2025年最新AI大模型原理和应用面试题
1、什么是 RAG?RAG 的主要流程是什么?
什么是 RAG?
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合信息检索和生成式模型的技术方案。其主要流程包括两个核心环节:
- 检索(Retrieval): 基于用户的输入,从外部知识库中检索与查询相关的文本片段,通常使用向量化表示和向量数据库进行语义匹配。
- 生成(Generation): 将用户查询与检索到的内容作为上下文输入给生成模型(如 GPT等),由模型输出最终回答。
即我们在本地检索到相关的内容,把它增强到提示词里,然后再去做结果生成。简单来说就是利用外部知识动态补充模型生成能力,既能保证回答的准确性,又能在知识库更新时及时反映最新信息(还有一点就是部分业务是内部文档,网上没有,因此可以本地提供知识库来增强 AI的知识)。
RAG 的主要流程是什么?
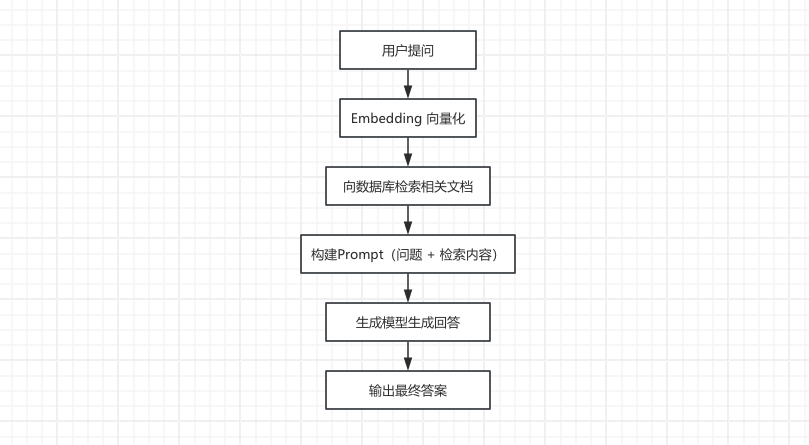
2、什么是 RAG 中的分块?为什么需要分块?
分块就是把原始长文本(比如一本书、一篇论文)拆成若干个“小块”(通常几百字到上千字,比如500-1000字),每个小块包含相对完整的语义单元,比如一个段落、几个段落或一个小节。为什么需要分块?
- 模型处理能力限制:大语言模型(如GPT)一次能处理的文本长度有限,太长的文本塞进去会“消化不良”,分块后每个小块能塞进模型的“肚子”里。
- 精准定位信息:用户提问通常针对局部内容(比如“第三章第二部分的案例是什么”),分块后每个小块像“信息卡片”,检索时能快速找到最相关的卡片,避免在整本大书里“大海捞针”
- 平衡上下文与效率:小块既能保留足够上下文(比如前后句子的逻辑),又能让计算机高效存储和检索(小块的向量计算更快)。
所以分块就是将输入文档或大段文本切分成多个较小的、可控粒度的“块”,以便后续的向量化检索和生成模块高效调用与组会。
3、在 RAG 中,索引流程中的文档解析怎么做的?
在 RAG 的索引流程中,文档解析主要分 5 大核心步骤,分别是“读、洗、拆、标、存”。
- 读(文档加载):支持 多格式解析(PDF/Word/Markdow/HTML/图片等),用工具库(如 PyPDF2 读 PDFDocx2Text 读 Word、Unstructured 处理复杂格式)
- 洗(文本清洗):去除噪声(如页眉页脚、乱码、重复内容),标准化文本(统一大小写、替换特殊符号),处理多语言混合文本(如中英夹杂时保留语义完整性)。
- 拆(文本分块): 按 语义单元拆分成合适长度的“知识块”(常见分块策略) 。
- 标(元数据标注):给每个知识块附加 来源信息(文档标题/URL/作者/上传时间)、结构信息(章节标题/段落位置)领域标签(如“产品手册”“用户协议”),方便后续检索时过滤和排序。
- 存(结构化输出):将分块后的文本和元数据整合成 索引系统能识别的格式(如 JSON/CSV),输出给向量数据库(如FAISS/Elasticsearch)或传统搜索引擎建立索引。
文档加载
常见的文档有很多,例如PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML、HTML等。LangChain 提供了非常强大的文档加载器(Document Loaders)集成 SDK,推荐使用它来集成使用对应的文档解析库即可。例如 csv:
from langchain_community.document_loaders.csv_loader import CSVLoaderloader = CSVLoader(... # <-- Integration specific parameters here
)
data = loader.load()文本清洗
噪声过滤规则:
- 通用规则:去除页眉页脚(关键词匹配,如“第 x页”“版权所有”)、删除重复段落(用哈希值去重)、过滤空白行/超长行(单行长超 2000 字符可能含乱码)。
- 领域定制:法律文档去除“附则”“附录”等固定章节,医疗文档统-“mmHg”“毫米汞柱”等单位表述
多语言处理:
- 语言检测:用 langdetect识别文本语言,混合语言文档(如中英夹杂)需保留原语序(避免拆分导致语义断裂)。
- 特殊字符:用正则表达式替换 \nt为空格,处理全角/半角符号(如“-”转“_”),保留标点符号(句号/逗号对分块至关重要)。
元数据标注
- 来源类:文档 ID(UUID 生成)、文件路径/URL、创建时间/上传时间(用于版本管理)
- 结构类:所在章节标题(如“第三章 第二节 第三条”)、段落序号(用于定位原文位置)、文档类型(如“用户手册”“API 文档”)。
错误处理与鲁棒性
异常场景处理:
-
文档损坏:PDF 加密/Word 乱码时,记录错误日志并跳过(避免阻塞整个流程),人工干预修复后重新解析
-
超长文档:超过 100MB 的大文档先按章节拆分(用正则匹配“第 X章”),再逐章节解析(防止内存溢出)
-
表格/公式:表格转文本时保留行列结构(如用“| 列1|列2"”格式),公式用 LaTeX 转义(如“E= mc?”),避免解析成乱码。
还可以考虑性能优化:
- 并行处理:用多线程/异步框架(如 Python 的concurrent.futures )同时解析多个文档,大文档分块解析时用生成器逐块输出(减少内存占用)。
- 缓存机制:对已解析过的文档(通过文件哈希值判断)跳过解析流程,直接加载历史分块结果(提升增量更新效率)。