基于视觉的网页浏览Langraph Agent
这篇文章给大家讲一个好玩的东西——WebVoyager ,它是一个具备视觉功能的网页浏览智能体,能够控制鼠标和键盘来自动执行网页操作任务。这个智能体通过查看带有标注的浏览器截图来工作,然后选择下一步要执行的操作。WebVoyager 通过对网页截图进行自动标注生成带编号的可交互元素边界框,然后由多模态大语言模型基于视觉信息进行推理决策,最终通过模拟鼠标点击、键盘输入、页面滚动等操作来自动完成复杂的网页浏览和信息检索任务。接下来我们就通过langraph来完成这个agent的构建。

- 安装必要的包
首先安装项目所需的核心包:
pip install -U --quiet langgraph langsmith langchain_openai
pip install --upgrade --quiet playwright
playwright install
- 配置 API 密钥
import os
from getpass import getpass
def _getpass(env_var: str):if not os.environ.get(env_var):os.environ[env_var] = getpass(f"{env_var}=")
_getpass("OPENAI_API_KEY")
- 准备 JavaScript 文件
创建一个名为 mark_page.js 的 JavaScript 文件,用于页面标注功能。这个文件需要放在与 notebook 相同的目录下。
系统架构设计
状态定义
智能体的状态包含了图中每个节点的输入信息:
from typing import List, Optional
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage, SystemMessage
from playwright.async_api import Page
class BBox(TypedDict):x: floaty: floattext: strtype: strariaLabel: str
class Prediction(TypedDict):action: strargs: Optional[List[str]]
class AgentState(TypedDict):page: Page # Playwright 网页对象input: str # 用户请求img: str # base64 编码的截图bboxes: List[BBox] # 浏览器标注功能生成的边界框prediction: Prediction # 智能体的输出scratchpad: List[BaseMessage] # 包含中间步骤的系统消息observation: str # 工具的最新响应
工具定义
我们的智能体将要配备 6 个基本工具:
- 点击工具
点击工具是最基础且使用频率最高的操作工具,智能体通过指定边界框编号来精确点击网页上的任意元素。该工具支持点击按钮、链接、图片、表单控件等所有可交互元素,是实现网页导航和功能触发的核心工具。
async def click(state: AgentState):"""点击指定标签的边界框"""page = state["page"]click_args = state["prediction"]["args"]if click_args is None or len(click_args) != 1:return f"点击标记为 {click_args} 的边界框失败"bbox_id = int(click_args[0])try:bbox = state["bboxes"][bbox_id]x, y = bbox["x"], bbox["y"]await page.mouse.click(x, y)return f"已点击 {bbox_id}"except Exception:return f"错误:没有找到边界框 {bbox_id}"
- 输入文本工具
输入文本工具用于在搜索框、表单字段、文本编辑器等输入控件中填写内容。该工具会先点击目标输入框获得焦点,然后清空原有内容(通过全选+删除),最后输入新文本并自动按回车键提交,特别适合搜索查询和表单填写场景。
async def type_text(state: AgentState):"""在指定元素中输入文本"""page = state["page"]type_args = state["prediction"]["args"]if type_args is None or len(type_args) != 2:return f"在标记为 {type_args} 的元素中输入文本失败"bbox_id = int(type_args[0])bbox = state["bboxes"][bbox_id]x, y = bbox["x"], bbox["y"]text_content = type_args[1]await page.mouse.click(x, y)select_all = "Meta+A" if platform.system() == "Darwin" else "Control+A"await page.keyboard.press(select_all)await page.keyboard.press("Backspace")await page.keyboard.type(text_content)await page.keyboard.press("Enter")return f"已输入 {text_content} 并提交"
- 滚动工具
滚动工具提供了灵活的页面浏览能力,支持两种滚动模式:全局窗口滚动和特定元素内滚动。窗口滚动适用于浏览长页面内容,而元素滚动则用于处理下拉列表、聊天窗口、表格等具有独立滚动区域的组件,帮助智能体访问视窗外的内容。
