深度学习11 Deep Reinforcement Learning
Reap:basics
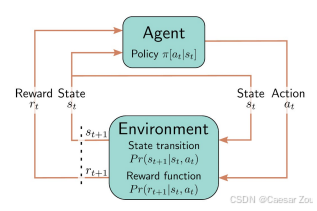
An agent takes actions based on the observation of an environment and a policy to maximise a cumulative reward/expected return.
Outcome of RL: develop a policy (i.e., strategy) to take an action at when in a state St.
这种学习方式模仿了人类和动物的学习过程 - 通过试错来学习最优策略
不同于监督学习,强化学习没有明确的标签,而是通过与环境交互来学习
面临探索-利用权衡问题:需要在探索新动作和利用已知好动作之间取得平衡
E.g.: An agent learning to play chess by playing games and getting feedback on what led to a win or a loss.
Markov Decision Process (MDP)
Common setup: learn a policy by maximising the return of a Markov Decision Process (MDP)
强化学习常用马尔可夫决策过程(MDP)框架来学习最优策略
马尔可夫过程:环境总是处于若干可能状态st之一
状态转移概率 Pr(st+1|st)描述了状态之间的变化关系
马尔可夫性质意味着未来状态只依赖于当前状态,与历史路径无关
这大大简化了问题,但也是一种近似 - 现实世界往往不完全满足马尔可夫性质
MDP提供了一个数学框架来形式化描述序贯决策问题
Markov reward process introduces a distribution Pr(rt+1|st) of possible rewards received at the next step, given current state st.
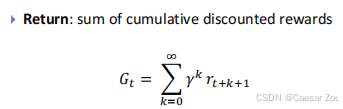
r 是每个时间步的奖励(at the next step when in step t+k),γ 是折扣因子(介于 0 和 1 之间),用于控制未来奖励的重要性。
k = 0 时,表示在当前时刻立刻获得的奖励;k = 1 时,表示在下一个时刻获得的奖励,以此类推。
This a stochastic process! I.e., includes “noise” in the agent actions.
马尔可夫决策过程 还定义了状态转移分布 Pr(st+1|st, at),即给定当前状态和动作,下一状态的可能性分布。奖励的分布也会受到动作和状态的影响
强化学习中的环境有时是部分可观察的(POMDP),即智能体并不能完全知道环境的所有状态。
Policy
Policy: set of rules determining the agent action at each state. Can be deterministic or stochastic, stationary or non-stationary:
确定性策略:每个状态只有一个固定的动作。
随机策略:在每个状态下都有一个动作的概率分布,智能体从中随机选择动作。
静态策略:策略只依赖于当前状态。
动态策略:策略还依赖于当前的时间步长。
- Stochastic policy π[a|s] : probability distribution over each possible action a for state s. Chosen action sampled from π[a|s] .
- Deterministic policy π[a|s] : 1 for chosen action and 0
otherwise.
- Stationary policy: depends on the current state.
- Non-stationary policy: also depends on the time step
随机策略 的优势是它更适合探索新的动作,而不总是选择看似最优的动作。这可以帮助智能体避免陷入局部最优解。
静态与动态策略 的区别在于,动态策略可以根据时间的变化来调整动作选择。这在一些长期规划问题中尤其重要,比如投资决策。
Choosing a policy

目标是找到一个能够最大化预期回报的策略。
状态值函数:表示在给定状态下,按照某策略执行时,未来可能获得的预期回报。
动作值函数:表示在给定状态和动作下,未来可能获得的预期回报。
- 状态值函数 帮助我们估计在某个状态下开始,长期执行策略后能获得的总回报。它会告诉我们哪些状态可能更有利,值得优先进入。
- 动作值函数 则是将特定的动作与回报联系起来,帮助智能体知道在某个状态下采取哪个动作最有利。

· 对于马尔可夫决策过程,总是存在一个最优的确定性静态策略,能够最大化每个状态的期望回报。
· 最优状态值函数:
表示在状态 st 下,选择最优策略π能够获得的最大预期回报(未来期望累积回报 G t的最大值。)。
· 最优动作值函数:
表示在状态 st 下,执行动作 at 并且后续按照最优策略执行时,获得的最大预期回报。

