基础IO详解
一、IO相关操作
文件操作本质就是 进程 和 被打开文件 的关系
1.C语言的文件操作
文件打开方式:
| r | 只读 |
| r+ | 读写 |
| w | 只写(会清空之前的内容) |
| w+ | 读写 |
| a | 追加(在之前的内容后追加) |
| a+ | 读写 |
文件操作相关函数:
int fgetc(FILE *stream)
int fputc(int c, FILE *stream)
char *fgets(char *str, int n, FILE *stream)
int fputs(const char *str, FILE *stream)
int fscanf(FILE *stream, const char *format, ...)
int fprintf(FILE *stream, const char *format, ...)
size_t fwrite(const void *ptr, size_t size, size_t count, FILE *stream)
size_t fread(void *ptr, size_t size, size_t count, FILE *stream)
文件指针相关:
int fseek(FILE *stream, long offset, int whence)
long ftell(FILE *stream)
void rewind(FILE *stream)
int feof(FILE *stream)
写文件:
#include <stdio.h>
#include <string.h>
int main()
{FILE *fp = fopen("myfile", "w");if(!fp){printf("fopen error!\n");}const char *msg = "hello bit!\n";int count = 5;while(count--){fwrite(msg, strlen(msg), 1, fp);}fclose(fp);return 0;
}读文件:
#include <stdio.h>
#include <string.h>
int main()
{FILE *fp = fopen("myfile", "r");if(!fp){ printf("fopen error!\n");}char buf[1024];const char *msg = "hello bit!\n";while(1){//注意返回值和参数,此处有坑,仔细查看man手册关于该函数的说明size_t s = fread(buf, 1, strlen(msg), fp);if(s > 0){buf[s] = 0;printf("%s", buf);}if(feof(fp))break;}fclose(fp);return 0;
}2.文件的操作路径(当前路径)
无论读还是写,都需要文件的路径,以上代码都没有具体的路径,全是文件名,却在当前目录下创建或读取文件,这是为什么呢?
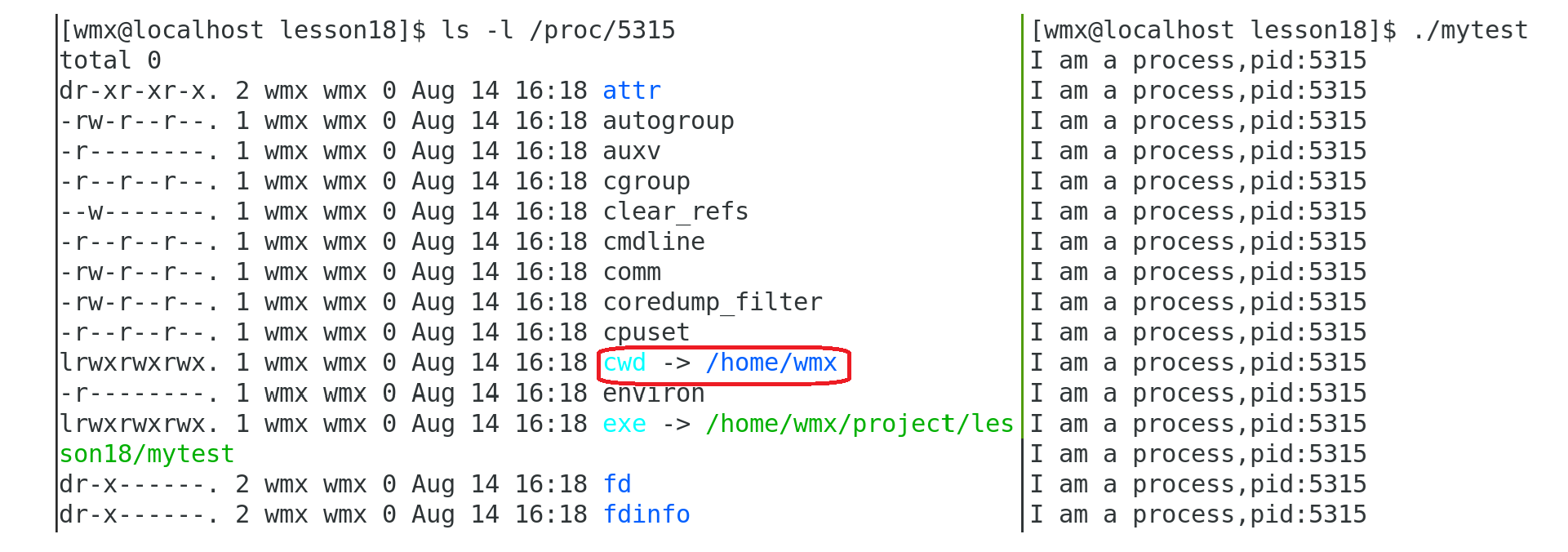
因为进程默认会在 当前路径 下操作,即 当前进程的工作目录 (默认为 进程当前“所在”的目录)
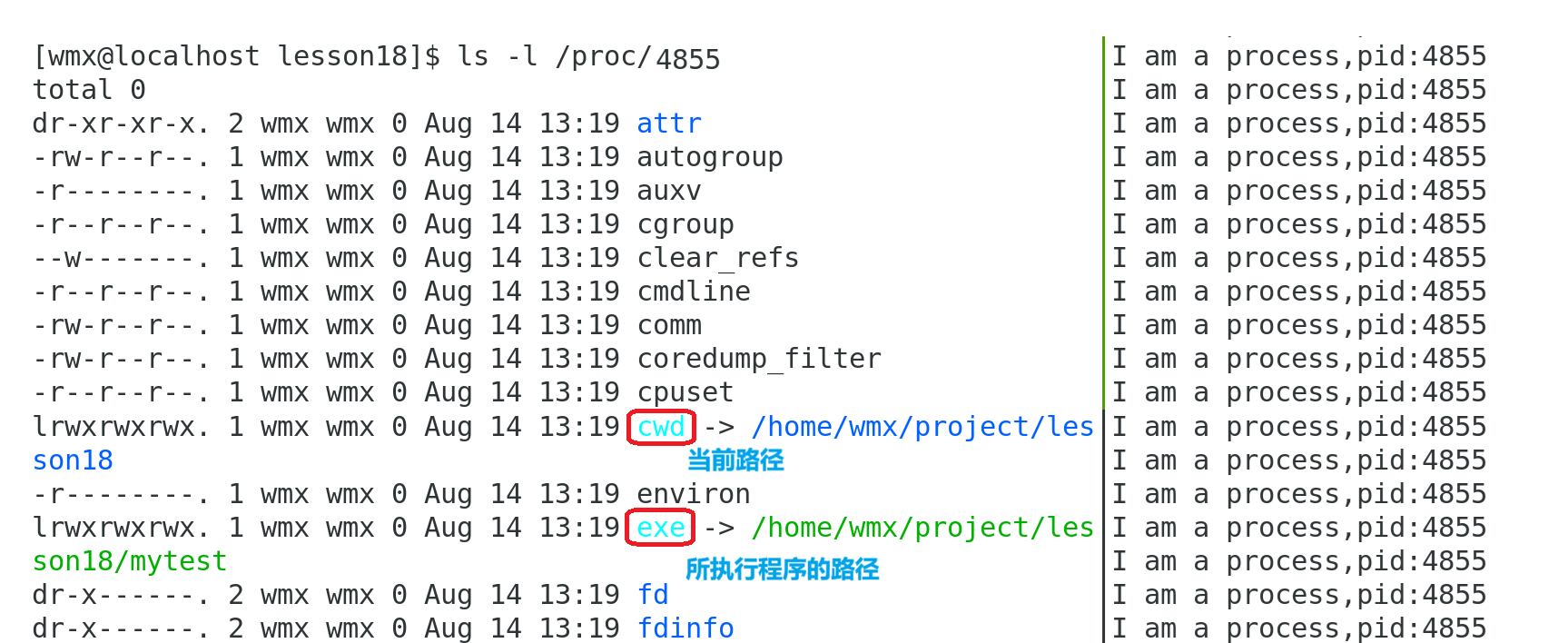
修改当前进程的工作目录:
在程序中调用chdir()函数
#include <unistd.h>int chdir(const char *path);
3.创建的文件权限
创建的文件权限与 默认权限(mask)和umask 有关
新建文件默认权限=0666
umask=超级用户默认为0022,普通用户默认为0002
实际创建的出来的文件权限:
mask & ~umask(按位与)
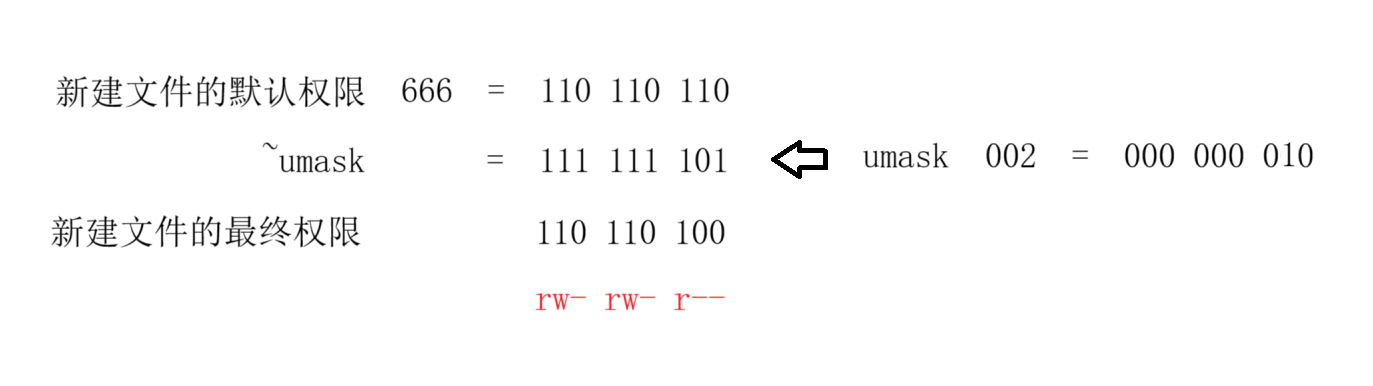
直观理解:想要去掉的权限,其umask二进制位为1
修改umask值:程序内调用umask()函数
注:修改只针对当前子进程有效
#include <sys/types.h>
#include <sys/stat.h>mode_t umask(mode_t mask);4.标准流
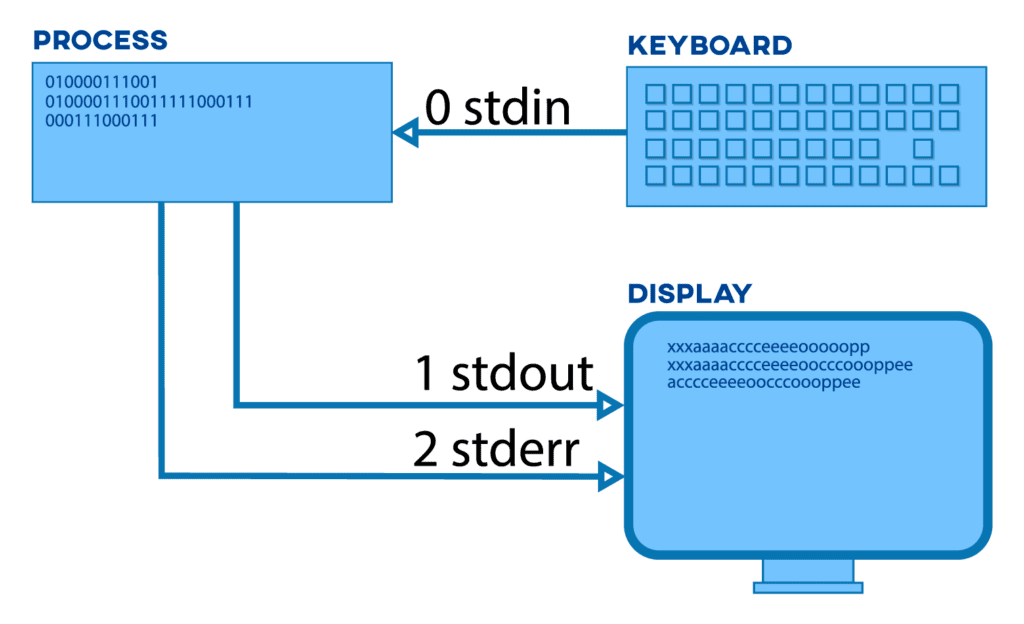
C语言会默认打开三个输入输出流:stdin(标准输入), stdout(标准输出), stderr(标准错误)
#include <stdio.h>extern FILE *stdin;extern FILE *stdout;extern FILE *stderr;
它们都是FILE*,文件类型指针,被操作系统当作文件管理
一般来说,stdin和stderr就是显示器,stdout就是键盘
后面还会提到他们...
举例:输出内容到显示器:
#include <stdio.h>
#include <string.h>
int main()
{const char *msg = "hello fwrite\n";fwrite(msg, strlen(msg), 1, stdout);printf("hello printf\n");fprintf(stdout, "hello fprintf\n");return 0;
}二、系统IO
由于文件在磁盘中,而磁盘属于硬件,所以想要操作文件就必须使用系统调用接口
C语言,C++,以及其他语言的IO接口本质上就是去封装系统的IO接口
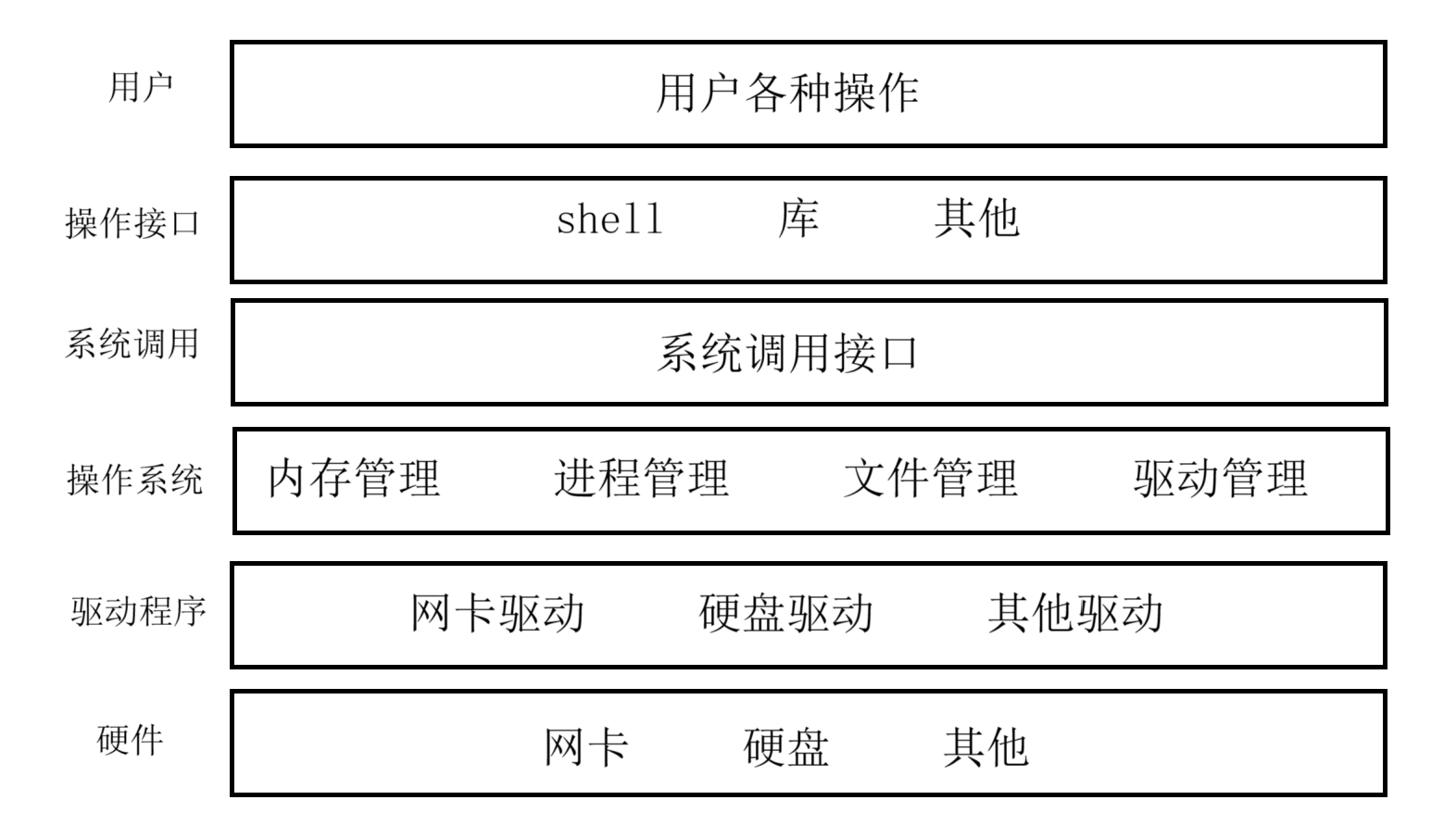
上面的 fopen fclose fread fwrite 都是 C 标准库当中的函数,我们称之为库函数(libc)
而下面要说的 open close read write lseek函数 都属于系统提供的接口,称之为系统调用接口
1.文件描述符fd(file descriptor)
1)文件描述符的概念
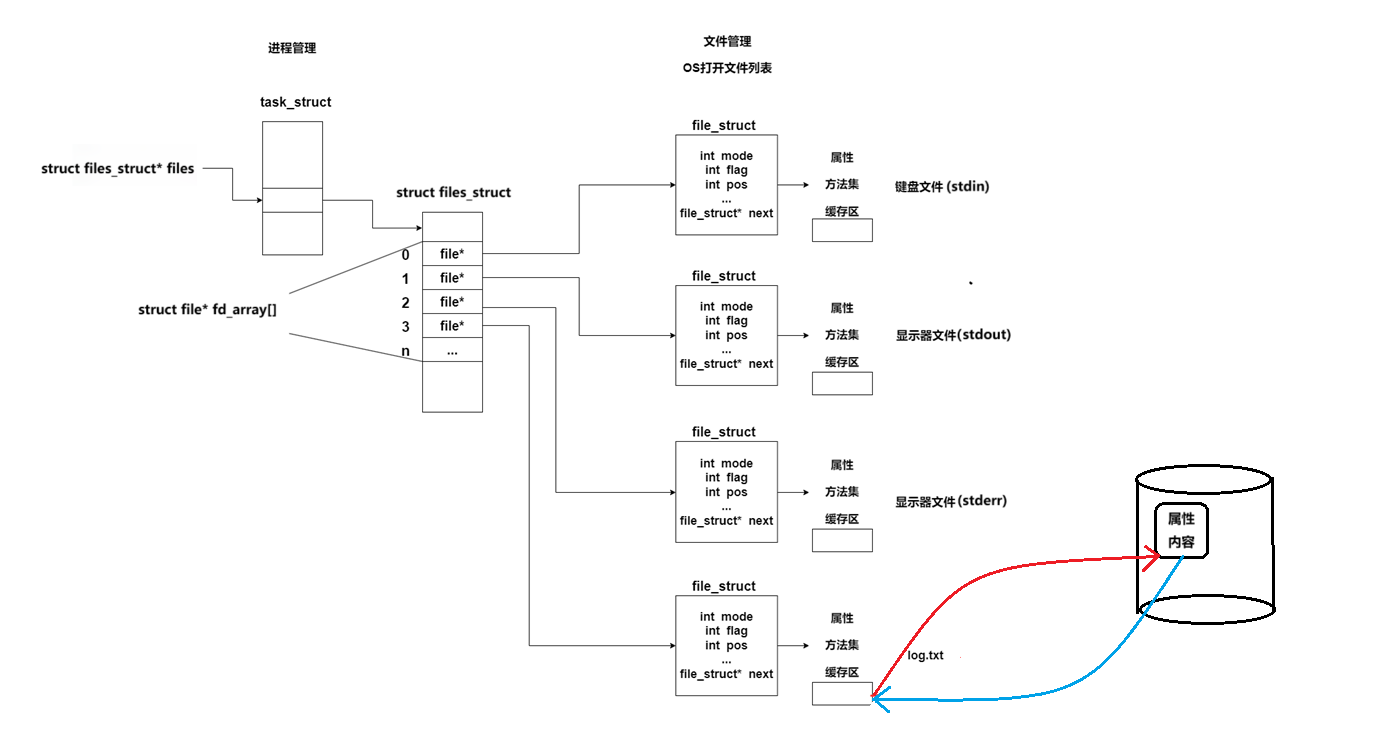
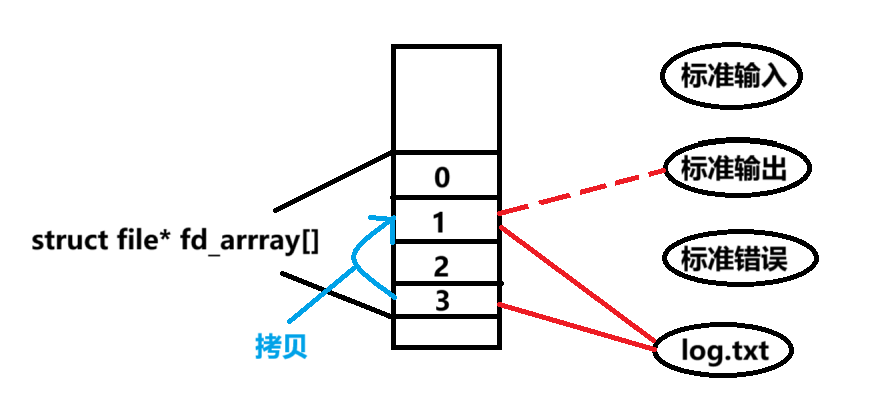
当我们打开文件时,操作系统在内存中要创建file_struct来描述目标文件
每个进程的task_struct中都有一个指针*files, 指向一张表files_struct, 该表最重要的部分就是包含一个指针数组fd_array[],每个元素都是一个指向打开文件的指针
所以,只要拿着文件描述符,就可以找到对应的文件
文件描述符的本质,就是数组下标!
