深度学习周报(9.1~9.7)
目录
摘要
Abstract
1 LSTM详解
1.2 遗忘门
1.3 输入门
1.4 输出门
1.5 优势与局限性
1.6 两个变体
1.6.1 Bi-LSTM
1.6.2 GRU
2 基于LSTM的代码实战(复现)
2.1 数据加载与预处理
2.2 模型定义
2.3 模型评估与预测
3 总结
摘要
本周主要学习了LSTM的相关内容,包括LSTM的核心结构、优势与局限性以及变体网络,重点了解了遗忘门、输入门与输出门的计算、细胞状态的变化过程、还有双向LSTM和GRU相较LSTM的相关改进与优缺点。此外,本周还对基于LSTM的情感分类项目进行了复现,在加深对LSTM了解的同时,拓展了关于独热向量,贝叶斯优化、超参数自动搜索等的认识。
Abstract
This week , I mainly studied LSTM (Long Short-Term Memory), including its core architecture, advantages and limitations, as well as variant networks. I focused on understanding the computations of the Forget Gate, Input Gate, and Output Gate, the evolution of the cell state, and improvements, advantages, and disadvantages of Bi-LSTM and GRU compared with LSTM. Additionally, I reproduced a sentiment classification project using LSTM. This not only deepened my understanding of LSTM but also expanded my knowledge of related concepts such as one-hot vectors, Bayesian optimization, and automated hyperparameter search.
1 LSTM详解
标准的循环神经网络(RNN)在理论上可以处理任意长度的序列,但在实际训练中,由于梯度消失和梯度爆炸问题,它们很难学习到跨越长时间步的依赖关系。例如最后一个输出往往与最后一个输入关系大,而与第一个输入关系小。
LSTM(Long Short-Term Memory,长短期记忆网络)作为传统RNN网络的变体,相较传统RNN网络而言更能有效捕捉长序列之间的语义关联。它的核心思想是引入一个细胞状态(Cell State),使之能够相对不受干扰地传递信息。同时,还引入了选择性机制--门控机制(Gating Mechanism) 扩展了传统RNN中的中间单元(隐藏状态)来控制信息的输入、输出与遗忘,从而解决了传统RNN的相关问题。
LSTM的核心结构可以分为四个部分,分别是遗忘门、输入门、输出门与细胞状态。具体结构如下所示:
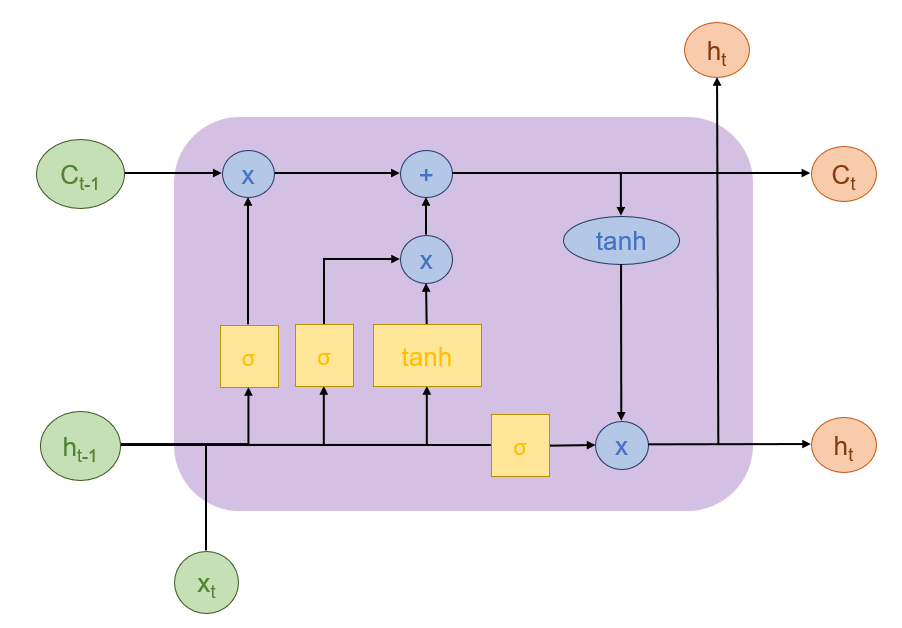
上图中, 与
分别代表上个时间步与当前时间步输出的细胞状态,
经过遗忘门与输入门变为
。
代表当前时间步的输入,
代表上个时间步输出的隐藏状态,
代表当前时间步输出的隐藏状态。
1.2 遗忘门
