【完整源码+数据集+部署教程】传送带建筑材料识别系统源码和数据集:改进yolo11-AFPN-P345
背景意义
研究背景与意义
随着建筑行业的快速发展,建筑材料的种类和应用场景日益丰富,如何高效、准确地识别和分类这些材料成为了一个亟待解决的问题。传统的人工识别方法不仅耗时耗力,而且容易受到人为因素的影响,导致识别结果的不准确。因此,基于计算机视觉的自动化识别系统应运而生,成为提升建筑材料管理效率的重要工具。
YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而广受欢迎。近年来,YOLOv11的推出进一步提升了目标检测的精度和速度,使其在复杂环境下的应用成为可能。本研究旨在基于改进的YOLOv11模型,构建一个高效的传送带建筑材料识别系统。该系统将利用包含3100张图像的CODD数据集,涵盖砖、混凝土、泡沫、石膏板、管道、塑料、石材、瓷砖和木材等10种建筑材料,进行实例分割和分类。
通过对数据集的深入分析与处理,系统将能够实现对建筑材料的快速识别和分类,进而为建筑施工、材料管理和资源调配提供有力支持。此外,基于深度学习的自动识别系统还将为建筑行业的数字化转型提供技术保障,推动智能建筑的实现。
本研究不仅具有重要的理论意义,能够丰富计算机视觉领域的研究成果,同时也具有广泛的应用前景,能够为建筑行业的智能化发展提供切实可行的解决方案。通过实现高效的建筑材料识别,能够有效降低人工成本,提高工作效率,推动建筑行业的可持续发展。
图片效果
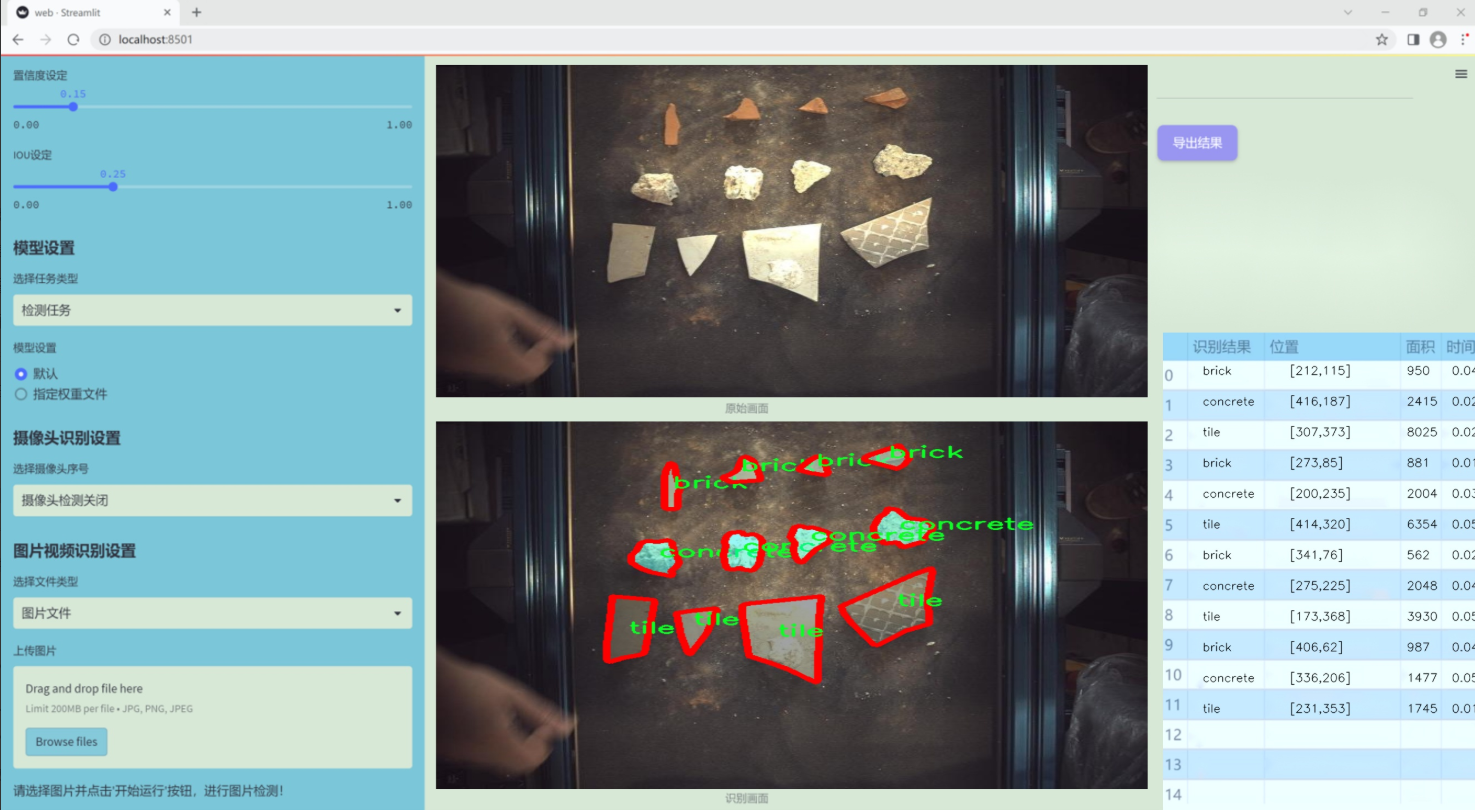
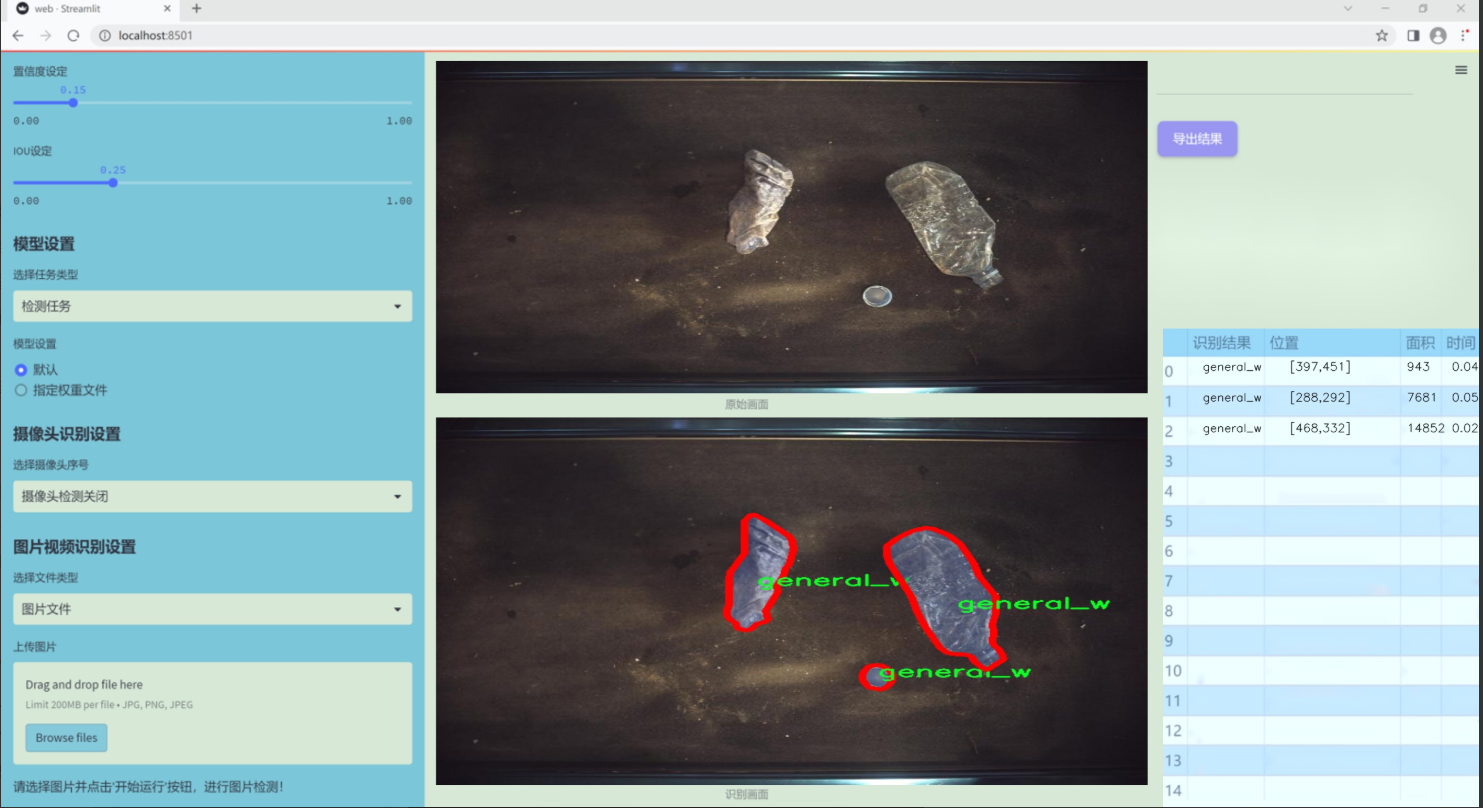
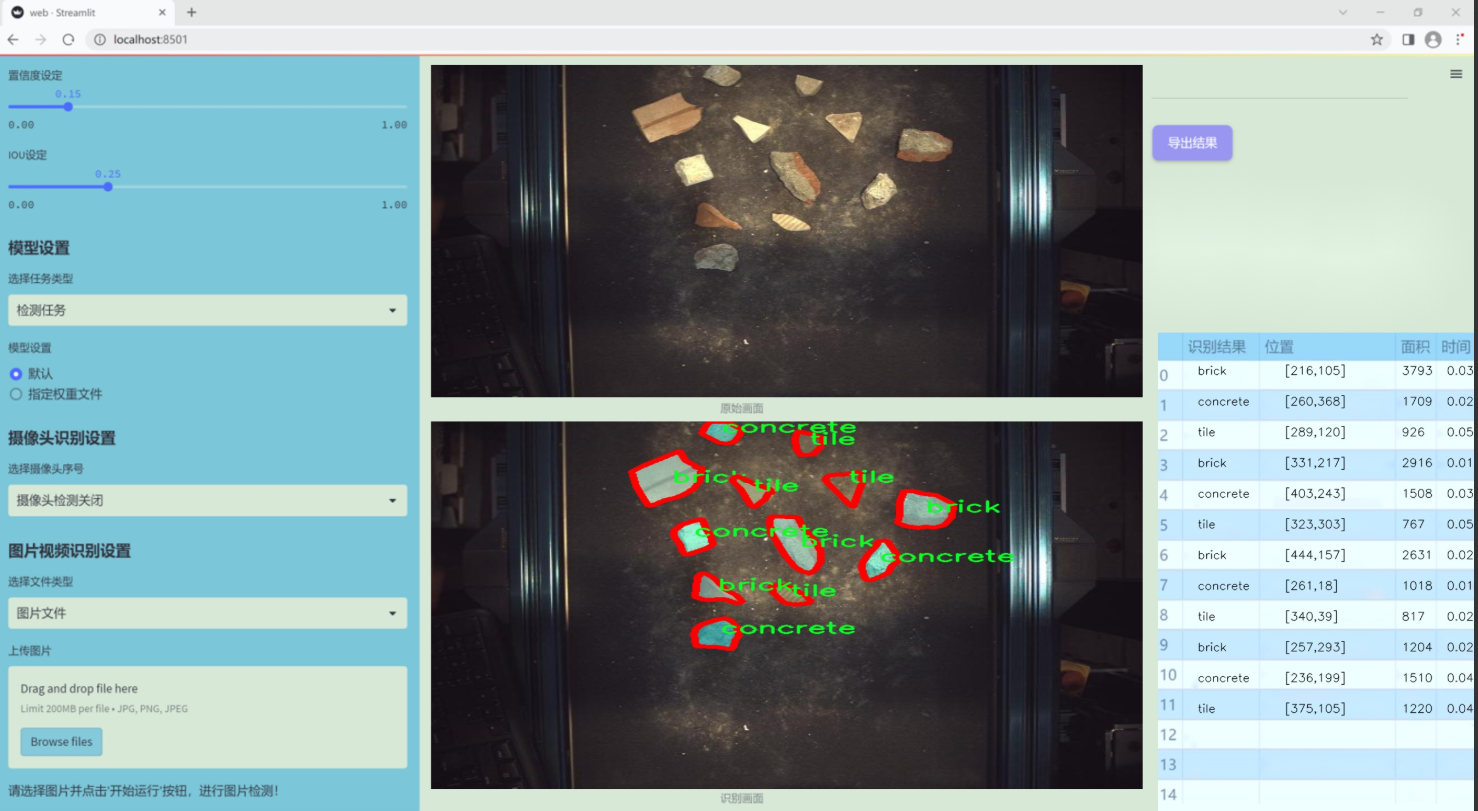
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11模型,以实现对传送带上建筑材料的高效识别。为此,我们构建了一个专门的数据集,涵盖了建筑材料的多种类别,以支持模型的训练和优化。该数据集的主题为“CODD”,意在为建筑行业提供更为智能化的材料识别解决方案。数据集中包含10个主要类别,具体包括砖块(brick)、混凝土(concrete)、泡沫(foam)、一般木材(general_w)、石膏板(gypsum_board)、管道(pipes)、塑料(plastic)、石材(stone)、瓷砖(tile)和木材(wood)。这些类别代表了在建筑施工和材料管理中常见的多种材料,具有广泛的应用价值。
在数据集的构建过程中,我们收集了大量的图像数据,确保每个类别的样本数量充足且多样化,以便模型能够学习到不同材料在各种环境和角度下的特征。每个类别的图像都经过精心标注,确保准确性和一致性,从而为模型的训练提供高质量的输入数据。此外,数据集还包含了不同光照条件、背景和材质的样本,以增强模型的鲁棒性,使其能够在实际应用中更好地适应各种复杂情况。
通过使用这一数据集,我们期望能够提升YOLOv11在建筑材料识别任务中的性能,使其在实时监测和自动化管理中发挥更大的作用。随着建筑行业对智能化和自动化需求的不断增加,开发出一个高效、准确的材料识别系统将为施工现场的管理和材料的使用效率带来显著的提升。因此,本项目的数据集不仅具有学术研究的价值,也为实际应用提供了重要的支持。





核心代码
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
from functools import partial
