果自动变成:
```json
{
"name": "tom",
"age": 12,
"timestamp": 1712345678901
}
```
也就是说,我们想通过一个自定义注解,比如 `@TimestampRequestBody`,来实现这个功能。但这一次,我们不直接查文档或问 AI,而是通过**打断点、读源码、一步步调试**的方式来实现。
我们先在 `test` 方法的参数 `data` 上打一个断点,看看这个 `Map` 是什么时候创建的。进入调试后,调用栈显示前面有很多反射相关的调用。我们从最开始的方法看起:
当前方法的参数 `data` 是一个 `LinkedHashMap`,内容就是我们传入的 JSON。我们向上查看这个参数值是从哪里来的,发现它来自 `getMethodArgumentValues()` 方法。
进入该方法,它会根据 Controller 方法的参数个数创建一个 `args Object[]` 数组,用于存放每个参数的值。我们的方法只有一个参数,所以数组长度为 1。
接下来关键逻辑是:遍历所有 `HandlerMethodArgumentResolver`(处理器方法参数解析器),判断哪一个支持当前参数,然后调用其 `resolveArgument()` 方法来解析并返回参数值。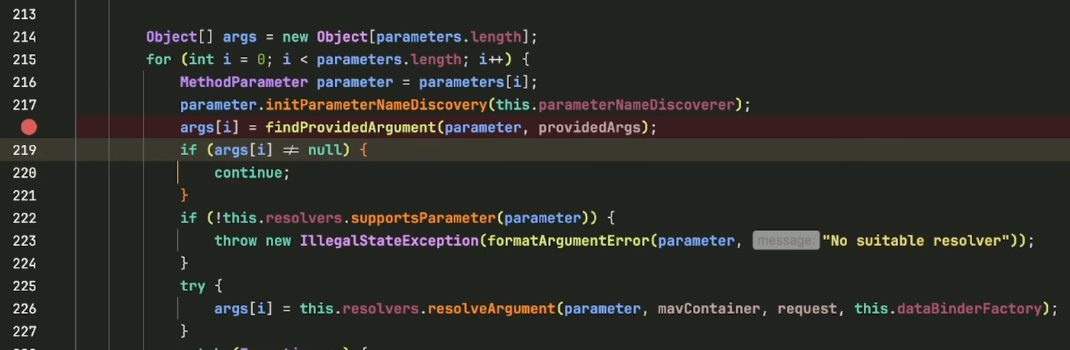
我们继续调试,发现最终是某个 `HandlerMethodArgumentResolver` 的 `resolveArgument` 方法返回了那个 `LinkedHashMap`。我们查看这个解析器的类型,发现是 `RequestResponseBodyMethodProcessor`。
我们点进去看这个类,它实现了 `HandlerMethodArgumentResolver` 接口,该接口有两个方法:
- `supportsParameter(MethodParameter parameter)`:判断是否支持该参数;
- `resolveArgument(...)`:真正解析参数并返回值。
我们看 `supportsParameter` 的实现,只有一行代码:判断参数是否标注了 `@RequestBody` 注解。所以只要参数加了 `@RequestBody`,Spring 就会选择这个解析器来处理。
而 `resolveArgument` 方法,正是**真正将 JSON 反序列化为 Map 的地方**。我们不需要关心它内部如何用 Jackson 解析,我们只关心:它返回了我们想要的 `Map`。
---
现在我们想:能不能“装饰”这个 `RequestResponseBodyMethodProcessor`?让它先完成原本的解析功能,然后我们再对结果进行增强——比如往 Map 里 put 一个时间戳。
这就是**装饰器模式**的思想:不改变原有逻辑,只在原有功能基础上增强。
我们新建一个类:`TimestampRequestBodyMethodProcessor`,也实现 `HandlerMethodArgumentResolver` 接口。
我们再定义一个自定义注解:`@TimestampRequestBody`,仿照 `@RequestBody` 的写法:
```java
@Target(ElementType.PARAMETER)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface TimestampRequestBody {}
```
然后在 `TimestampRequestBodyMethodProcessor` 中:
```java
@Override
public boolean supportsParameter(MethodParameter parameter) {
return parameter.hasParameterAnnotation(TimestampRequestBody.class);
}
```
接下来是 `resolveArgument` 方法的实现。我们想:如果我能拿到那个原始的 `RequestResponseBodyMethodProcessor`,让它先解析出 Map,然后我再往里面加时间戳,就完成了。
所以我们需要一个成员变量,持有被装饰的 `RequestResponseBodyMethodProcessor`:
```java
private final RequestResponseBodyMethodProcessor delegate;
@Override
public Object resolveArgument(...) throws Exception {
Object result = delegate.resolveArgument(parameter, mavContainer, webRequest, binderFactory);
if (result instanceof Map) {
((Map<String, Object>) result).put("timestamp", System.currentTimeMillis());
}
return result;
}
```
这样,我们就实现了功能增强,而不需要知道原始解析器内部如何工作。
---
但问题来了:我们有两个问题要解决:
1. 如何拿到那个 `RequestResponseBodyMethodProcessor`?
2. 如何把我们自己的 `TimestampRequestBodyMethodProcessor` 注册到 Spring 的参数解析器列表中?
