CVPR深度学习研究指南:特征提取模块仍是论文创新难点
关注gongzhonghao【CVPR顶会精选】
在深度学习赛道里,别只盯着堆模型卷参数了。最近不少高分工作都在打“可解释”这张牌,把原本难以理解的黑箱模型用轻量方法剖开,既能增强学术价值,还能拓展落地场景。
更妙的是,这类研究门槛其实比想象中低,往往是将经典模型或分析方法迁移到视觉新领域,再结合任务痛点提出改进,就能快速产出有影响力的成果。对想在CVPR领域突围的同学来说,这是一个既实用又高产的方向。今天小图给大家精选3篇CVPR有深度学习方向的论文,供大家借鉴和参考。
论文一:Theory-Inspired Deep Multi-View Multi-Label Learning with Incomplete Views and Noisy Labels
方法:
文章首先利用信息瓶颈理论构建特征提取模块,通过优化互信息模型及其理论上限,实现对共享特征和特定特征的有效提取与区分;接着在噪声转换矩阵体积最小化网络中,利用几何属性进行噪声识别,通过循环一致性估计框架提升估计稳定性;最后,结合噪声数据中的真实语义信息和隐藏的标签相关性作为模型正则化,降低过拟合风险,从而完成整个模型的训练与优化。
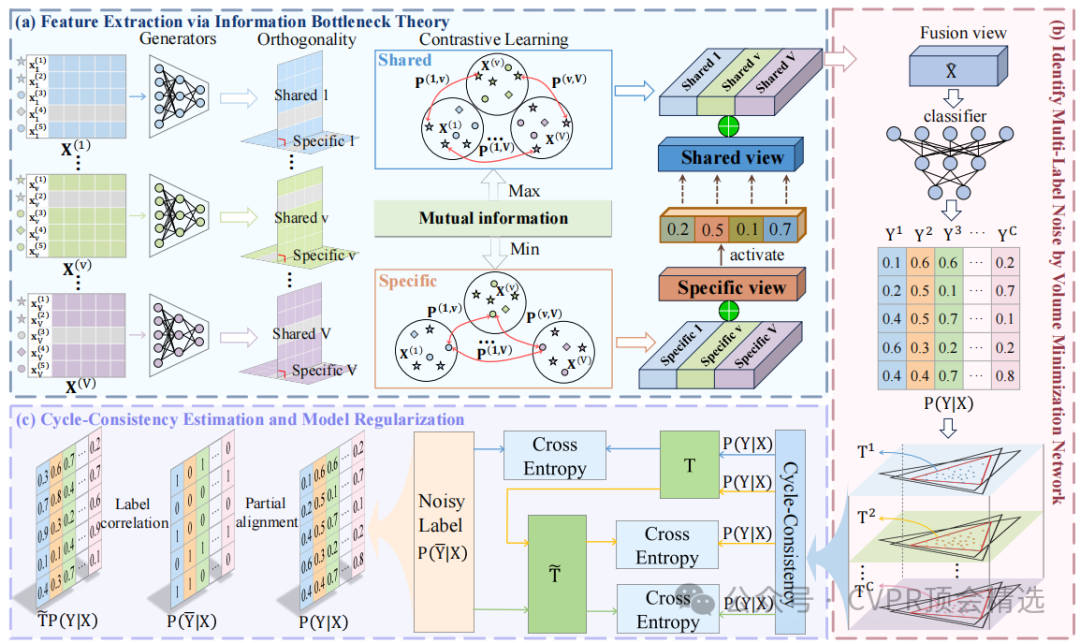
创新点:
这篇文章首次提出了一个能够同时处理视图缺失和标签噪声的多视图多标签学习框架,填补了这一领域的研究空白。
实验从有限视图中提取语义上具有区分性的表示,有效促进了任务相关共享信息的合成,同时保留了各个视图独特特征的独立性。