class Mlp(nn.Module):
“”" 多层感知机模块 “”"
def init(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().init()
out_features = out_features or in_features # 输出特征数
hidden_features = hidden_features or in_features # 隐藏层特征数
self.fc1 = nn.Conv2d(in_features, hidden_features, 1) # 第一层卷积
self.dwconv = DWConv(hidden_features) # 深度卷积
self.act = act_layer() # 激活函数
self.fc2 = nn.Conv2d(hidden_features, out_features, 1) # 第二层卷积
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):""" 前向传播 """x = self.fc1(x)x = self.dwconv(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
class LSKblock(nn.Module):
“”" LSK模块 “”"
def init(self, dim):
super().init()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim) # 深度卷积
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3) # 空间卷积
self.conv1 = nn.Conv2d(dim, dim//2, 1) # 1x1卷积
self.conv2 = nn.Conv2d(dim, dim//2, 1) # 1x1卷积
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3) # 压缩卷积
self.conv = nn.Conv2d(dim//2, dim, 1) # 1x1卷积
def forward(self, x): attn1 = self.conv0(x) # 第一个注意力分支attn2 = self.conv_spatial(attn1) # 第二个注意力分支attn1 = self.conv1(attn1) # 处理第一个分支attn2 = self.conv2(attn2) # 处理第二个分支attn = torch.cat([attn1, attn2], dim=1) # 拼接两个分支avg_attn = torch.mean(attn, dim=1, keepdim=True) # 平均注意力max_attn, _ = torch.max(attn, dim=1, keepdim=True) # 最大注意力agg = torch.cat([avg_attn, max_attn], dim=1) # 拼接平均和最大注意力sig = self.conv_squeeze(agg).sigmoid() # Sigmoid激活attn = attn1 * sig[:,0,:,:].unsqueeze(1) + attn2 * sig[:,1,:,:].unsqueeze(1) # 加权组合attn = self.conv(attn) # 最终卷积return x * attn # 通过注意力加权输入