---
先解决第二个问题:注册自定义参数解析器。
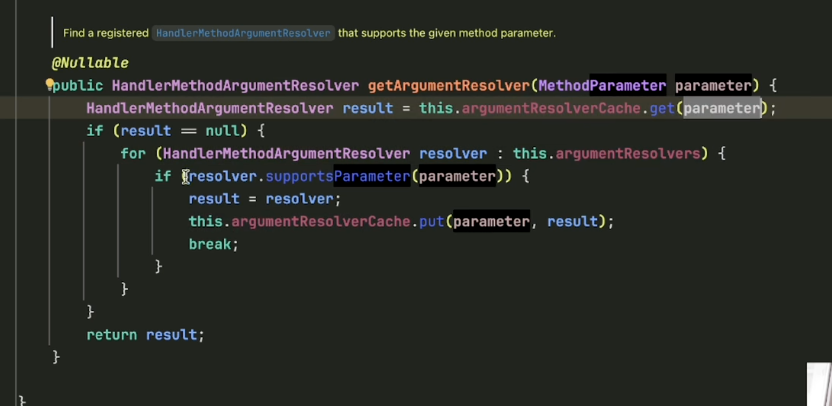
我们回到调试,查看 `HandlerMethodArgumentResolverComposite`(参数解析器组合类)的内部,发现它持有一个 `List<HandlerMethodArgumentResolver>`,里面共有 27 个解析器。我们找到 `RequestResponseBodyMethodProcessor` 在第 8 个位置。
这个列表是怎么来的?我们继续向上看,发现是在 `RequestMappingHandlerAdapter` 中通过 `getDefaultArgumentResolvers()` 创建的。
我们点进去,发现是一大段“屎山代码”:Spring 硬编码 new 出了所有默认的解析器,并放入列表。
但注意到其中有一段:
```java
addCustomResolvers(customArgumentResolvers);
```
这说明 Spring 提供了扩展点:我们可以通过配置,将自定义的解析器添加进去。
我们继续调试,发现 `customArgumentResolvers` 来自 `WebMvcConfigurationSupport` 类中的一个方法:`addArgumentResolvers()`。
而这个方法是一个空方法,说明它是**留给用户重写的钩子方法**。
再看 `WebMvcConfigurationSupport` 的子类,发现只有一个:`DelegatingWebMvcConfiguration`,它会收集所有实现了 `WebMvcConfigurer` 接口的 bean,并调用它们的 `addArgumentResolvers` 方法。
所以,我们只需要:
1. 创建一个配置类,实现 `WebMvcConfigurer`;
2. 重写 `addArgumentResolvers` 方法,把我们的 `TimestampRequestBodyMethodProcessor` 加进去。
代码如下:
```java
@Configuration
public class MyWebMvcConfig implements WebMvcConfigurer {
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> resolvers) {
resolvers.add(new TimestampRequestBodyMethodProcessor(/* 需要传入 delegate */));
}
}
```
这样,我们的解析器就会被加入到 Spring 的解析器列表中,共 28 个。
---
现在解决第一个问题:如何拿到 `RequestResponseBodyMethodProcessor`?
我们不能用 `@Autowired` 直接注入,因为它不是 Spring 管理的 Bean——它是直接 `new` 出来的。
但我们可以通过 `RequestMappingHandlerAdapter` 拿到它。这个 `adapter` 是 Spring 管理的 Bean,它内部持有所有参数解析器。
所以我们可以在配置类中注入 `ApplicationContext`,然后在 `addArgumentResolvers` 中获取 `RequestMappingHandlerAdapter`,遍历其 `argumentResolvers`,找到 `RequestResponseBodyMethodProcessor`,作为 delegate 传入。
但要注意:此时 `RequestMappingHandlerAdapter` 可能还未初始化,直接获取会有循环依赖。
解决方案:**延迟初始化**。我们不在构造函数中赋值,而在 `resolveArgument` 第一次调用时再去容器中查找并设置 delegate。
我们修改 `TimestampRequestBodyMethodProcessor`:
```java
private RequestResponseBodyMethodProcessor delegate;
public void setDelegate(RequestResponseBodyMethodProcessor delegate) {
this.delegate = delegate;
}
private void initDelegate(ApplicationContext context) {
if (delegate != null) return;
RequestMappingHandlerAdapter adapter = context.getBean(RequestMappingHandlerAdapter.class);
for (HandlerMethodArgumentResolver resolver : adapter.getArgumentResolvers()) {
if (resolver instanceof RequestResponseBodyMethodProcessor) {
this.delegate = (RequestResponseBodyMethodProcessor) resolver;
return;
}
}
}
```
然后在 `resolveArgument` 开头调用 `initDelegate`。
---
最后,我们在 Controller 中使用我们的注解:
```java
@PostMapping("/test")
public Map<String, Object> test(@TimestampRequestBody Map<String, Object> data) {
return data;
}
```
重启应用,发送请求,返回结果成功包含 `timestamp` 字段。
---
我们回顾整个过程:
- 我们通过调试,找到了 `@RequestBody` 的解析器是 `RequestResponseBodyMethodProcessor`;
- 我们用装饰器模式包装它,增强其功能;
- 我们通过实现 `WebMvcConfigurer`,将自定义解析器注册到 Spring 中;
- 我们通过 `ApplicationContext` 延迟获取被装饰的对象,避免了依赖问题。
整个过程没有修改任何 Spring 内部代码,完全基于扩展机制实现。
---
思考题:
`WebMvcConfigurerComposite` 和 `HandlerMethodArgumentResolverComposite` 都是“组合模式”的体现,它们有什么不同?
前者是将多个 `WebMvcConfigurer` 的配置方法合并执行,后者是将多个 `ArgumentResolver` 组合成一个解析链。它们的职责不同:一个是配置聚合,一个是执行链路。