【MySQL 为什么默认会给 id 建索引? MySQL 主键索引 = 聚簇索引?】
MySQL 索引
MySQL 为什么默认会给 id 建索引? & MySQL 主键索引 = 聚簇索引?
结论:在 MySQL (InnoDB) 中,主键索引是自动创建的聚簇索引,不需要删除,其他索引是补充优化。
1. MySQL 的id 索引是怎么来的?
问题描述
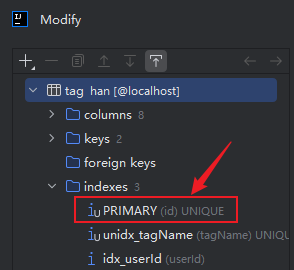
发现数据库表中
id字段默认有一个索引,并不清楚是怎么来的,或者是否应该删除这个索引?
核心解释
- 在 MySQL 中,主键本质上就是一个索引,由数据库自动生成,用于确保唯一性和非空约束,同时优化查找效率。
- 在 InnoDB 引擎中,主键还是 聚簇索引,决定数据的物理存储结构。
- 因此,看到
id自带索引是正常的、不需要删除。
官方引用
- Vultr 文档:“定义主键时,MySQL 会自动创建索引。”
Using Primary Keys, Indices, and Composite Keys in MySQL
- MySQL 官方文档:主键是唯一索引,会被用作聚簇索引。
CREATE TABLE Statement
Clustered and Secondary Indexes - Stack Overflow:主键一定会被索引、聚簇索引与主键。
Is the primary key automatically indexed in MySQL?
Does MySQL create an extra index for primary key or uses the data itself as an “index”
2. MySQL 自动创建的 id 索引对项目有没有影响?
不会产生负面影响,反而是必须的。 原因如下:
- 主键索引是表的核心结构
- 在 InnoDB 引擎下,主键索引是 聚簇索引,它决定了数据在磁盘上的物理存储顺序。
- 这意味着:每一行数据在物理层面上是按照
id排序存放的。
- 其他索引依赖主键
- 定义的二级索引(如
idx_userId)在 InnoDB 中存储的其实是:userId → 主键 id的映射。 - 也就是说,MySQL 通过二级索引定位到主键 id,再通过聚簇索引找到实际的数据行。
- 所以没有主键索引,二级索引都无法正常工作。
- 定义的二级索引(如
- 性能方面没有冲突
- 主键索引只影响按
id查找/排序的场景。 - 自己定义的索引会在特定查询中生效(比如按
tagName查找时会走唯一索引,按userId查找会走普通索引)。 - 优化器会根据 SQL 选择最合适的索引,不会因为有主键索引就影响你额外建的索引。
- 主键索引只影响按
- 例子
-- 走主键索引 select * from tag where id = 100; -- 走唯一索引 unidx_tagName select * from tag where tagName = 'Java';-- 走普通索引 idx_userId select * from tag where userId = 1;
总结
id主键索引是 MySQL 自动创建的,必须存在,它是所有索引的基石。- 手动添加的唯一索引和普通索引是根据业务场景来优化查询的,它们和主键索引是 互补关系。
- 因此,不需要删除 MySQL 默认的
id索引。相反,正确的做法是 在主键之外,根据实际查询场景设计合适的二级索引。
3. 索引设计说明
在这个项目中,一共涉及了三个索引:
- 主键索引(MySQL 自动创建)
id bigint auto_increment primary key- 在 MySQL(InnoDB 引擎)中,主键会自动创建聚簇索引 (Clustered Index)。
- 聚簇索引不仅保证了主键的唯一性和非空性,还决定了数据在磁盘上的物理存储顺序。
- 作用:每条记录都能通过主键索引快速定位,是表的基础结构。
- 唯一索引(手动创建)
constraint unidx_tagName unique (tagName)- 用于保证标签名的唯一性。
- 查询场景:当我通过标签名查找记录时,MySQL 优化器会优先走这个唯一索引。
- 普通索引(手动创建)
create index idx_userId on tag (userId);- 用于加速用户维度下的标签查询。
- 查询场景:比如获取某个用户的所有标签时,走这个索引会比全表扫描快很多。
4. 补充
面试鸭:MySQL InnoDB引擎中的聚簇索引和非聚簇索引有什么区别?
其他博客:MySQL 聚簇索引和非聚簇索引的区别
简单总结
| 特性 | 聚簇索引 (Clustered Index) | 非聚簇索引 (Secondary Index) |
|---|---|---|
| 存储结构 | 数据行按主键顺序存储 | 只存储索引列 + 主键值 |
| 数据定位 | 直接定位到数据行 | 先找到主键 → 再回表查数据 |
| 数量 | 每个表只能有一个 | 可以有多个 |
| 示例 | PRIMARY KEY (id) | INDEX (userId)、UNIQUE (tagName) |