使用kettle批量调用大模型
背景:
最近接到一个需求,需要根据医生书写的出院记录,定时去调用大模型生成健康指导,经分析和评估,发现实现的方式比较多,其实核心就是定时任务+api调用,这里分享下使用kettle实现的路径。
第一步:
新建转换,我们需要用到的对象有:
表输入:用于读取数据库中需要大模型生成的内容;
http post:用于调用大模型的API;
JavaScript代码块:用于解析api返回的参数;
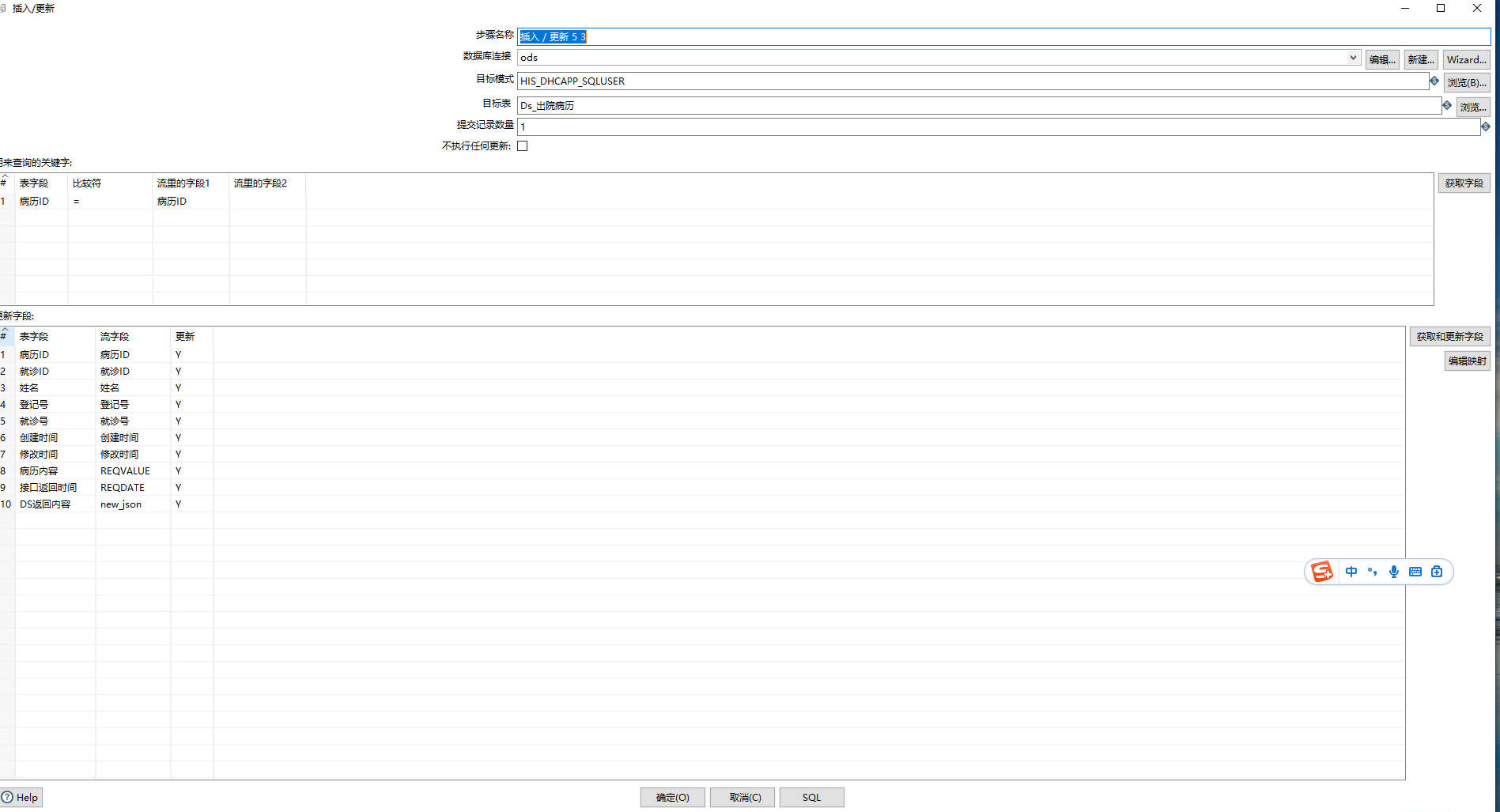
插入/更新:用于记录API返回到数据库。
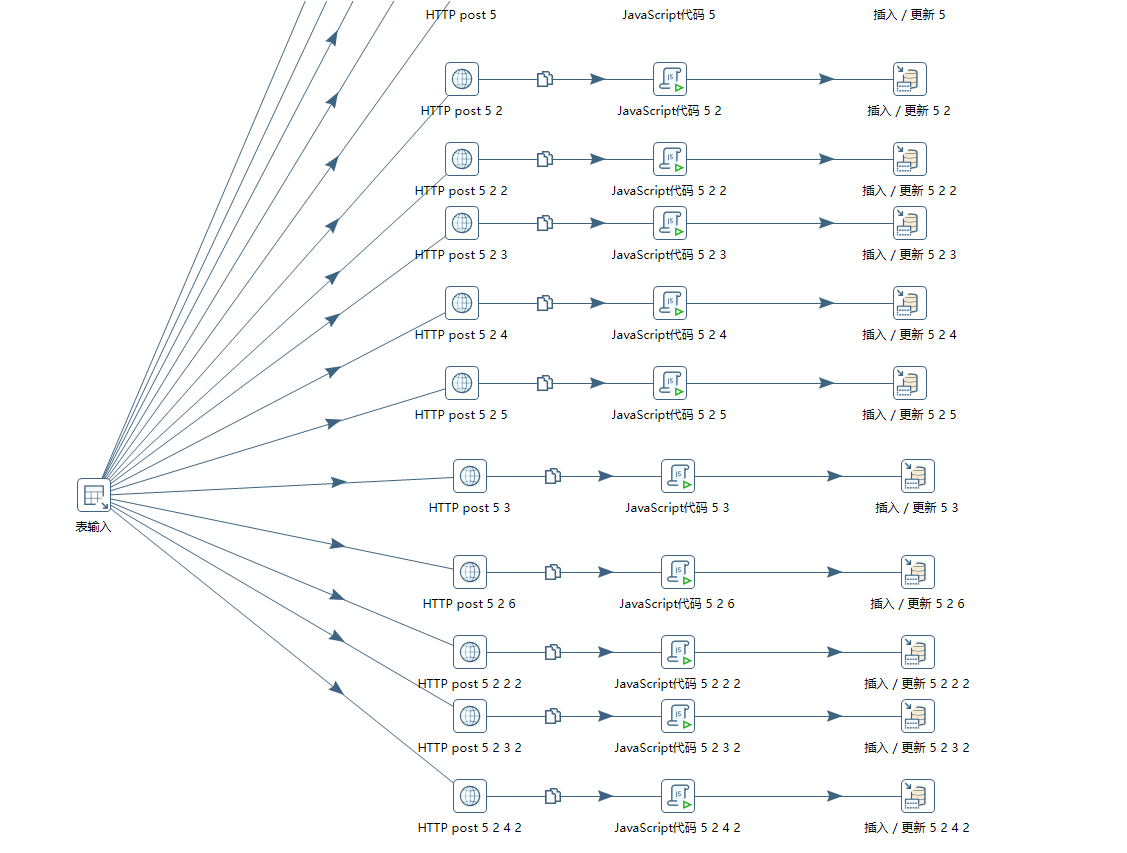
