【行业洞察】多智能体的风口浪尖--微软MagenticOne/UI
最近一段时间在持续调研和跟进工业界、学术界多智能体编排的发展和趋势,文本整理微软开源的Magentic One(多智能体协同自主解决复杂多步任务,偏向网络和文件操作)和Magentci UI(核心模块基于Magentic One,增加人机交互设计)工作。由于Magentcic One论文中实验基于GAIA,因此也简单介绍笔者对GAIA的理解。
简单总结:
- 中心化的多智能体协同模式:“orchestrator”智能体负责协调调度四个专家智能体执行复杂的多步骤任务
- 多步骤地自动化分析多智能体执行日志,来进行失败归因(做了笔者一直想尝试的事情)
- 人-智能体智能体共同参与任务编排和任务执行,不过存在的问题是目前过于依赖人的决策,需要用户参与的步骤过多
Magentic One论文
1. 目标
这篇工作的终极目标是构建一个通用的、能够解决跨领域复杂任务的多智能体系统。一个任务怎样才算复杂?作者将需要经过一轮或者多轮的规划、执行、观察和反思的任务定义为复杂任务,任务包含输入和期待输出,并能够使用评估方法对比实际输出和期待的输出。
2. 核心观点
- 构建协作共同完成复杂任务的多智能体系统
- 包含担任leader角色的**"Orchestrator"智能体和具备不同能力、擅长不同任务的四个智能体(操作浏览器、处理文件、生成并执行代码)。 其中"Orchestrator"负责 1>生成执行计划 2>将计划中的子任务分发给智能体 3>跟踪任务执行进展 4>必要时调整计划。**其余四个智能体(Coder/Computer Terminal/File Surfer)调用不同的工具执行orchestrator下发的指令。
- 针对用户请求:Orchestrator 首先将用户请求拆解成子任务、生成初始的计划;然后针对每个子任务选择合适的智能体并交给它执行;同时监管任务的执行进度和完成情况。