class Attention(nn.Module):
“”" 注意力模块 “”"
def init(self, d_model):
super().init()
self.proj_1 = nn.Conv2d(d_model, d_model, 1) # 投影层
self.activation = nn.GELU() # 激活函数
self.spatial_gating_unit = LSKblock(d_model) # 空间门控单元
self.proj_2 = nn.Conv2d(d_model, d_model, 1) # 反投影层
def forward(self, x):shorcut = x.clone() # 残差连接x = self.proj_1(x)x = self.activation(x)x = self.spatial_gating_unit(x)x = self.proj_2(x)x = x + shorcut # 添加残差return x
class Block(nn.Module):
“”" 网络块,包含注意力和MLP “”"
def init(self, dim, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU):
super().init()
self.norm1 = nn.BatchNorm2d(dim) # 归一化层
self.norm2 = nn.BatchNorm2d(dim) # 归一化层
self.attn = Attention(dim) # 注意力模块
self.drop_path = nn.Identity() if drop_path <= 0. else DropPath(drop_path) # 随机深度
mlp_hidden_dim = int(dim * mlp_ratio) # MLP隐藏层维度
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) # MLP模块
def forward(self, x):""" 前向传播 """x = x + self.drop_path(self.attn(self.norm1(x))) # 注意力x = x + self.drop_path(self.mlp(self.norm2(x))) # MLPreturn x
class LSKNet(nn.Module):
“”" LSK网络 “”"
def init(self, img_size=224, in_chans=3, embed_dims=[64, 128, 256, 512], depths=[3, 4, 6, 3]):
super().init()
self.num_stages = len(depths) # 网络阶段数
for i in range(self.num_stages):# 每个阶段的嵌入层和块patch_embed = OverlapPatchEmbed(img_size=img_size // (2 ** i), in_chans=in_chans if i == 0 else embed_dims[i - 1], embed_dim=embed_dims[i])block = nn.ModuleList([Block(dim=embed_dims[i]) for _ in range(depths[i])]) # 每个阶段的块norm = nn.BatchNorm2d(embed_dims[i]) # 归一化层setattr(self, f"patch_embed{i + 1}", patch_embed)setattr(self, f"block{i + 1}", block)setattr(self, f"norm{i + 1}", norm)def forward(self, x):""" 前向传播 """outs = []for i in range(self.num_stages):patch_embed = getattr(self, f"patch_embed{i + 1}")block = getattr(self, f"block{i + 1}")norm = getattr(self, f"norm{i + 1}")x, H, W = patch_embed(x) # 嵌入for blk in block:x = blk(x) # 通过块x = norm(x) # 归一化outs.append(x) # 保存输出return outs
class DWConv(nn.Module):
“”" 深度卷积模块 “”"
def init(self, dim=768):
super(DWConv, self).init()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim) # 深度卷积
def forward(self, x):return self.dwconv(x) # 前向传播
def lsknet_t(weights=‘’):
“”" 创建LSKNet T版本 “”"
model = LSKNet(embed_dims=[32, 64, 160, 256], depths=[3, 3, 5, 2])
if weights:
model.load_state_dict(torch.load(weights)[‘state_dict’]) # 加载权重
return model
def lsknet_s(weights=‘’):
“”" 创建LSKNet S版本 “”"
model = LSKNet(embed_dims=[64, 128, 256, 512], depths=[2, 2, 4, 2])
if weights:
model.load_state_dict(torch.load(weights)[‘state_dict’]) # 加载权重
return model
代码核心部分说明:
Mlp类:实现了一个多层感知机,包含两个卷积层和一个深度卷积层,使用GELU激活函数和Dropout。
LSKblock类:实现了一个特殊的块,使用深度卷积和空间卷积来生成注意力特征,并通过加权组合来调整输入。
Attention类:实现了一个注意力机制,包含两个投影层和一个LSK块。
Block类:将注意力和MLP结合在一起,形成一个网络块。
LSKNet类:构建整个网络结构,包含多个阶段,每个阶段有嵌入层、多个块和归一化层。
DWConv类:实现了深度卷积,用于特征提取。
lsknet_t和lsknet_s函数:用于创建不同版本的LSKNet,并可选择性加载预训练权重。
这个程序文件 lsknet.py 实现了一个名为 LSKNet 的深度学习模型,主要用于图像处理任务。代码中使用了 PyTorch 框架,并定义了多个类和函数来构建和训练这个模型。
