「日拱一码」068 机器学习——迁移学习TL
目录
核心思想
为什么要使用迁移学习?
常见方法
代码示例
核心思想
迁移学习(Transfer Learning)是一种机器学习方法,其核心思想是:将一个领域(源领域)中学习到的知识和模型,应用到另一个不同但相关的领域(目标领域)中。
通俗来讲,就是“举一反三”。我们不再要求模型每次都从零开始学习,而是像人类一样,利用之前解决其他问题时获得的经验(预训练模型),来更快、更好地解决新的、数据可能较少的问题。
为什么要使用迁移学习?
- 数据稀缺(最主要的原因):在许多实际应用场景中,为目标任务收集大量高质量的标注数据非常困难、昂贵或耗时(例如,医疗图像分析、特定领域的文本分类)。迁移学习允许我们使用在大规模通用数据集(如 ImageNet、Wikipedia)上预训练的模型,只需少量目标数据即可获得优异性能。
- 节省计算资源和时间:从头训练一个复杂的深度学习模型(如大型CNN或Transformer)需要巨大的计算力和时间。使用预训练模型作为起点进行微调(Fine-tuning),可以大幅减少训练时间和计算成本。
- 提升模型性能:预训练模型已经学习到了非常通用且有效的特征表示(如图像的边缘、纹理、物体的部分;文本的语法、语义关系)。这些特征对于许多任务都是有益的,可以作为很好的初始化,往往能比随机初始化的模型取得更好的最终性能,特别是当目标数据集较小时。
常见方法
迁移学习主要有以下几种策略:
1. 特征提取(Feature Extraction):
- 将预训练模型(去掉最后的分类层)作为一个固定的特征提取器。
- 将目标数据集输入该模型,得到输出的特征向量(也称为“瓶颈特征”)。
- 在这些提取的特征之上,训练一个新的、简单的分类器(如全连接层+Sigmoid/Softmax)。
- 优点:训练速度快,计算成本低,不易过拟合。
- 适用场景:目标数据集很小,与源数据集差异较大。
2. 微调(Fine-Tuning):
- 不仅训练新添加的分类层,还解冻预训练模型的一部分或全部层,并用较小的学习率对它们的权重进行更新。
- 通常策略:微调靠近输出的高层(学习特定特征),冻结靠近输入的底层(保留通用特征)。
- 优点:潜力更大,模型能更好地适应目标任务。
- 适用场景:目标数据集较大,与源数据集相似。
3. 预训练模型作为组件:
- 将预训练模型(如BERT、GPT)作为更复杂模型架构的一个组件嵌入其中,其权重可以固定也可以参与训练。
代码示例
任务: 使用在MNIST上预训练的模型,来对圆形vs方形进行分类
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as pltprint("TensorFlow版本:", tf.__version__)# 设置随机种子以确保可重复性
tf.random.set_seed(42)
np.random.seed(42)# 1. 准备源任务数据集(MNIST数字识别)
print("加载MNIST数据集作为源任务...")
(x_train_src, y_train_src), (x_test_src, y_test_src) = keras.datasets.mnist.load_data()# 预处理源数据
x_train_src = x_train_src.astype('float32') / 255.0
x_test_src = x_test_src.astype('float32') / 255.0
x_train_src = np.expand_dims(x_train_src, -1) # 添加通道维度
x_test_src = np.expand_dims(x_test_src, -1)print(f"源任务数据集形状: {x_train_src.shape}") # (60000, 28, 28, 1)# 2. 准备目标任务数据集
# 创建一个小型的目标分类任务:区分圆形和方形
def create_target_dataset(num_samples=1000):"""创建模拟的目标数据集(圆形 vs 方形)"""images = []labels = []for i in range(num_samples):# 随机决定生成圆形还是方形is_circle = np.random.choice([0, 1])# 创建空白图像img = np.zeros((28, 28, 1), dtype=np.float32)if is_circle:# 生成圆形center_x, center_y = np.random.randint(5, 23, 2)radius = np.random.randint(3, 8)for x in range(28):for y in range(28):if (x - center_x) ** 2 + (y - center_y) ** 2 <= radius ** 2:img[x, y, 0] = 1.0labels.append(1) # 圆形标签为1else:# 生成方形size = np.random.randint(5, 12)start_x = np.random.randint(0, 28 - size)start_y = np.random.randint(0, 28 - size)img[start_x:start_x + size, start_y:start_y + size, 0] = 1.0labels.append(0) # 方形标签为0images.append(img)return np.array(images), np.array(labels)print("创建目标任务数据集...")