2)文件描述符的分配规则
在 files_struct 数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符
但是当我们创建文件时,fd默认从3开始分配,这是因为0,1,2被占用了
如果关闭了0/1/2,fd也会将其重新分配
0:标准输入 stdin
1:标准输出 stdout
2:标准错误 stderr
3)举例
直接打开文件:此时创建的文件fd=3
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>int main()
{int fd = open("myfile.txt", O_WRONLY|O_CREAT|O_TRUNC);if(fd < 0){perror("open");return 1;}printf("fd: %d\n", fd);close(fd);return 0;
}
关闭fd=0的文件(stdin),再打开文件:此时创建的文件fd=0
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>int main()
{close(0);int fd = open("myfile.txt", O_WRONLY|O_CREAT|O_TRUNC);if(fd < 0){perror("open");return 1;}printf("fd: %d\n", fd);close(fd);return 0;
}
2.IO相关的系统调用函数
1)open函数
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
a.参数:
pathname:
表示要打开的文件及路径(只有文件名则默认为当前路径)
flags:
表示打开方式
O_RDONLY 只读打开 O_WRONLY 只写打开 O_RDWR 可读可写打开
下列常数是可选择的:
O_CREAT 若文件不存在则创建它。使用此选项时,需要同时说明第三个参数mode,用其说明该新文件的权限。
O_EXCL 如果同时指定了O_CREAT,而文件已经存在,则出错。
O_APPEND 每次写时都加到文件的尾端,不会覆盖原先内容。
O_TRUNC 打开文件时,直接清空文件内部数据
这些flags本质都是宏,通过 特定的比特位为1,其余比特位为0 实现
可利用 位或运算符 同时使用多个选项
例如:
#define ONE (1<<0)
#define TWO (1<<1)
#define THREE (1<<2)ONE|TWO|THREE
与C语言选项对比:
| r | O_RDONLY |
| w | O_WRONLY|O_CREAT|O_TRUNC |
| a | O_WRONLY|O_CREAT|O_APPEND |
mode:
表示所创建文件的默认权限(mask),但是文件的最终权限是 mask&~umask (umask默认为0002)
只有在flags中使用了O_CREAT标志,才需要使用mode选项
b.返回值:
所打开文件的文件描述符fd
c.举例:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>//r只读
int fd = open("log.txt",O_RDONLY);
//w只写(增加功能:没有就创建新文件+清空数据)
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
//a追加(增加功能:没有就创建新文件)
int fd = open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);2)write和read函数
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
ssize_t read(int fd, void *buf, size_t count);a.参数:
fd:
要 被写入/读出 的文件所对应的文件描述符
buf:
无类型的指针buf,可以存放要 写/读 的内容
可以看出,要 写/读 的内容不管是文本文件,还是其他种类文件,操作系统都会当作二进制类型处理
注:在输出字符串时,没必要将"\0"输出,因为"\0"在C语言中作为字符串结尾标志,并且会被处理为二进制乱码输入文件中;在读入字符串时,需要加上"\0"
count:
表示 输出/输入 数据的最大字节数
b.返回值
表示 输出/输入 数据的实际字节数
c.举例
char outBuffer[] = {"hello\n"};
//不会将"\0"写入
write(1, outBuffer, strlen(outBuffer));char inBuffer[64];
ssize_t num = read(0, inBuffer, sizeof(inBuffer)-1);
//在字符串末尾加上"\0"
if(num > 0) inBuffer[num] = 0;3)close函数
#include <unistd.h>
int close(int fd);参数:fd:文件描述符
返回值:成功返回0,失败返回-1
3.重定向
1)重定向概念
重定向是指将命令的 输入 或 输出 从默认的标准位置(如终端)重定向到其他位置(如文件或其他设备)
2)重定向本质
通过操作 文件描述符fd 来实现输入输出的重定向,上层用的fd不变,更改对应fd所指向的文件
那么,关闭fd=0/1/2所指向的文件,使其指向其他文件,即可实现重定向
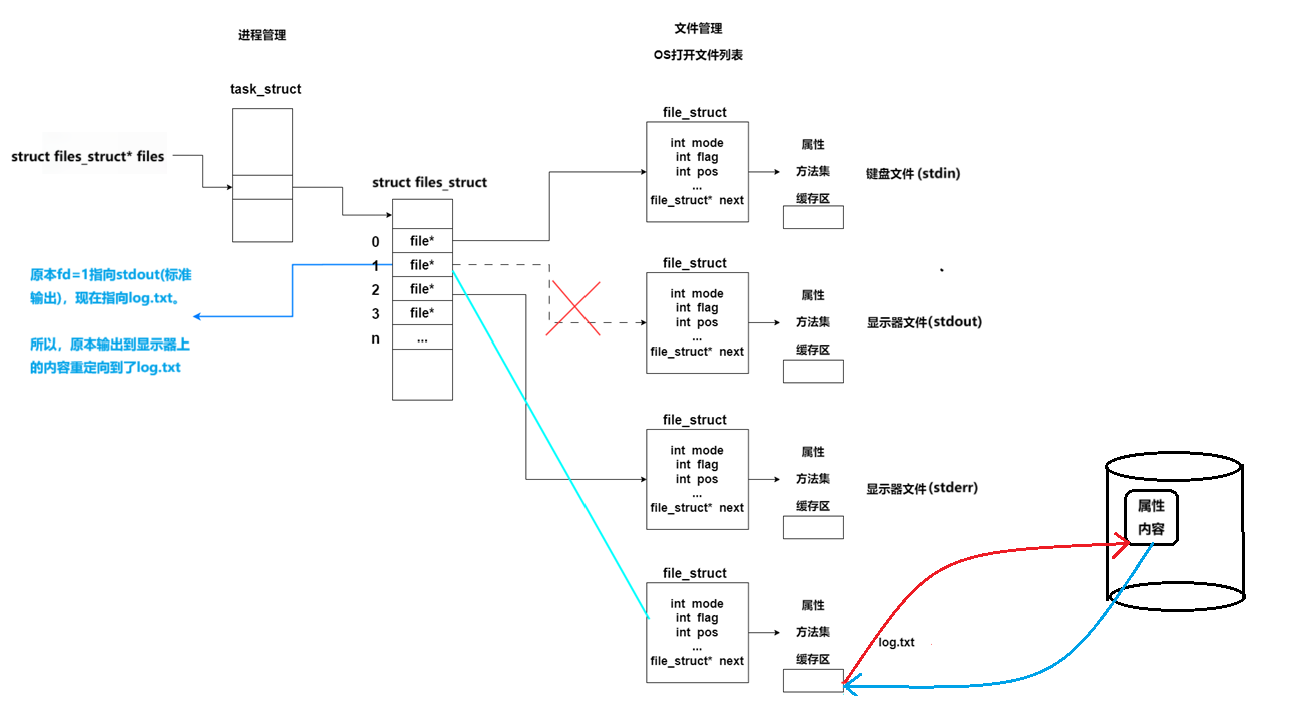
3)重定向举例
关闭fd=1文件,打开新文件,fd=1指向新文件,完成重定向
必要说明:
printf 是 C 库当中的 IO 函数,一般往 stdout 中输出,但是 stdout 是文件类型指针FILE*,在底层访问文件的时候,找的还是 fd=1的文件。一般情况下,fd=1指向的文件是显示器,但此时, fd=1指向的文件是lg.txt。
所以,向显示器输出的任何消息都会写入到文件log.txt中,进而完成输出重定向。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>int main()
{//关闭了显示屏close(1);//将fd=1重新分配给文件log.txtint fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);if(fd < 0){perror("open");return 1;}//原本应该输出到显示屏,现在输出到log.txtprintf("fd: %d\n", fd);//刷新缓冲区fflush(stdout);close(fd);return 0;
}
4)重定向的方法
命令行中:
>操作符:输出重定向(覆盖写入)
>>操作符:输出重定向(追加写入)
<操作符:输入重定向(从文件中读取)
C程序中:
方式一:先关闭fd=0/1/2的文件,再创建新文件
//关闭了显示屏
close(1);
//将fd=1重新分配给文件log.txt
int fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);方式二:系统调用:dup2函数
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);dup2函数将oldfd中的地址拷贝给newfd,newfd原本指向标准位置,现在和oldfd同时指向新文件,同时会关闭newfd原来指向的文件
举例:
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>int main()
{int fd = open("redirect.txt", O_WRONLY|O_TRUNC|O_CREAT, 0666);if(fd < 0){perror("open");return 0;}dup2(fd, 1);printf("fd: %d\n", fd);return 0;
}
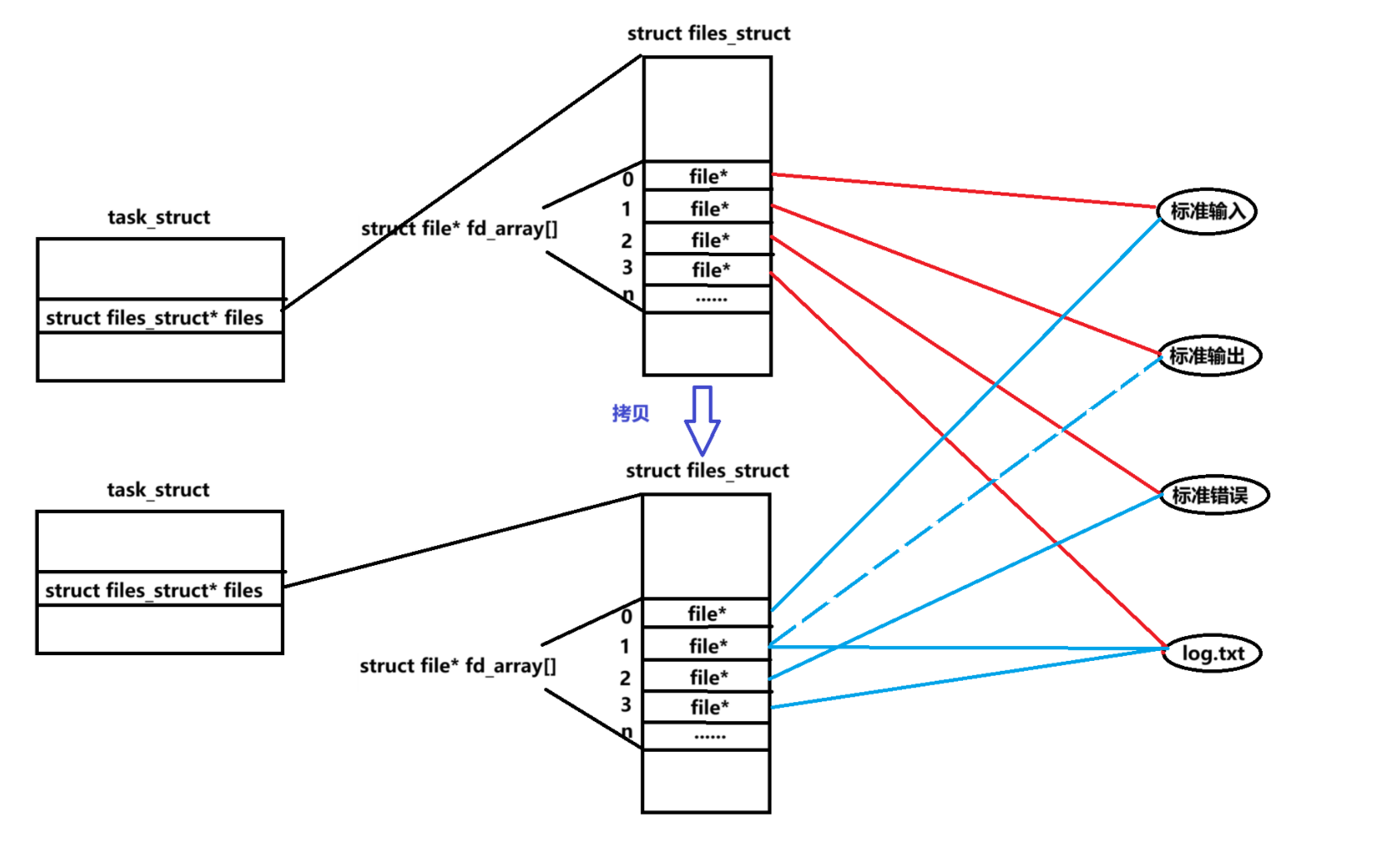
5)子进程重定向
子进程重定向不影响父进程
原因:子进程会拷贝files_sturct,包含了fd与文件对应关系的表,在其中进行修改
举例:子进程输出重定向
6)模拟shell中实现重定向功能
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <ctype.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include <errno.h>#define NUM 1024
#define OPTION_NUM 64//支持重定向命令
#define NONE_REDIR 0//无重定向
#define INPUT_REDIR 1//输入重定向