- 构建评测体系和方法
3. 详细设计
3.1 架构
Magentci-One定位是一个通用的多智能体系统,能自主处理解决复杂的任务。整个系统由"Orchestator"智能体协调调度:负责任务拆解和规划、指导系统内其他智能体执行子任务、跟踪进展、并在必要时采取正确的行动。系统内其他智能体在"Orchestator"的协调调度下执行具体任务,它们能调用不同的工具,具备解决开放和特定任务的不同能力。
设计理念:分层,把“高层能力”分散在不同智能体之间,再把“低层动作”放在各个智能体内部,这种分解方式就形成了一个分层结构(hierarchy)。层级的工具使用更易于llm做推理。
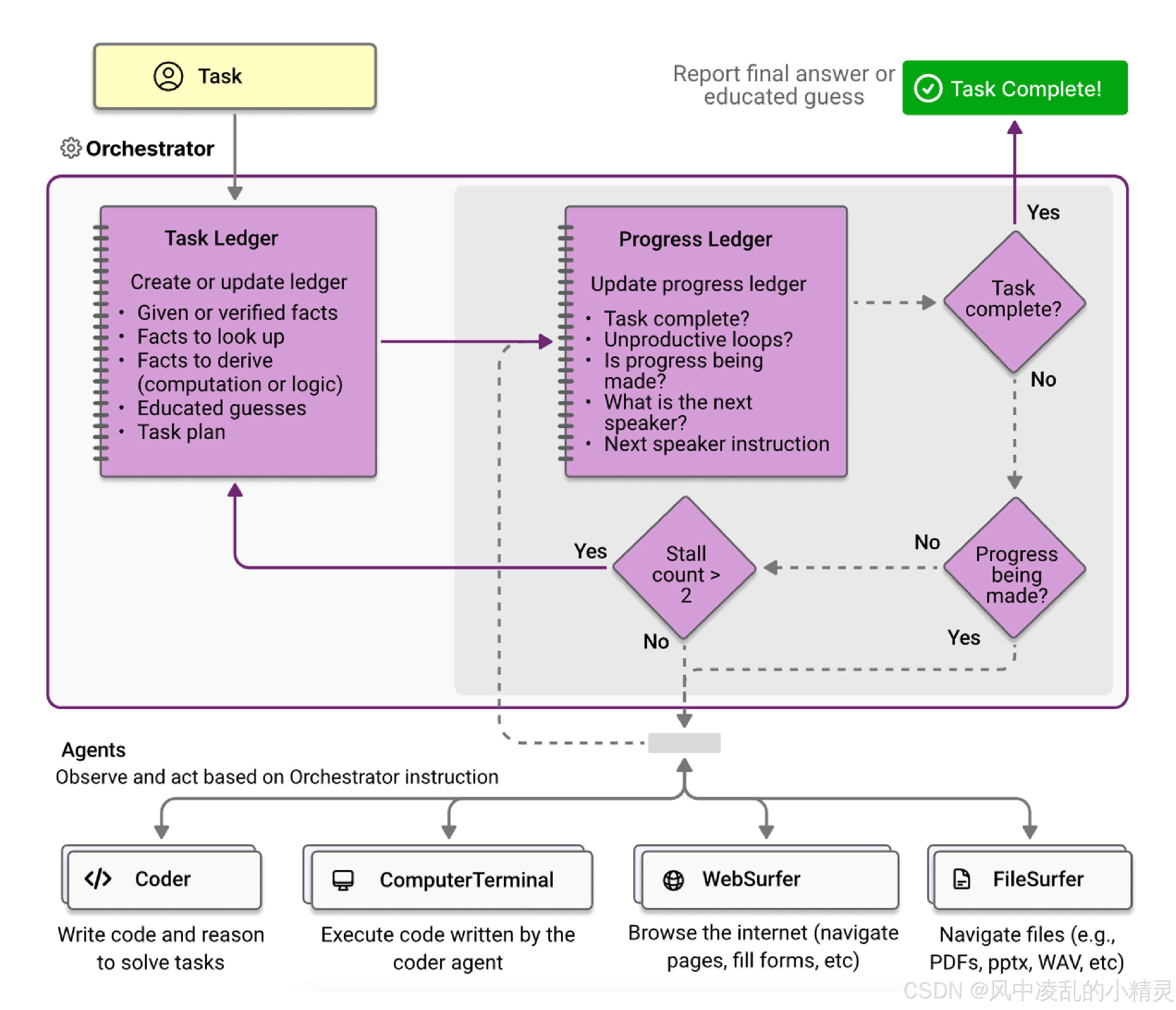
3.2 工作流程
包含两层循环: 外层循环掌管"全局计划",内层循环掌管评估"执行进度"(每个步骤包含指令和路由的专家智能体)
- 外层循环
- 接收任务,"Orchestractor"创建任务执行期间的短期记忆–“task ledger”
- 思考完成这些任务需要哪些信息?将这些信息预先填写到task ledger中,包含(1)已知/验证的事实 (2)需要查询的事实 (3)需要推导/计算的事实 (4)合理的推测
- 制定计划:根据团队智能体的能力描述和当前task ledger的内容,制定执行计划plan。计划包含一系列的执行步骤steps和每步分配的智能体。
- 修正计划: 计划plan只是作为逐步执行的提示,类似COT,并不会要求严格按照计划执行。外部循环迭代过程中,计划可能会被修正。
- 内层循环–计划plan制定形成之后,内层循环初始化
- 每次迭代,Orthestrator会创建"progress ledger",分析并向其中填写:(1)整体任务是否完成(2)智能体是否存在无效循环和重复 (3)当前步骤是否取得了进展 (4)下一步选择哪个智能体 (5)给智能体提供什么样的任务指令。
