深度解读:PSPNet(Pyramid Scene Parsing Network) — 用金字塔池化把“场景理解”装进分割网络
论文总结
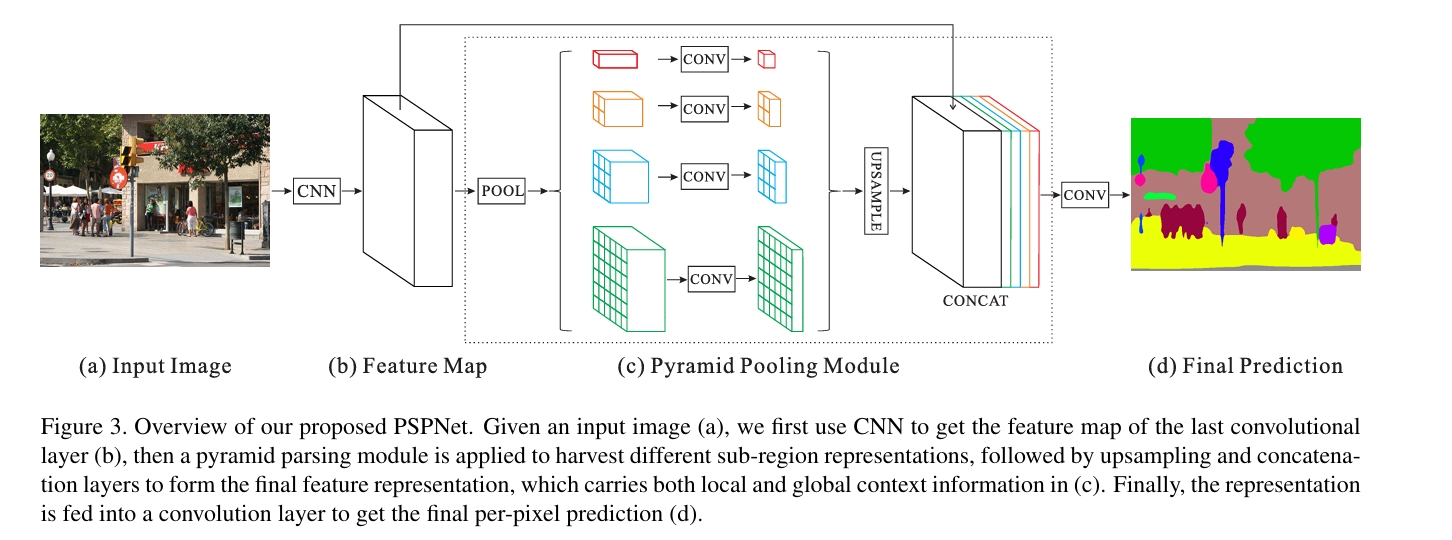
本文(Pyramid Scene Parsing Network, PSPNet)的核心目标是:在语义分割/场景解析任务中,有效引入不同尺度的全局上下文信息,从而弥补常规模型(例如 FCN 或单纯的全局池化)在复杂场景下的不足。作者的主要观察包括:复杂场景中物体类别容易混淆、局部外观相似会导致误判、小/大尺度对象和场景先验的缺失会让模型失误。基于这些直觉,作者提出了一个金字塔池化(pyramid pooling)模块,把最后层的特征用不同大小的区域划分并做池化,得到多尺度的“子区域先验”,再通过 1×1 卷积降维并上采样回原 feature map 大小后拼接,最终混合局部与全局信息做像素预测(PSPNet)。此外,作者在 ResNet+膨胀卷积骨干上使用深度监督(auxiliary loss)、使用多尺度测试与数据增强等训练技巧,使性能进一步提升,并在多个 benchmark(ADE20K、PASCAL VOC、Cityscapes)上取得当时的 SOTA 成绩(论文声明:ImageNet scene parsing challenge 2016 冠军,PASCAL VOC/Cityscapes top)。
亮点(优点):
- 模块设计直观且高效:pyramid pooling 用不同 bin sizes(论文采用 1×1、2×2、3×3、6×6)来捕获从全局到局部的上下文,既保留空间结构又增强全局先验,用简单的 1×1 conv 做降维、双线性上采样与 concat 实现,易于加入任意 FCN/ResNet 型骨干。
- 工程化细节齐备:作者写明了骨干采用 dilated/atrous 策略使输出 stride 为 8,提出深度监督分支以缓解优化难度,并报告了训练/推理要点(多尺度、fine-tuning、初始化策略),便于复现。
- 强实证:在 ADE20K、PASCAL VOC、Cityscapes 等多数据集上显著提升,且论文中给出消融实验(pooling size、pooling type、auxiliary loss 等),论据充分。
可能的不足或局限:
- 对长尾和小目标仍有挑战:虽然多尺度池化提供了更丰富的上下文,但对非常细小、稀疏的目标(例如街灯、标牌)仍需浅层更高分辨率特征或额外检测模块来弥补。论文也提到小/大尺度对象问题。
- 空间精细度 vs 全局先验的权衡:拼接 global/sub-region features 后,如何平衡不同层级信息的权重需要在训练与设计上小心(例如通道数降维比例、1×1 conv 参数及正则化等),不当可能引入噪声或过拟合。
- 计算与内存开销:尽管 PSP 模块本身计算量不大,但在高分辨率输入 + 大骨干(ResNet-101) + 多尺度测试时,整体资源需求依然不低,工程部署要考虑效率折衷。