#define OUTPUT_REDIR 2//输出重定向
#define APPEND_REDIR 3//追加重定向
//宏函数:跳过命令中的空格
#define skipSpace(start) do{while(isspace(*start)) ++start;}while(0)char lineCommand[NUM];//存放整个命令行
char* myargv[OPTION_NUM];//存放切割后的命令行参数
int status = 0;const char* UserName()
{const char* name = getenv("USER");if(name)return name;elsereturn "None";
}const char* HostName()
{const char* name = getenv("HOSTNAME");if(name)return name;elsereturn "None";
}const char* CurrentWorkDir()
{const char* name = getenv("PWD");if(name)return name;elsereturn "None";
}//存放重定向类型
int redirType = NONE_REDIR;
//存放重定向命令中的文件名
char* redirFile = NULL;//解析重定向命令
//"ls > log.txt"->"ls" "log.txt"
void commandCheck(char* commands)
{assert(commands);char* start = commands;char* end = commands + strlen(commands);while(start < end){if(*start == '>'){*start = '\0';start++;//追加重定向if(*start == '>'){redirType = APPEND_REDIR;start++;}//输出重定向else{redirType = OUTPUT_REDIR;}skipSpace(start);redirFile = start;break;}//输入重定向else if(*start == '<'){*start = '\0';start++;skipSpace(start);//填写重定向信息redirType = INPUT_REDIR;redirFile = start;break;}else{start++;}}
}int main()
{while(1){//输出提示符printf("[%s@%s %s]$", UserName(), HostName(), CurrentWorkDir());fflush(stdout);//刷新缓冲区//获取用户输入char *s = fgets(lineCommand, sizeof(lineCommand)-1, stdin);assert(s != NULL);s = NULL;//防止野指针//消除用户最后输入的\nlineCommand[strlen(lineCommand)-1] = 0;//重定向准备工作//初始化redirType = NONE_REDIR;redirFile = NULL;errno = 0; //拆分命令commandCheck(lineCommand); //切割命令行字符串,使其变为多个命令行参数myargv[0] = strtok(lineCommand, " ");//以空格为分隔符切割int i = 1;//如果没有可以分割的子串了,strtok()返回NULL,此时myargv[end]=NULLwhile(myargv[i++] = strtok(NULL, " "));//执行内置命令,如cd,echo命令//执行cd命令if(myargv[0] != NULL && strcmp(myargv[0], "cd") == 0){if(myargv[1] != NULL){chdir(myargv[1]);//直接改变父程序的工作路径continue;//无需再创建子进程执行命令}}//执行echo命令if(myargv[0] != NULL && myargv[1] !=NULL && strcmp(myargv[0], "echo") == 0){if(strcmp(myargv[1], "$?") == 0){printf("%d\n",(status>>8) & 0xFF);}else{printf("%s\n",myargv[1]);}continue;//无需再创建子进程执行命令}//创建子进程执行命令pid_t id = fork();assert(id != -1);//通过子进程替换,执行命令if(id == 0){//执行重定向命令switch(redirType){case NONE_REDIR:break;case INPUT_REDIR:{int fd = open(redirFile, O_RDONLY);if(fd < 0){perror("open");exit(errno);}dup2(fd, 0);break;}case OUTPUT_REDIR:case APPEND_REDIR:{int flags = O_WRONLY | O_CREAT;if(redirType == APPEND_REDIR) flags |= O_APPEND;else flags |= O_TRUNC;int fd = open(redirFile, flags, 0666);if(fd < 0){perror("open");exit(errno);}dup2(fd,1);break;}default:printf("bug\n");break;}execvp(myargv[0], myargv);exit(1);}//阻塞等待,获取子进程的退出结果pid_t ret = waitpid(id, &status, 0);assert(ret > 0);(void)ret;}
}4.缓冲区
1)缓冲区的作用
a.缓冲区作为临时中转站,程序可快速将数据写入缓冲区后继续执行,从而减少CPU中断次数
b.批量处理数据
2)缓冲区的意义
节省进程进行数据IO的时间
3)缓冲区的位置
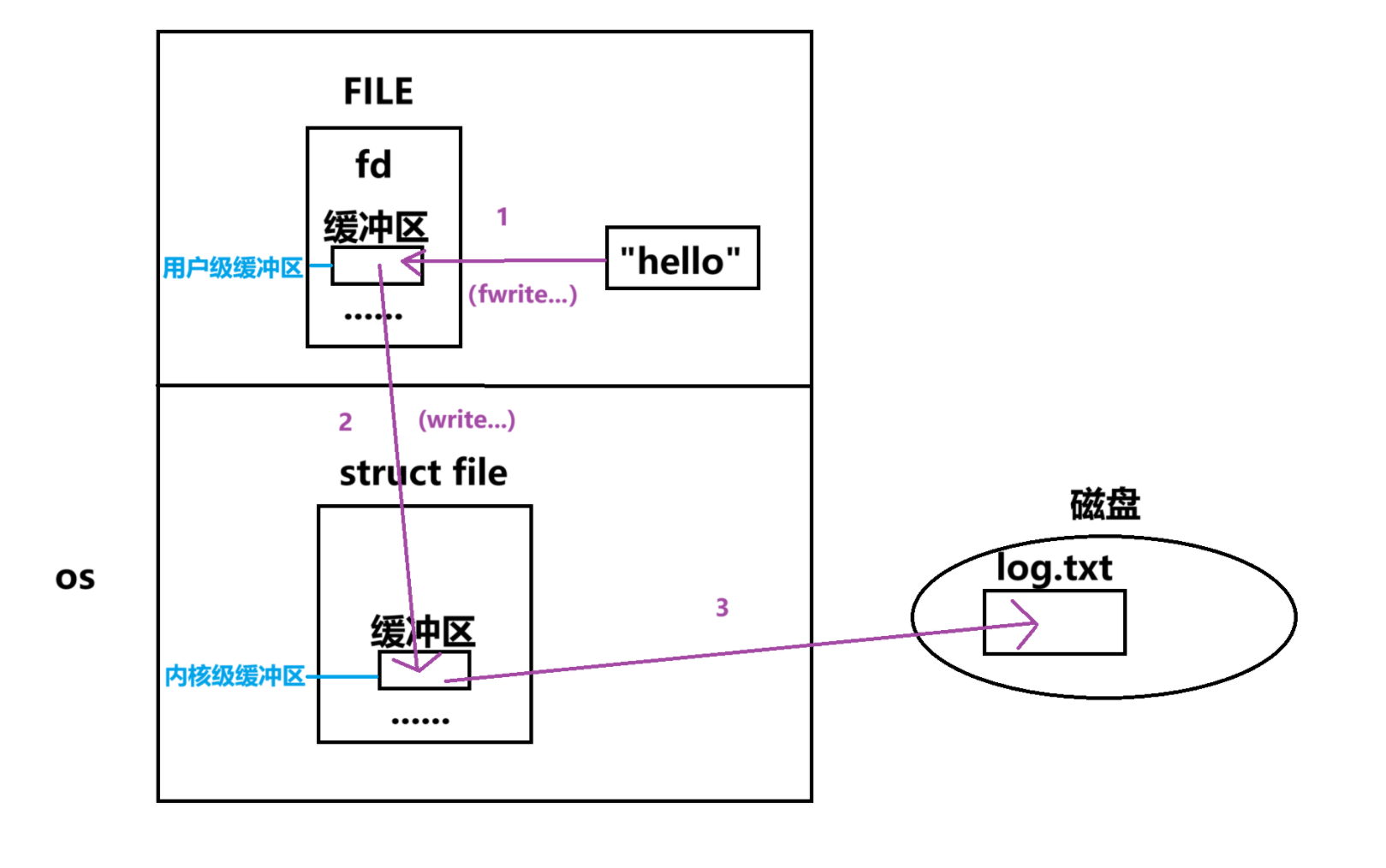
用户级缓冲区:
C语言中,每个打开文件都有对应的FILE结构体,它里面有对应打开文件的fd,而打开文件的缓冲区也在FILE中
所以,该缓冲区在封装的C语言库中,属于语言层面
内核级缓冲区:在操作系统中
4)缓冲区的刷新策略
a.用户级缓冲区(库函数中):
1.立即刷新——无缓冲(用户强制刷新:fflush函数;进程退出)
2.行刷新——行缓存(向显示器写入)
3.缓冲区满——全缓冲(向磁盘文件写入)
强制刷新函数:
#include <stdio.h>
int fflush(FILE *stream);
b.内核级缓冲区(操作系统中):
操作系统自主决定
强制刷新函数:
#include <unistd.h>int fsync(int fd);5)子进程的缓冲区
输出举例:
#include <stdio.h>
#include <string.h>
#include <unistd.h>int main()
{//验证C语言中的缓存区//C语言的IO函数const char* s = "fprintf\n";const char* S = "fwrite\n";fprintf(stdout, "%s", s);fwrite(S, strlen(S), 1, stdout);//系统调用const char* c = "write\n";write(stdout->_fileno/*fd*/, c, strlen(c));fork();return 0;
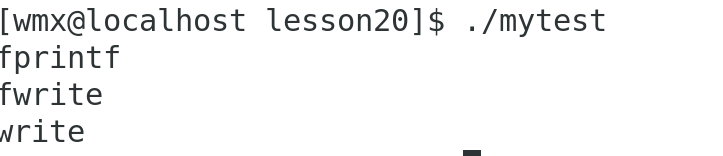
}向显示器打印:
向文件中打印:
现象:C语言的函数都输出了两次;而系统调用的函数只输出了一次
原因:
C语言封装的缓冲区写入显示器时采用行缓存。在创建子进程之前,数据就已经打印到显示器上,FILE内的缓冲区中没有数据;
C语言封装的缓冲区写入文件时采用全缓冲。子进程创建后,数据仍在FILE内的缓冲区中,紧接着进程退出就会刷新缓冲区,此时,父子进程的任意一个退出都会刷新缓冲区,触发写时拷贝,后退出的进程会再次刷新其所拷贝的缓冲区,所以输出了两次。
而系统调用函数没有经过C语言封装的缓冲区,所以只输出了一次。
6)模拟C语言封装系统调用,并设置缓冲区
myStdio.h
#pragma once#include <assert.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define SIZE 1024
//刷新方式
#define SYNC_NOW (1<<0)//立即刷新