- 同时,为了避免整个系统陷入死循环,Orthestractor维护计数器counter,计数器一旦大于阈值就会中止内层循环,开启新一轮外部迭代(修改原有计划)。这其中会启动反思步骤:识别可能出现了什么问题?在此过程中获得了什么新的信息?下次外部迭代可能采取哪些不同的做法。
3.3 执行具体任务的四个智能体
设置四个专家智能体,分别对特定场景进行了优化
- WebSurfer:
- 基于LLM的智能体,擅长控制和管理浏览器,负责将用户的请求映射为动作并报告页面状态(截屏和文本描述)
- 支持的动作包括:导航(访问URL、执行网页搜索、滚动页面)、网页操作(点击、输入)、阅读动作(总结、回答问题)
- 使用到的技术包括:(1)文档问答document Q&A和(2)采用视觉标记引导模型推理set-of-marks prompting
- FileSurfer:操作基于Markdown 文件的预览应用
- Coder:基于LLM的智能体,擅长编写调试代码程序、分析从其他智能体收集的信息
- ComputerTerminal:访问控制台,使得coder的程序可运行,同时可以运行shell命令,如下载安装新的编程库
4. 实验分析
4.1 评测存在的挑战–前后执行改变状态导致评测的不公平
多智能体共同运行在有状态(环境会被改变)的环境的中,彼此的运行会互相影响,评估结果可能会不公平;比如第一个智能体执行动作时发现缺少必要的库,经过搜索下载安装后使得该库可用;第二个智能体会直接受益于“库已经被安装过;反过来,前面智能体的错误操作也会影响后续的任务
4.2 探索的解决方法
保持任务之间的评估独立–AutoGenderBench会严格控制任务的初始条件,每个任务使用新的docker避免环境干扰,评估结果写入日志以支持后续分析
