【大模型面试宝典之微调篇】(一)
【注】本篇内容均来自于:【九天Hector的个人空间-哔哩哔哩】 https://b23.tv/md9rjFS,如侵删。
1. 如何评估大模型微调效果?
评估大模型的微调效果,通常需要结合人工评估与自动化评估两条路径。
人工评估的核心,是让专业人员或目标用户直接去体检模型的输出效果,通过打分、对比和主观判断来衡量模型是否更贴近人类偏好。比如在法律场景中,可以邀请律师对模型的答复进行专业性和准确性评分;在金融场景中,则由分析师判断回答是否具备使用价值。
人工评估的优势在于它能真实反映“模型回答是否符合与其场景”,而不是单纯依赖指标。
除了人工评估外,我们往往还需要依靠数据集驱动的系统化评估,来评估模型的数学、推理、代码、Agent性能。常见做法是构建一套独立的验证数据集,在微调前后对比模型的各项指标是否发生变化。
例如想要验证模型的数学和推理方面的性能,可以使用AIME、GPQA等数据集进行评估;如果想要验证模型的代码能力,可以使用SWE-Bench数据集进行评估;而如果希望验证模型指令跟随或者Function calling能力,则可以用IFEval数据集。
总的来说,只有把人工评估的主观体验与这些客观数据指标结合起来,才能真正全面、可靠地判断微调是否达到效果。
2. 在人工评估微调结果的过程中,如何尽量避免偏差?
人工评估不可避免会受到主观因素的影响,因此要尽量通过多评审员+盲测来降低偏差。
多评审员能平衡个体差异,取平均或投票结果更可靠;盲测可以避免因对模型身份的预期而影响判断。
此外,还可以制定统一的评分标准和示例,保证不同评审员之间的尺度一致。
3. 如何构建用于评估微调效果的验证集或测试集?
首先,验证集或测试集数据需要覆盖模型未来可能面对的各类典型任务场景,例如金融模型就要包含行情解读、风险分析、投资建议等多种类型的问题。
其次,要保证样本的多样性,避免模型只在某一种体型上表现良好而在真实应用中失效。
4. 通常有哪些工具可以用于快速构建模型评估数据集?
工程化场景下,往往会考虑使用魔塔社区EvalScope项目,来自动构建测试数据集、自动评估模型性能并产出分析报告。
5. 模型微调和RAG的区别?
大模型微调(Fine-tuning)与检索增强生成(RAG)是优化大模型性能的两种核心技术,其核心差异体现在知识存储方式、更新机制与适用场景上。
微调通过调整模型参数将领域知识内化到权重中,适合知识相对静态且专业性强的任务,例如法律文书生成或医疗诊断报告,它能深度掌握领域术语和逻辑,但需大量标注数据和算力支持,且更新成本高,每次知识变动都需重新训练模型。而RAG不修改模型参数,通过实时检索外部知识库(如数据库、文档或实时API)动态补充信息,适合需要时效性或长尾知识覆盖的场景,例如股票行情查询或政策解读,其优势在于知识更新灵活、答案可溯源,但依赖检索系统的质量与效率,且对复杂推理任务的支持较弱。
从技术实现来看,微调是“让模型成为专家”,通过训练数据将知识固化于参数中,生成结果更稳定但可能因数据不足产生幻觉;RAG则是“为模型配备智库”,通过检索约束生成内容,显著降低幻觉风险,但需额外维护检索系统并可能增加推理延迟。
实际应用中,二者常协同使用:例如医疗问答系统可先微调模型掌握基础诊疗逻辑,再通过RAG接入最新医学论文,兼顾专业性与时效性;或金融分析工具用微调学习财报术语,结合RAG实时检索市场数据生成动态报告。这种混合策略既能发挥微调对领域逻辑的深度理解,又能利用RAG的动态知识扩展能力,成为当前大模型落地的优选方案。
6. 模型微调和模型蒸馏的区别?
模型蒸馏是指借助更强大的教师模型产生的数据,来训练小尺寸的学生模型。
目前模型蒸馏分为黑箱蒸馏和白箱蒸馏。黑箱蒸馏过程中教师模型不会公开中间输出,学生模型只能学习教师模型的输入和输出,此时学生模型的训练过程本质上就是有监督微调,二者没有区别。典型例子就是DeepSeek R1模型蒸馏Llama3系列小模型和Qwen3系列小模型的过程,其实就是有监督微调。
而白箱蒸馏则要求教师模型输出中间预测结果,在透明的情况下,学生模型不仅能模仿最终答案,还能学习教师模型的推理链路、注意力分布、隐藏层表示等更丰富的信息。这种方式能更好地提升学生模型的推理能力和对齐效果,但同时也依赖于教师模型内部结构的开放程度。
7. 什么时候用微调技术,什么时候用RAG技术?