#define SYNC_LINE (1<<1)//行缓存
#define SYNC_FULL (1<<2)//全缓冲typedef struct _FILE
{int flags;//刷新方式int fileno;//fdint cap;//buffer的总容量int size;//buffer的当前使用量char buffer[SIZE];//缓冲区
}FILE_;FILE_* fopen_(const char* path_name, const char* mode);
void fwrite_(FILE_* fp, const void* ptr, int num);
void fclose_(FILE_* fp);
void fflush_(FILE_* fp);myStdio.c
#include "myStdio.h"
FILE_ *fopen_(const char* path_name, const char* mode)
{int flags = 0;int defaultMode = 0666;if(strcmp(mode, "r") == 0){flags |= O_RDONLY;}else if(strcmp(mode, "w") == 0){flags |= (O_WRONLY | O_CREAT | O_TRUNC);}else if(strcmp(mode, "a") == 0){flags |= (O_WRONLY | O_CREAT | O_APPEND);}else{}int fd = 0;//只读if(flags & O_RDONLY) fd = open(path_name, flags);//只写else fd = open(path_name, flags, defaultMode);//打开失败if(fd < 0){const char* err = strerror(errno);write(2, err, strlen(err));return NULL;}FILE_* fp = (FILE_*)malloc(sizeof(FILE_));assert(fp);//初始化FILE_fp->flags = SYNC_LINE;//默认设置为行刷新fp->fileno = fd;fp->cap = SIZE;fp->size = 0;memset(fp->buffer, 0, SIZE);//返回FILE*指针return fp;
}void fwrite_(FILE_* fp, const void* ptr, int num)
{//1.写入缓冲区memcpy(fp->buffer+fp->size, ptr, num);fp->size += num;//2.判断是否刷新if(fp->flags & SYNC_NOW)//立即刷新{write(fp->fileno, fp->buffer, fp->size);fp->size = 0;//清空缓冲区}else if(fp->flags & SYNC_FULL)//全缓冲{if(fp->size == fp->cap){write(fp->fileno, fp->buffer, fp->size);fp->size = 0;}}else if(fp->flags & SYNC_LINE)//行缓存{if(fp->buffer[fp->size-1] == '\n'){write(fp->fileno, fp->buffer, fp->size);fp->size = 0;}}else{}}
//刷新缓冲区:从缓冲区写入系统
void fflush_(FILE_ *fp)
{if(fp->size > 0) write(fp->fileno, fp->buffer, fp->size);fsync(fp->fileno);//内核级缓冲区强制刷新fp->size = 0;
}void fclose_(FILE_* fp)
{fflush_(fp);close(fp->fileno);
}测试文件main.c
#include "myStdio.h"const char* filename = "./log.txt";int main()
{FILE_ *fp = fopen_(filename, "w");if(fp == NULL) return 1;int cnt = 3;const char *msg = "hello world\n";while(cnt){fwrite_(fp, msg, strlen(msg));sleep(1);cnt--;}fclose_(fp);return 0;
}运行结果:
三、文件系统
文件系统是静态管理磁盘上没有被打开的文件的
1.磁盘的结构
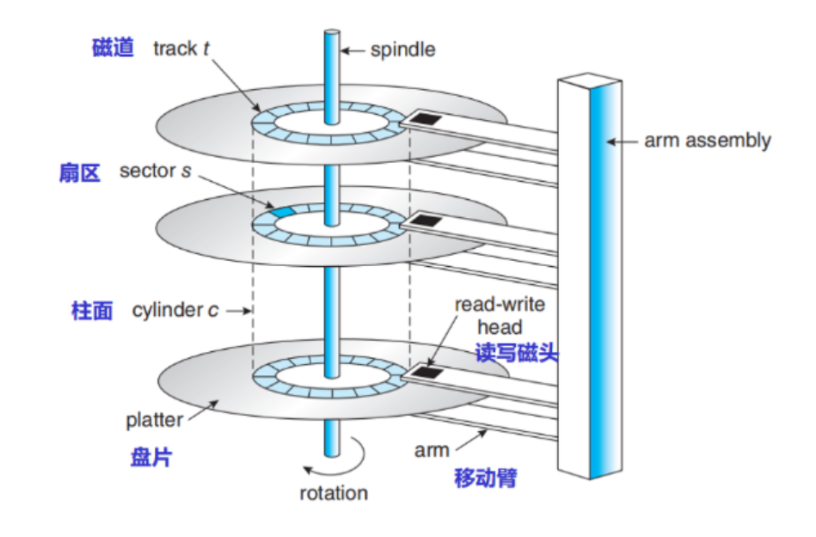
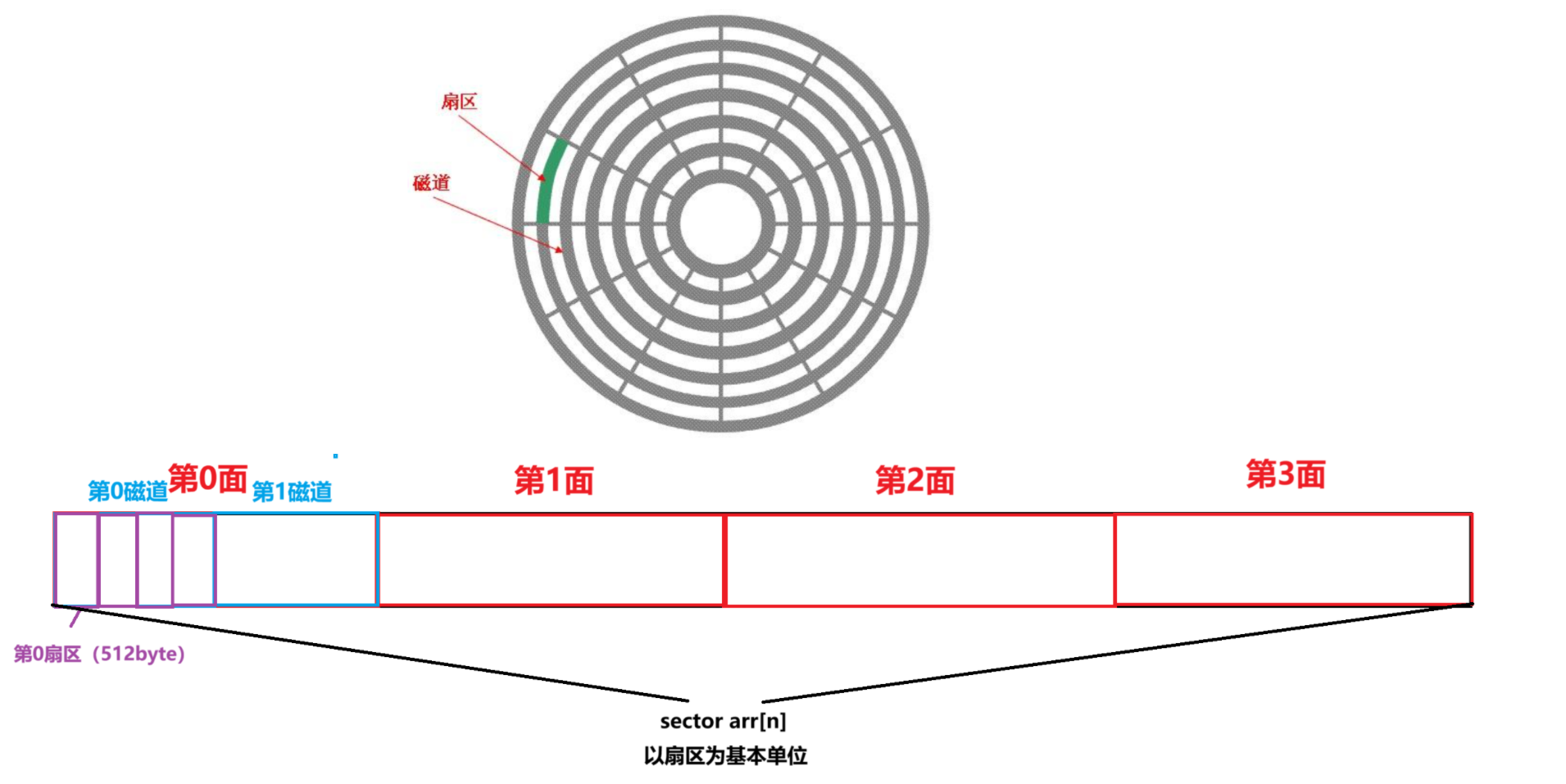
1)磁盘的物理结构
盘片:硬盘有多个盘片,每盘片2面
磁头:每面一个磁头扇区:盘片被分为多个扇形区域,每个扇区存放512字节的数据,是硬盘的最小存储单位
磁道:同一盘片不同半径的同心圆,是由磁头在盘片表面划出的圆形轨迹
柱面:不同盘片相同半径构成的圆柱面,由同一半径圆的多个磁道组成
盘片旋转,磁头摆动,但是磁头和盘面没有接触

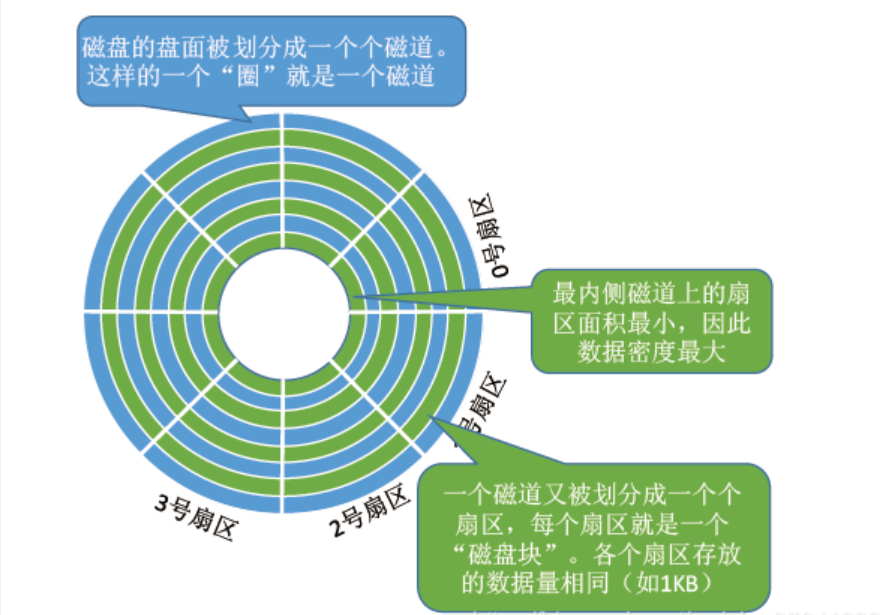
2)磁盘的存储结构
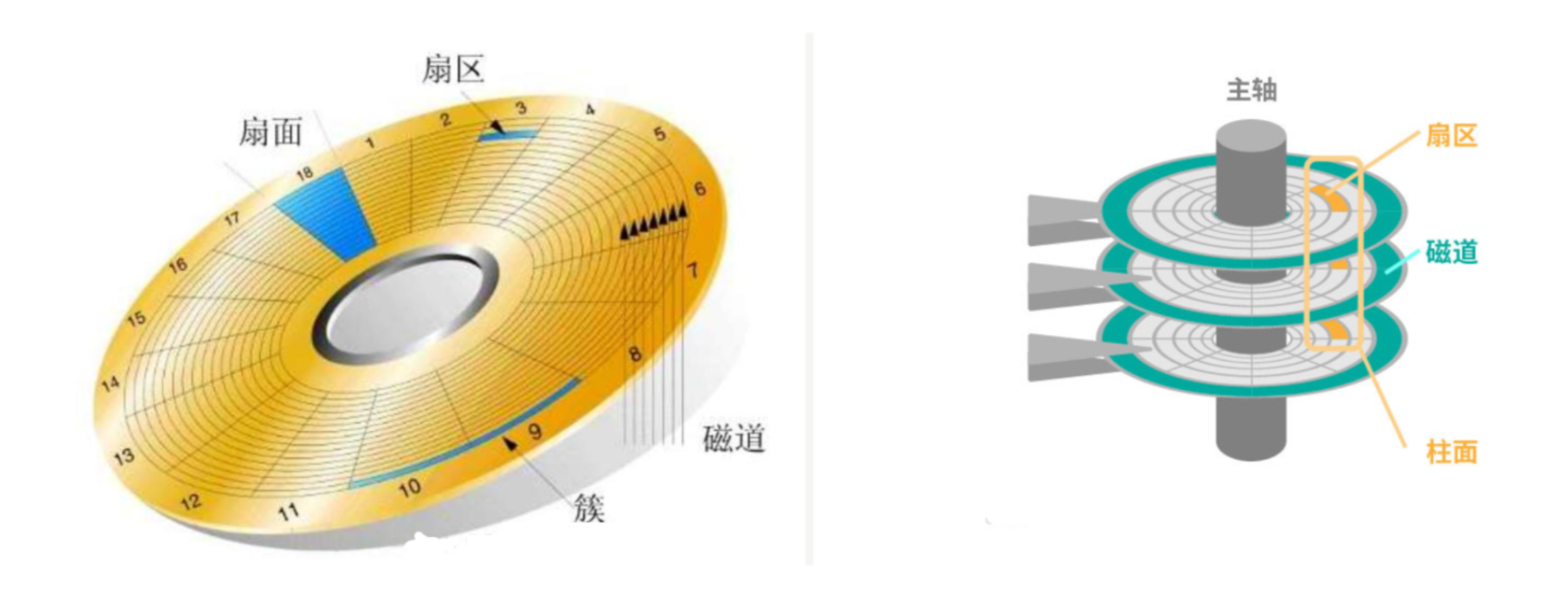
磁盘寻址的基本单位是扇区(512byte)
定位扇区的方法: CHS定位法:
定位柱面 => 定位磁头(一个磁头对应一个盘面) => 定位扇区
(柱面:Cylinder 磁头:Head 扇区:Sector)
1.选择柱面:将磁头移动到指定的柱面(磁道)。
2.选择磁头:选择对应的磁头,即选择哪个盘面的数据。
3.选择扇区:通过磁盘的旋转找到指定磁道上的目标扇区。
3)磁盘的逻辑结构
a.概念
磁盘物理上是圆形的,逻辑上看作一个线性数组。所以,管理磁盘就是管理数组
数组的最小单位是扇区(512byte),一般来说,扇区在每一个盘面和磁道上的数量相同,所存的数据量也相同
扇区对应的 数组下标 就是 LBA地址(Logical Block Addressing)
如图(数据虚构):
b.将 LBA逻辑地址 转化为 CHS物理地址:
根据一个扇区的逻辑下标n,可以做出以下计算:
n / 一个盘面的扇区数 算出 位于第几个盘面;
n % 一个盘面的扇区数 算出 目标位于单盘上的位置(临时数据,记作temp);
temp / 一个磁道的扇区数 算出 位于第几个磁道(柱面);
temp % 一个磁道的扇区数 算出 位于第几个扇区。
举例(数据虚构):

c.为什么操作系统要逻辑抽象用LBA地址,不直接用CHS地址呢?
便于管理;不让OS的代码和硬件强耦合
4)磁盘的读取/修改
磁盘访问的基本单位是扇区(512byte),但是磁盘如果一次只读取/修改一个扇区,数据量就太小了,效率低。
所以,操作系统 读取/修改 一次磁盘的基本单位一般是4KB(8个扇区)。也就是说,即使只读取/修改1bit的数据,也要将4KB大小的磁盘数据加载到内存中,再进行读取/修改
所以,内存被分成多个4KB大小的空间(页框);磁盘中的文件尤其是可执行文件被划分成多个4KB大小的块(页帧),方便分块加载到内存中
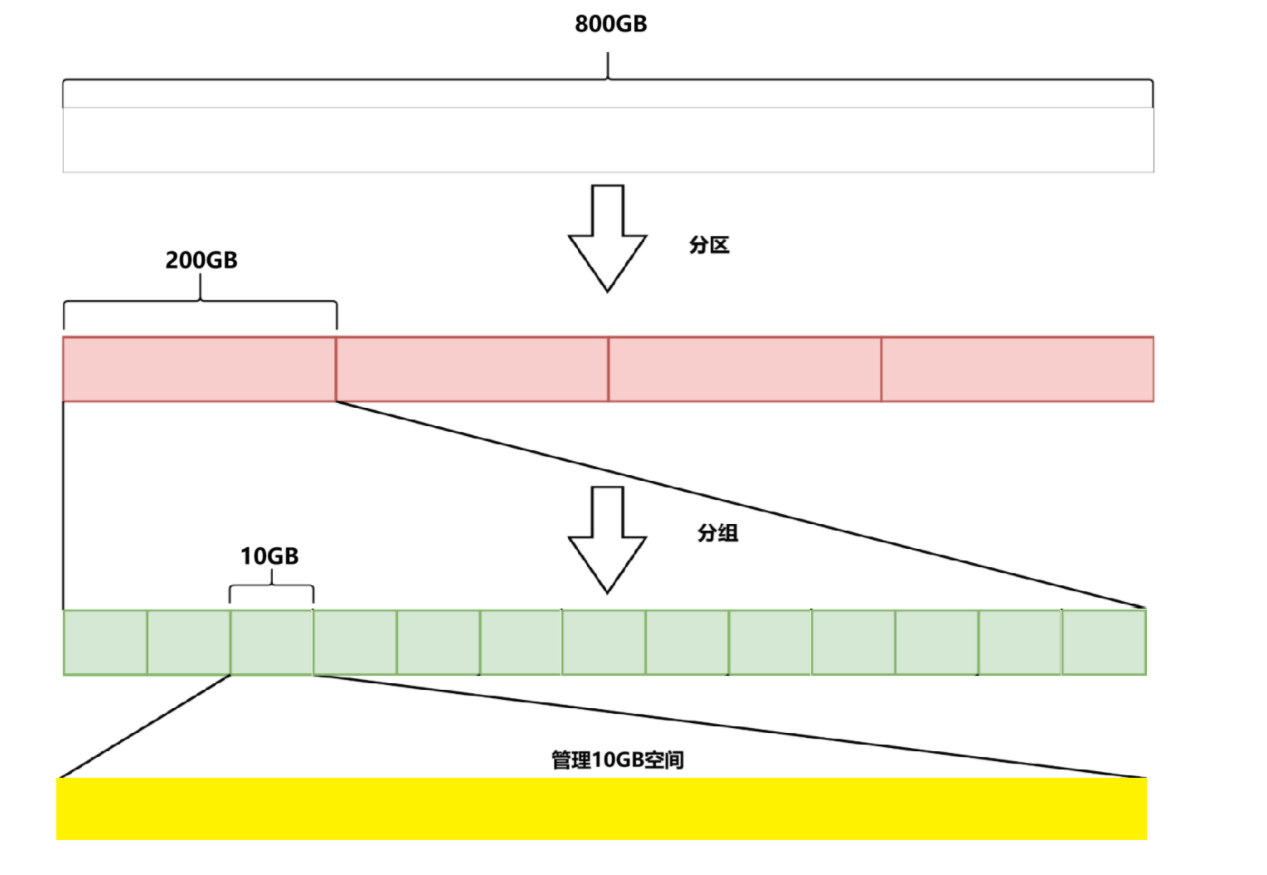
2.磁盘的管理
分治思想:将一个大空间拆成若干个小空间,对小空间的进行管理;再把小空间的管理模式应用到其他空间。
如图(数据虚构):
磁盘文件系统图(数据虚构):
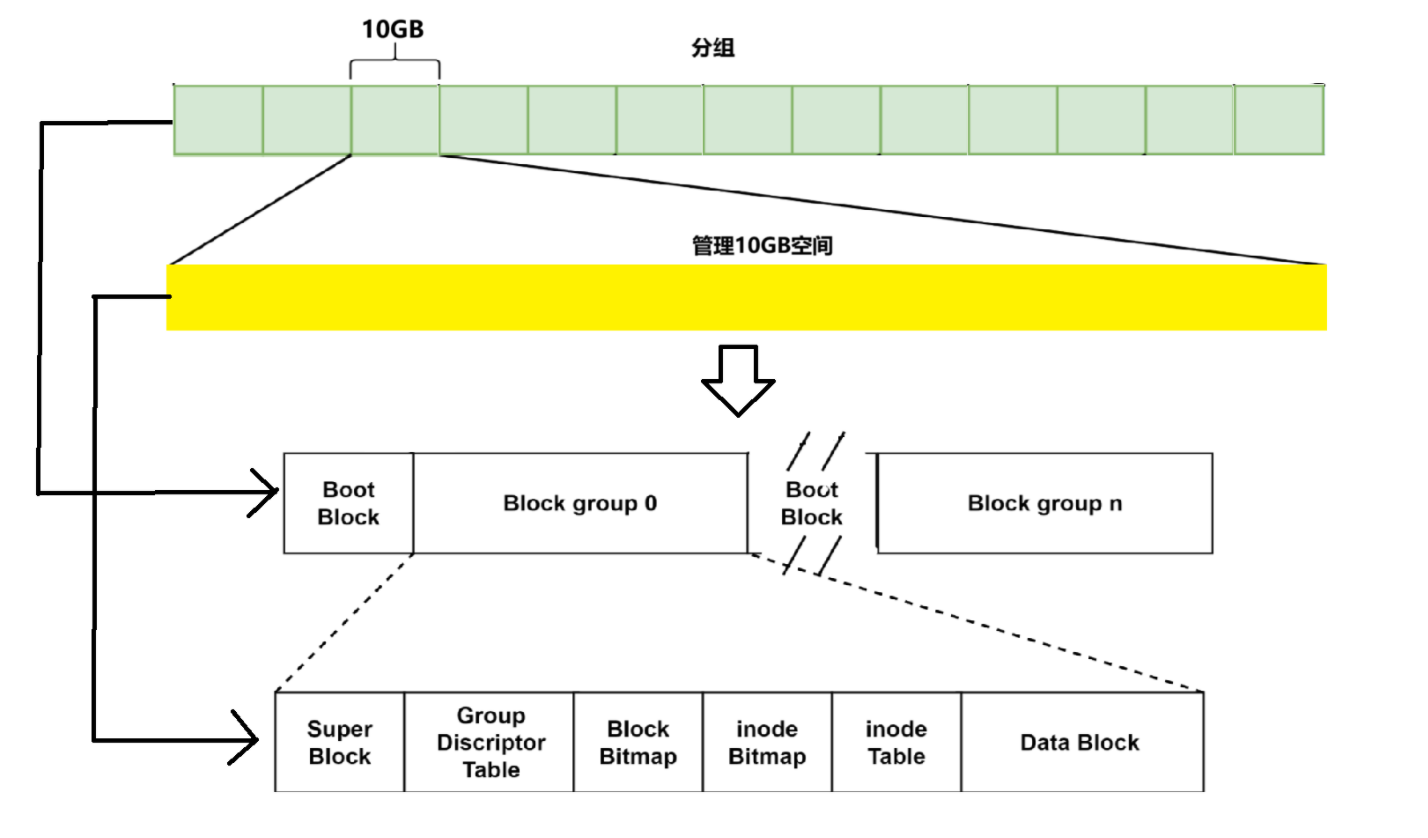
Boot Block:存储 分区表、操作系统等 开机就加载的文件
Super Block(超级块):存放文件系统本身(对应分区)的结构信息
记录的信息主要有:bolck 和 inode 的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。通常在一个分区内多个分组共有一个超级块,假设一个100G的分区中有1000个分组,每20个分组共有一个super block,那么总共就有50个超级块。
为什么需要这些超级块呢?是为了数据备份,如果某个块组或者inode丢失,那么就可以通过super block来进行恢复。
文件=内容+属性,Linux下的内容和属性是分开存储的。
- 文件属性存储在Inode中,Inode大小固定,一个文件对应一个Inode。一个文件的所有属性几乎都存储在Inode中,但是文件名并不存储在Inode中。
- 文件的内容存储在data block数据块中,数据块随着应用类型的变化,大小也会发生变化
Inode:
Inode是一个结构体,大小一般为128字节
Inode在内核中的大致结构:
struct inode
{类型大小时间....