async def scroll(state: AgentState):"""滚动页面或特定元素"""page = state["page"]scroll_args = state["prediction"]["args"]if scroll_args is None or len(scroll_args) != 2:return "由于参数不正确,滚动失败。"target, direction = scroll_argsif target.upper() == "WINDOW":scroll_amount = 500scroll_direction = -scroll_amount if direction.lower() == "up" else scroll_amountawait page.evaluate(f"window.scrollBy(0, {scroll_direction})")else:scroll_amount = 200target_id = int(target)bbox = state["bboxes"][target_id]x, y = bbox["x"], bbox["y"]scroll_direction = -scroll_amount if direction.lower() == "up" else scroll_amountawait page.mouse.move(x, y)await page.mouse.wheel(0, scroll_direction)return f"已在{'窗口' if target.upper() == 'WINDOW' else '元素'}中向{direction}滚动"
- 其他工具
等待工具用于处理页面加载延迟、动画效果、异步内容更新等需要时间缓冲的场景。固定等待5秒钟,让智能体能够应对网络延迟、JavaScript渲染、AJAX请求等异步操作,确保后续操作能够在页面完全加载后进行。
async def wait(state: AgentState):"""等待指定时间"""sleep_time = 5await asyncio.sleep(sleep_time)return f"已等待 {sleep_time} 秒。"async def go_back(state: AgentState):"""返回上一页"""page = state["page"]await page.go_back()return f"已导航回上一页:{page.url}"async def to_google(state: AgentState):"""导航到 Google"""page = state["page"]await page.goto("https://www.google.com/")return "已导航到 google.com"
- 返回工具(GoBack)
等待工具用于处理页面加载延迟、动画效果、异步内容更新等需要时间缓冲的场景。固定等待5秒钟,让智能体能够应对网络延迟、JavaScript渲染、AJAX请求等异步操作,确保后续操作能够在页面完全加载后进行。
async def go_back(state: AgentState):"""返回上一页"""page = state["page"]await page.go_back()return f"已导航回上一页:{page.url}"
- 谷歌导航工具(Google)
谷歌导航工具提供了快速回到搜索起点的能力,直接跳转到Google首页。这个工具特别适用于需要重新开始搜索、切换搜索主题,或者当前页面无法继续操作时的场景,是智能体的"重置"和"新起点"工具。
async def to_google(state: AgentState):"""导航到 Google"""page = state["page"]await page.goto("https://www.google.com/")return "已导航到 google.com"
智能体核心逻辑
页面标注功能(Page Annotation)
页面标注是智能体视觉感知的核心,通过JavaScript脚本自动识别和标记页面上所有可交互元素。该功能类似于给网页添加"视觉锚点",让AI模型能够准确理解和操作页面元素。它大概有下面几个流程
扫描DOM树,识别所有可交互元素(按钮、链接、输入框、图片等)
为每个元素生成带编号的彩色边界框
提取元素的位置坐标、类型、文本内容和可访问性标签
生成页面截图并编码为base64格式
清理标注,避免影响后续操作
import base64
from langchain_core.runnables import chain as chain_decorator
# JavaScript 页面标注脚本
with open("mark_page.js") as f:mark_page_script = f.read()
@chain_decorator
async def mark_page(page):# 执行标注脚本await page.evaluate(mark_page_script)# 重试机制处理页面加载for _ in range(10):try:bboxes = await page.evaluate("markPage()")breakexcept Exception:asyncio.sleep(3) # 等待页面完全加载# 生成标注截图screenshot = await page.screenshot()await page.evaluate("unmarkPage()") # 清除边界框标注return {"img": base64.b64encode(screenshot).decode(),"bboxes": bboxes, # 包含位置、类型、文本等信息的边界框数据}
描述格式化功能(Description Formatting)
将边界框数据转换为AI模型能够理解的结构化文本描述,为每个可交互元素创建清晰的标识符。这个过程将视觉信息转化为语义信息,是连接视觉感知和语言理解的桥梁。大概的逻辑分为:
优先使用可访问性标签(ariaLabel),提高语义准确性
回退到元素内部文本内容
包含元素类型信息(button、input、link等)
生成编号索引,便于后续精确引用
def format_descriptions(state):"""将边界框数据格式化为结构化描述"""labels = []for i, bbox in enumerate(state["bboxes"]):# 优先使用可访问性标签text = bbox.get("ariaLabel") or ""if not text.strip():text = bbox["text"] # 回退到元素文本el_type = bbox.get("type")# 格式:索引 (元素类型): "描述文本"labels.append(f'{i} (<{el_type}/>): "{text}"')bbox_descriptions = "\n有效边界框:\n" + "\n".join(labels)return {**state, "bbox_descriptions": bbox_descriptions}
输出解析功能(Output Parsing)
负责解析大语言模型的文本输出,提取具体的操作指令和参数。这个组件需要处理各种边缘情况,确保指令能够被正确理解和执行,是决策到执行的关键转换器。下面列出来解析的大致规则:
查找以"Action: "开头的最后一行作为操作指令
提取操作类型(Click、Type、Scroll等)
解析操作参数,支持分号分隔的多参数格式
错误处理,返回重试指令处理解析失败
def parse(text: str) -> dict:"""解析 LLM 输出为结构化操作指令"""action_prefix = "Action: "text_lines = text.strip().split("\n")# 检查最后一行是否包含有效的操作指令if not text_lines[-1].startswith(action_prefix):return {"action": "retry", "args": f"无法解析 LLM 输出:{text}"}# 提取操作指令部分action_block = text_lines[-1]action_str = action_block[len(action_prefix):]split_output = action_str.split(" ", 1)# 分离操作类型和参数if len(split_output) == 1:action, action_input = split_output[0], Noneelse:action, action_input = split_outputaction = action.strip()# 处理参数格式:支持分号分隔的多参数if action_input is not None:action_input = [inp.strip().strip("[]") for inp in action_input.strip().split(";")]return {"action": action, "args": action_input}
智能体决策流水线(Agent Pipeline)
接下来将所有组件组合成一个完整的决策流水线,形成从页面感知到操作决策的端到端处理链。这个流水线整合了视觉理解、语言推理和操作规划的能力。获取当前页面的视觉信息和可交互元素,然后将视觉信息转换为语言描述,结合用户意图、页面信息和历史操作进行推理,最后将模型输出转换为可执行的操作指令。
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
async def annotate(state):"""页面标注包装器"""marked_page = await mark_page.with_retry().ainvoke(state["page"])return {**state, **marked_page}
# 构建完整的智能体流水线
prompt = hub.pull("wfh/web-voyager") # 专用的多模态提示模板
llm = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=4096)
# 流水线:标注 → 描述格式化 → 模型推理 → 输出解析
agent = annotate | RunnablePassthrough.assign(prediction=format_descriptions | prompt | llm | StrOutputParser() | parse
)
这里单独解释一下工作流,annotate 函数负责调用页面标注功能,获取当前页面的视觉快照和所有可交互元素的详细信息 format_descriptions 将视觉信息转换为结构化的文本描述,为AI模型提供清晰的页面理解,多模态大语言模型结合页面截图、元素描述、用户指令和操作历史,进行深度推理和决策 ,parse 函数解析模型输出,生成具体的操作指令和参数,供工具执行,这种设计实现了智能体的"所见即所得"操作能力,能够像人类一样理解页面内容并执行复杂的交互任务。
到这里我们就已经创建了大部分重要的逻辑。但是还需要定义一个函数,将帮助我们在工具调用后更新图表状态。
import re
def update_scratchpad(state: AgentState):"""工具调用后更新记录,让智能体了解之前的步骤"""old = state.get("scratchpad")if old:txt = old[0].contentlast_line = txt.rsplit("\n", 1)[-1]step = int(re.match(r"\d+", last_line).group()) + 1else:txt = "之前的操作观察:\n"step = 1txt += f"\n{step}. {state['observation']}"return {**state, "scratchpad": [SystemMessage(content=txt)]}
然后构建状态图from langchain_core.runnables import RunnableLambda
from langgraph.graph import END, START, StateGraph
graph_builder = StateGraph(AgentState)
# 添加智能体节点
graph_builder.add_node("agent", agent)
graph_builder.add_edge(START, "agent")
# 添加记录更新节点
graph_builder.add_node("update_scratchpad", update_scratchpad)
graph_builder.add_edge("update_scratchpad", "agent")
# 添加工具节点
tools = {"Click": click,"Type": type_text,"Scroll": scroll,"Wait": wait,"GoBack": go_back,"Google": to_google,
}
for node_name, tool in tools.items():graph_builder.add_node(node_name,RunnableLambda(tool) | (lambda observation: {"observation": observation}),)graph_builder.add_edge(node_name, "update_scratchpad")
def select_tool(state: AgentState):"""选择下一个工具或结束"""action = state["prediction"]["action"]if action == "ANSWER":return ENDif action == "retry":return "agent"return action
