【深入理解Batch Normalization(1)】原理与作用
1.为什么需要Normalization
深度学习网络模型训练困难的原因是,cnn包含很多隐含层,每层参数都会随着训练而改变优化,所以隐层的输入分布总会变化,每个隐层都会面临covariate shift的问题。
internal covariate shift(ICS)使得每层输入不再是独立同分布。这就造成,上一层数据需要适应新的输入分布,数据输入激活函数时,会落入饱和区,使得学习效率过低,甚至梯度消失。
Batch Normalization 的主要目的是通过减少内部协变量偏移(Internal Covariate Shift) 来加速训练并提高模型的稳定性
2.Normalization的基本思想
由于cnn层数多,ICS会使激活输入分布偏移,落入饱和区,导致反向传播时出现梯度消失,这是训练收敛越来越慢的本质原因。而BN就是通过归一化手段,将每层输入强行拉回均值0方差为1的标准正态分布,这样使得激活输入值分布在非线性函数梯度敏感区域,从而避免梯度消失问题,大大加快训练速度。
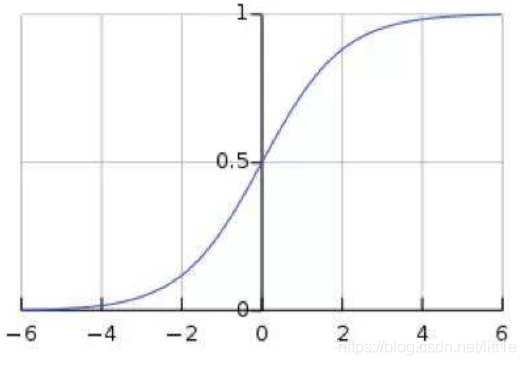
如上图,sigmoid函数,BN使输入值分布在-1~1之间,在此区间梯度值大,有效避免梯度消失并提高收敛速度。
但是,归一化后,激活输入值均被分布于-1~1之间,这会导致非线性程度降低,夸张一点说,其实输入域的分布把原来的非线性函数转变成了线性函数。这意味着网络的表达能力下降了。因此BN为了保证非线性,对变换后的满足均值为0方差为1的x又进行了scale shift操作,即y=scale*x+shift。这两个参数通过训练获得,其实又将输入分布在标准正态分布的基础上进行了平移。其实就是为了在线性与非线性间找到平衡,让泛化能力与收敛能力最大程度的体现。
3、BN中均值、方差通过哪些维度计算得到?
神经网络中传递的张量数据,其维度通常记为[N, H, W, C],其中N是batch_size,H、W是行、列,C是通道数。那么上式中BN的输入集合就是下图中蓝色的部分。
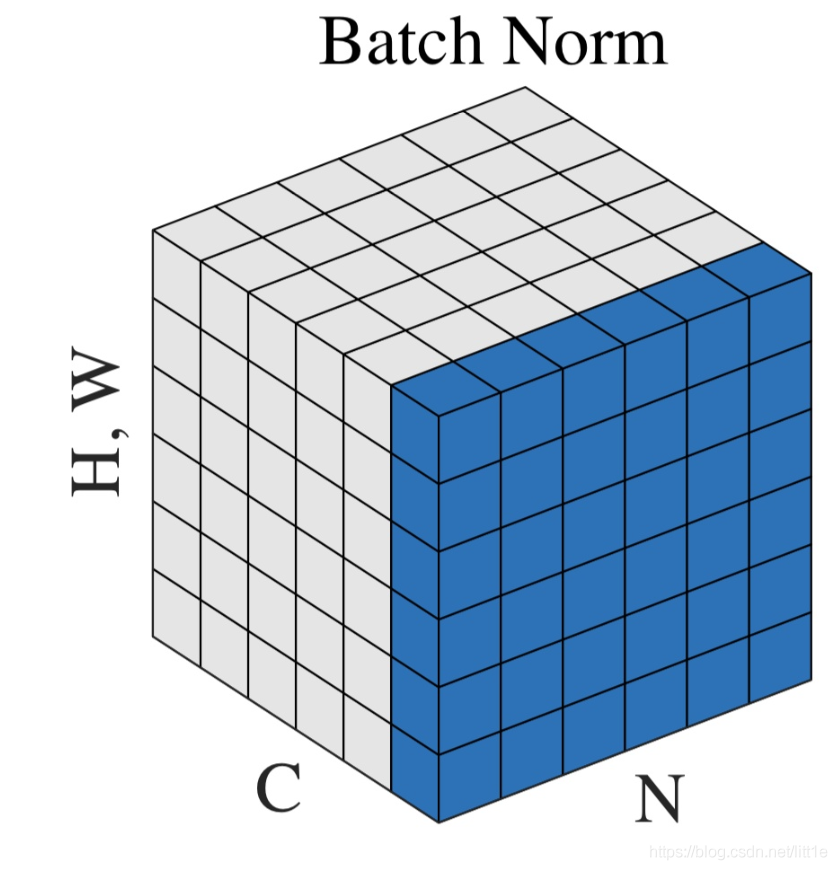
- 均值的计算,就是在一个批次内,将每个通道中的数字单独加起来,再除以 N×W×H。举个例子:该批次内有10张图片,每张图片有三个通道RBG,每张图片的高、宽是H、W,那么均值就是计算10张图片R通道的像素数值总和除以 10×W×H,再计算B通道全部像素值总和除以10×W×H,最后计算G通道的像素值总和除以10×W×H。
- 方差的计算类似。
- 可训练参数 γ , β 的维度等于张量的通道数,在上述例子中,RBG三个通道分别需要一个 γ 和一个 β ,所以 γ , β 的维度等于3。
4.训练BatchNorm
其核心操作是对每一批(Batch)数据的每个特征通道进行归一化:
•计算一个批次数据的均值和方差:对于每个特征通道,计算当前批次所有样本在该通道上所有值的均值(μ)和方差(σ²)。
•归一化:使用计算得到的均值和方差对该通道上的所有值进行归一化:x_hat = (x - μ) / sqrt(σ² + ε),其中 ε 是一个很小的数,防止除以零。
•缩放和偏移:引入两个可学习的参数 γ(缩放)和 β(偏移),对归一化后的值进行变换:y = γ * x_hat + β。这是为了保持模型的表达能力,避免归一化破坏原本已学到的特征分布。
同时,利用当前批次的统计量,通过指数移动平均(EMA) 来更新全局均值(μ)和全局方差(σ²),公式一般为:new_running_mean = (1 - momentum) * running_mean + momentum * batch_mean。
BN 层通常插入在卷积层(或线性层)和激活函数(如 ReLU)之间。

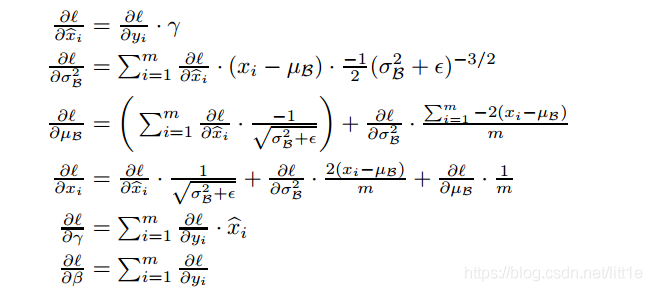