}Inode在内核中的实际结构:
struct inode {umode_t i_mode;//文件的访问权限(eg:rwxrwxrwx)unsigned short i_opflags;kuid_t i_uid;//inode拥有者idkgid_t i_gid;//inode拥有者组idunsigned int i_flags;//inode标志,可以是S_SYNC,S_NOATIME,S_DIRSYNC等#ifdef CONFIG_FS_POSIX_ACLstruct posix_acl *i_acl;struct posix_acl *i_default_acl;
#endifconst struct inode_operations *i_op;//inode操作struct super_block *i_sb;//所属的超级快/*address_space并不代表某个地址空间,而是用于描述页高速缓存中的页面的一个文件对应一个address_space,一个address_space与一个偏移量能够确定一个一个也高速缓存中的页面。i_mapping通常指向i_data,不过两者是有区别的,i_mapping表示应该向谁请求页面,i_data表示被改inode读写的页面。*/struct address_space *i_mapping;#ifdef CONFIG_SECURITYvoid *i_security;
#endif/* Stat data, not accessed from path walking */unsigned long i_ino;//inode号/** Filesystems may only read i_nlink directly. They shall use the* following functions for modification:** (set|clear|inc|drop)_nlink* inode_(inc|dec)_link_count*/union {const unsigned int i_nlink;//硬链接个数unsigned int __i_nlink;};dev_t i_rdev;//如果inode代表设备,i_rdev表示该设备的设备号loff_t i_size;//文件大小struct timespec i_atime;//最近一次访问文件的时间struct timespec i_mtime;//最近一次修改文件的时间struct timespec i_ctime;//最近一次修改inode的时间spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */unsigned short i_bytes;//文件中位于最后一个块的字节数unsigned int i_blkbits;//以bit为单位的块的大小blkcnt_t i_blocks;//文件使用块的数目#ifdef __NEED_I_SIZE_ORDEREDseqcount_t i_size_seqcount;//对i_size进行串行计数
#endif/* Misc */unsigned long i_state;//inode状态,可以是I_NEW,I_LOCK,I_FREEING等struct mutex i_mutex;//保护inode的互斥锁//inode第一次为脏的时间 以jiffies为单位unsigned long dirtied_when; /* jiffies of first dirtying */struct hlist_node i_hash;//散列表struct list_head i_wb_list; /* backing dev IO list */struct list_head i_lru; /* inode LRU list */struct list_head i_sb_list;//超级块链表union {struct hlist_head i_dentry;//所有引用该inode的目录项形成的链表struct rcu_head i_rcu;};u64 i_version;//版本号 inode每次修改后递增atomic_t i_count;//引用计数atomic_t i_dio_count;atomic_t i_writecount;//记录有多少个进程以可写的方式打开此文件const struct file_operations *i_fop; /* former ->i_op->default_file_ops */struct file_lock *i_flock;//文件锁链表struct address_space i_data;
#ifdef CONFIG_QUOTAstruct dquot *i_dquot[MAXQUOTAS];//inode磁盘限额
#endif/*公用同一个驱动的设备形成链表,比如字符设备,在open时,会根据i_rdev字段查找相应的驱动程序,并使i_cdev字段指向找到的cdev,然后inode添加到struct cdev中的list字段形成的链表中*/struct list_head i_devices;,union {struct pipe_inode_info *i_pipe;//如果文件是一个管道则使用i_pipestruct block_device *i_bdev;//如果文件是一个块设备则使用i_bdevstruct cdev *i_cdev;//如果文件是一个字符设备这使用i_cdev};__u32 i_generation;#ifdef CONFIG_FSNOTIFY//目录通知事件掩码__u32 i_fsnotify_mask; /* all events this inode cares about */struct hlist_head i_fsnotify_marks;
#endif#ifdef CONFIG_IMAatomic_t i_readcount; /* struct files open RO */
#endif//存储文件系统或者设备的私有信息void *i_private; /* fs or device private pointer */
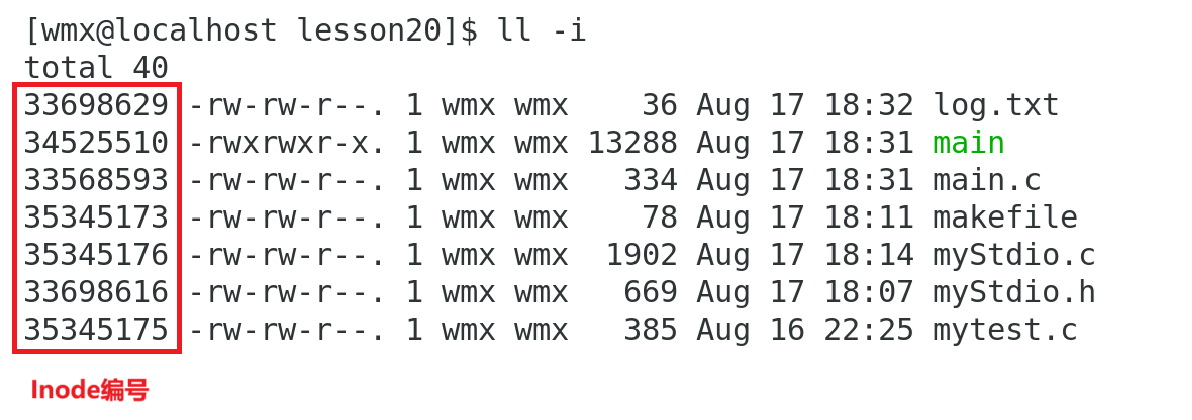
};Inode编号:
由于每个文件都有Inode,为了区分彼此,每个Inode都有自己的编号。编号是以每个分区为单位进行编的。
查看Inode编号:ll -i 命令
inode table:保存一个分组内部所有可用的(已经使用+没有使用)的inode。
Data blocks:保存分组内部所有文件的数据块(一个数据块大小为4KB)。
Inode Bitmap:
Inode对应的位图结构。用于查看每个inode的使用情况:0表示未使用;1表示已使用。
假设inode一共有n个,位图结构中的比特位的个数至少也为n个。位图中比特位的位置与当前文件的inode的ID是一一对应的。