理论上证明了最小化噪声转换矩阵体积与分类器训练之间的统计一致性,并设计了循环一致性估计方法来增强转换矩阵估计,进一步提高了多标签噪声识别的稳定性。
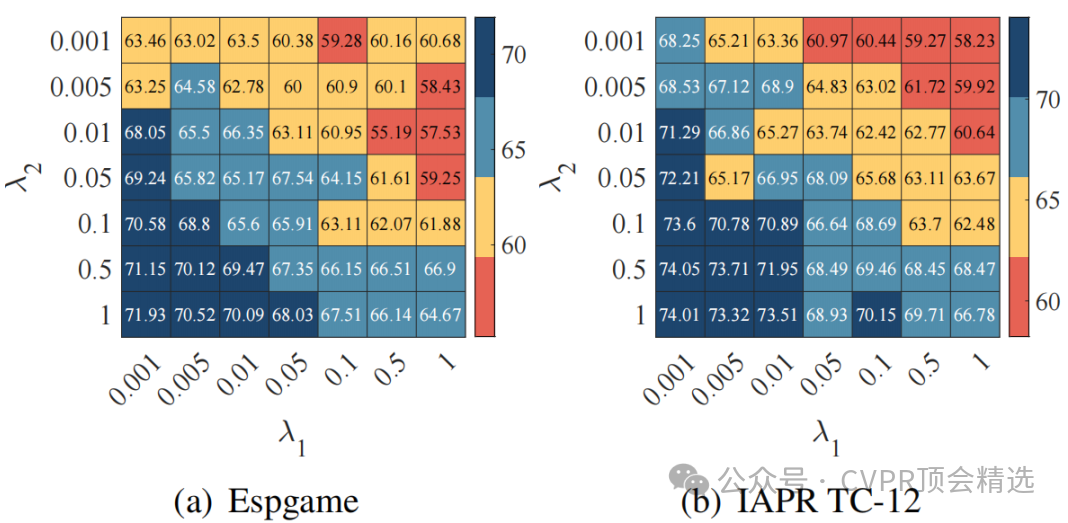
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/34682
图灵学术科研辅导
论文二:Potential Field Based Deep Metric Learning
方法:
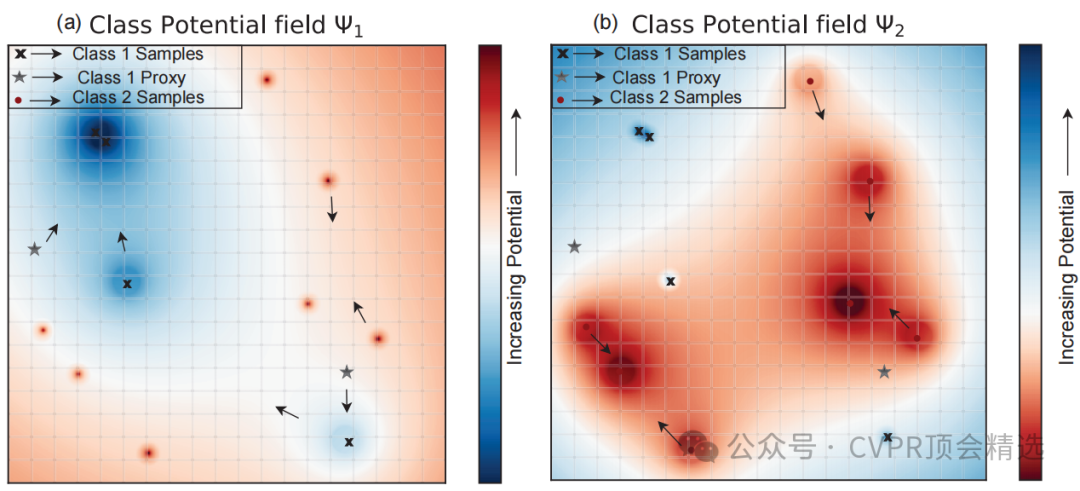
文章首先定义了每个样本产生的吸引场和排斥场,通过这些场的叠加形成全局势场,以此来建模样本间的相互作用。接着,利用梯度下降法训练网络,通过最小化所有样本和代理点在全局势场中的总势能来优化网络参数和代理点位置。最后,在三个标准的深度度量学习基准数据集上验证了该方法的有效性,结果表明其在标准无噪声场景以及更贴近现实的标签噪声场景下均优于现有的最先进方法。
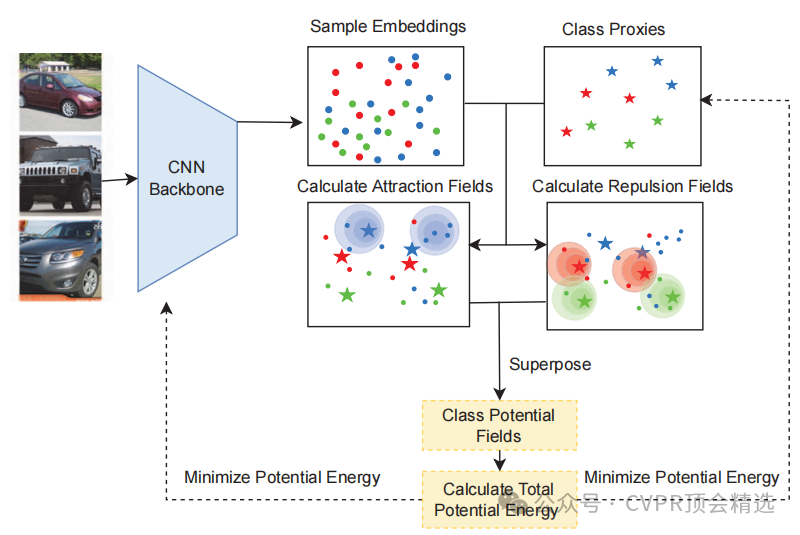
创新点:
提出了基于势场的深度度量学习框架,用连续势场代替传统的样本间直接交互,能够全面建模所有样本的相互作用。
逆转了样本间相互作用随距离增强的传统模型,显著提升了在真实世界数据集中面对标签噪声时的鲁棒性。