这里注意我将后面的对象都多复制了几次,是为了实现并发处理,因为类似deepseek之类的模型,api返回时有大量的思考内容,返回比较慢,为了提高执行效率,所以使用了并发。
第二步:
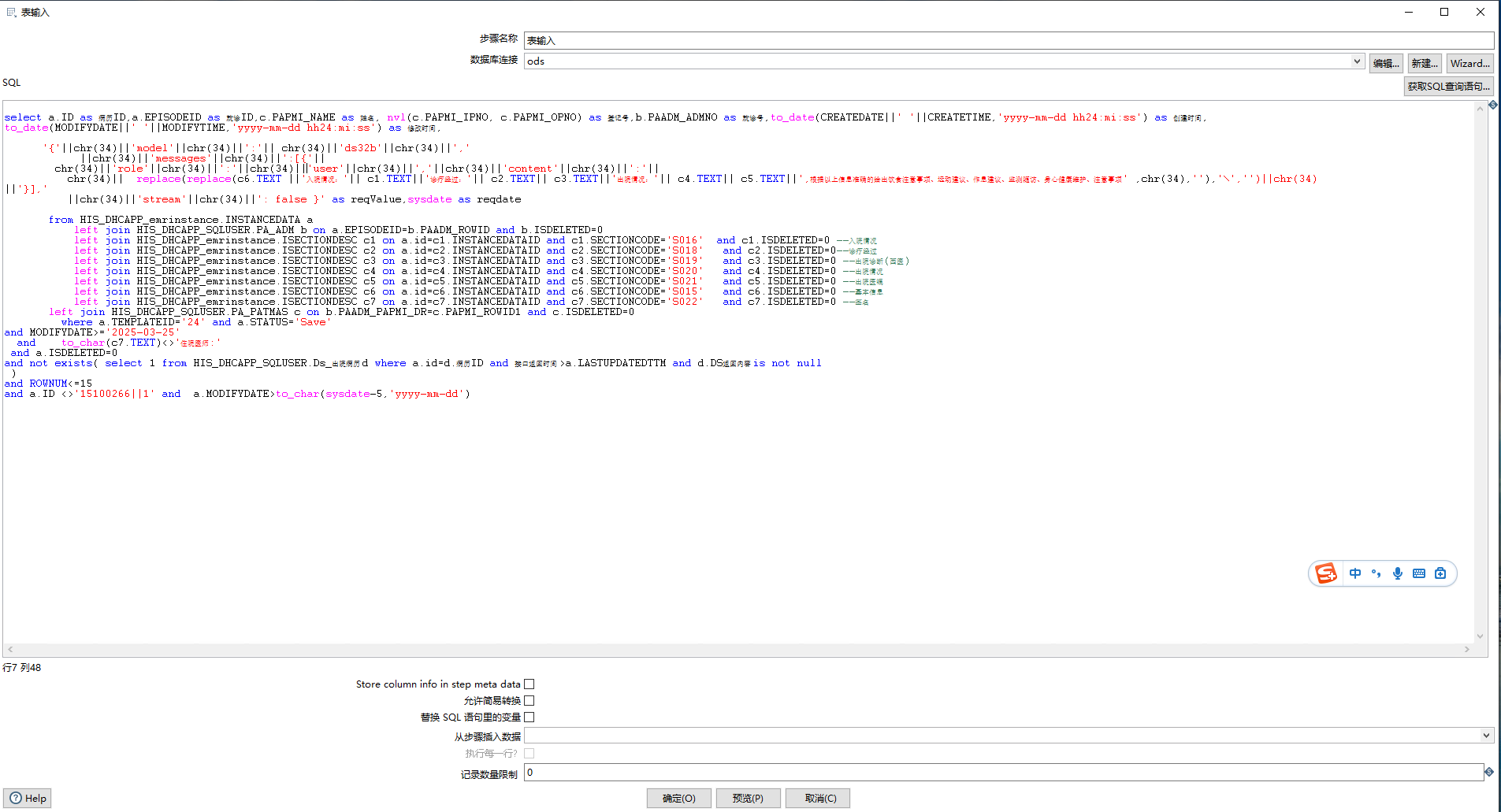
表输入的sql语句仅供参考,实现方式比较多,根据具体不同模型的api需要实现,也跟数据库本身的支持相关,最简单的实现方式是将需要的入参以字符串的形式拼接为json串。
第三步:
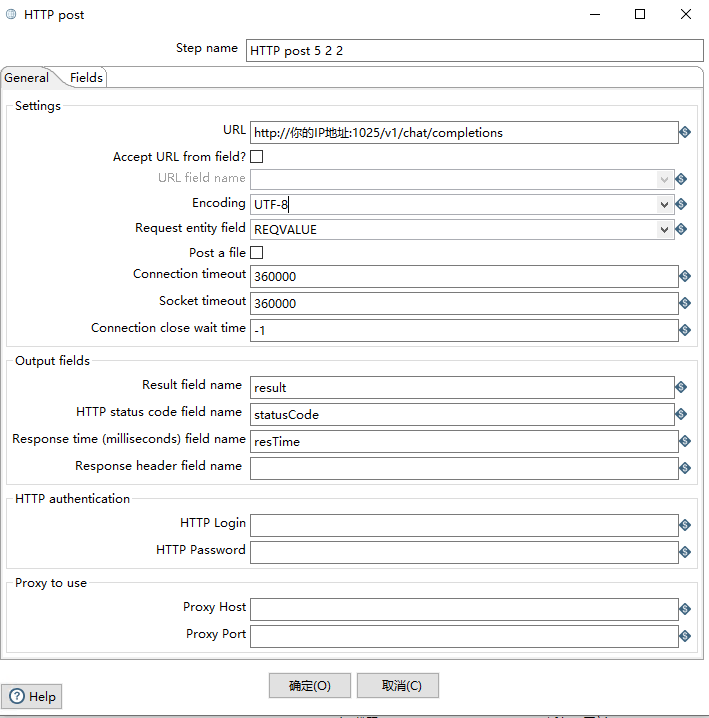
HTTP post 的配置,根据你选择的大模型确定,这里我以openAI的api协议为例
第四步:
JavaScript代码块 的配置,也可以不需要,直接将返回的内容持久化存储即可,后续应用端解析,根据自己的情况判断。