block Bitmap:
数据块对应的位图结构。用于查看每个数据块的使用情况。位图中比特位的位置和当前data block对应的数据块的位置是一一对应的。
Group Descriptor Table:
包含对应分组的宏观属性信息,包括:一共有多少个数据块,使用了多少;一共有多少个Inode,使用了多少等等。
3.在磁盘中查看文件
通过 Inode编号 查找文件
查看文件属性:
- 通过 Inode Bitmap 查找对应的比特位的位置是1还是0
- 如果这个编号被占用,在Inode Table中找到对应Inode结构体,然后确定一下是否是我们要查找的文件。
查看文件内容:
查看文件内容就需要找到文件的数据块
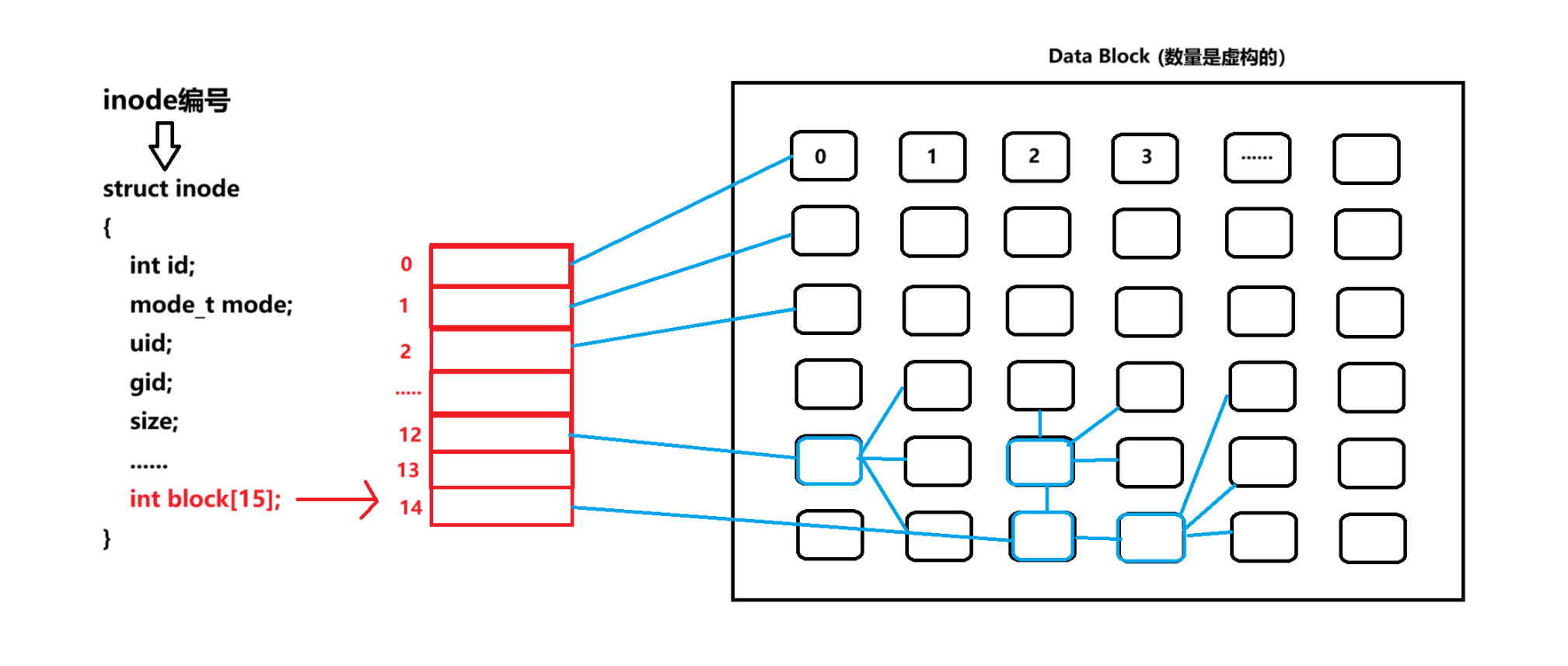
根据文件的 inode编号 找到对应的 inode结构体 ,inode结构体中有一个数组int block[15](数组元素的个数是固定的15)用于存放该文件数据块的编号,然后就能找到文件的数据块,查看文件内容
关于int block[15]数组:
虽然int block[15]数组只有15个元素,但并不代表文件仅可以使用15个数据块。
数组中元素所指向的数据块中的内容:
- [0, 11]:直接存放文件数据
- [12,13]:其他数据块编号,指向存放文件数据的数据块,是一种二级索引
- [14]: 其他数据块编号,而且其指向的数据块还是存着其他数据块编号,是三级索引
如此,就可以增加文件可使用数据块的个数。
如图:
4.在磁盘中删除文件
惰性删除:
将要删除文件的 Inode编号 在Inode Bitmap中对应的比特位由1置为0;将要删除文件的 所用数据块 在block bitmap中对应的比特位由1置为0。
这里并没有直接删除数据块,所以Linux下删除是可以恢复的。
5.文件名与Inode的关系
所有文件都在目录下,而目录的数据块中存放了当前目录下文件名与Inode编号的映射关系
所以,在查找文件的时候,只需要文件名,操作系统就会自动访问目录的数据块,找到对应的Inode编号,进行查找
四、软链接和硬链接
1.软链接
1)软链接的概念
软链接(Symbolic Link)也称为 符号链接 ,类似于 Windows 系统中的快捷方式。它是一个独立的文件,其内容是指向目标文件或目录的路径。通过软链接,我们可以在不同的位置访问同一个文件或目录,而无需复制文件。
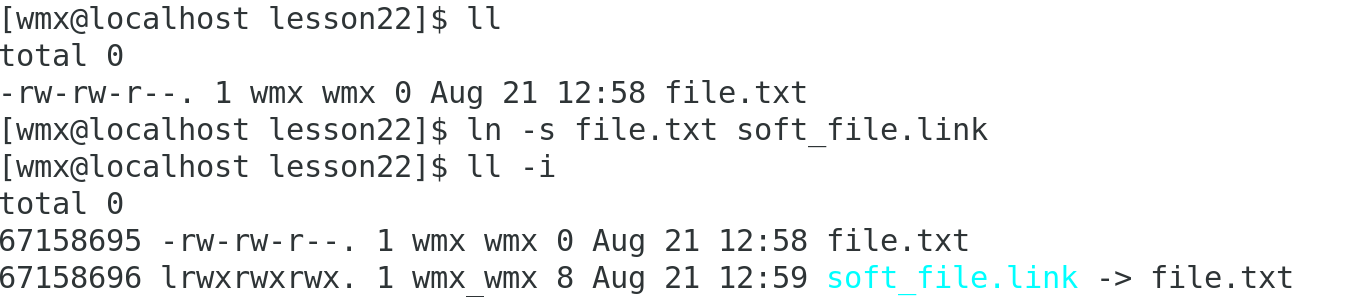
2)创建软链接
ln(link) -s 命令:其中 -s 表示创建符号链接
ln -s <目标文件或目录> <软链接名称>
举例:
3)软链接的特性
- 独立性:软链接是一个独立的文件,具有自己的 inode 编号。
- 路径依赖:软链接依赖于目标文件的路径。如果目标文件被移动或删除,软链接将失效。
举例:
删除目标文件后,软链接将失效。
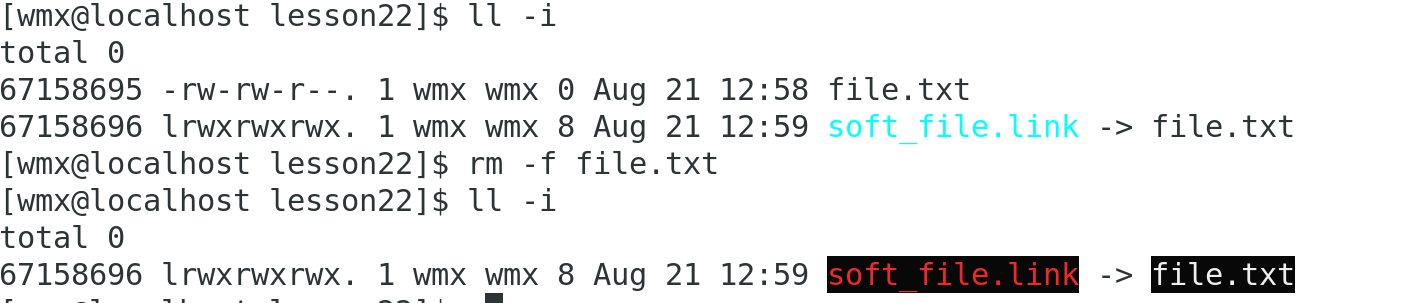
可以看到,file_soft.link 仍然存在,但它已经失效,因为目标文件 file.txt 被删除了。
4)软链接的用途
- 路径重定向:将文件或目录的访问路径重定向到另一个位置。
- 简化路径:通过软链接简化复杂路径,方便访问。
- 文件共享:在不同目录中共享同一个文件。
2.硬链接
1)硬链接的概念
硬链接(Hard Link)是指多个文件名指向同一个 inode(索引节点)。硬链接不是独立的文件,它与目标文件共享同一个 inode,因此它们实际上是同一个文件的不同入口。
硬链接实际上就是增加了 文件名与Inode编号的映射关系
2)创建硬链接
ln 命令:
ln <目标文件> <硬链接名称>
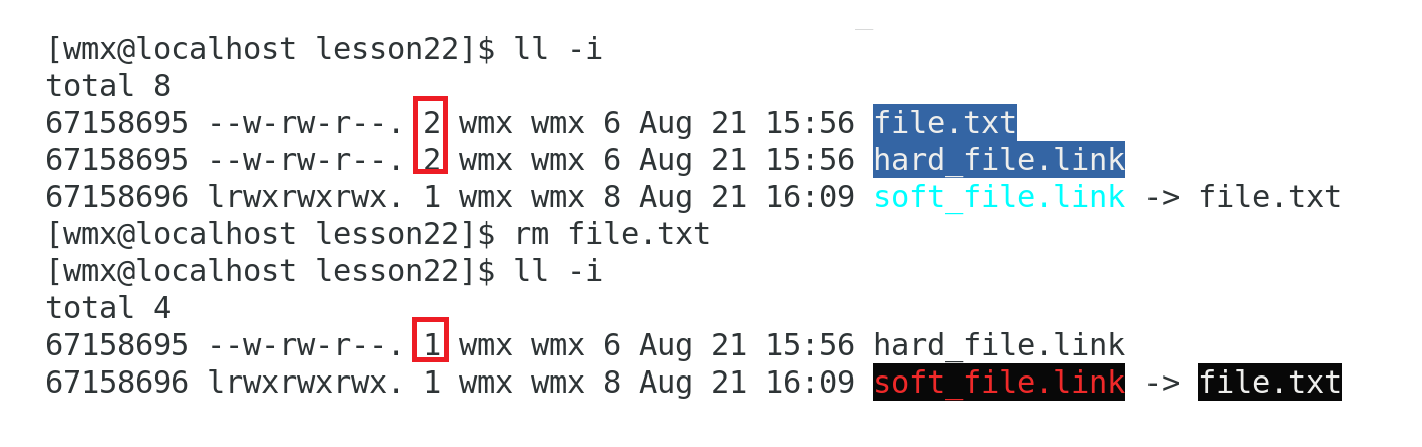
举例:

从输出中可以看到,file_hard.link 和 file.txt 的硬链接数都是 2,这表明它们共享同一个 inode。
3)硬链接的特性
- 共享 inode:硬链接与目标文件共享同一个 inode,因此它们实际上是同一个文件。
- 路径独立:硬链接不依赖于目标文件的路径,即使目标文件被重命名或移动,硬链接仍然有效。
- 删除行为:删除一个硬链接不会影响其他硬链接或目标文件,只有当所有硬链接都被删除时,文件才会被真正删除。
举例:
删除一个硬链接,目标文件仍然存在。
通过Inode中的引用计数实现
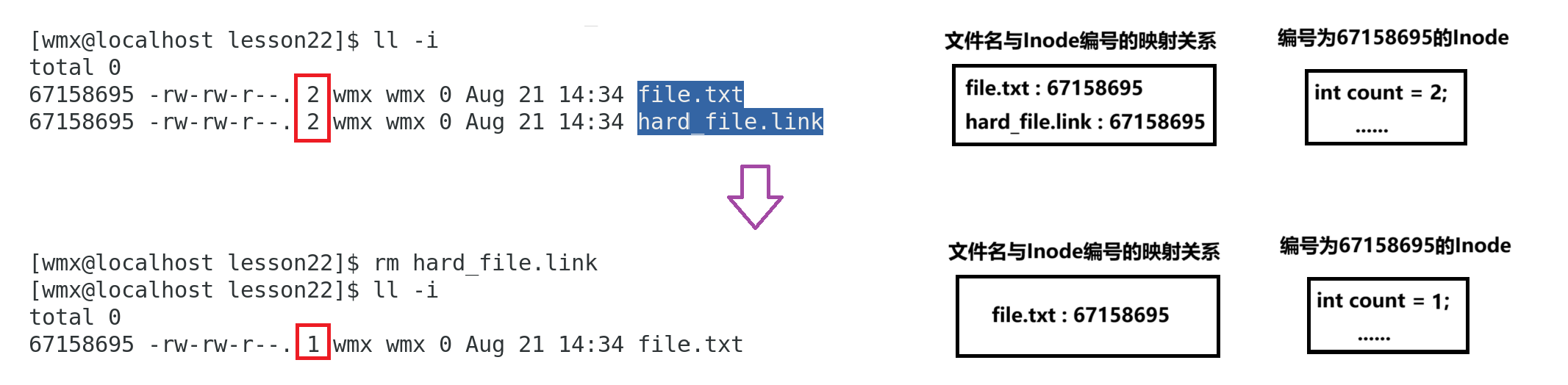
可以看到,file.txt 仍然存在,只是硬链接数减少到 1。
4)硬链接的用途
- 文件备份:通过硬链接创建文件的备份,节省磁盘空间。
- 文件共享:在不同目录中共享同一个文件。
- 系统文件管理:用于系统文件的冗余备份和管理
5)目录硬链接的特殊性
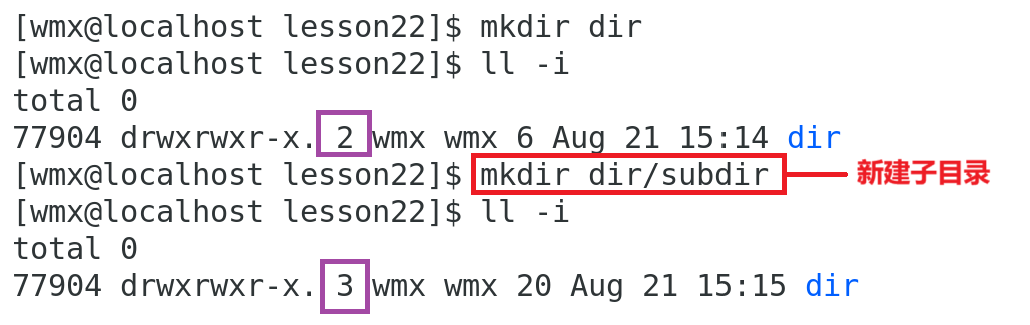
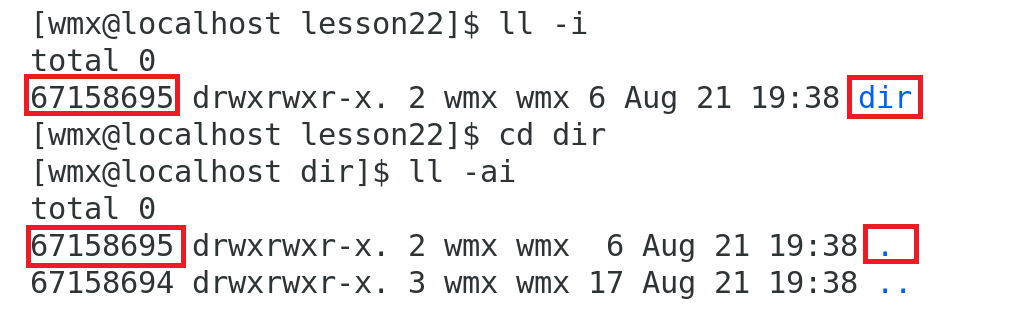
目录结构解析:
.代表当前目录..代表父目录- 当前目录的 . 会增加当前目录的硬链接数
- 每个子目录的
..都会增加父目录的硬链接数
系统限制 用户创建目录硬链接 的目的:
禁止用户创建目录硬链接是为了防止出现循环引用,避免文件系统陷入死循环
3.软链接与硬链接的区别
1)inode 编号
- 软链接:具有独立的 inode 编号。
- 硬链接:与目标文件共享同一个 inode 编号。

可以看到,file_soft.link 有独立的 inode 编号(67158696),而 file_hard.link 与 file.txt 共享同一个inode编号(67158695)
2)路径依赖
- 软链接:依赖于目标文件的路径,路径改变会导致软链接失效。
- 硬链接:不依赖于目标文件的路径,即使目标文件被重命名或移动,硬链接仍然有效。
举例:
移动目标文件后,软链接失效,硬链接仍然有效。

可以看到,file_soft.link 已经失效,而 file_hard.link 仍然有效。
3)删除行为
- 软链接:删除软链接不会影响目标文件。
- 硬链接:删除一个硬链接不会影响其他硬链接或目标文件,只有当所有硬链接都被删除时,文件才会被真正删除。
举例:
删除目标文件后,硬链接仍然有效。
五、文件的三个时间
当我们在linux中创建了文件或文件夹,文件/文件夹就有了时间属性,而且linux中的文件具有三个时间,
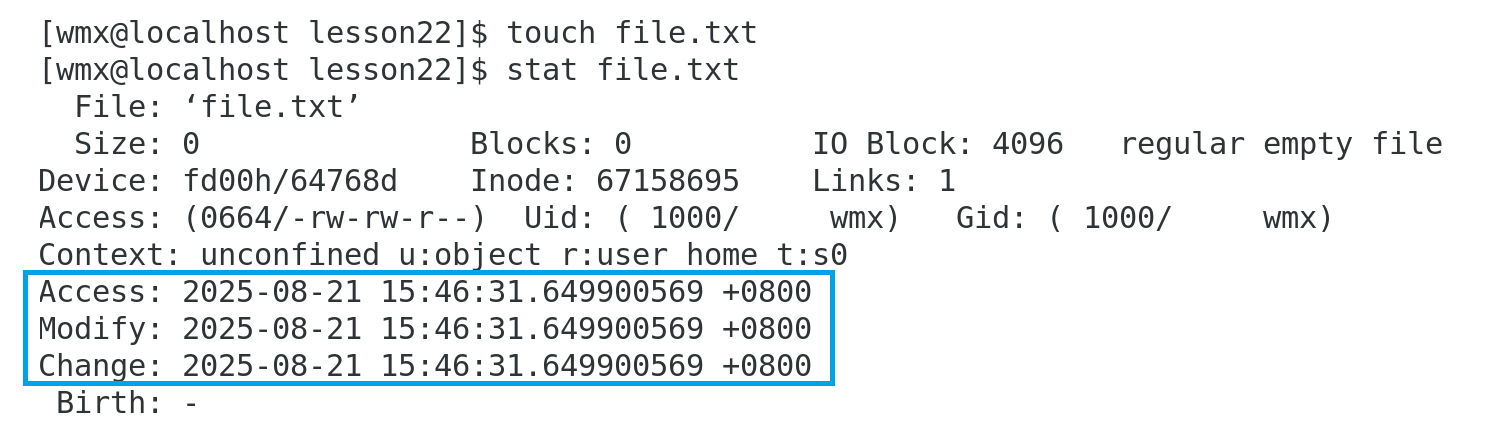
可以通过stat命令查看文件的三种时间:
- 访问时间(Access time):对文件进行一次读操作,它的访问时间就会改变。
- 修改时间(Modify time):文件内容最后一次修改的时间。
- 改变时间(Change time):文件属性最后一次被修改的时间。
1.Access time