PSPNet 在“把全局场景先验系统化引入语义分割”上是一项非常务实且影响深远的工作。其设计既有理论直觉(多尺度子区域聚合能提供更有辨别力的全局信息),又有工程可操作性(易于复用到不同骨干并配合深度监督与多尺度测试)。很多后续工作(例如多尺度上下文聚合、金字塔结构、Transformer 中的全局信息建模)都能看到 PSPNet 的影子或直接受其启发。
深度解读:PSPNet(Pyramid Scene Parsing Network) — 用金字塔池化把“场景理解”装进分割网络
原文:Hengshuang Zhao 等人,Pyramid Scene Parsing Network,arXiv:1612.01105。本文基于原文内容,逐段拆解原理、实现与实验,并给出工程化建议与扩展思路。
导读
语义分割(scene parsing)要求对图像中每个像素赋予语义标签。经典 FCN 风格方法善于学习局部语义,但在复杂场景、多类别、外观相似但语义不同的情形下往往出错(例如“船”与“车”的外观可能相似,但基于场景先验事实“车通常不在河上”可以纠正错误)。PSPNet 的贡献就是通过多尺度子区域的全局池化,将不同尺度的上下文信息并入像素预测,从而显著提升复杂场景的解析能力。论文在 ADE20K、PASCAL VOC、Cityscapes 等多个数据集上都取得了优秀成绩,并在 ImageNet Scene Parsing Challenge 2016 中夺冠。
核心思路:金字塔式的全局上下文
PSPNet 的核心模块是 Pyramid Pooling Module(PPM),流程如下:
- 在骨干网络(论文使用 ResNet,采用 dilated convolution 策略使 feature map 的下采样倍率为 8)提取最后一层 feature map(记为 F,尺寸约为 H/8 × W/8 × C)。
- 对 F 做若干尺度的池化(论文使用 4 个尺度:
1×1,2×2,3×3,6×6),每个尺度将 feature map 分割成对应数量的“bin”,对每个子区域做池化得到对应的小 feature。这样既有**全局平均池化(1×1)**的全局先验,又有若干较细分区的局部上下文。 - 每个尺度产物接一个 1×1 convolution 将通道数降到较小值(例如降为原来 1/N),随后对每个尺度的结果做双线性上采样到与 F 相同的空间大小。
- 把原始 F 与所有上采样得到的尺度特征沿通道维拼接(concat),再用若干卷积进一步融合并产生最终的预测特征。这个拼接包含了从“全局到局部”的上下文信息,有助于消除像“外观相似导致的误判”等错误。
直观理解:把整张图“从远看(global)到近看(sub-region)”分层观察,再把这些观察结果带回到像素级的判断中,像是在给每个像素配了一个多视角的上下文记忆。
细节拆解
1) 池化尺度(为什么是 1/2/3/6?)