对于精细化、非常细节的问题检索,如查看某天发生的事件、某天的天气,推荐采用RAG技术对文档进行检索。
对于一些相对固定的领域知识,比如一些法律知识、医学知识、行业规范等,则可以采用较多主题一致、但内容多样的文档进行微调,从而实现知识灌注。
在实际应用中,微调与RAG技术往往是需要结合使用,我们可以先通过微调让模型掌握稳定的核心知识与专业表达风格,然后在必要的场景中,通过RAG技术让模型能够动态地获取最新信息。二者结合可以在保证回答的专业性与一致性的同时,避免知识过时,兼顾长期记忆与实时更新,从而显著提升系统的可靠性与实时性。
8. 大模型微调能提升模型的哪些能力?
根据目前业内的实践经验,大模型微调可以用于优化模型问答的语气风格,可以进行知识灌注,可以用于修改模型的自我认知,也可以提升模型指令跟随能力、提升模型工具调用与Agent能力。
9. 模型微调可能存在哪些风险?
微调最大的风险是可能使得模型丧失原有能力,也就是所谓的灾难性以往。
此外,还有可能造成训练数据过拟合,或者在训练数据中带入隐私数据,后期使用不当可能间接导致模型在回答问题时造成隐私数据泄露等等。
10. 如何评估大模型微调和训练所需的硬件成本?
在 Dense 模型架构下,如果是做全量微调,每一步计算都会激活所有参数,此时硬件成本的评估逻辑相对直接。常见做法是根据 【模型参数规模 x 精度位宽】 来粗略估算显存需求,例如一个 70B 参数的 Dense 模型,若来用 FP16 进行存储,需要大约140GB显存才能完整容纳。此外梯度存储还要占用140G,而优化器则需要占用4倍的显存,也就是约560G,这里总共约840G,再考虑激活值存储、显存碎片化以及分布式训练的几余开销,实际需求往往在 1TB 显存左右。
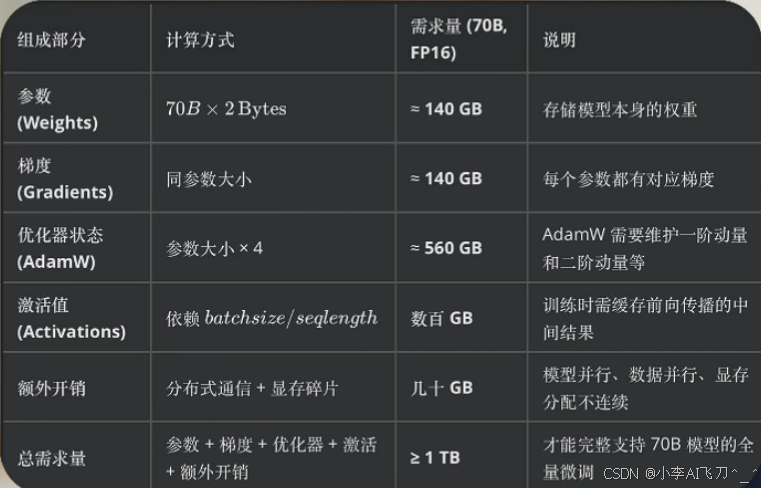

如果换成参数更小的 Dense 模型,一般可以按照近似线性比例来估算显存需求。例如,一个13B参数的模型,参数是70B模型的1/5左右,整体可能200GB显存以内就能完成全量微调。如果精度降低,比如采用8bit或4bit 量化存储,显存占用会近似按照位宽缩减。以70B模型为例,FP16下参数是140GB,如果用8bit存储则需要约 70GB,用 4bit 存储则只有约35GB。
不过,梯度和优化器通常还是以 FP16 形式保存,因此总体显存缩减幅度有限。最后,如果不是做全量微调,而是采用LORA等高效微调方法,显存占用会显著降低,因为 LORA只需要在部分矩阵中引入低秩适配器,训练时只更新新增的参数,原始大模型参数保持冻结。例如对 70B 模型应用LORA,实际需要更新的参数量可能只有 1%~2%,因此显存需求往往控制在160G左右。
如果是MOE架构的模型,则可以简单粗暴的将其等价为共享参数+激活参数等量的Dense模型,例如Qwen3235B-A22B模型,激活参数为22B,共享参数约7.8B,因此模型微调显存占用等价于一个30B的dense模型,也就是全量微调约需要500G,而高效微调则仅需110G品存即可。每个MOE模型的激活参数和共享参数量雪要查阅官方说明文档来确定。