x_train_target, y_train_target = create_target_dataset(500) # 仅500个训练样本
x_test_target, y_test_target = create_target_dataset(200) # 200个测试样本print(f"目标任务数据集形状: {x_train_target.shape}") # (500, 28, 28, 1)
print(f"类别分布: {np.bincount(y_train_target)}") # [265 235]# 3. 可视化数据集
plt.figure(figsize=(12, 5))# 显示源任务样本(MNIST数字)
plt.subplot(2, 5, 1)
plt.imshow(x_train_src[0].squeeze(), cmap='gray')
plt.title('Source: Digit 5')
plt.axis('off')for i in range(1, 5):plt.subplot(2, 5, i + 1)plt.imshow(x_train_src[i].squeeze(), cmap='gray')plt.title(f'Source: Digit {y_train_src[i]}')plt.axis('off')# 显示目标任务样本(圆形vs方形)
plt.subplot(2, 5, 6)
plt.imshow(x_train_target[0].squeeze(), cmap='gray')
plt.title('Target: Circle' if y_train_target[0] == 1 else 'Target: Square')
plt.axis('off')for i in range(1, 5):plt.subplot(2, 5, i + 6)plt.imshow(x_train_target[i].squeeze(), cmap='gray')plt.title('Circle' if y_train_target[i] == 1 else 'Square')plt.axis('off')plt.tight_layout()
plt.show()# 4. 在源任务上预训练基础模型
print("\n在源任务(MNIST)上预训练模型...")def create_base_model():"""创建基础CNN模型"""model = keras.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dropout(0.5),layers.Dense(10, activation='softmax') # 10个数字类别])return model# 创建并训练源任务模型
base_model = create_base_model()
base_model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']
)# 快速训练
base_model.fit(x_train_src, y_train_src,epochs=3,batch_size=32,validation_split=0.2,verbose=1
)# 评估源任务性能
src_test_loss, src_test_acc = base_model.evaluate(x_test_src, y_test_src, verbose=0)
print(f"源任务测试准确率: {src_test_acc:.4f}") # 0.9890# 5. 迁移学习:重用预训练的特征提取器
print("\n进行迁移学习...")# 移除源任务的分类头
feature_extractor = keras.Model(inputs=base_model.inputs,outputs=base_model.layers[-3].output # 获取特征提取部分
)# 冻结特征提取器的权重
feature_extractor.trainable = False# 为目标任务构建新模型
inputs = keras.Input(shape=(28, 28, 1))
x = feature_extractor(inputs)
x = layers.Dense(32, activation='relu')(x)
x = layers.Dropout(0.3)(x)
outputs = layers.Dense(1, activation='sigmoid')(x) # 二分类transfer_model = keras.Model(inputs, outputs)transfer_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']
)transfer_model.summary()# 6. 训练迁移学习模型(使用小数据集)
print("训练迁移学习模型...")
history_transfer = transfer_model.fit(x_train_target, y_train_target,epochs=10,batch_size=16,validation_data=(x_test_target, y_test_target),verbose=1
)# 7. 对比:从头开始训练的目标任务模型
print("从头开始训练目标任务模型(对比)...")