遗忘门可以决定从记忆单元中丢弃哪些信息。具体而言,它根据当前的输入与上一步的隐藏状态来遗忘多少上一层的细胞状态所携带的过往信息。
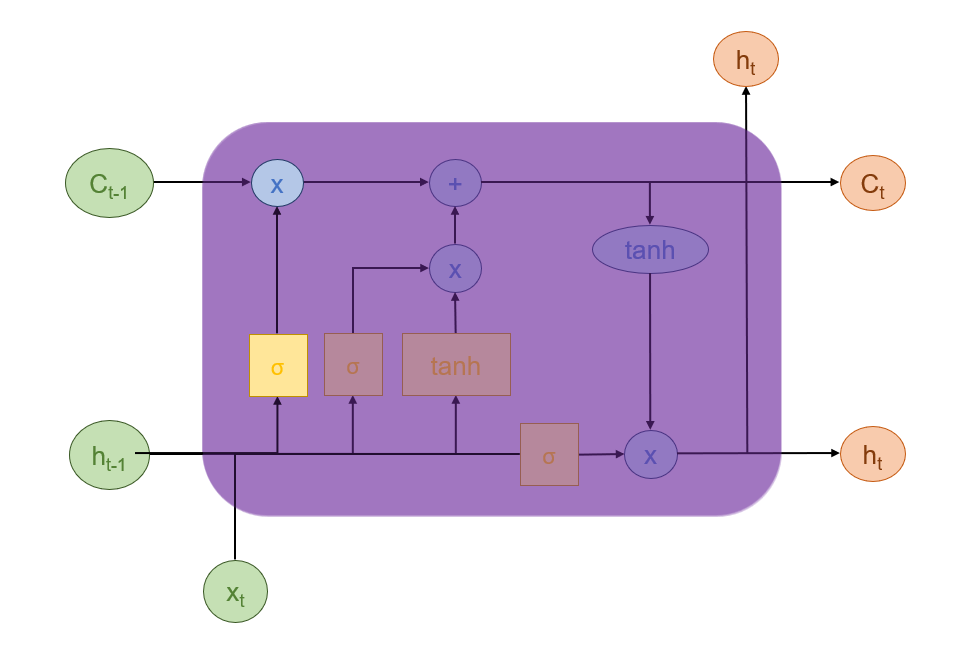
它首先接收上一时间步的隐藏状态 和当前时间步的输入
,将两者进行拼接,然后通过全连接层做变换,最后通过Sigmoid函数输出一个与
维度相同的向量(
),其中每个元素的值都在0到1之间。其公式如下:
会与
进行逐元素相乘以进行细胞状态的更新。若
的某个元素接近 1,那么
中对应位置的值就会被几乎完整地保留下来;若
的某个元素接近 0,那么
中对应位置的值就会被几乎完全丢弃;若
的某个元素是 0.5,那么
对应位置的值就会被减半。
1.3 输入门
输入门可以决定哪些新信息需要被存储到记忆单元中,它的核心作用是决定当前时间步的输入信息中有多少以及哪些部分是重要的,值得被写入(更新)到细胞状态中。它与遗忘门协同工作,共同管理着LSTM的“长期记忆”。
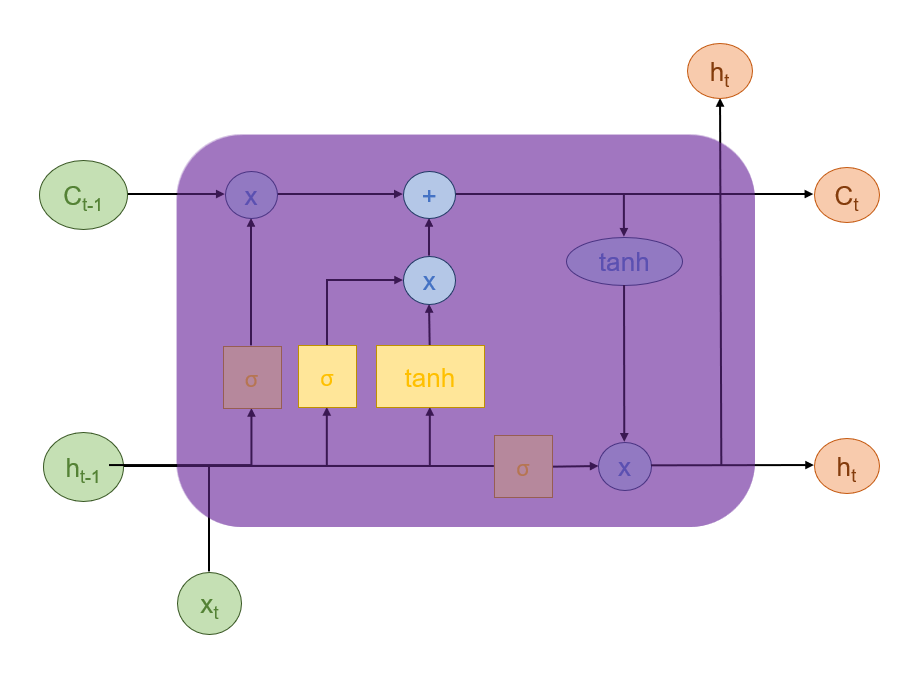
它的计算包含两个并行的部分:一个Sigmoid层和一个tanh层。
前者负责信息筛选以及决策,决定了后者能以多大的强度被添加到记忆中,其公式如下:
后者负责生成候选新信息,它包含了基于当前输入和上下文生成的所有可能的新知识,其公式如下:
这两者计算完成后,同样会进行逐元素相乘,让
综上,可得细胞状态的更新公式如下:
1.4 输出门
输出门用于决定基于当前(经过遗忘门与输入门更新后)的记忆单元状态,输出什么信息作为当前时刻的隐藏状态。
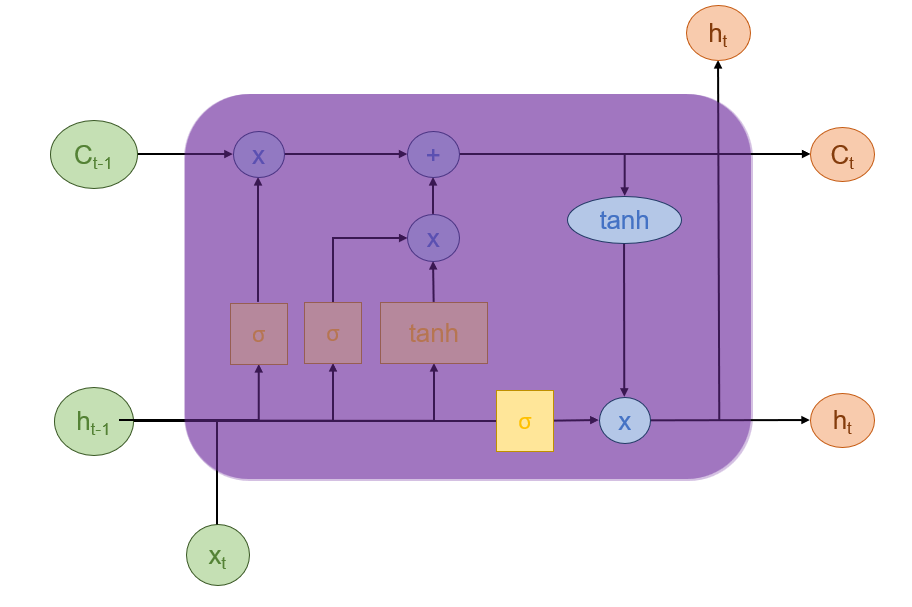
它的计算主要也包括两个部分。
第一部分与上一小节sigmoid层类似,不过作用是负责筛选输出信息,决定从长期记忆(细胞状态) 中提取哪些信息作为当前的短期记忆或可访问状态
,而非选择信息添加到细胞状态中。其公式如下:
第二部分就是利用上述公式生成的决策,从细胞状态 中生成最终的隐藏状态
(同样是逐元素相乘)。
这个隐藏状态一方面作为当前时间步隐藏的输出,另一方面作为下一个时间步的隐藏输入继续发挥作用。
1.5 优势与局限性
LSTM的优势包括:首先它能够解决长期依赖问题,能够有效捕捉序列中相隔较远的时间步之间的依赖关系;其次,它的应用十分广泛,在自然语言处理(NLP)、语音识别、时间序列预测、机器翻译等领域取得了巨大成功;最后,它十分灵活,可以堆叠多层以形成深度LSTM网络,从而学习更复杂的特征。
LSTM的局限性包括:首先它计算复杂度高,LSTM相比标准RNN和GRU,参数更多,训练速度更慢;其次,它并行化困难,由于其序列依赖性,难以像卷积神经网络(CNN)那样高效并行化。最后,近年来,LSTM在许多任务(尤其是NLP)上被基于自注意力机制的Transformer模型超越了。
1.6 两个变体
1.6.1 Bi-LSTM
Bi-LSTM(Bidirectional Long Short-Term Memory,双向长短期记忆网络)是标准 LSTM 的一个重要扩展,由 Schuster 和 Paliwal 于 1997 年提出。由于标准(单向)LSTM 是一个从左到右(或从右到左)处理序列的模型。在时间步 t ,它只能访问从序列开始到 t 时刻的信息(,
, ...,
,
, ...,
