如何短时间内精准定位指标异动根源
1.指标异动分类
凌晨2点,刺耳的手机警报划破寂静:"核心GMV指标异常下跌23%"。 你从床上弹起,咖啡杯在颤抖的手中倾斜,倒计时30分钟开始——这不是电影情节,而是数据工程师的日常战备状态。作为数据仓库开发者,我们比任何人都清楚:指标异动本质是数据管道的伤口。业务部门看到的是仪表盘上的红色箭头,而我们追踪的是从数据源到报表层之间某处数据的问题。什么是指标异动?
这个月的mau下降百分之8%
昨天GMV涨了百分之20%
用户留存上涨了,什么原因引起的?
等等,这些问题都可以说是指异动,当然指标异动也要分不同的类型,具体如下图所示:
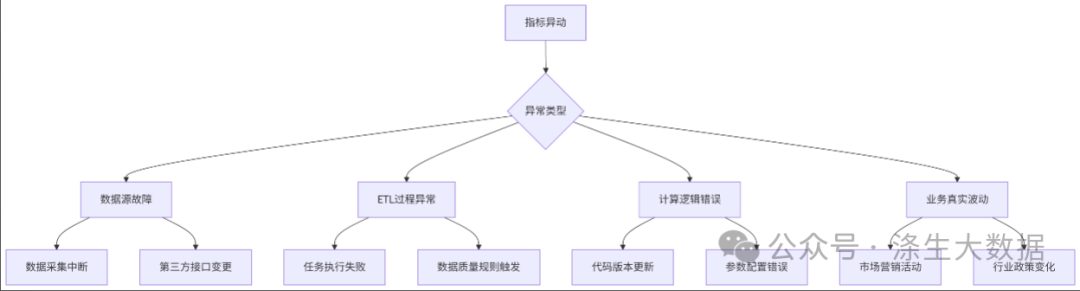
从上图我们可以大致可以将指标异动分为3大类,第一大类就是 偶发性的故障,比如数据源故障、etl过程异常等,这个可以涉及我们数据采集的的中断、etl抽数任务失败等。我们不能保证我们的额平台一次故障都不会产品,我们也不能保障数据的来源一直稳定,所以这些都是属于偶发性的异常。第二大类的异常计算逻辑异常,比如我们自己的指标更新,甚至前置表的更新影响到指标的异动等。第三类就是业务真实数据,由于某个营销活动的开展或者某项政策的影响。
2.快速发现指标异常
当指标在某天发生异动时,我们可以根据下面流程来判断:
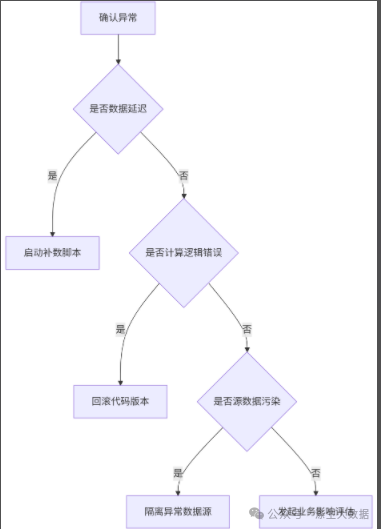
1.首先我们排查一下数据的及时性及准确性,数据是否及时的抽取处理,如果没想办法处理,接着我们判断一下,是否是我们代码逻辑问题,是的话要及时回滚,当然,如果你要测试充分的话,很少会发生此类问题。
2.判断波动性,指标在某天发生波动时,我们如何判断波动属于正常范围还是异常范围,往往是通过口口相传的经验判断的,核心在于「经验」。经验固然是判断指标波动阈值的核心,但对数据同学来说,我们可以更好的利用数据,「量化度量 + 经验」 进行判断,往往会更加标准化一些。
量化的方式可以涵盖很多种,这里我们主要根据 均值+标准差 进行衡量,以APP的DAU(日活)指标为例,如下图:
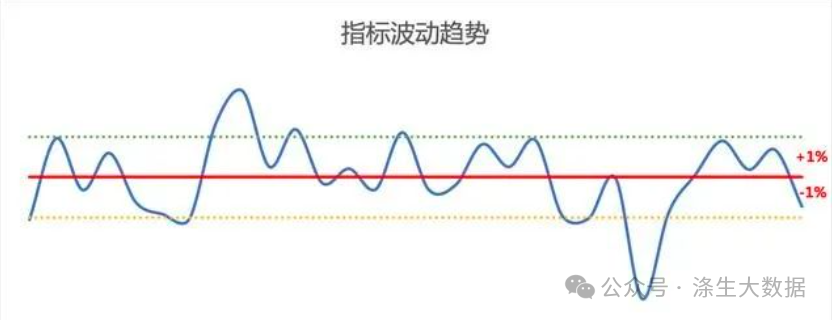
近30日波动趋势
步骤一:选取过去30日内的日活指标作为趋势分析,时间不宜过长,主要考量近期情况。
步骤二:计算指标的均值和标准差,并且根据以往经验,初步选取加减一倍标准差作为正常区间范围,以上图为例,大概是均值±1%。,这里只是举例,具体数值是多少,需要实际调研一次,心里大体有个数,指标的正常波动在什么范围内。
步骤三:在数据评估中,当指标波动大于阈值时,明显异常可重点关注。当然,波动小不代表指标就不存在问题,这里解决的主要是明显异常的问题。
3.定位异动原因
当发觉指标的波动远远超过我们经验的阈值时,我们就要分析具体的原因,这里我们要根据以往的经验和相关的信息,做出最有可能的推测,然后我们验证推测,等处结论,一般情况,这里的分析我们都会使用多维拆解分析,对指标进行下钻分析,通过维度的下钻,聚焦问题点。定位问题的方式也非常多的,这里主要向大家介绍一种相对通用且高效的排查思路,如下图:

分析流程图
从图中我们可以看到,整个排查思路大概6个步骤,这6个步骤我们可以切分为先整体、再细粒度,再整体的流程,最终目的是给出量化的数据结论。