Bellman equations
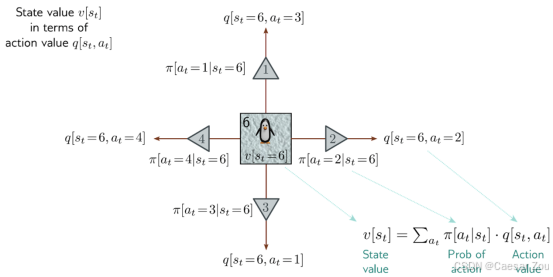

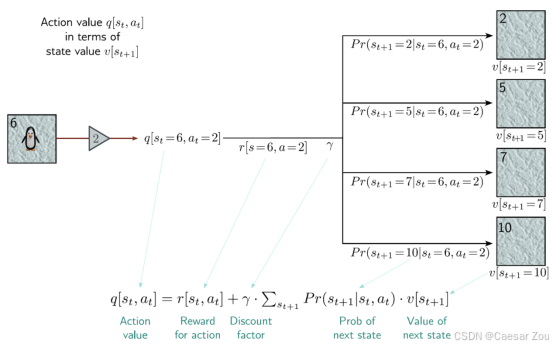

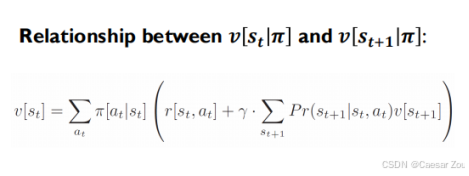
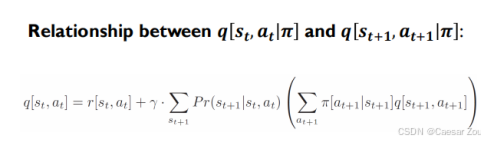
状态值是所有可能动作的加权平均值,而动作值则包含了从当前状态到下一个状态的即时奖励和未来折扣回报的组合。
The state value v[st|π] can be found by taking a weighted sum of the action values q[st, at|π], where the weights depend on the probability under the policy π[at|st] of taking that action.
Tabular RL
- 表格型强化学习 使用查找表的方式来存储状态-动作对的值。这种方法只适用于状态和动作空间较小的场景,因为数据量较大时无法有效存储和处理。
- 模型驱动方法:基于已知的状态转移矩阵和奖励结构,通过动态规划等算法直接优化策略。

动态规划常见的两种算法是策略评估(Policy Evaluation) 和 策略改进(Policy Improvement)
动态规划(Dynamic Programming, DP) 是一种将复杂问题分解为更小的子问题并通过保存子问题的解(即“记忆化”)来避免重复计算的算法思想。它常用于求解最优决策问题,通过递归地解决子问题,并将其结果合并成最终解。
举个通俗的例子:
假设你在攀登一段有100级台阶的楼梯,你可以每次迈一步或两步。动态规划的方法就是先计算每一级台阶的可能走法,并保存这些结果。比如,第一级有1种走法,第2级有2种走法(一步或两步),第3级的走法等于前两级走法之和(即可以从第1级迈两步,或从第2级迈一步)。通过逐步计算,你可以得到100级台阶的走法,而不需要重复计算每个状态。
无模型方法 Model-free methods
不需要知道状态转移概率 Pr(st+1∣st,at)和奖励结构 r(s,a)。这些需要通过经验数据来估计。
- 值估计:估计最优的状态-动作值函数,然后根据每个状态下具有最大值的动作来制定策略。
- 策略估计:直接使用梯度下降来估计最优策略,而不是估计值函数。
估计过程通过采样完成Estimation built through sampling:
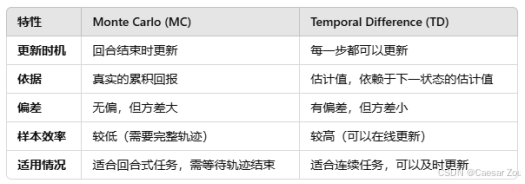
蒙特卡洛采样:通过模拟轨迹(即执行一个完整的回合或游戏)来观察奖励,随后更新策略。是一种直接的采样方法,通过观察一系列的完整游戏或事件,并使用这些信息来更新策略。优点是它简单,但需要完整的回合。

是一种通过模拟轨迹(即一个完整的回合或多个回合,称为"episodes"或"rollouts")从马尔可夫决策过程(MDP)中采样的方式。智能体会根据当前策略 π 选择动作,并与环境交互,观察获得的奖励。