在三个标准的深度度量学习基准数据集上,在无噪声的标准场景下超越了现有最先进方法,有效提高模型7%的性能。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/33305
图灵学术科研辅导
论文三:Rashomon Sets for Prototypical-Part Networks: Editing Interpretable Models in Real-Time
方法:
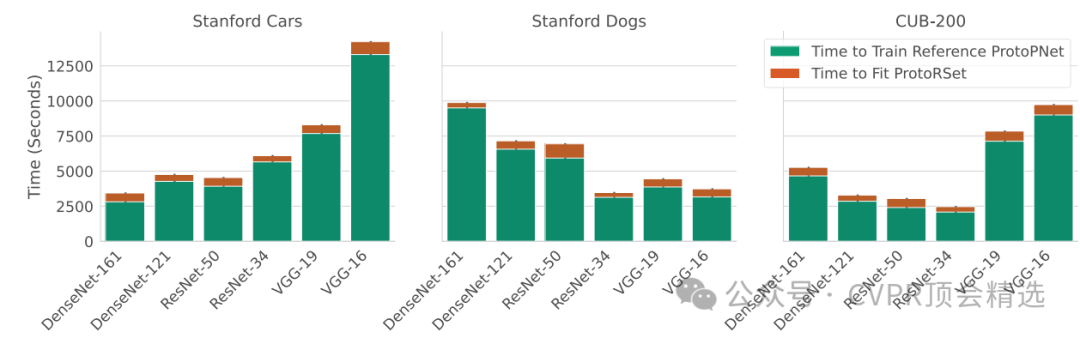
文章回顾ProtoPNets的结构与训练,并定义其Rashomon集,提出利用二阶泰勒展开近似计算的方法,将问题简化为多类逻辑回归的Rashomon集。随后介绍Proto-RSet的三种交互方式:模型采样、不使用特定原型的子集、以及使用特定原型且系数≥α的子集。实验结果表明,该方法能在多数据集与不同CNN骨干下高效生成满足用户约束的准确模型。
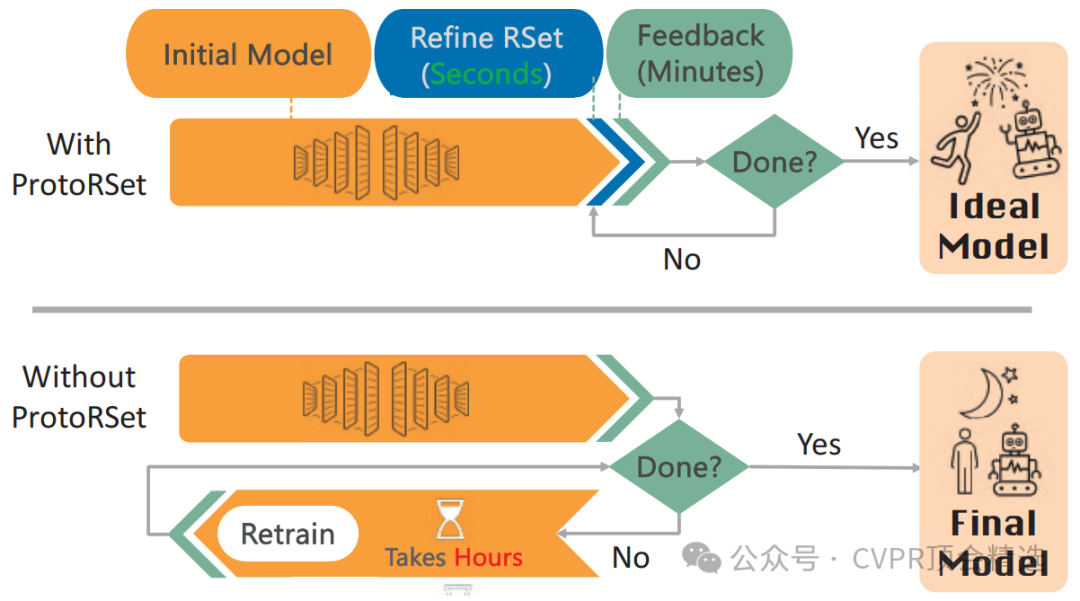
创新点:
首次将 Rashomon 集合方法引入计算机视觉,支持在复杂视觉任务中快速探索等效优良模型。
提出 Proto-RSet,可在秒级别生成满足用户约束的 ProtoPNet,避免传统耗时的重新训练。
在真实场景中验证方法,展示其在消除偏差与增强可靠性上的实用价值。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/32669
本文选自gongzhonghao【CVPR顶会精选】