文件的访问时间,但不是每次读文件后都会改变,而是读文件的次数积累到一定数量后才会改变。
这是因为读文件的次数在实际情况中较多,这样可以提高效率
2.Modify time
文件内容最后一次修改的时间
举例:
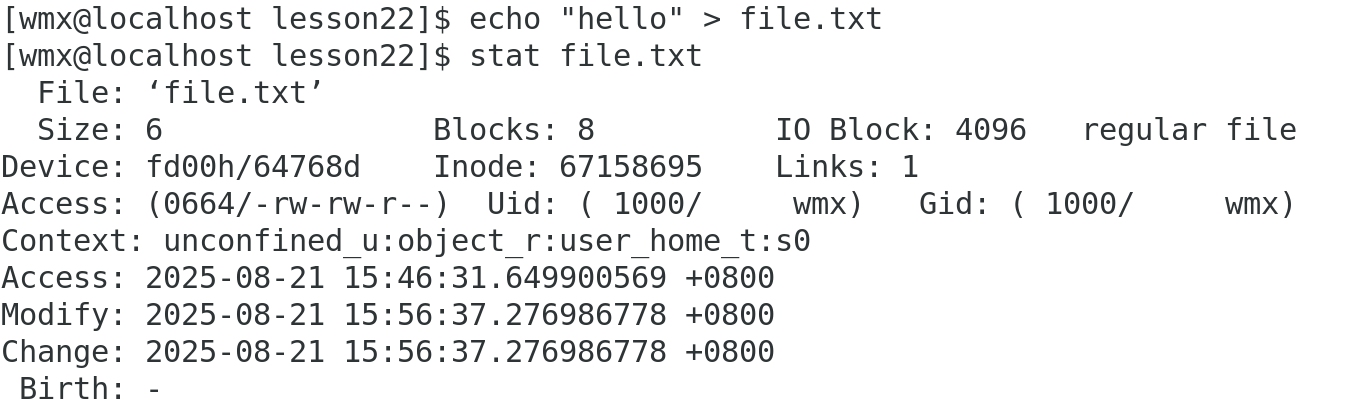
change time 也发生了变化,因为文件大小的改变也是文件属性的改变
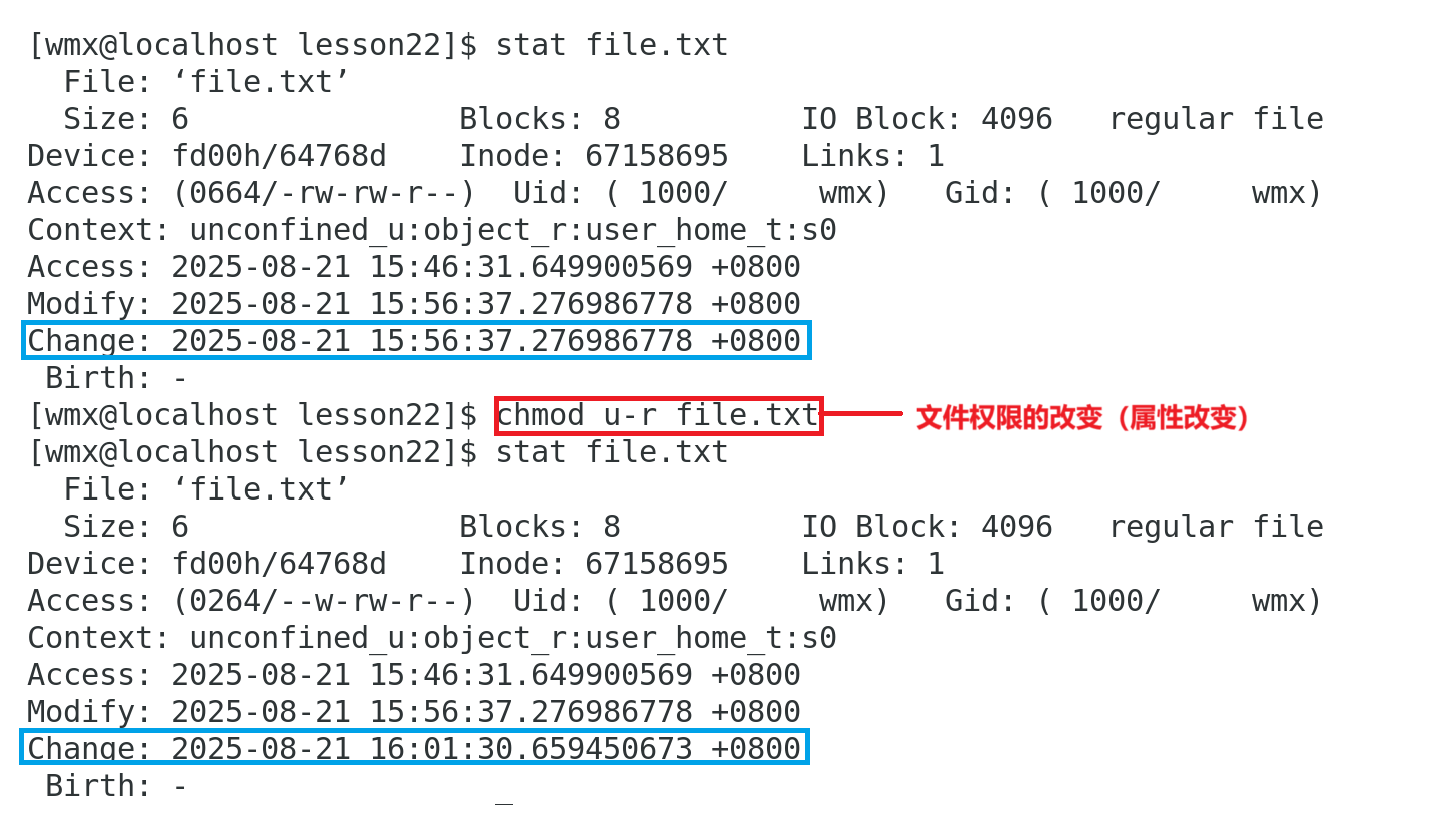
3.Change time
文件属性最后一次修改的时间
六、静态库与动态库
1.库的概念
- 静态库(.a):程序在编译链接的时候把库的代码拷贝到可执行文件中,运行的时候将不再需要静态库。
- 动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
命名规则:
去掉开头lib,去掉.so或者.a后的内容
例如:"llibc.so.6"=>"c"---C标准库
2.库的本质和意义
将含有函数实现方法的.c文件编译成.o文件(不包含主函数),打包后就形成了库。
使用时,将 库文件(函数实现)和头文件(函数目录) 提供给使用者,只需包含对应的头文件,并链接库中的.o文件即可。
这样就可以使用库函数的功能,提高效率。
3.库的制作和使用
举例:
my_add.h
#pragma once
#include <stdio.h>extern int Add(int a, int b);
my_add.c
#include "my_add.h"int Add(int a,int b)
{printf("enter Add func, %d + %d = ?\n", a, b);return a + b;
}my_sub.h
#pragma once
#include <stdio.h>extern int Sub(int a, int b);my_sub.c
#include "my_sub.h"int Sub(int a,int b)
{printf("enter Sub func, %d - %d = ?\n", a, b);return a - b;
}main.c
#include "my_add.h"
#include "my_sub.h"int main()
{int ret1 = Add(10,20);printf("result:%d\n",ret1);int ret2 = Sub(10,20);printf("result:%d\n",ret2);return 0;
}1)不使用库
情况一:直接形成可执行文件
gcc会自动将.c文件编译为.o文件,并进行链接
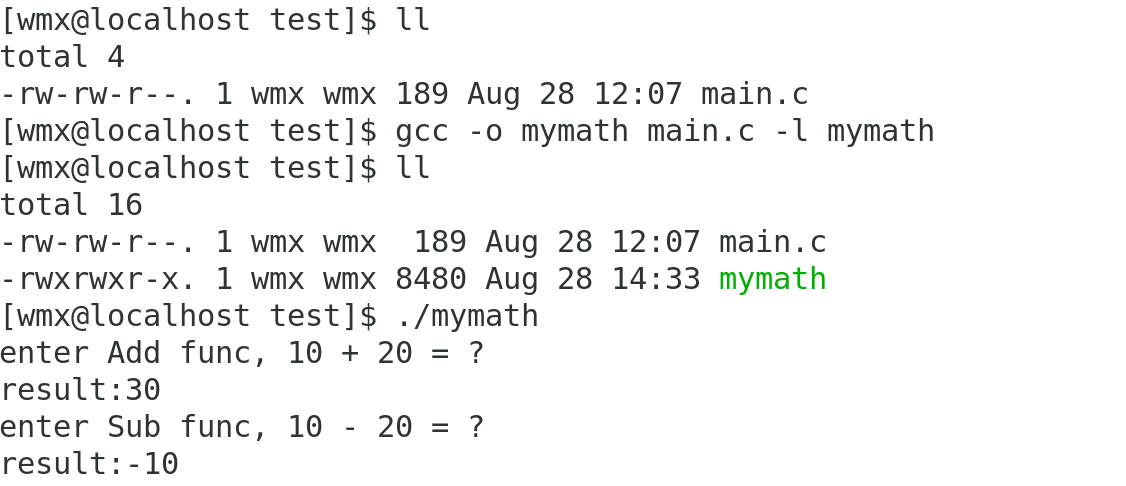
gcc -o mymath main.c my_add.c my_sub.c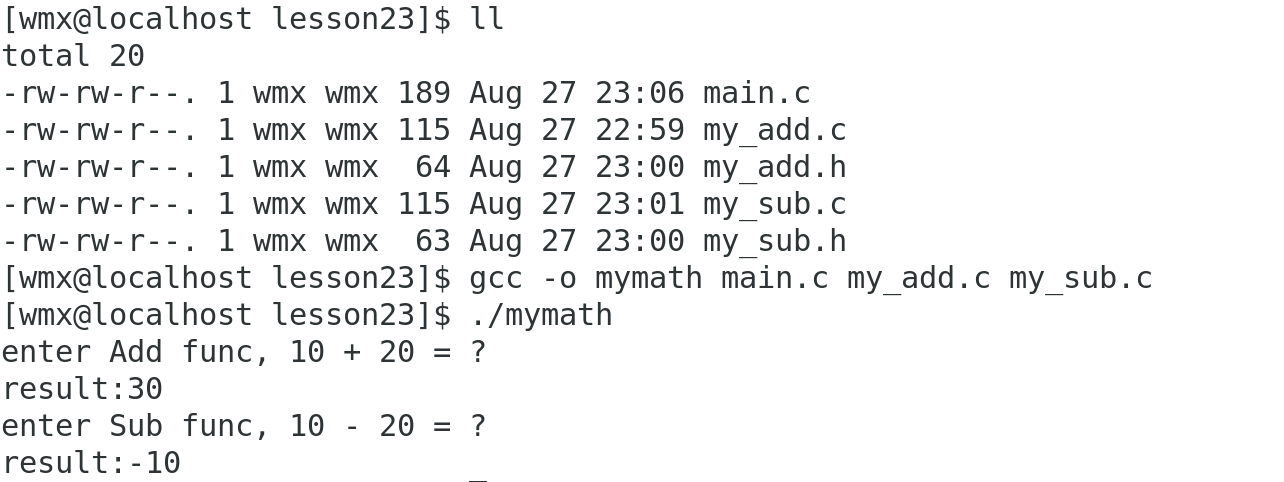
情况二:先编译形成.o文件,再进行链接形成可执行文件
与直接形成可执行文件相比,只是先手动将文件编译,并无本质区别,是为后面理解库做铺垫。
gcc -c main.c
gcc -c my_add.c
gcc -c my_sub.c
gcc -o mymath main.o my_add.o my_sub.o
2)静态库的制作和使用
a.制作静态库
(1)先将.c文件编译为.o文件(需要在当前目录下包含对应头文件)
gcc -c my_add.c
gcc -c my_sub.c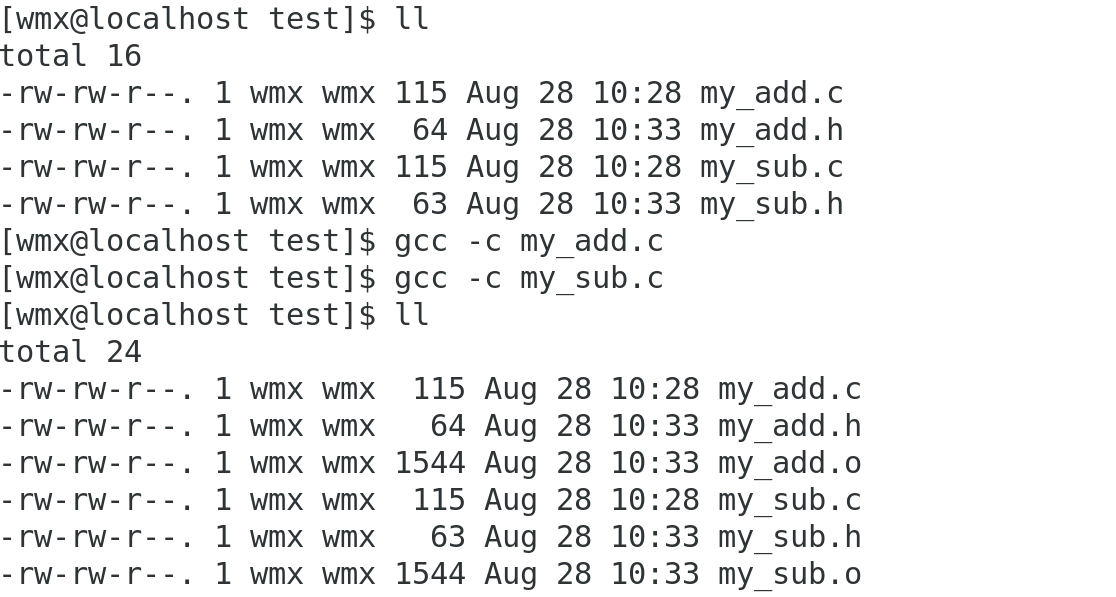
(2)将.o文件打包,形成库
ar -rc libmymath.a my_add.o my_sub.oar(archive)是gnu归档工具,rc(replace and create)表示替换或创建,.a表示生成的是静态库。
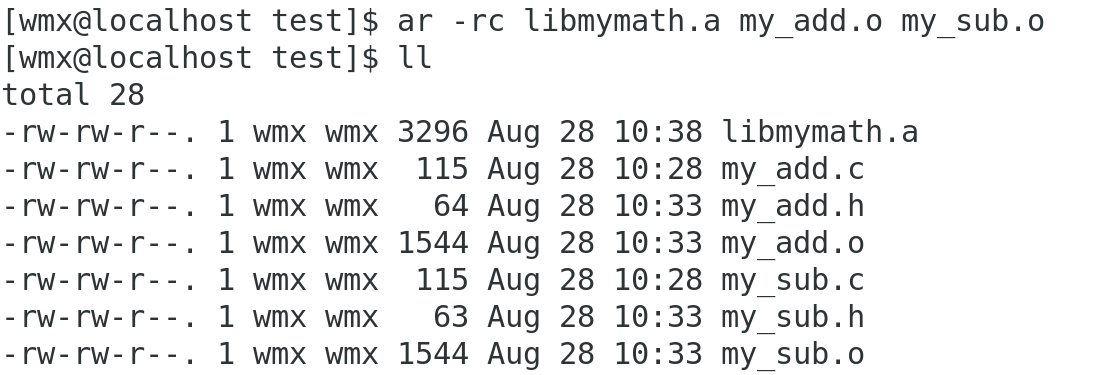
file命令:查出 libmymath.a 是归档文件

(3)整理库,准备交付
交付库本质就是提供 库文件(.a/.so)和匹配的头文件
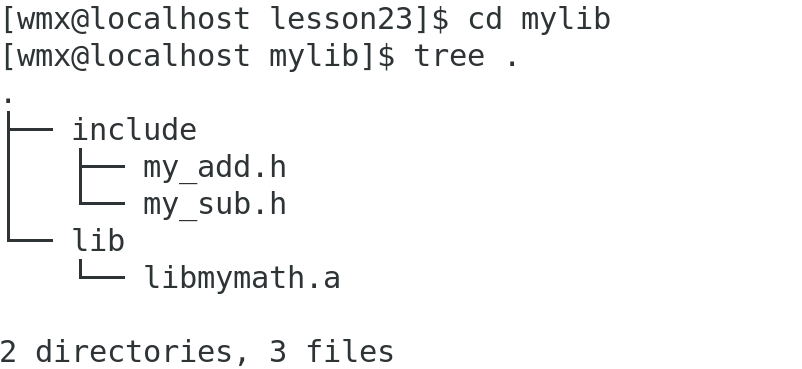
b.使用静态库
情况一:安装静态库到任意路径
(1)安装静态库到任意路径
安装本质就是拷贝
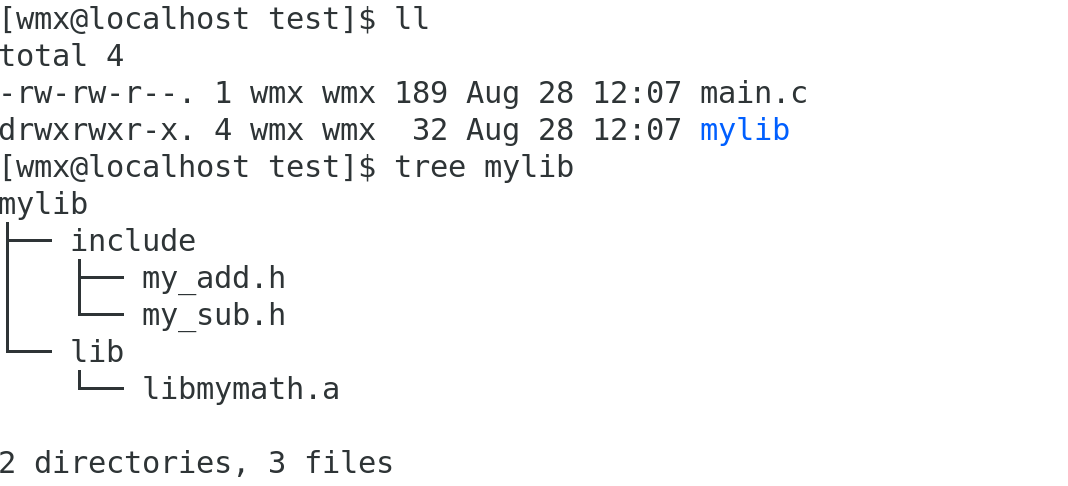
(2)编译链接形成可执行文件
gcc -o mymath main.c -I ./mylib/include -L ./mylib/lib -l mymath- -I 指定头文件所在路径
- -L 指定库的路径
- -l 指定库名称
- (使用这三个选项时,后面的空格可以省略)
要链接第三方库,必须指明库名称(库名称要去掉开头lib,去掉.so/.a)
1.为什么使用库需要指明库名称?
因为一个路径下可能有多个库
2.为什么使用头文件不需要指明名称?
在main.c中已经指明了要用到的头文件
3.为什么在平时形成可执行文件时,不需要指明库名称?
在使用gcc/g++工具时,只使用了C/C++的标准库,默认能够找到
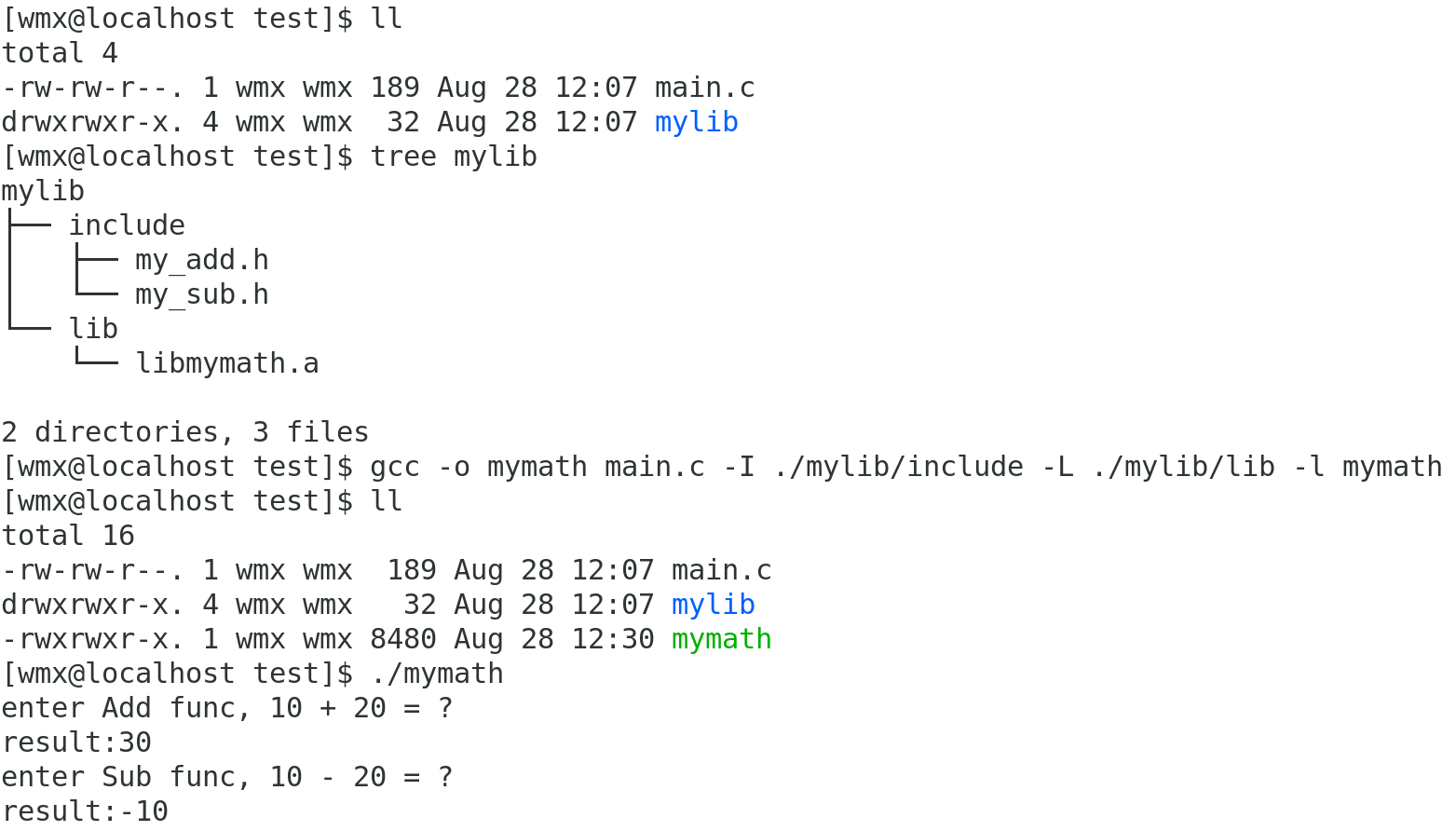
情况二:安装静态库到系统路径
(1)安装静态库到系统路径
- 将头文件安装到:/usr/include/
- 将库文件安装到:/lib64/

(2)编译链接形成可执行文件
gcc -o mymath main.c -l mymath由于头文件和库文件都在系统路径下,所以不用指明路径,但还是需要指明库名称
3)动态库的制作和使用
a.制作动态库
(1)先将.c文件编译为.o文件(需要在当前目录下包含对应头文件)
与静态库制作相比,形成.o文件多了-fPIC选项
fPIC(position independent code):产生位置无关码(后面原理时会讲解)
gcc -c -fPIC my_add.c
gcc -c -fPIC my_sub.c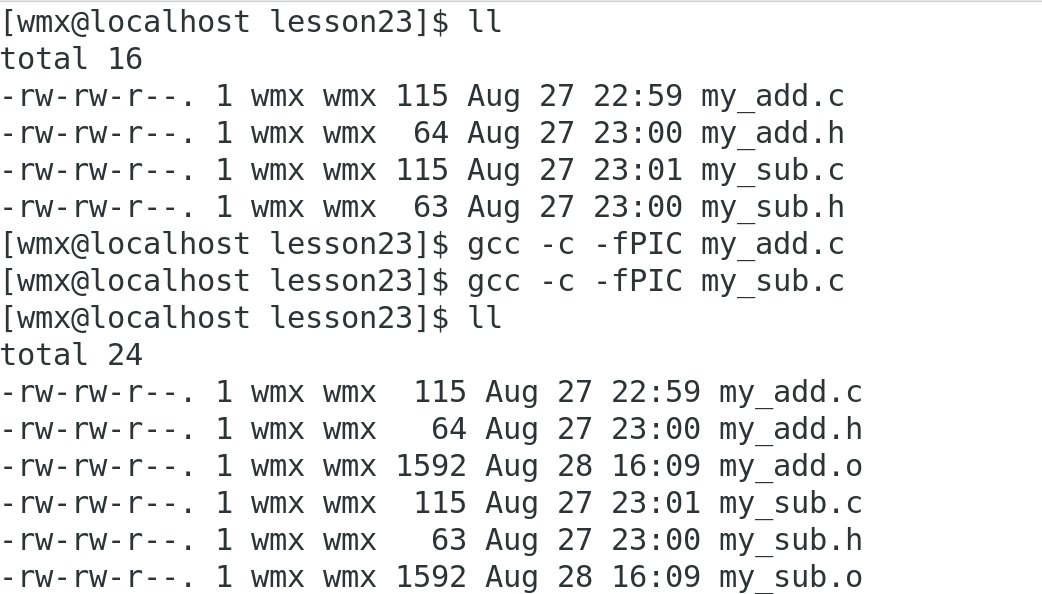
(2)将.o文件打包,形成库
与静态库制作相比,形成库文件时多了-shared选项
gcc -shared -o libmymath.so my_add.o my_sub.o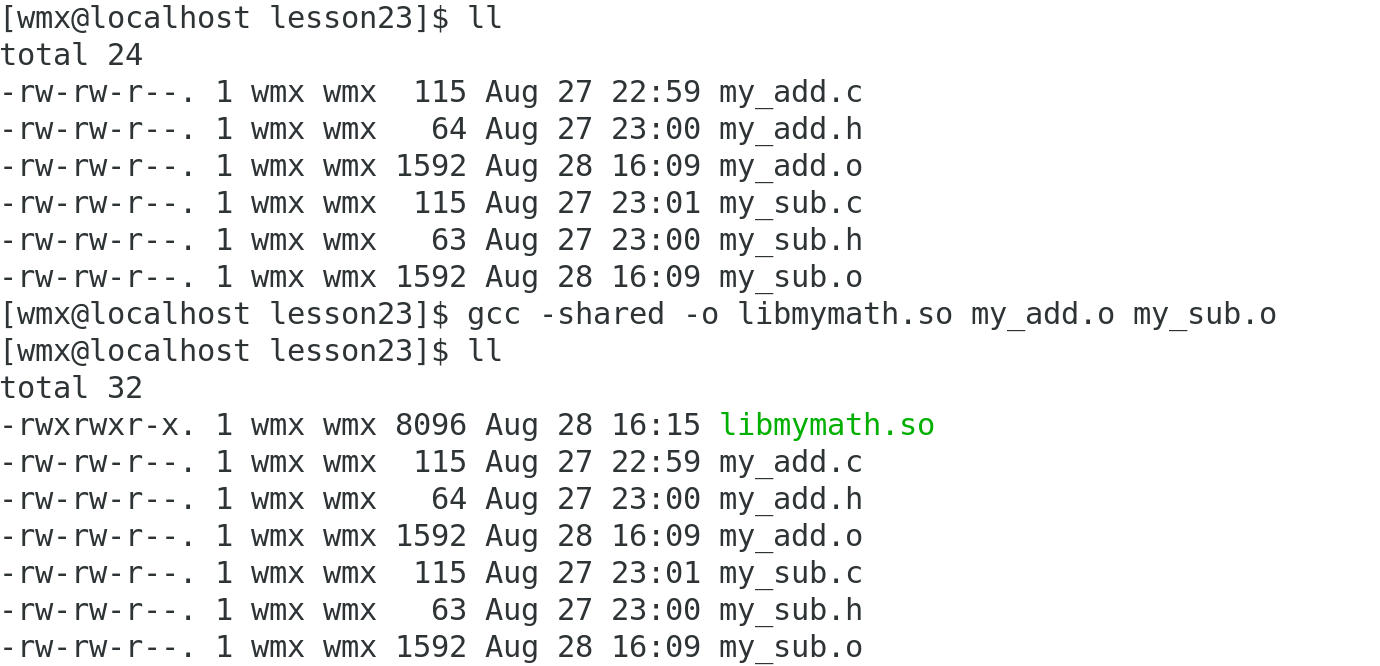

(3)整理库,准备交付

b.使用动态库
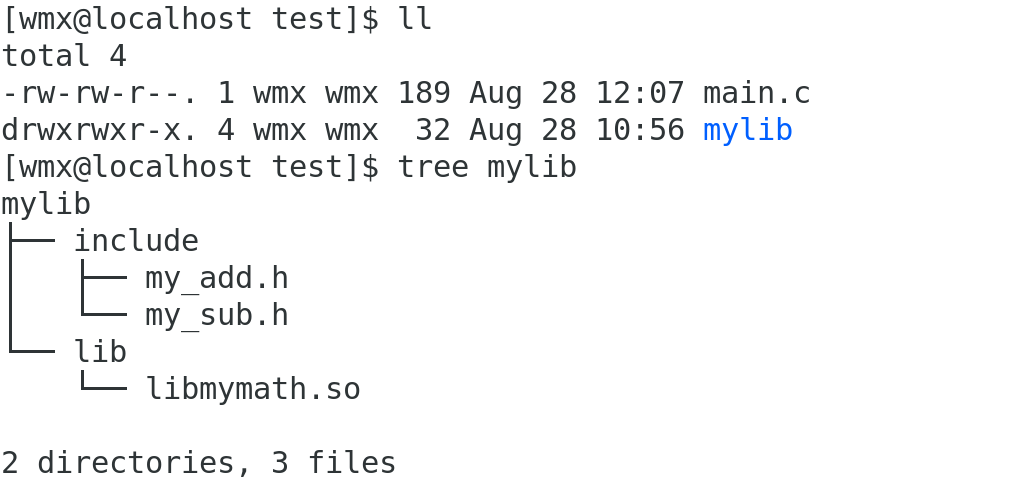
(1)安装动态库到任意路径
(2)编译链接形成可执行文件
形成可执行文件时,与静态库的使用相同
gcc -o mymath main.c -I ./mylib/include -L ./mylib/lib -l mymath
(3)执行可执行文件
与静态库使用不同的是:此时,可执行文件并不能直接运行,因为没有找到动态库

为什么在编译的时候已经指明了库文件的路径和名称,还是无法使用动态库呢?