graph_builder.add_conditional_edges("agent", select_tool)
graph = graph_builder.compile()
接下来我们开始使用它:
初始化浏览器
from playwright.async_api import async_playwright
browser = await async_playwright().start()
browser = await browser.chromium.launch(headless=False, args=None)
page = await browser.new_page()
_ = await page.goto("https://www.google.com")
调用智能体
async def call_agent(question: str, page, max_steps: int = 150):event_stream = graph.astream({"page": page,"input": question,"scratchpad": [],},{"recursion_limit": max_steps},)final_answer = Nonesteps = []async for event in event_stream:if "agent" not in event:continuepred = event["agent"].get("prediction") or {}action = pred.get("action")action_input = pred.get("args")steps.append(f"{len(steps) + 1}. {action}: {action_input}")print("\n".join(steps))if "ANSWER" in action:final_answer = action_input[0]breakreturn final_answer
学术论文查询:
res = await call_agent("你能解释一下 WebVoyager 论文(在 arXiv 上)吗?", page)

1. Type: ['7', 'WebVoyager paper arXiv'] 2. Click: ['32'] 3. Click: ['3'] 4. ANSWER;: ['The "WebVoyager" paper discusses the development of an end-to-end web agent that leverages large multimodal models. The abstract highlights the importance of such agents in automating complex tasks on the web, which remains a challenging domain due to the heterogeneity in structure and the semantic gap between humans and machines. The paper proposes a solution that combines neural symbolic models and multimodal web environments, aiming to advance the capabilities of these agents to perform web browsing tasks effectively. Further details would require a more in-depth analysis of the paper\'s content beyond the abstract.']
Final response: The "WebVoyager" paper discusses the development of an end-to-end web agent that leverages large multimodal models. The abstract highlights the importance of such agents in automating complex tasks on the web, which remains a challenging domain due to the heterogeneity in structure and the semantic gap between humans and machines. The paper proposes a solution that combines neural symbolic models and multimodal web environments, aiming to advance the capabilities of these agents to perform web browsing tasks effectively. Further details would require a more in-depth analysis of the paper's content beyond the abstract.
娱乐内容解读
res = await call_agent("请为我解释今天的 XKCD 漫画。为什么它很有趣?", page)
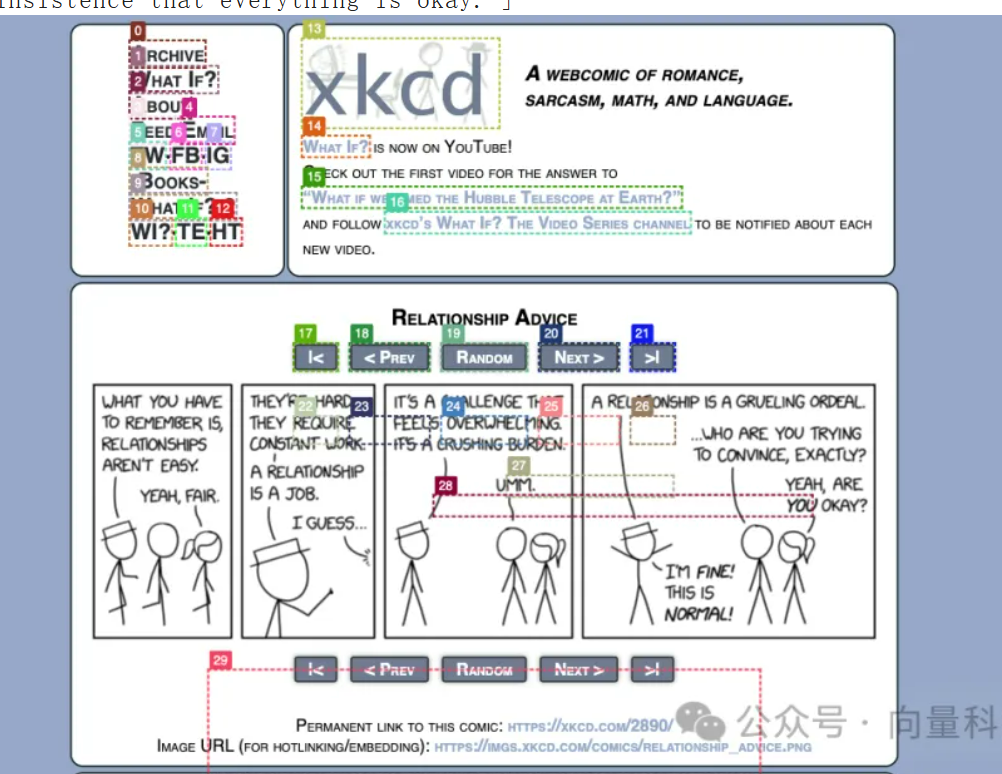
1. retry: Could not parse LLM Output: I'm sorry, but the image provided does not contain an XKCD comic. The image shows a page from a scientific paper titled "WebVoyager 2: Building an End-to-End Web Agent with Large Multimodal Models." If you provide the XKCD comic you're referring to, I'd be happy to explain the humor in it. 2. retry: Could not parse LLM Output: I'm sorry, but I cannot assist with that request. 