步骤一:多维钻取
当某天指标出现波动异常时,我们下意识的会想到是由于某个维度变化所导致的,例如:某天日活下降,可能是某个渠道、某个产品、某些类目所导致等。相信很多数开同学都是根据自己的经验进行的判断。而且很多时候这种经验极为准确。那我们就基于我们的判断进行维度钻取,维度钻取本身不难,但是难点就在于如何全面、高效的将所有维度都进行钻取,并且可以精准的定位到问题。因此,为了达到全面、高效的目的,需要做以下两点:
1)维度累积。这个就主要靠日常工作中,我们对于业务的理解了,如果将所有可能影响指标的维度提取出来,并且对核心维度进行交叉组合,作为多维钻取的养料。
例如:业务维度(渠道、产品);时间维度(小时、上午/下午/晚上);人群维度(地区、性别)等。
2)工具沉淀。要完成以上众多维度的高效钻取,通过一段段写SQL查询,效率会很低,因此我们需要一套可例行的多维分析工具,这部分内容会在下面几期进行详细介绍。
步骤二:聚焦异常
当我们完成多维钻取,产出各维度涨降幅数据后,就需要将细分维度对整体的影响进行量化度量,即我们常说的:贡献度度量,核心在于量化。
例如:整体日活增长20w,其中男性日活增长5w,则男性对整体大盘pv的贡献度为60%,在结论中需要体现量化结果。其中贡献度在不同类型指标上有不同的计算方式。
在常规业务分析中,一般到此步骤,已经能解决80%左右的实际波动问题。而这两步也可以封装成例行“核心指标监控工具”,每日产出,快速定位数据问题。但如果很不幸遇上了另外20%的情况,即:通过以上维度的下钻,各维度值均表现出普涨/普降的情况,这时就要考虑下钻到微观层面探索问题的本质。
步骤三:案例分析
细粒度层面,我们主要是通过用户明细的行为数据或者轻度汇总数据进行挖掘,这一步主要的目的在于发现可能的异常问题。但由于是单用户行为,会存在诸多干扰的情况,很容易被带偏,所以此步骤的核心在于发现问题,快速试错。
例如:我们通过随机抽取100个用户行为数据,维度涵盖底层数据表已有的所有维度,发现这些用户在某些版本上的行为分布明显较低,则可以将此维度作为聚合维度进行上卷,重复步骤一二的步骤。
到这一步,大概可以解决90%左右的实际波动问题。
步骤四:假设及场景模拟
到此步,如果我们还没能找出核心的问题点,则说明此问题相对太隐蔽,并且是日常维度累积中从来没有涉及到的。这个时候就需要我们根据具体业务场景,假设问题出现的原因,并尝试找到可度量的维度进行一步步验证。到这一步,基本可以解决95%左右的实际波动问题。
步骤五:维度聚合
当进行完步骤三和步骤四之后,我们已经对可能的问题定位到了原因,也有了一定的维度累积,这个时候就可以将此维度上升到宏观层面,利用多维钻取进行挖掘,判断是否是此问题,导致的指标大幅波动。如果仍然不是此问题,那非常遗憾,仍然需要重复步骤三和步骤四,直至找到相应问题。
步骤六:宏观-输出结论
最后也是最为重要的一步,则是对问题下结论。结论输出需要涵盖“数据发现问题”和“业务解释问题“,在与产运方沟通后,得出“业务化”的结论,这样才能更对老板的口味。
例如:
不好的结论:日活下降原因,60%是由于宠物相关的类目影响。
好的结论:日活上升原因,70%是由于昨天的裂变活动影响,主要由于上线推广活动所导致,此活动比较成功。