首先,程序导入了必要的库,包括 PyTorch 的核心模块和一些辅助函数。接着,定义了一个名为 Mlp 的类,它是一个多层感知机(MLP),包含两个卷积层和一个深度卷积层(DWConv),并使用 GELU 激活函数和 Dropout 层来增加模型的非线性和防止过拟合。
接下来,定义了 LSKblock 类,这是模型的一个基本构建块。它包含多个卷积层,利用空间注意力机制来增强特征表示。通过对输入特征进行不同的卷积操作并结合平均和最大池化的结果,生成一个加权的特征图,最后通过卷积层输出。
Attention 类实现了注意力机制,利用前向传播中的短路连接(shortcut connection)来增强模型的学习能力。它首先通过一个卷积层进行线性变换,然后经过激活函数和空间门控单元(LSKblock),最后再通过另一个卷积层输出。
Block 类则将注意力机制和 MLP 结合在一起,形成一个完整的网络模块。它使用批归一化(Batch Normalization)来规范化特征,并在前向传播中结合了 DropPath 技术以增强模型的鲁棒性。
OverlapPatchEmbed 类用于将输入图像转换为补丁嵌入,使用卷积层提取特征并进行归一化处理。
LSKNet 类是整个模型的主体,负责构建多个阶段的网络结构。每个阶段包含一个补丁嵌入层、多个块(Block)和一个归一化层。模型的深度和宽度可以通过参数进行调整。
此外,DWConv 类实现了深度卷积操作,用于增强特征提取的能力。
update_weight 函数用于更新模型的权重,确保模型字典中的权重与给定的权重字典相匹配。
最后,提供了两个函数 lsknet_t 和 lsknet_s,分别用于创建不同配置的 LSKNet 模型,并可选择加载预训练权重。主程序部分创建了一个 LSKNet 模型实例,并对一个随机生成的输入进行前向传播,输出每个阶段的特征图的尺寸。
整体来看,这个程序文件展示了如何使用现代深度学习技术构建一个复杂的神经网络模型,结合了卷积、注意力机制和多层感知机等多种技术,以提高图像处理任务的性能。
10.4 dyhead_prune.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DyReLU(nn.Module):
“”“动态ReLU激活函数,可以根据输入自适应调整参数。”“”
def init(self, inp, reduction=4, lambda_a=1.0, use_bias=True):
super(DyReLU, self).init()
self.oup = inp # 输出通道数
self.lambda_a = lambda_a * 2 # 调整因子
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化层
# 根据输入通道数和压缩比例计算压缩后的通道数squeeze = inp // reductionself.fc = nn.Sequential(nn.Linear(inp, squeeze), # 全连接层,将输入通道数压缩nn.ReLU(inplace=True), # ReLU激活函数nn.Linear(squeeze, self.oup * 2), # 再次全连接层,输出2倍的通道数h_sigmoid() # 使用h_sigmoid激活函数)def forward(self, x):"""前向传播函数。"""