Bi-LSTM的突破就在于其核心思想并未改变LSTM的内部结构,而是同时运行两个独立的 LSTM 层,即前向 LSTM(Forward LSTM)与后向 LSTM(Backward LSTM)。前者从序列的开头到结尾(左到右)处理序列,捕获过去的上下文信息。后者从序列的结尾到开头(右到左)处理序列,捕获未来的上下文信息。在任意时间步 t ,Bi-LSTM 的最终表示是前向 LSTM 在 t 时刻的隐藏状态
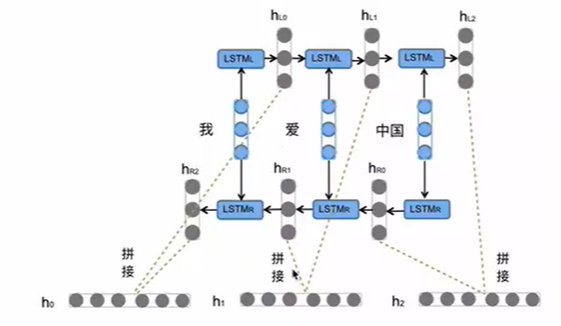
这种结构能够捕捉语言语法中一些特定的前置或后置特征,增强语义关联,但是模型参数和计算复杂度也会随之增加(两个LSTM,通常增加一倍),在使用前一般需要对计算资源进行评估。另外,Bi-LSTM 必须在整个序列都可见的情况下才能进行预测,因为它需要从右到左处理未来信息。而且它并不适用于实时或流式任务,举个例子,实时翻译,你不能等到用户说完一整句话才开始翻译。
1.6.2 GRU
GRU(Gated Recurrent Unit,门控循环单元)Kyunghyun Cho 等人在 2014 年提出的一种简化版的 LSTM。它的目的是在保留 LSTM 强大功能的同时,通过减少门控机制和参数数量来简化模型结构、降低计算复杂度,并加速训练过程。
GRU的核心思想是对 LSTM 的三个门(遗忘门、输入门、输出门)进行简化和合并。
它首先将 LSTM 的遗忘门和输入门的功能合并为一个单一的更新门(Update Gate),这是 GRU 的核心,因为它同时控制着遗忘和更新。它决定了当前隐藏状态有多少来自上一时刻的隐藏状态(旧信息),有多少来自新计算的候选隐藏状态(新信息)。其公式如下:
其次,它移除了独立的细胞状态,它的隐藏状态( )同时扮演了 LSTM 中隐藏状态和细胞状态的角色,是短期记忆与长期记忆的共同载体。
最后,它还引入重置门(Reset Gate,输出为 )来控制信息的写入,若
接近0 表示几乎完全忽略
,
接近 1 表示几乎完全保留
另外,它同样也有一个类似LSTM输入门中生成候选新信息的候选隐藏状态。不同于输入门的是,它需要先控制上一时间步信息的输入,再与当前时间步的输入进行拼接,这个设计允许网络在计算新信息时,有选择地忽略无关的历史信息。其公式如下:
最终隐藏状态公式如下:
相较于LSTM而言,GRU结构更简单,参数更少的同时计算更加高效,也更容易理解。但由于其结构简化,表达能力可能在一定程度上受限,在面对某些极端复杂任务时,LSTM 可能仍有优势。同时,它与LSTM一样,也面临着基于自注意力机制的 Transformer 模型的挑战。
2 基于LSTM的代码实战(复现)
项目来源:基于LSTM的Twitter消息情感分析 - Heywhale.com
数据集来源:Twitter 情绪分析 --- Twitter Sentiment Analysis
该项目主要是给定一条消息和一个实体,判断该消息对该实体的情感倾向。数据集共包含三类情感:正面(Positive)、负面(Negative)和中性(Neutral)。对于与该实体无关的消息(即 Irrelevant),则将其归类为中性(Neutral)。
2.1 数据加载与预处理
#数据加载
columns = ['Tweet_ID', 'entity', 'sentiment', 'Tweet_content'] #定义列名(ID,实体,情感偏向,文本)