TD方法(时间差分法):在每个状态转移过程中逐步更新状态值和策略。是一种更为高效的方法,它在每一步都更新策略,不需要等待整个回合结束。比如,Q学习 是一种常见的TD方法。
- Q学习 是一种常见的离线方法,它通过最大化每个状态的动作值来更新策略,而不局限于当前的策略。这使得它在某些情况下比在线方法更加高效。它通过估计每个状态-动作对的价值来决定策略。这意味着 Q学习的目标是学会一个动作值函数,用于评估在某个状态下选择特定动作能获得的期望回报。之后,智能体通过最大化这个值来选择动作。(学习动作值函数q(st,at) 估计每个状态下的动作回报,智能体可以选择哪个动作能带来最大的长期收益。因此,它需要通过计算每个动作的值来选择动作。)

On-policy vs off-policy methods
- 在线(on-policy)方法 使用当前策略来模拟轨迹(也就是rollouts),并在执行这些轨迹的过程中更新策略。
只有当前策略下的动作会被探索,这意味着该算法不太鼓励探索其他策略中的动作。 - 离线(off-policy)方法 存储来自不同策略(行为策略)的rollouts。主策略偶尔会基于所有收集到的不同策略的数据进行更新。 有时,主策略是确定性的(更高效),而行为策略是随机性的(更倾向于探索)。
在线方法 更依赖于当前的策略,这意味着它不太适合那些需要广泛探索的场景,因为它只专注于当前策略所提供的行动空间。
离线方法 更灵活,因为它允许智能体从多个策略的数据中学习,这对于需要广泛探索和多样化学习的场景更有利。
Fitted Q-learning & Deep Q-networks
表格型强化学习方法(如蒙特卡洛和TD方法)只适用于较小的马尔可夫决策过程(MDP),因为当状态空间过大时(如国际象棋中可能的合法状态超过10^{40}),这些方法难以应用。
- 拟合Q学习Fitted Q-learning:使用机器学习模型代替传统的离散表示 discrete representation q(st,at),来进行动作值函数的拟合。
- 损失函数用于学习模型的参数 ϕ,但这种方法的收敛性无法保证,因为目标(最大值)本身也在不断变化。
什么是参数?神经网络的权重和偏置,经过训练过程不断调整,以最小化预测误差,使输出的 q(st,at) 尽可能接近实际观察到的回报
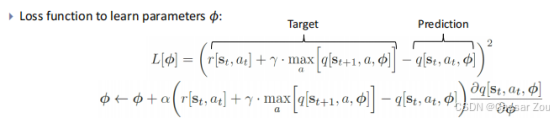
Least squares loss based on the consistency of adjacent action values.
例如,深度Q网络(DQN) 是一种基于拟合Q学习和深度神经网络的算法,被用于解决诸如ATARI 2600游戏中的动作选择问题。
Not guaranteed to converge (chase a moving target).
深度Q网络(DQN)架构
- 深度Q网络(DQN) 结合了拟合Q学习与深度学习,用于学习ATARI 2600游戏中的动作选择。通过深度网络学习状态-动作值函数,从而指导智能体的决策。
- 固定目标参数:为了提高收敛性,DQN中的目标参数 ϕ− 只会在特定周期内更新。
![]()
新参数=旧参数+学习率*(即时奖励+折扣*未来最大奖励-到当前估计动作值)*梯度项
括号里的就是误差项,所谓的TD误差(Temporal Difference Error),它衡量了当前估计的动作值 和根据实际奖励以及未来回报计算出的目标之间的差距。通过最小化这个误差,我们可以不断改进模型。
其中最大奖励,是未来状态s t+1中最优动作 a 对应的最大动作值,这个值是通过“目标网络”计算得到的,参数为 ϕ−,即目标网络的参数。目标网络是为了稳定训练过程,每隔一段时间才更新。
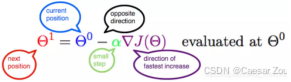
原始公式:Θ1 =Θ0+α▽J(Θ)
- 奖励通过游戏得分驱动,负得分变化对应 -1,正得分变化对应 +1。
DQN 采用了经验回放机制,即将最近的状态-动作对存储在一个缓冲区中,i.e., recent tuples < st,at,rt+1,st+1 > stored in a buffer, sampled to generate a batch at each step.
- Reducing temporal correlation in training data.在传统的强化学习中,智能体在每个时刻与环境交互时,产生的状态转移样本是连续的,彼此之间有很强的时间相关性。如果直接使用这些连续的样本进行训练,模型很容易过拟合短期行为,导致学习效果不稳定。经验回放通过从缓冲区中随机采样,打乱了样本的时间顺序,这样就减少了样本之间的时间相关性,避免了模型仅仅关注最近的经验,从而提高了训练的稳定性和泛化能力。
- Improving sample efficiency. 将每个经验样本存储在缓冲区中并进行多次使用
- Promoting convergence.减少了训练过程中的震荡和不稳定性。由于经验样本的分布更加均匀且独立,模型的更新方向更加准确,有助于加速收敛。
在每个步骤中从中抽取一批数据来进行训练。
策略梯度方法 Policy gradient methods:
策略梯度方法 直接学习一个随机策略 π(at∣st, θ),其参数 θ 用于将状态 st 映射为在动作at上的动作分布 Pr(at∣st)
- 与Q学习不同,策略梯度方法并不估计动作值,而是直接学习如何从状态生成动作(通过策略函数来输出动作,这个函数给出每个状态选择动作的概率)。
- 目标是通过最大化多个轨迹中的期望回报来优化策略。
- 策略梯度方法的核心思想是直接优化策略,以便在一系列可能的动作序列(轨迹)中获得最大回报。它的主要特点是不估计每个状态或动作的值,而是直接从策略中采样动作,并根据实际得到的回报来调整策略。