作者经验性选择了 4 个尺度(1×1、2×2、3×3、6×6)。思路是覆盖“整图、粗分区、中等、较细分区”这样宽泛的上下文粒度:1×1 给全局场景类别先验(例如室内/街道/海边等),2×2 与 3×3 提供中等上下文(局部区域布局),6×6 可以照顾较细的空间结构。论文有消融实验比较不同设置,显示 4-level 配置效果好且计算量可控。
2) 降维与上采样
每个池化分支后接 1×1 conv 降通道(降低参数与避免拼接后通道爆炸),再用双线性插值上采样到原 feature map 大小。双线性上采样是计算友好且能保持空间平滑性的选择,随后拼接的特征由小卷积来融合。整个过程可端到端训练。
3) 骨干与输出 stride
论文采用 ResNet-101/50 作为主干,并结合 dilated(atrous)卷积策略将最终特征 map 的下采样率设置为 8(相对输入),以便在不牺牲感受野的前提下保留更高空间分辨率,这对于准确的像素级预测尤为重要。
4) 深度监督(auxiliary loss)
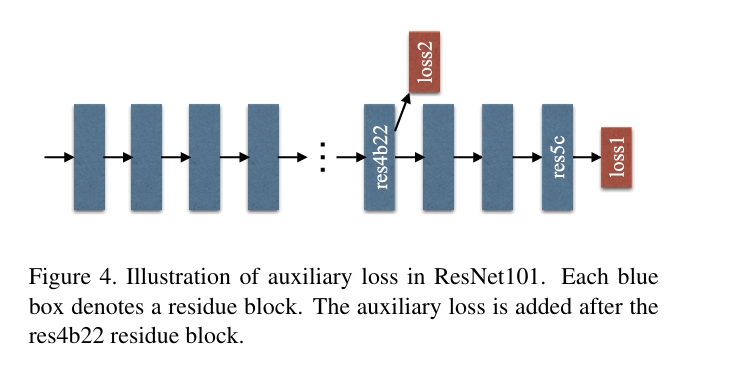
为了提升训练稳定性与优化深层网络的收敛,作者在中间层(res4b22)加了一个辅助分支并施加额外 softmax 损失(深度监督),这个 trick 降低了训练难度并提升最终结果。论文给出具体做法与优势讨论。
实验与效果
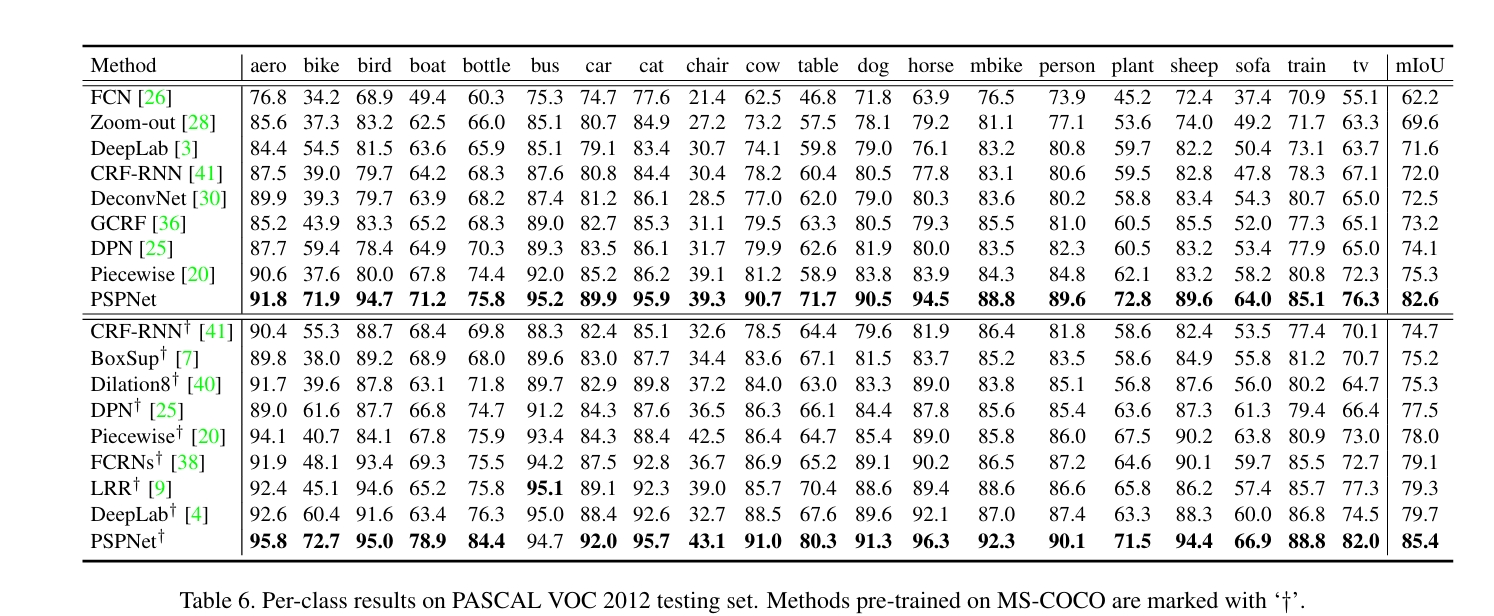
- ImageNet Scene Parsing Challenge 2016 冠军。
- PASCAL VOC 2012:论文给出的单模型 mIoU 达到论文中报告的高分。
- Cityscapes:论文报告了城市道路场景的高精度。

消融与工程技巧
论文不仅提出模块,还给出许多可复用的工程建议,例如:
- 选择合适的 池化类型(avg vs max) 的实验对比;
- 在 ResNet 上使用 dilated convolution 而非简单下采样以保持分辨率;
- 使用 深度监督 来缓解深层网络训练问题;
- 采用 多尺度测试(multi-scale testing) 与 sliding-window 在高分图像上的拼接策略以提升推理准确率;
- 提供了代码仓库(作者公开实现)作为复现起点。
优化与部署建议