每层BN参数是根据特征图的channel数来确定的。
5.不同模型中 BN 层数量举例
•简单CNN:一个只有几层的卷积神经网络可能只有 2-4 个 BN 层。
•ResNet:更深的网络如 ResNet-50 可能包含 几十个 BN 层(例如,ResNet-50 有 53 个 BN 层)。
•轻量级模型:一些为移动设备设计的模型(如 MobileNet)可能会减少 BN 层的使用以降低计算量,但其数量仍然可观。
•不使用BN的模型:有些模型可能使用其他归一化技术(如 Layer Normalization, Group Normalization)或干脆不使用归一化层
BN 层数量的影响
BN 层能加速模型收敛、提供一定的正则化效果从而可能降低过拟合风险,并允许使用更高的学习率。但其数量也并非越多越好:
•计算开销:BN 层会增加模型的计算量和训练时间。
•小批量大小问题:当训练时的批量大小(Batch Size)过小时,BN 层对均值和方差的估计会不准确,可能影响模型性能
6.BatchNorm推理(Inference)
| 参数类别 | 参数名称 | 是否可学习? | 数量 (基于特征维度 C) | 推理阶段行为 |
|---|---|---|---|---|
| 可学习参数 | 缩放因子 (γ, gamma) | 是 | C | 使用训练最终学到的固定值 |
| 偏移因子 (β, beta) | 是 | C | 使用训练最终学到的固定值 | |
| 非学习统计量 | 全局均值 (running_mean) | 否 | C | 使用训练阶段通过移动平均计算的固定值 |
| 全局方差 (running_var) | 否 | C | 使用训练阶段通过移动平均计算的固定值 | |
| 超参数 | ε (epsilon) | 否 | 1 | 固定的小常数,用于数值稳定 |
| 动量 (momentum) | 否 | 1 | 仅训练时用于更新统计量,推理时不使用 |
因此,对于一个特征维度为 C 的 BN 层,其参数总量为 4 * C + 2(4C个与维度相关的参数,加上2个超参数)。
BN层的参数可以分为可学习参数和非学习的统计量两大类:
-
可学习参数 (Learned Parameters):
- 缩放因子 (γ, gamma):一个维度为
num_features的可学习向量。用于在标准化后恢复数据原本的表达能力,初始值通常为全1。 - 偏移因子 (β, beta):一个维度为
num_features的可学习向量。用于在标准化后恢复数据原本的表达能力,初始值通常为全0。
- 缩放因子 (γ, gamma):一个维度为
-
非学习的统计量 (Non-learned Statistics):
- 全局均值 (running_mean):在训练过程中,通过指数移动平均 (EMA) 累积计算的整个训练数据集的均值估计,维度为
num_features。 - 全局方差 (running_var):在训练过程中,通过指数移动平均 (EMA) 累积计算的整个训练数据集的方差估计,维度为
num_features。
- 全局均值 (running_mean):在训练过程中,通过指数移动平均 (EMA) 累积计算的整个训练数据集的均值估计,维度为
-
超参数 (Hyperparameters):
- ε (epsilon):一个很小的常数(例如
1e-5),添加到方差中以防止除以零,确保数值稳定性。 - 动量 (momentum):用于控制指数移动平均 (EMA) 更新速度的超参数,决定当前批次的统计量对全局统计量的贡献程度,PyTorch 中默认为 0.1。需要注意的是,BN中的momentum与优化器中的momentum是不同的概念。
- ε (epsilon):一个很小的常数(例如
- 推理阶段:
- 不再使用当前批次的统计量,而是使用训练期间通过EMA累积得到的固定的全局均值(running_mean)和全局方差(running_var)。
- 标准化公式变为:
x_hat = (x - running_mean) / sqrt(running_var + ε)。 - 同样使用训练好的、固定的参数 γ 和 β 进行缩放和偏移:
y = γ * x_hat + β。 - 这样做是为了确保推理结果的一致性和稳定性,避免因输入样本数量或内容不同而导致输出波动。
重要提醒
- 参数固定:在推理阶段,BN层的所有参数(γ, β)和统计量(running_mean, running_var)都是固定的,直接使用训练阶段学习或计算好的值,不需要也不应该再更新。
model.eval()的重要性:在PyTorch等框架中,将模型设置为评估模式(model.eval())会自动切换BN层的行为到推理模式,使用 running_mean 和 running_var 并进行计算。- 训练模式的影响:如果模型在推理时意外处于训练模式(
model.train()),BN层会尝试使用当前输入批次的统计量,这可能因为批次特性(如批次大小为1)导致性能下降或产生不一致的结果。
推理时,均值、方差是基于所有批次的期望计算所得,公式如下:
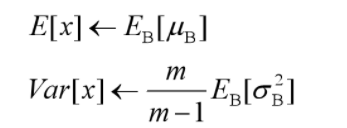
有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算NB进行变换了,在推理过程中进行BN采取如下方式:
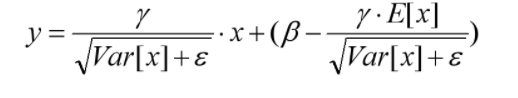
beta、gamma在训练状态下,是可训练参数,在推理状态下,直接加载训练好的数值。moving_mean、moving_var在训练、推理中都是不可训练参数,只根据滑动平均计算公式更新数值,不会随着网络的训练BP而改变数值;在推理时,直接加载储存计算好的滑动平均之后的数值,作为推理时的均值和方差。
滑动平均,储存固定个数Batch的均值和方差,不断迭代更新推理时需要的E(x),Var(x)。
7.BatchNorm的作用
1.加快收敛速度,有效避免梯度消失。
2.提升模型泛化能力,BN的缩放因子可以有效的识别对网络贡献不大的神经元,经过激活函数后可以自动削弱或消除一些神经元。另外,由于归一化,很少发生数据分布不同导致的参数变动过大问题。
最后还想谈一谈Instance normalization
BN适用于判别模型中,比如图片分类模型。因为BN注重对每个batch进行归一化,从而保证数据分布的一致性,而判别模型的结果正是取决于数据整体分布。但是BN对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
IN适用于生成模型中,比如图片风格迁移,GAN等。因为图片生成的结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,在风格迁移中使用Instance Normalization不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立。
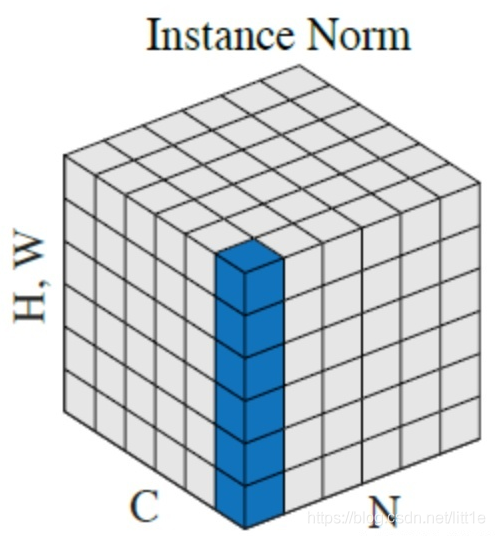
上图中,从C方向看过去是指一个个通道,从N看过去是一张张图片。每6个竖着排列的小正方体组成的长方体代表一张图片的一个feature map。蓝色的方块是一起进行Normalization的部分。由此就可以很清楚的看出,Batch Normalization是指6张图片中的每一张图片的同一个通道一起进行Normalization操作。而Instance Normalization是指单张图片的单个通道单独进行Noramlization操作。
参考
https://blog.csdn.net/litt1e/article/details/105817224