# header=None 表示原始文件没有标题行,所以用自定义的 names 来命名列
train_df = pd.read_csv('twitter_training.csv', names=columns, header=None) #训练集
valid_df = pd.read_csv('twitter_validation.csv', names=columns, header=None) #验证集#加载英文停用词(如 "the", "is", "and" 等),方便后续处理
stop_words = set(stopwords.words('english'))#文本清洗
def clean_text(text):if isinstance(text, str):text = text.lower() #统一小写text = re.sub(r"http\S+|www\S+|https\S+", '', text) #去除URLtext = re.sub(r'@\w+|#', '', text) # 去除 @ 和 #text = re.sub(r"[^\w\s]", '', text) # 保留单词和空格text = re.sub(r"\d+", "", text) # 去除数字text = " ".join([word for word in word_tokenize(text) if word not in stop_words]) # 去除停用词return text
train_df['clean_text'] = train_df['Tweet_content'].apply(clean_text)
valid_df['clean_text'] = valid_df['Tweet_content'].apply(clean_text)#文本向量化
MAX_NB_WORDS = 20000 # 最多保留词汇表中频率最高的 20000 个词
MAX_SEQUENCE_LENGTH = 100 # 每条文本最多保留 100 个词,不足补零,超长截断
# .fillna('')作用是将该列中所有缺失值(NaN)转换为空字符串
train_df['clean_text'] = train_df['clean_text'].fillna('').astype(str)
valid_df['clean_text'] = valid_df['clean_text'].fillna('').astype(str)
#初始化tokenizer
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(train_df['clean_text'])
#texts_to_sequences 将文本转化为数字序列;maxlen=MAX_SEQUENCE_LENGTH,统一序列长度为设定值
X_train = pad_sequences(tokenizer.texts_to_sequences(train_df['clean_text']), maxlen=MAX_SEQUENCE_LENGTH)
X_valid = pad_sequences(tokenizer.texts_to_sequences(valid_df['clean_text']), maxlen=MAX_SEQUENCE_LENGTH)#标签编码, 顺序取决于LabelEncoder 的内部排序(通常按字母先后),也可以另外手动排序
label_encoder = LabelEncoder()