扩展说明:
- 策略梯度方法 的一个主要优点是它能够处理连续的动作空间,这对于许多复杂的控制问题(如机器人操控)尤为重要。
- 相比之下,基于值函数的强化学习方法(如Q学习)通常更适合离散动作空间。
策略更新公式:

denotes the gradient of the expected gain for all possible trajectories.



策略梯度方法的核心思想是直接优化策略函数,这使得它能够处理复杂的动作空间,特别是连续动作空间。这在机器人操控和金融投资等领域非常有用。
- 这个公式表明策略梯度方法通过观察轨迹中的每一步来更新策略参数。这个过程类似于我们通过反馈来调整决策,逐渐改进自己的行动策略。
REINFORCE 算法
REINFORCE 算法 是一种基于蒙特卡洛方法的策略梯度算法,它通过生成完整的轨迹 τ=[s1,a1,s2,a2,…,sT,aT] 来估计回报(基于当前policy π[at|st,θ])。
对于离散动作,神经网络 π(s,θ) 被训练为每个可能的动作返回一个输出值。
每步的经验折扣回报为:
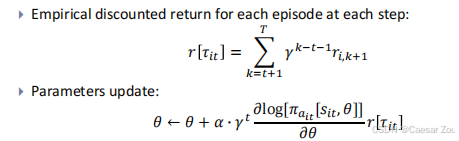
![]()
扩展说明:
- REINFORCE 算法 是强化学习中一种经典的策略梯度方法,它的优点是简单易实现,但由于是基于蒙特卡洛采样的,可能存在较高的方差。
Actor-Critic 方法
Actor-Critic 方法是一类结合了策略梯度和值函数估计的强化学习算法。它与 REINFORCE 不同的是,它在每一步 t 都更新策略,而不是等整个轨迹结束后再更新。
优势:该方法不需要等待整个轨迹结束,能够在每一步实时更新策略,从而加速了学习过程。
近似值:由于无法访问未来的所有奖励,因此它通过当前观察到的奖励和下一个状态的折扣值来近似更新。其中 v 是一个第二个神经网络估计出的状态值函数。
![]()
Actor-Critic 方法 通过在策略网络(actor)和值函数网络(critic)之间进行交替更新,使得智能体能够同时学习如何选择动作(actor)和评估动作的好坏(critic)。
离线强化学习(Offline RL):
离线强化学习(Offline RL)有时被称为批量强化学习,它的目标是在不与环境进行直接交互的情况下学习如何采取行动。
这种方法在以下情况中特别有用:
- 例如,在自动驾驶或工业操作中,允许智能体自由探索可能导致危险行为。
- 在金融领域,采集数据可能非常耗时或昂贵。
模拟环境 是一种常见的替代方案,但模拟也可能存在高昂的成本,或不能完全捕捉到真实环境中的复杂性。
离线强化学习允许智能体从历史数据中学习,这在没有机会直接操作环境的情况下非常有用。通过已有的数据,智能体可以有效训练策略,然后再应用到现实环境中。
离线强化学习的方法:
一些离线强化学习方法基于 Q-learning 和策略梯度,这些方法利用历史数据进行训练,而不是通过与环境的直接交互。换句话说,它需要通过已知的状态-动作-奖励序列来推断未来该采取的动作。
离线强化学习也可以被视为一个序列学习问题sequence learning problem,目标是根据状态、奖励和动作的历史来预测下一步的行动。这与典型的序列预测任务类似,序列预测任务的目标通常是根据过去的输入来预测下一个元素。比如在自然语言处理中的语言模型,它会根据前面的词汇来预测下一个词。