b, c, h, w = x.size() # 获取输入的批次大小、通道数、高度和宽度y = self.avg_pool(x).view(b, c) # 对输入进行自适应平均池化并调整形状y = self.fc(y).view(b, self.oup * 2, 1, 1) # 通过全连接层并调整形状# 分割y为两个部分,分别用于动态调整参数a1, b1 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + 1.0 # 动态调整参数a1b1 = b1 - 0.5 # 动态调整参数b1out = x * a1 + b1 # 计算输出return out # 返回输出
class DyDCNv2(nn.Module):
“”“带有归一化层的ModulatedDeformConv2d,用于动态头部。”“”
def init(self, in_channels, out_channels, stride=1, norm_cfg=dict(type=‘GN’, num_groups=16)):
super().init()
self.conv = ModulatedDeformConv2d(in_channels, out_channels, 3, stride=stride, padding=1) # 定义可调变形卷积
self.norm = build_norm_layer(norm_cfg, out_channels)[1] if norm_cfg else None # 根据配置构建归一化层
def forward(self, x, offset, mask):"""前向传播函数。"""x = self.conv(x.contiguous(), offset, mask) # 进行卷积操作if self.norm:x = self.norm(x) # 如果有归一化层,则进行归一化return x # 返回输出
class DyHeadBlock_Prune(nn.Module):
“”“DyHead模块,包含三种类型的注意力机制。”“”
def init(self, in_channels, norm_type=‘GN’):
super().init()
self.spatial_conv_high = DyDCNv2(in_channels, in_channels) # 高层空间卷积
self.spatial_conv_mid = DyDCNv2(in_channels, in_channels) # 中层空间卷积
self.spatial_conv_low = DyDCNv2(in_channels, in_channels, stride=2) # 低层空间卷积
self.spatial_conv_offset = nn.Conv2d(in_channels, 27, 3, padding=1) # 计算偏移和掩码的卷积层
self.task_attn_module = DyReLU(in_channels) # 任务注意力模块
def forward(self, x, level):"""前向传播函数。"""offset_and_mask = self.spatial_conv_offset(x[level]) # 计算偏移和掩码offset = offset_and_mask[:, :18, :, :] # 提取偏移mask = offset_and_mask[:, 18:, :, :].sigmoid() # 提取掩码并应用sigmoidmid_feat = self.spatial_conv_mid(x[level], offset, mask) # 中层特征sum_feat = mid_feat * self.scale_attn_module(mid_feat) # 计算加权特征# 处理低层和高层特征if level > 0:low_feat = self.spatial_conv_low(x[level - 1], offset, mask) # 低层特征sum_feat += low_feat * self.scale_attn_module(low_feat) # 加权低层特征if level < len(x) - 1:high_feat = F.interpolate(self.spatial_conv_high(x[level + 1], offset, mask), size=x[level].shape[-2:], mode='bilinear', align_corners=True) # 高层特征sum_feat += high_feat * self.scale_attn_module(high_feat) # 加权高层特征return self.task_attn_module(sum_feat) # 返回最终输出
代码说明:
DyReLU:自适应ReLU激活函数,能够根据输入动态调整参数。
DyDCNv2:实现了带有归一化层的可调变形卷积,用于特征提取。
DyHeadBlock_Prune:包含多个卷积层和注意力机制的模块,用于处理不同层次的特征。
这个程序文件 dyhead_prune.py 实现了一些深度学习中的模块,主要用于动态头(Dynamic Head)模型的构建,特别是在计算机视觉任务中。文件中使用了 PyTorch 框架,并包含了一些自定义的激活函数、卷积层和注意力机制。
首先,文件导入了必要的库,包括 PyTorch 的核心模块和一些特定的功能模块,如 mmcv 和 mmengine。这些库提供了构建神经网络所需的基本组件和工具。
接下来,定义了一个 _make_divisible 函数,该函数用于确保某个值是可被指定的除数整除的,并且在调整时不会过度降低值。这在构建网络时常用于确保通道数等参数符合特定的约束。
然后,文件中定义了几个自定义的激活函数类,包括 swish、h_swish 和 h_sigmoid。这些激活函数在深度学习中用于引入非线性特性,以帮助模型学习复杂的模式。
DyReLU 类是一个动态激活函数模块,它根据输入的特征动态调整激活函数的参数。它使用了全局平均池化和全连接层来生成激活参数,并支持空间注意力机制的选项。这个模块的设计允许模型在不同的上下文中自适应地调整其激活方式,从而提高性能。
DyDCNv2 类实现了一个带有归一化层的可调变形卷积(Modulated Deformable Convolution),它可以根据输入特征计算偏移量和掩码。这种卷积操作在处理图像时能够更好地捕捉到物体的形状和位置变化。
DyHeadBlock_Prune 类是动态头模块的主要构建块,包含了多个注意力机制。它结合了不同层次的特征,通过计算偏移量和掩码来进行卷积操作,并通过自适应池化和卷积来生成注意力权重。该模块的设计使得它能够灵活地整合来自不同层次的特征,从而增强模型的表达能力。
最后,整个模块的前向传播过程通过 forward 方法实现,该方法接收输入特征并计算出最终的输出特征。该过程涉及到特征的变形卷积、注意力权重的计算以及特征的融合。
总的来说,这个文件实现了一种灵活且强大的动态头结构,能够在多层次特征融合和自适应激活方面提供有效的支持,适用于各种计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式