- 资源-精度权衡:若需在实时或受限设备上部署,可采用更轻的骨干(ResNet-18 / MobileNet)并减少多尺度测试,或把 PPM 的通道降维比调小。
- 小目标补强:对小目标可在浅层增加 skip-connection 融合(借鉴 FCN/U-Net 式结构),或在训练时使用更细的 crop/augment 策略。
- 推理优化:用半精度(fp16)与 batch inference,缓存骨干提取特征,避免多次重复计算;同时考虑把 PPM 改写为更高效的全局-局部注意力机制在 Transformer/轻量化模型上实现类似功能。
- 超参注意:pooling bin 数、1×1 conv 降维比、auxiliary loss 权重与学习率策略对最终结果影响大,建议逐一做小规模网格搜索。
优缺点速览(工程师视角)
优点:
- 结构简单、易于复用;
- 能显著改善复杂场景下的语义一致性错误(混淆类/关系不匹配);
- 实证充分,在多个 benchmark 取得好成绩。
缺点 / 限制:
- 对超高分辨率或超小目标仍需额外设计;
- 在低资源平台上直接跑 ResNet101+PPM+多尺度测试会比较重;
- PPM 的拼接方式虽然有效,但在某些场景需要更细腻的特征权重自适应机制(例如 attention)来替代简单 concat。
进一步研究与扩展方向(面向论文后的 发展)
- 用自注意力(Transformer)或非局部块替代或补充 PPM 以更灵活建模全局-局部关系;
- 在轻量化网络上设计类似 PPM 的上下文汇聚模块以适配移动/嵌入式场景;
- 结合实例分割/检测信息(多任务学习)进一步提升类别一致性与边界质量;
- 将 PPM 思想移植到视频分割/3D 点云语义分割场景,探索时空或几何上下文聚合。
总结
PSPNet 用金字塔池化把“场景级”信息系统化地带入像素级预测,是一篇兼顾直觉、工程与实证的经典论文。它的模块化设计和大量工程实现细节使其成为语义分割领域的“实用主义”范例,也为后续很多方法(包括 attention、金字塔池化变体和多尺度上下文聚合)提供了重要启发。若你正在做语义分割工程或研究,把 PSPNet 作为 baseline 或模块化组件进行试验,通常会带来稳健的性能提升。文中所有关键描述均基于原论文内容。
附:便捷资源
- 原文(arXiv PDF):arXiv:1612.01105(本文所有引用基于该文)。
- 作者实现/复现仓库(论文内提供)可作为实践起点(论文末有链接)。