超详细讲解urllib库的使用
目录
一.urllib的作用
二.urllib库的模块
2.1发送请求
2.1.1 urlopen
一.urllib的作用
- 实现HTTP请求的发送
不需要关心HTTP协议本身甚至更底层的实现,我们要做的就是指定请求的URL、请求头、请求体等信息
2.可以把服务器返回的响应转化为python对象
通过该对象便可以方便地获取响应的相关信息,如响应状态码、响应头、响应体等
注意:在python2中,有urllib和urllib2两个库来实现HTTP请求的发送。而Python3中,urllib2库已经不存在了,统一为urllib
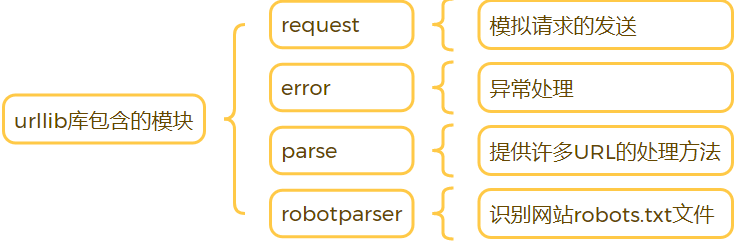
二.urllib库的模块
urllib库使用方法:它是python内置的HTTP请求库,也就是说不需要额外安装,可直接使用
2.1发送请求
2.1.1 urlopen
urllib.request模块作用:
- 模拟浏览器的请求发起过程
- 处理授权验证(Authentication)、重定向(Redirection)、浏览器Cookie以及其他一些功能
例:抓取python官网的HTML的源代码
import urllib.requestresponse = urllib.request.urlopen('https://www.python.org')
#1.打印python网页HTML的源代码
print(response.read().decode('utf-8'))
#2.打印响应对象的类型
print(type(response))运行结果如下:
![]()
type方法输出响应类型,响应的是一个HTTPResponse类型对象,主要包含read、readinto、getheader、getheaders、filemo等方法,以及msg、version、status、reason、debuglevel、closed属性。
得到响应后,把它赋值给response变量,然后就可以调用上述方法和属性,得到返回结果的一系列信息
import urllib.requestresponse = urllib.request.urlopen('https://www.python.org')
#3.打印响应对象的状态码
print(response.status)
#4.打印响应对象的响应头
print(response.getheaders())
#5.打印响应对象的响应头
print(response.getheader('Server'))
#6.打印响应对象的内容
print(response.read())
#7.打印响应对象内容
print(response.readinto())
#8.打印响应对象的文件描述符
print(response.fileno())urlopen的API:
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)参数说明:
1.data参数
data参数是可选的,在添加该参数时,需要使用bytes方法将参数转化为字节流编码格式的内容,即bytes类型。
如果传递data参数,那么它的请求方式就不再是GET,而是POST
import urllib.parse
import urllib.requestdata = bytes(urllib.parse.urlencode({'name': 'yhy'}), encoding='utf-8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read().decode('utf-8'))运行结果如下:
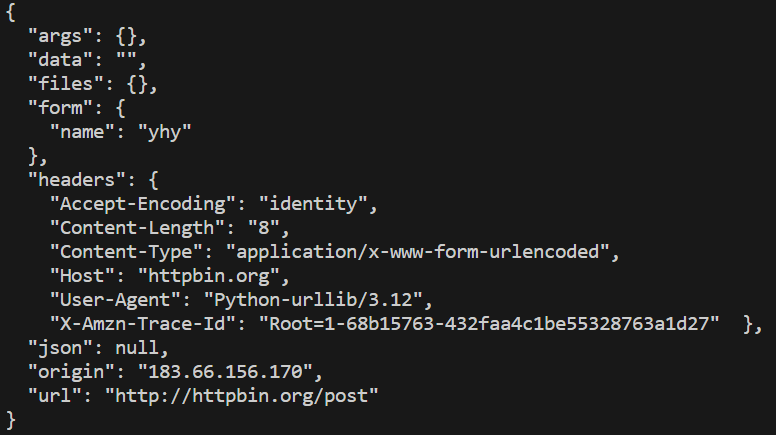
传递了一个参数name,值为yhy,需要将它转化为bytes类型。转码时采用bytes方法,该方法第一个参数时str(字符串)类型,因此用urllib.parse模块例urlencode方法将字典参数转化为字符串。
2.timeout参数
作用:用于设置超时时间,单位为秒,意思时如果请求超出了设置的这个时间,还没有响应,就会抛出异常。
如果不指定该参数,则会使用全局默认时间。
这个参数支持HTTP/HTTPS/FTP请求。
import urllib.parse
import urllib.requestresponse = urllib.request.urlopen('https://www.httpbin.org/get',timeout=0.1)
print(response.read())运行结果如下:
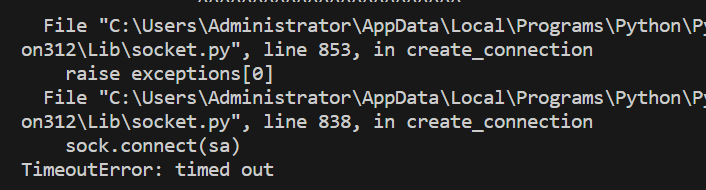
设置超时时间为0.1s。程序运行0.1s后,服务器依然没有响应,于是抛出了URLError异常。
因此,可以通过设置这个超时时间,实现当一个网页长时间未响应时,就跳过对她的抓取。此外,利用try except语句也可以实现