from_scratch_model = keras.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dropout(0.5),layers.Dense(1, activation='sigmoid')
])from_scratch_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']
)history_scratch = from_scratch_model.fit(x_train_target, y_train_target,epochs=10,batch_size=16,validation_data=(x_test_target, y_test_target),verbose=1
)# 8. 性能对比
transfer_test_loss, transfer_test_acc = transfer_model.evaluate(x_test_target, y_test_target, verbose=0)
scratch_test_loss, scratch_test_acc = from_scratch_model.evaluate(x_test_target, y_test_target, verbose=0)print("\n" + "=" * 60)
print("迁移学习性能对比")
print("=" * 60)
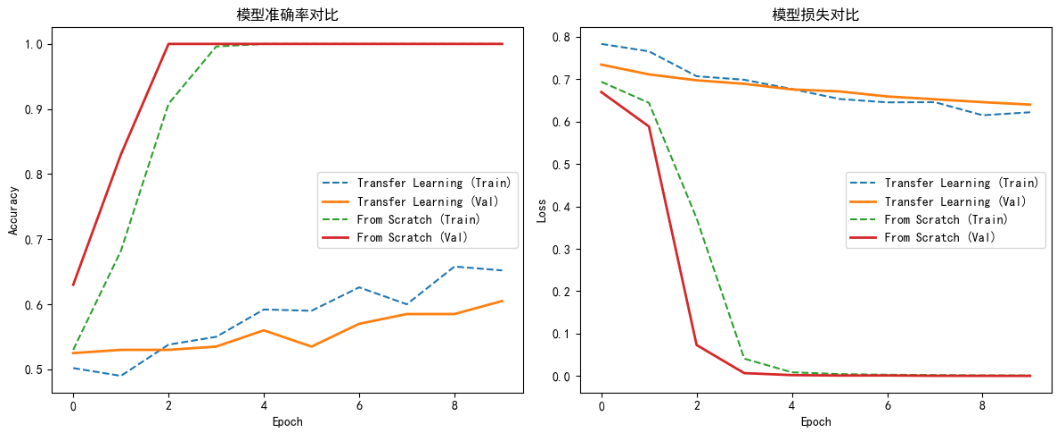
print(f"迁移学习模型 - 测试准确率: {transfer_test_acc:.4f}") # 0.6050
print(f"从头训练模型 - 测试准确率: {scratch_test_acc:.4f}") # 1.0000
print(f"性能提升: {transfer_test_acc - scratch_test_acc:.4f}") # -0.3950# 9. 可视化训练过程
plt.figure(figsize=(12, 5))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 准确率对比
plt.subplot(1, 2, 1)
plt.plot(history_transfer.history['accuracy'], label='Transfer Learning (Train)', linestyle='--')
plt.plot(history_transfer.history['val_accuracy'], label='Transfer Learning (Val)', linewidth=2)
plt.plot(history_scratch.history['accuracy'], label='From Scratch (Train)', linestyle='--')
plt.plot(history_scratch.history['val_accuracy'], label='From Scratch (Val)', linewidth=2)
plt.title('模型准确率对比')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()# 损失对比
plt.subplot(1, 2, 2)
plt.plot(history_transfer.history['loss'], label='Transfer Learning (Train)', linestyle='--')
plt.plot(history_transfer.history['val_loss'], label='Transfer Learning (Val)', linewidth=2)
plt.plot(history_scratch.history['loss'], label='From Scratch (Train)', linestyle='--')
plt.plot(history_scratch.history['val_loss'], label='From Scratch (Val)', linewidth=2)
plt.title('模型损失对比')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()plt.tight_layout()
plt.show()# 10. 预测示例
print("\n预测示例:")
sample_indices = np.random.choice(len(x_test_target), 6, replace=False)
sample_images = x_test_target[sample_indices]
sample_labels = y_test_target[sample_indices]predictions = transfer_model.predict(sample_images)
predicted_probs = predictions.flatten()
predicted_labels = (predicted_probs > 0.5).astype(int)plt.figure(figsize=(12, 4))
for i in range(6):plt.subplot(2, 3, i + 1)plt.imshow(sample_images[i].squeeze(), cmap='gray')actual = "Circle" if sample_labels[i] == 1 else "Square"predicted = "Circle" if predicted_labels[i] == 1 else "Square"confidence = predicted_probs[i] if predicted_labels[i] == 1 else 1 - predicted_probs[i]color = 'green' if actual == predicted else 'red'plt.title(f'True: {actual}\nPred: {predicted}\nConf: {confidence:.2f}', color=color)plt.axis('off')plt.tight_layout()
plt.show()