因为编译时这些信息是告诉了gcc工具,而执行程序的OS并不知道库在哪里
方法一:直接安装动态库到系统路径(永久有效)
- 将头文件安装到:/usr/include/
- 将库文件安装到:/lib64/
使用时与静态库方法相同
方法二:配置环境变量LD_LIBRARY_PATH(临时有效)
程序运行寻找动态库时,OS除了在系统默认的路径下搜索,也会在环境变量 LD_LIBRARY_PATH 中搜索
缺点:每次重新登录,这个环境变量会被刷新,需要重新配置

添加动态库路径到 环境变量LD_LIBRARY_PATH 中
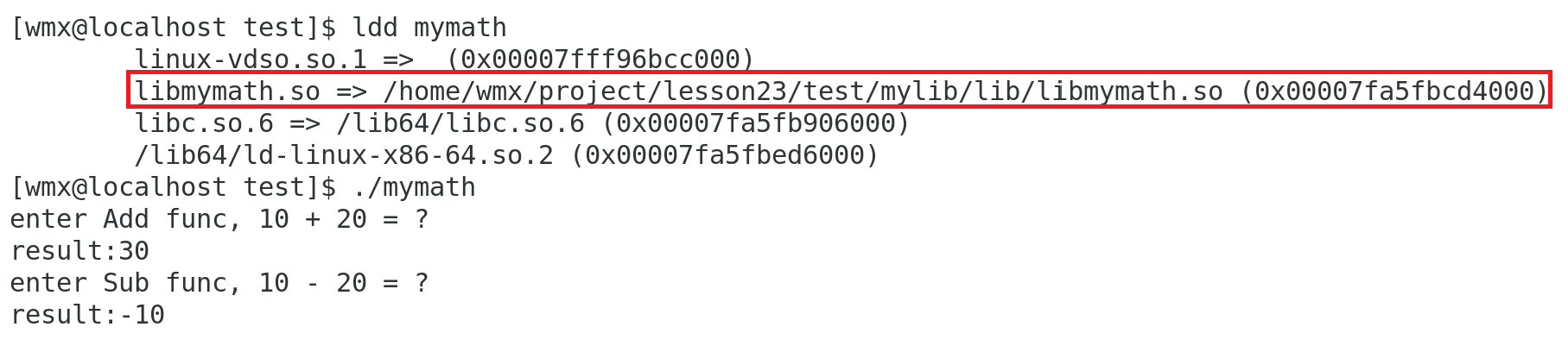
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/wmx/project/lesson23/test/mylib/lib
正常运行:
方法三:配置/etc/ld.so.conf.d/目录(永久有效)
1.在/etc/ld.so.conf.d/目录中创建.conf文件,将动态库的路径写入.conf文件
cd /etc/ld.so.conf.d #切换到对应目录
sudo touch lesson23.conf #创建.conf文件
sudo vim lesson23.conf #将动态库的路径写入
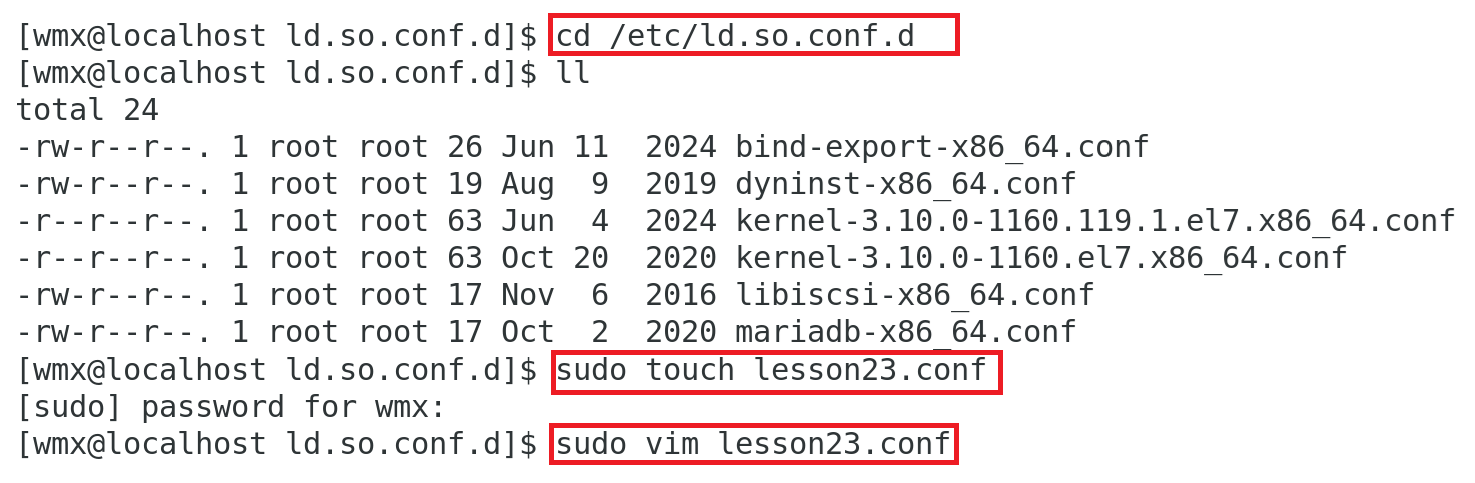

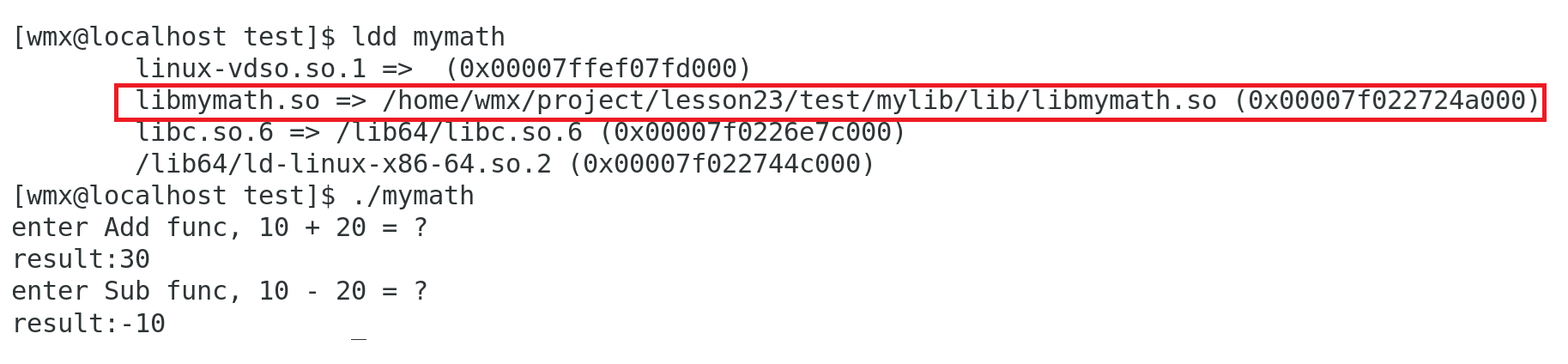
2.使用ldconfig命令更新
sudo ldconfig
执行程序
方法四:创建软连接
程序运行寻找动态库时,会在当前路径下和系统路径(/lib64/)下搜索。所以,可以在 当前路径下/系统路径(/lib64/) 创建软链接
//当前路径下
ln -s /home/wmx/project/lesson23/test/mylib/lib/libmymath.so libmymath.so
//系统路径下
sudo ln -s /home/wmx/project/lesson23/test/mylib/lib/libmymath.so /lib64/libmymath.so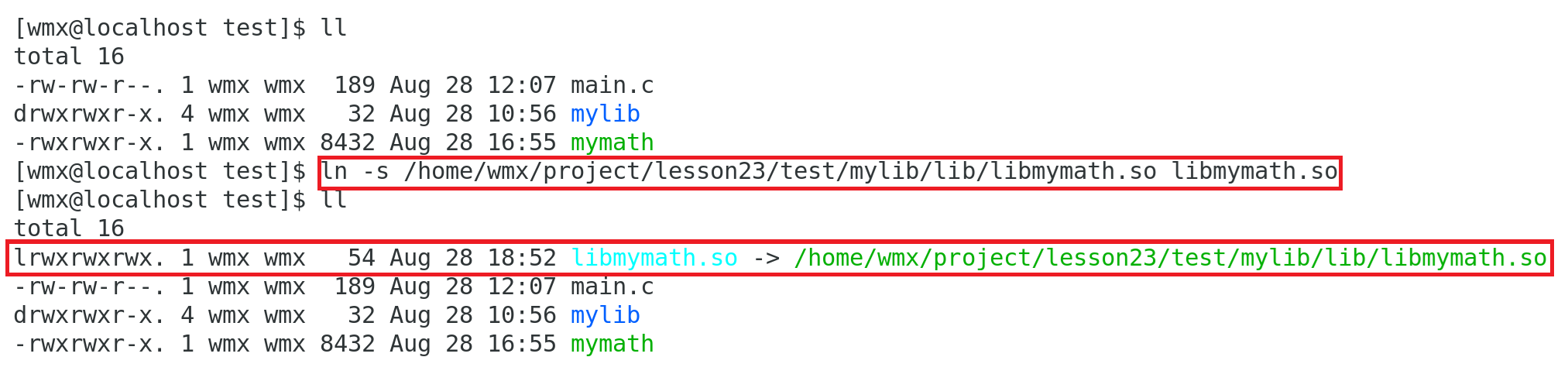
程序运行:
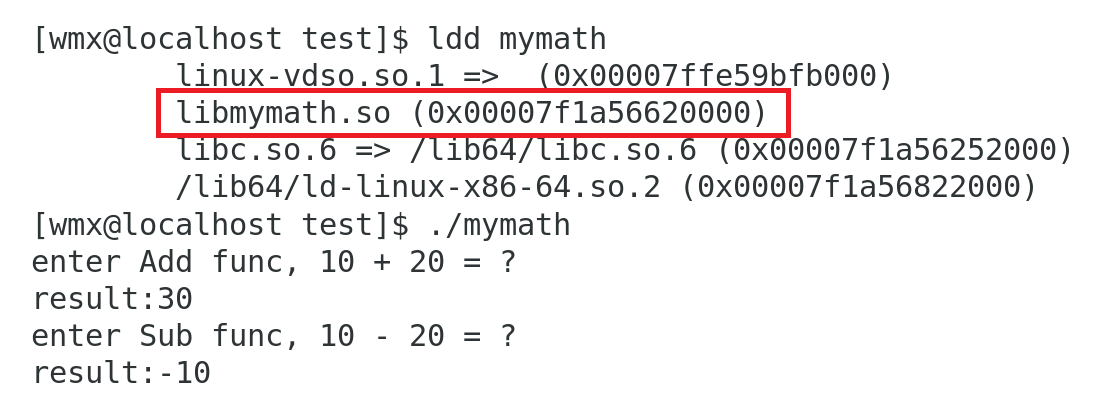
4)使用外部库
使用外部库时,OS会在系统路径下将头文件和库文件自动安装
4.静态链接与动态链接
对于一个特定的库,链接的类型取决于库的类型。
- 如果只有静态库,使用静态连接;
- 如果只有动态库,使用动态连接。
- 当同时有静态库和动态库时,gcc默认使用动态链接;使用 -static 选项,进行静态链接。
gcc -o test test.c
gcc -o test test.c -static对于一个可执行程序,只要有一个动态链接的库,那就是动态链接。
5.动态库的加载
在形成可执行程序时,静态库的二进制文件就已经拷贝到程序的代码区中。所以,在程序运行时,不需要加载静态库,只需要加载动态库。
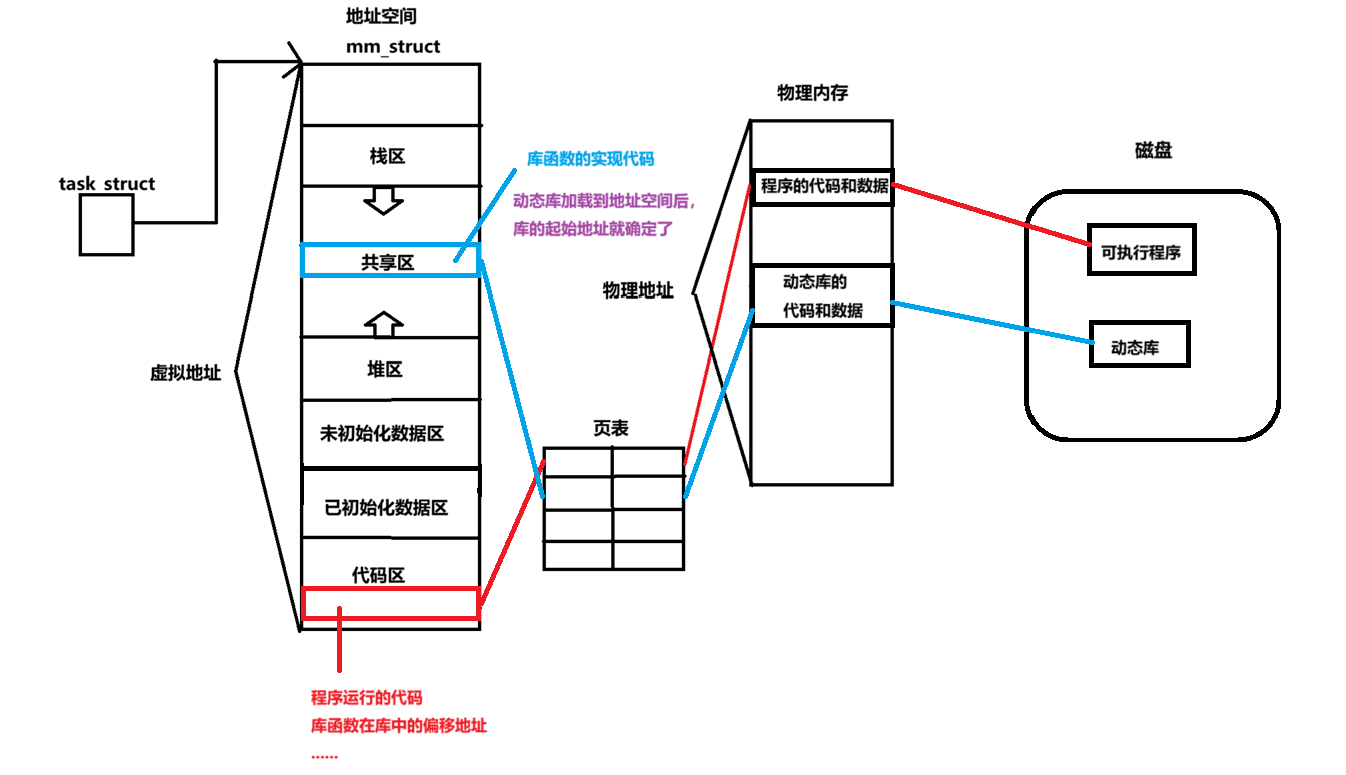
1)基地址(Base Address)和偏移地址(Offset Address)
虚拟地址:当程序编译后就会生成虚拟地址(函数地址,变量地址…),提供给CPU读取。CPU通过虚拟地址访问进程地址空间,然后通过页表映射,对物理内存进行访问。
- 基地址是具体的虚拟地址,是一个绝对地址
- 偏移地址是相对某个基地址的差值,是一个相对地址
2)编译后程序的函数虚拟地址
a.使用静态库时
当程序编译完成时,相应的静态库函数已经加载到代码中。此时, 库函数和自己实现的函数 的虚拟地址都是基地址。
b.使用动态库时
在形成.o文件时,使用了fPIC选项:产生位置无关码。所以,当程序编译完成时,会将动态库函数的偏移地址写入程序中。
这个偏移地址是函数代码在动态库中的偏移量。
3)动态库的加载
当程序运行到需要使用库函数时,会将动态库加载到物理内存中,再通过页表映射到进程地址空间的共享区中。此时,库的起始位置就确定了,再通过库函数的偏移地址,就可以找到函数实现的代码。
如图:
6.静态库和动态库的区别
1)静态库
- libxxx.a格式命名
- 在程序编译的时候,直接将静态库继承到可执行程序中,因此可执行程序比较大
- 程序在运行的时候占用内存大,存储的时候占用磁盘大
- 可执行程序,脱离静态库后不受影响
- 程序的更新部署比较麻烦
2) 动态库
- libxxx.so格式命名
- 可执行程序编译的时候,不会连接到动态库,而是在程序执行的时候,将动态库加载到内存中。内存中最多只有一份。
- 因此,可执行程序比较小
- 占用内存和磁盘比较小
- 可执行程序,脱离动态库后会崩溃
- 程序更新部署比较方便