train_df['sentiment_label'] = label_encoder.fit_transform(train_df['sentiment'])
valid_df['sentiment_label'] = label_encoder.transform(valid_df['sentiment'])
#将整数标签转为 one-hot 向量(适合 softmax 输出):
y_train = pd.get_dummies(train_df['sentiment_label']).values
y_valid = pd.get_dummies(valid_df['sentiment_label']).values#划分,从训练集中划分20%作为调参子集以调整超参数
X_train_main, X_tune, y_train_main, y_tune = train_test_split(X_train, y_train, test_size=0.2, random_state=42)对于上述代码:
首先,文本清洗部分涉及到了python中的re模块,这个模块主要用于进行字符串的匹配、搜索、替换和分割等操作, 代码中使用的re.sub就是对需要删除的地方用空字符串进行替换。
其次,标签编码如果使用手动编码,代码可能如下:
label_map = {'negative': 0, 'neutral': 1, 'positive': 2}
train_df['sentiment_label'] = train_df['sentiment'].map(label_map)最后,独热向量(One-Hot Vector),又称独热编码,是一种将离散的类别数据转换为机器可读的二进制向量的方法,每个类别用一个独立的维度表示,向量中只有一个元素是 1(表示当前类别),其余所有元素都是 0。
2.2 模型定义
#模型定义
def build_model(hp):model = Sequential([#Embedding的作用是将离散的符号(如单词、字符、类别)映射为连续的、低维稠密的向量表示#input_dim指词汇表大小,output_dim指词向量维度,input_length序列长度Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=100, input_length=MAX_SEQUENCE_LENGTH),#LSTM层(以下定义是一个参与超参数自动搜索的可调结构)#units=... 设置LSTM层的隐藏单元数(最小为64,最大为256,步长为64,可能取值为64、128、192、256)#dropout=... 设置正则化(最小为0.2,最大为0.5,步长为0.1,可能取值类推)LSTM(units=hp.Int('LSTM_UNITS', min_value=64, max_value=256, step=64),dropout=hp.Float('dropout_rate', min_value=0.2, max_value=0.5, step=0.1)),#全连接层Dense(64, activation='relu'),Dropout(0.5),#全连接层,输出长度为3的概率分布Dense(y_train.shape[1], activation='softmax')])# 定义损失函数、优化器与评估指标model.compile(loss='categorical_crossentropy',optimizer=Adam(learning_rate=hp.Choice('learning_rate', values=[0.001, 0.0005, 0.0001])), #学习率参与超参数自动搜索metrics=['accuracy'])return model#运行Bayes优化