Why not using DNN architectures specialised with sequence prediction?
1.奖励和动作的长期依赖性:
在强化学习中,未来的动作不仅依赖于最近的状态和动作,还依赖于历史中某些关键时刻获得的奖励,这涉及到长期依赖性。传统的序列模型(如LSTM或GRU)虽然能够捕捉某些短期和中期的依赖,但它们并不一定适合处理强化学习中的复杂回报信号,因为这些回报信号通常通过折扣因子 γ 来影响未来决策,涉及到长期累积回报的优化。
2. 价值函数和策略的优化:
强化学习的核心任务是找到一个最优策略来最大化累积奖励。这不仅仅是预测下一个动作,还包括优化策略和估计价值函数(如Q值或状态值)。传统的序列预测模型通常只是进行下一步的预测,而没有涉及强化学习中特有的目标,例如通过价值函数来指导决策和策略的改进。因此,离线RL需要特别设计的架构来处理这种价值优化问题,而不仅仅是序列预测问题。
3. 数据分布的挑战(Distributional Shift):
在离线RL中,训练数据(历史数据)和测试数据(未来实际策略执行的数据)之间可能存在数据分布的差异,这被称为**分布偏移(Distributional Shift)**问题。传统的序列学习模型在这样的情况下可能会出现性能不稳定,因为它们依赖于已有的数据分布,而离线RL需要一种更鲁棒的机制来处理这种分布差异,确保在未见的状态下依然能作出合理的决策。
4. 探索与利用的权衡:
强化学习中的一个核心挑战是探索与利用的权衡,即在选择行动时,智能体需要平衡已知的动作带来的回报和未知动作可能带来的更大回报。序列预测模型通常没有这种权衡,它们只是基于历史信息进行预测,而不会主动探索新的动作。离线RL需要在模型架构中内嵌一定的策略探索机制,而不仅仅是依赖序列预测。
决策转换器(Decision Transformer)
是一种基于 Transformer 的架构,它通过对未来奖励的预测来进行动作决策。这个方法的关键在于,它不仅依赖于过去的经验,还考虑了未来的潜在回报,从而在选择动作时能够更好地预测将来可能获得的总回报。
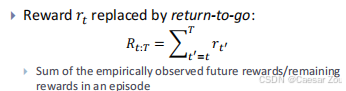
传统强化学习中,回报 rt仅仅指即时奖励,但在决策转换器中,使用了“return-to-go”,即从当前时间 t 到回合结束的剩余回报之和。这个值可以理解为“未来期望的累积回报”。
换句话说,剩余回报R t:T是指从时间步 t 开始直到回合结束所能获得的所有奖励的总和
结论:
- 强化学习方法通过智能体在环境中探索状态来学习最优策略。
- 它们的目标是最大化预期回报,通过使用状态值和动作值函数来更新策略。
- 表格型强化学习 适用于小规模状态空间,通过查表更新策略。
- 深度Q网络(DQN) 使用拟合 Q 学习来更新大规模状态空间的动作值函数。拟合Q值函数的作用在于,它帮助智能体估计在某个状态下选择某个动作后可能获得的长期回报。这样,智能体可以通过比较不同动作的Q值,选择能够获得最高回报的动作。简单来说,拟合Q值函数就是为了让智能体在每个状态下知道选哪个动作回报最高。
- 策略梯度方法 直接通过观察到的轨迹来优化策略。策略梯度方法是通过模拟或采样轨迹来直接学习和优化策略的
- 离线强化学习 是一种新的学习范式,旨在不与环境进行交互的情况下学习策略。