【RAG知识库实践】向量数据库VectorDB
一、概述
1.1 什么是向量库
向量数据库是一种专门为存储、索引和查询高维向量数据而优化的数据库系统。与传统的关系型数据库不同,向量数据库将数据映射到向量空间中,使得数据的相似性计算、聚类、分类和检索变得更加高效和精确
向量数据库一般包括以下几个部分:索引、查询、过滤
第一步:建立索引
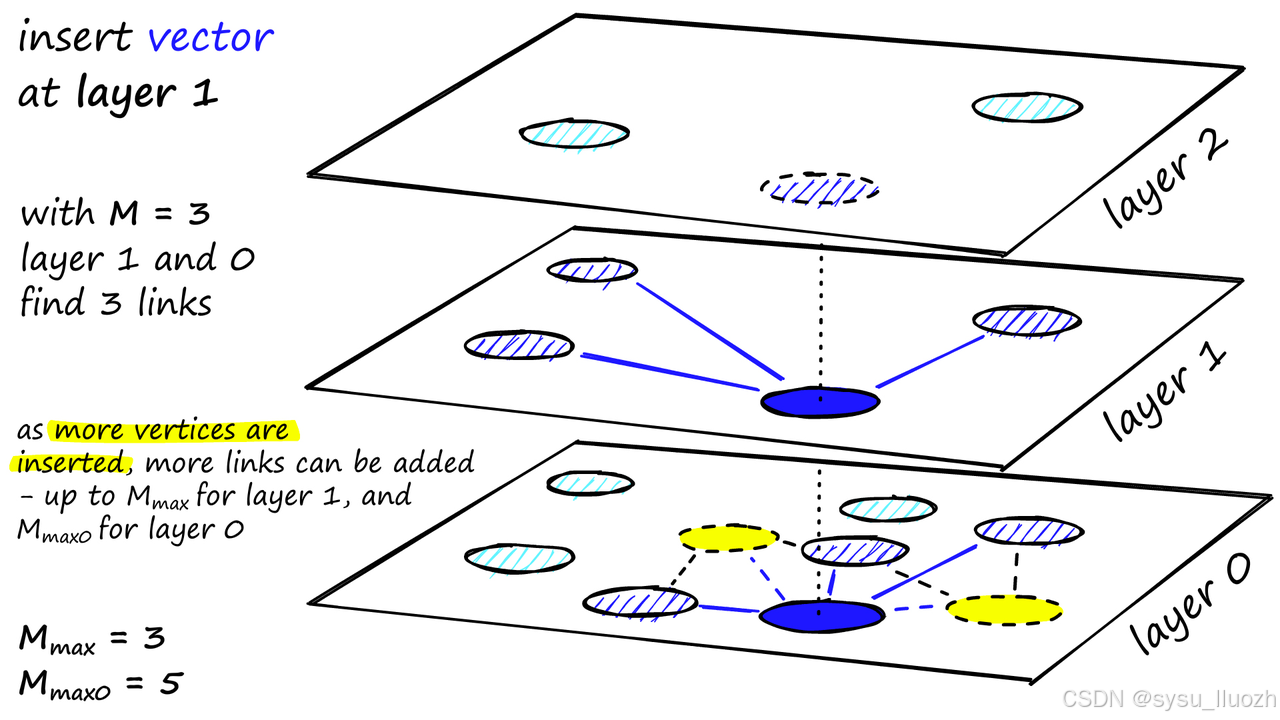
向量数据库使用 HNSW(分层可导航小世界)等算法对向量进行索引,此步骤将向量映射到数据结构,以实现更快的搜索。索引的目标是通过创建可快速遍历的数据结构来实现快速查询,通常会将原始向量的表示形式转换为压缩形式以优化查询过程
HNSW 创建一个分层的树状结构,其中树的每个节点代表一组向量。节点之间的边代表向量之间的相似度。在高层次,数据点的数量较少,连接关系较少,搜索效率较高。在底层,数据点的数量较多,连接关系更密集,能够更精确地找到最近邻。通过逐层导航和搜索,HNSW 能够快速找到与查询点最相似的点
第二步:查询检索
向量数据库将索引查询向量与数据集中的索引向量进行比较,以找到最近的邻居,这里会应用该索引使用的相似性度量。相似性度量是用于确定向量空间中两个向量相似程度的数学方法。向量数据库中使用相似性度量来比较数据库中存储的向量并找到与给定查询向量最相似的向量。可以使用多种相似性度量,包括:余弦相似度