// 检查 result 是否存在
if (result) {try {var resultJson = JSON.parse(result);// 检查 choices 数组是否存在if (resultJson.choices && resultJson.choices.length > 0) {var newJson = {"role": resultJson.choices[0].message.role,"response": resultJson.choices[0].message.content,"tool_calls": resultJson.choices[0].message.tool_calls};new_json = JSON.stringify(newJson);} else {// 如果 choices 数组不存在或为空,设置 new_json 为空字符串或其他默认值new_json = "";}} catch (e) {// 处理 JSON 解析错误new_json = "";// 你可以在这里添加日志记录,方便后续排查问题// 例如:logError("JSON 解析错误: " + e.message);}
} else {// 如果 result 为空,设置 new_json 为空字符串或其他默认值new_json = "";
}
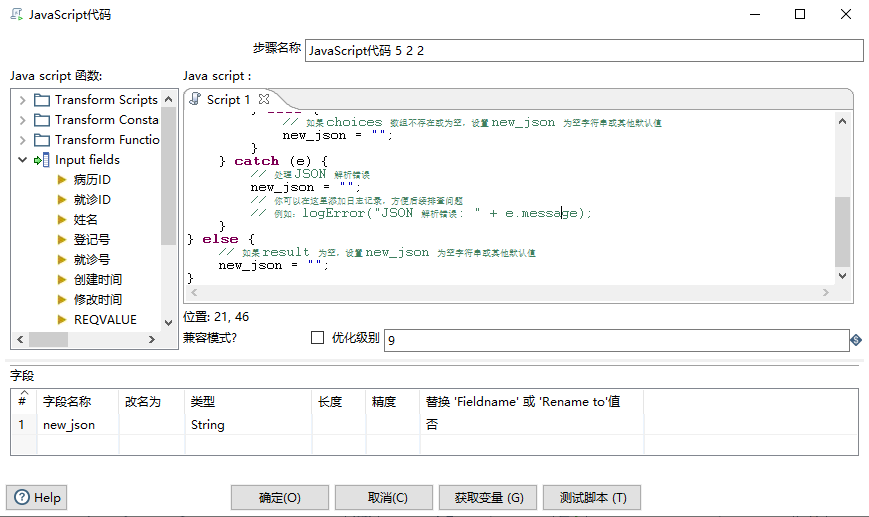 }
}
第五步:
插入/更新,根据自己需要记录的数据库表实现。