tuner = BayesianOptimization(build_model, # 传入一个可调模型的构造函数objective='val_accuracy', # 优化目标:准确率越高越好max_trials=10, # 最多尝试 10 组超参数组合(每组称为一个试验)executions_per_trial=1, # 每组参数只训练一次(较快,可以设为多次后取平均)directory='tuner_results', # 保存搜索结果的文件夹project_name='sentiment_analysis_tuning'
)#启动贝叶斯优化器
tuner.search(X_train_main, y_train_main, epochs=5, batch_size=32, validation_data=(X_tune, y_tune))#获取最佳参数
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]#训练最优模型
best_model = tuner.hypermodel.build(best_hps)
best_model.fit(X_train, y_train, epochs=5, batch_size=32, validation_data=(X_valid, y_valid))贝叶斯优化通过构建代理模型并智能选择下一个评估点,用最少的迭代次数找到最优解,特别适用于目标函数计算代价高、不可导、非凸、无显式表达式的场景。上述代码就是利用贝叶斯进行超参数调优。
超参数自动搜索能够自动、高效地找到机器学习或深度学习模型中最优的超参数组合,以提升模型性能,减少人工调参成本。
2.3 模型评估与预测
#评估
y_pred = best_model.predict(X_valid)
y_pred_classes = np.argmax(y_pred, axis=1) #将概率矩阵转换为预测的类别索引,np.argmax(..., axis=1):对每一行取最大值的下标
y_true = np.argmax(y_valid, axis=1) #将真实标签转换为类别索引#打印详细的分类性能报告
print(classification_report(y_true, y_pred_classes, target_names=label_encoder.classes_))
#打印混淆矩阵
print(confusion_matrix(y_true, y_pred_classes))#加载最优模型进行预测
best_model.evaluate(X_valid, y_valid)3 总结
本周深入学习了LSTM的相关知识,并进行了相应的代码实战,加深自己了对LSTM以及循环神经网络的了解。在复现代码的同时,学到了一些深度学习的新方法,比如超参数自动搜索可以让模型自动选择范围内最优的超参数,而不用自己手动调整。下周预计会对Transformer的相关知识进行学习。