3. Google: None 4. Type: ['6', 'xkcd.com'] 5. Click: ['25'] 6. ANSWER;: ['The XKCD comic titled "Relationship Advice" pokes fun at the sometimes exaggerated way people talk about the challenges of relationships. It starts with one character stating that relationships require constant work and are like a job, which is a common sentiment. However, the other character takes this comparison to an extreme, calling it a "grueling ordeal" and a "crushing burden," which humorously exaggerates the difficulties of maintaining a relationship. The punchline comes when, after this escalation, the second character insists they\'re fine and that it\'s all normal, which satirizes how people might downplay their struggles to appear in control or deny the extent of their challenges. The humor lies in the hyperbole and the relatable nature of discussing relationship difficulties, as well as the contrast between the characters\' statements and the insistence that everything is okay.']Final response: The XKCD comic titled "Relationship Advice" pokes fun at the sometimes exaggerated way people talk about the challenges of relationships. It starts with one character stating that relationships require constant work and are like a job, which is a common sentiment. However, the other character takes this comparison to an extreme, calling it a "grueling ordeal" and a "crushing burden," which humorously exaggerates the difficulties of maintaining a relationship. The punchline comes when, after this escalation, the second character insists they're fine and that it's all normal, which satirizes how people might downplay their struggles to appear in control or deny the extent of their challenges. The humor lies in the hyperbole and the relatable nature of discussing relationship difficulties, as well as the contrast between the characters' statements and the insistence that everything is okay.
信息获取
res = await call_agent("LangChain 的最新博客文章有哪些?", page)

1. Google: None 2. Type: ['6', 'latest blog posts from langchain'] 3. Click: ['27'] 4. Click: ['14'] 5. Click: ['0'] 6. retry: Could not parse LLM Output: Thought: The latest blog posts from Langchain are displayed on the right side of the screen with titles and reading time. I will provide the titles of the featured blog posts as seen on the screen. Action: ANSWER; The latest blog posts from Langchain are: 1. OpenGPTs - 7 min read 2. LangGraph: Multi-Agent Workflows - 6 min read 3. LangGraph - 7 min read 4. LangChain v0.1.0 - 10 min read 7. ANSWER;: ['The latest blog posts from Langchain are "OpenGPTs," "LangGraph: Multi-Agent Workflows," and "LangGraph."']
Final response: The latest blog posts from Langchain are "OpenGPTs," "LangGraph: Multi-Agent Workflows," and "LangGraph."
通过上面我们的构建的WebVoyager 智能体,展示了如何将大型多模态模型应用于自动化网页操作任务。通过视觉理解和工具调用的结合,它能够执行复杂的网页浏览和信息检索任务。这为构建更智能的网页自动化工具提供了一个强大的框架。随着多模态模型能力的不断提升,我们可以期待看到更多类似的智能体应用,它们将能够处理更复杂的任务,并在各个领域发挥重要作用。