4.3 选择的评测数据集:GAIA, AssistantBench, and WebArena
选择benchmark的标准:必须包含复杂多步任务,一些任务或者步骤必须需要规划或者调用工具。
4.4 选择的模型:论文中默认使用 gpt-4o-2024-05-13
4.5 实验结论
-
1.相比简单的任务,Magentic One更擅长解决复杂任务。引入的开销和复杂度有助于长流程的多步骤任务,同时也给短流程少步骤任务引入了错误。
- 虽然论文给出了这样的结论,但是在GAIA数据集上该结论并不成立。
- Level 1:最佳基线得分为 53.76,Magentic-One (GPT-4o) 得分为 46.24。 差距为 53.76 - 46.24 = 7.52。
- Level 3:最佳基线得分为 26.53,Magentic-One (GPT-4o)得分为 18.75。 差距为 26.53 - 18.75 = 7.78
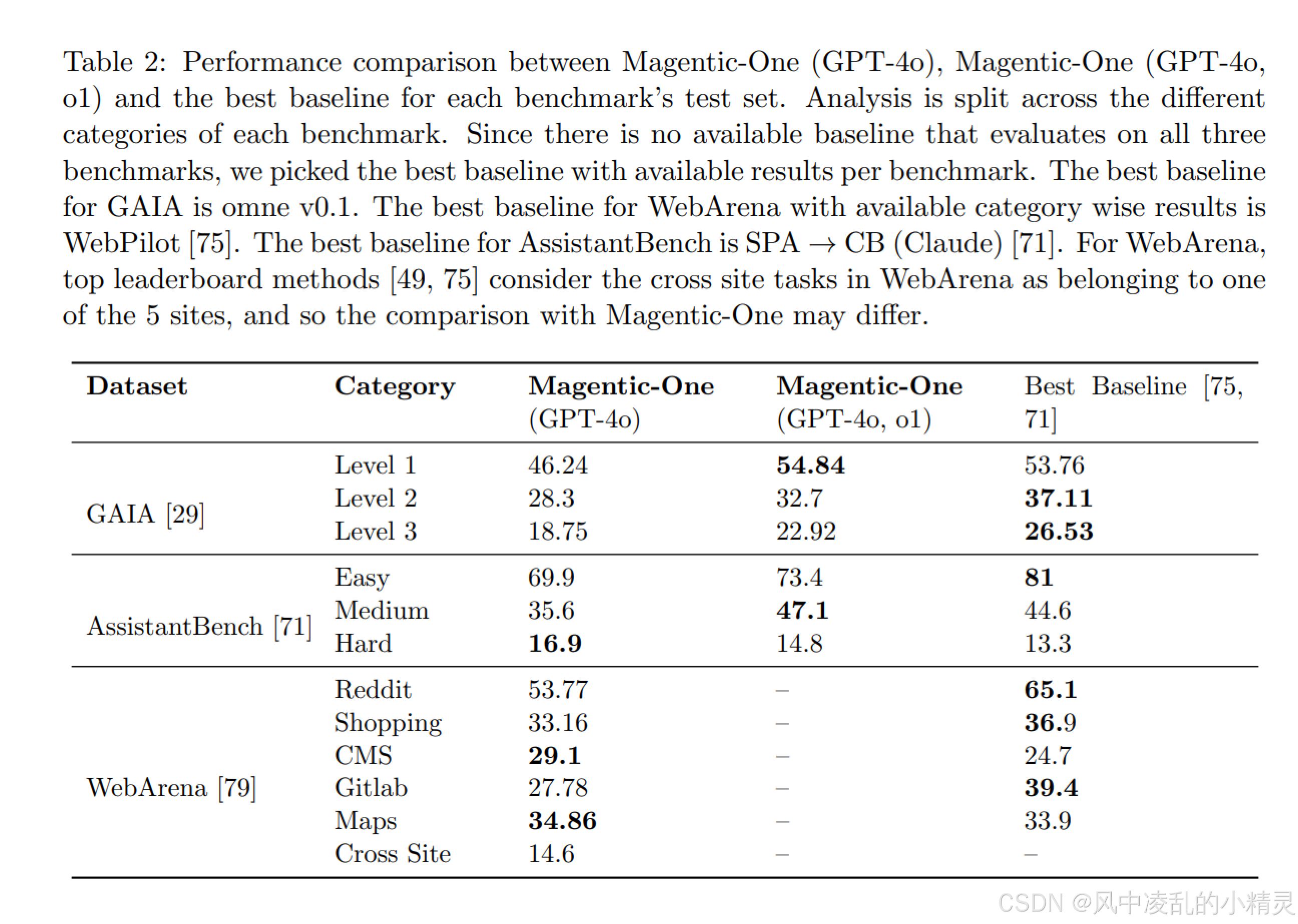
- 虽然论文给出了这样的结论,但是在GAIA数据集上该结论并不成立。
-
2.消融证明每个智能体对整体系统的响应:没有Orchestractor的ledgers,GAIA验证集上效果会下降31%
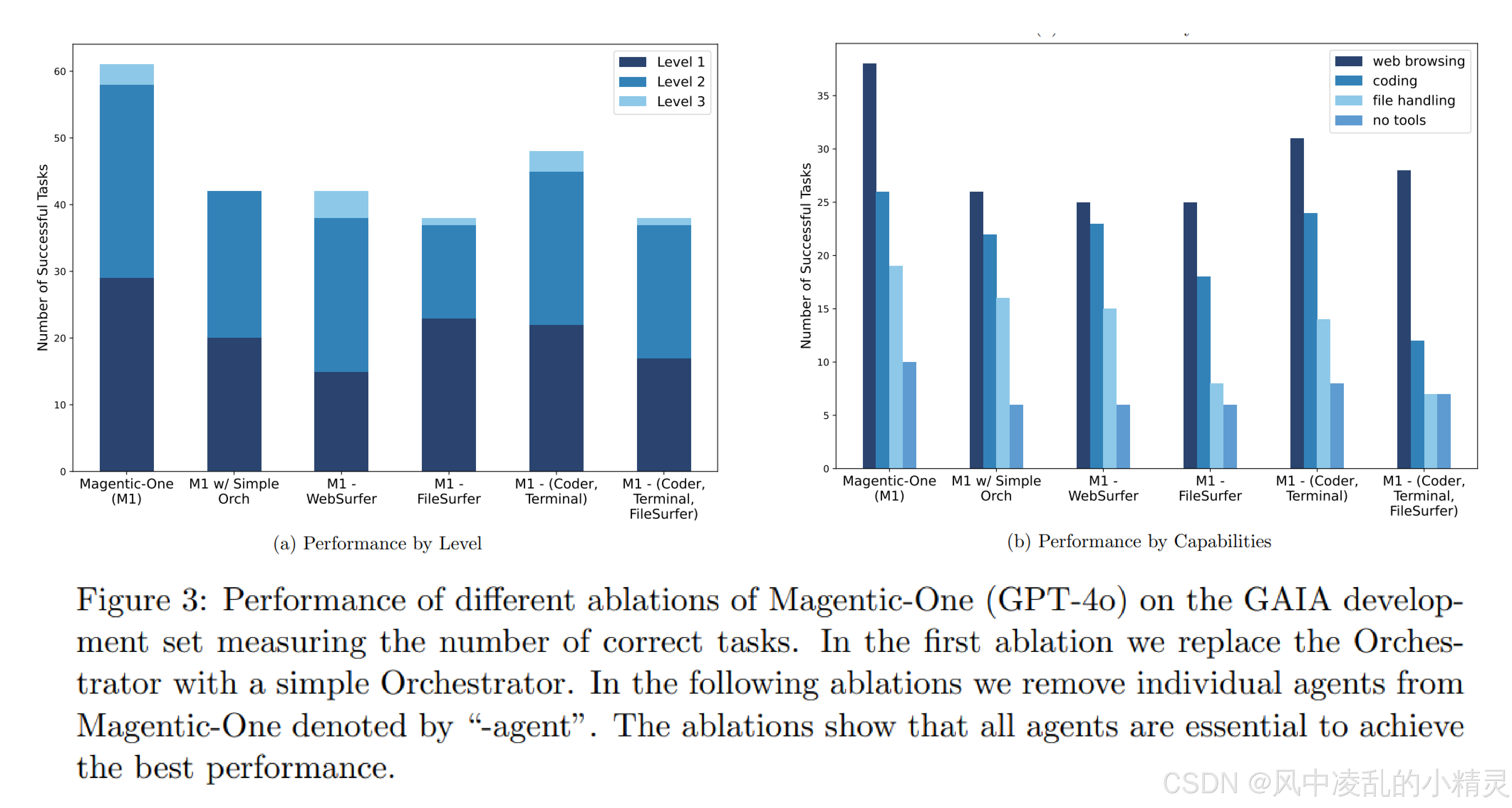
-
3.自动化日志分析来评估系统存在的问题
- 采用多阶段的方法(每个阶段都基于GPT-4o):
- 第一步:提炼日志–使用GPT -4o分析详细执行日志,提炼浓缩成分析文档,目的是识别导致失败的根源以及影响因素→root-cause文档
- 第二步:给每个root cause 文档生成描述性标签,如"遗漏关键信息",没有预设的固定标签库
- 第三步:聚类相似的标签
- 存在问题 //待更新
- 采用多阶段的方法(每个阶段都基于GPT-4o):