基础|Golang内存分配
内存分配
背景
os背景
操作系统控制所有的内存,程序想要用内存,操作系统会分一块给程序,在程序看来操作系统给的内存是连续的一块,很好用,实际上这是操作系统的功能,在真实物理内存上铺了一层虚拟内存管理的机制,给到程序一块“连续”的内存。但是对于程序而已,不用管是不是在物理内存上是连续的,就当它是连续,不影响程序自己的工作,至于性能好不好,这是操作系统的问题。程序(runtime、jvm)拿到一整块内存后,(app程序的)线程就会去申请内存,程序会在这块内存中划一块空间给线程,app程序的线程就去创造对象在内存上,这样对象就在内存上生成了。不同语言有不同的分配机制,有些语言是手动管理的(C、C++等),有些是自动管理的,例如Java,Golang。这里讲的是Golang的内存分配机制。
C中分配内存用的malloc等方法,而Golang的内存分配问题就有点像 【Go 的“malloc”实现】。
类比:Go 的内存分配(逃逸分析+ tcmalloc) ≈ Java JVM 的对象分配机制(TLAB + 堆管理)
Java的TLAB类似于go中的mcache,线程(协程)私有的内存,很朴素的思想:私有的资源不用参与并发竞争。
栈与堆
- Go 里有两大类内存
- 栈内存 (stack memory)
每个 goroutine 都有一块独立的栈(初始只有 2KB,按需增长/缩小)。
栈上的变量随函数调用创建,函数返回时自动销毁。
栈内存由 runtime 单独管理,不是通过 mcache/mcentral/mheap 来分配的。
分配和回收都非常快(就是指针移动)。 - 堆内存 (heap memory)
需要在多个函数间共享,或者逃逸分析判定无法放栈的对象。
这些对象才会通过 Go 的内存分配器(mcache/mcentral/mheap)获得内存。
生命周期由 GC 管理。
- 栈内存和堆内存的关系
栈和堆是两块完全不同的内存区域:
栈:goroutine 独占,自动增长缩减。
堆:全局共享,走分配器,需 GC 回收。
变量放在哪里,由 逃逸分析 (escape analysis) 决定:
如果编译器能确定变量只在当前函数/栈帧中使用 → 放栈。
如果变量可能在函数外部被引用(比如返回指针、闭包捕获) → 放堆。
生命周期
- 编译期:编译器进行逃逸分析,决定每个变量应该被分配在栈上还是堆上。
- 运行时 - 栈分配:对于栈变量,随着 goroutine 的创建和函数调用,在各自的栈上通过移动栈指针极速分配和释放。
- 运行时 - 堆分配:对于堆变量,Go 运行时启动那套复杂而高效的三级分配器(mcache -> mcentral -> mheap)来为其分配内存。
- 垃圾回收 (GC):GC 会定期扫描堆上的对象,回收那些不再被任何指针引用的“垃圾”内存。注意:GC 不会管理栈内存,函数返回时栈帧一销毁,上面的指针就没了,它们所引用的堆内存的引用计数也会相应减少。
逃逸分析Q&A
Q:逃逸分析是什么?
A:Go 编译器决定将变量放 栈 还是 堆。
Q:内存逃逸是什么?
A:在 Go 中,编译器会尽量在栈上分配内存,因为栈上的内存分配和回收非常快。然而,并不是所有的内存分配都可以在栈上完成。当编译器无法保证对象的生命周期仅限于其定义的作用域时,会将这些对象分配到堆上,这个过程称为“内存逃逸”。
简述:由于生命周期没法只在这个函数上的时候,没法放在栈上了,只能放在堆上了。
Q:什么情况放堆,什么情况放栈?
A:
- 栈分配:小对象、作用域明确、不被闭包/返回值持有。
- 堆分配:
- 语义上逃逸:
被返回到函数外、传递到goroutine
被闭包捕获
存入接口/容器(指当一个值被赋值给接口类型变量时,这个值可能会逃逸到堆上) - 策略上分配:
对象过大(阈值几十 KB)、栈上空间不足
对象大小运行时才知道
全局/静态存活对象、Go runtime 内部的数据结构(调度器、GC 元数据等)。
开发者显式申请的堆对象(new、make);
- 语义上逃逸:
Q:对于编译阶段,数据还没形成,未知大小,例如一个接口是io取数据的,程序预先是不知道这个io来的数据大小是什么,编译器如何进行逃逸分析呢?
func readDynamic(r io.Reader, n int) {buf := make([]byte, n)_, _ = r.Read(buf)fmt.Println(buf[0])
}
A:直接分配在堆上。
确实,程序在运行时才会有真实数据,编译器在 编译阶段 并不知道运行时数据的实际大小。这里的 n 是运行时才知道的。编译器无法判断 n 的大小,所以 保守起见,它会让 buf 直接分配在堆上。
总结:
小对象:放栈(快,随函数栈帧回收)。
中等对象:若生命周期短,编译器可能仍放栈。
大对象(如 IO 读大数据):通常直接放堆,避免栈爆掉。
goroutine 栈是动态扩展的,但编译器策略更倾向于 避免栈被大对象撑爆。
Q:方法返回指针好,还是返回值好?
A:对象小返回对象,对象大返回指针
| 返回方式 | 内存分配影响 | 适用场景 |
|---|---|---|
| 返回对象值 | 通常栈分配,快速高效 | 对象较小,复制开销低 |
| 返回指针 | 对象逃逸堆分配,GC负担 | 对象较大,不想复制,或者需要共享访问 |
堆内存分配
三层缓存机制
在 Golang 中,内存分配主要由 Go 运行时系统(runtime)负责,这里把堆内存分配相关的部分称之为:内存分配器。内存分配器设计目标是减少全局锁的竞争,提高多线程程序的性能。Go 的内存分配器是基于 tcmalloc 概念的一个实现(tcmalloc 是Google开发的并发内存分配库),是一套内存多级分配机制。
-
mcache(每个 P 独享的本地缓存)
每个 P(调度器 Processor)有一个 mcache,存放小对象的空闲 span。
优点:无锁,分配超快。
如果 mcache 没有可用对象,就去找 mcentral。mcache与并发调度器整合在一起了:mcache 绑定到 P,与 G-P-M 调度模型耦合在一起
-
mcentral(所有 P 共享的中央缓存)
存放一类大小的 span(比如 8B、16B、32B …)。每个规格的 span 都有自己专属的 mcentral(例如,所有 8B 的 span 由一个 mcentral 管理,所有 16B 的由另一个管理)。
内部有空闲链表。
需要加锁访问。
当 mcache 耗尽时,从 mcentral 获取一整个 span。全局缓存,存 span,每个 size class 一个。
span 的大小不是固定的,而是根据 size class 来动态确定的,它是由若干个连续 page(通常 8KB) 组成的
-
mheap(全局堆管理)
从操作系统申请大块内存(page 级别,通常 8KB)。
划分成 span(连续的 page),再交给 mcentral 管理。
当 mcentral 没有 span 时,就去 mheap 要。
最底层通过 sysAlloc 调用操作系统(mmap / VirtualAlloc)。
简单来看: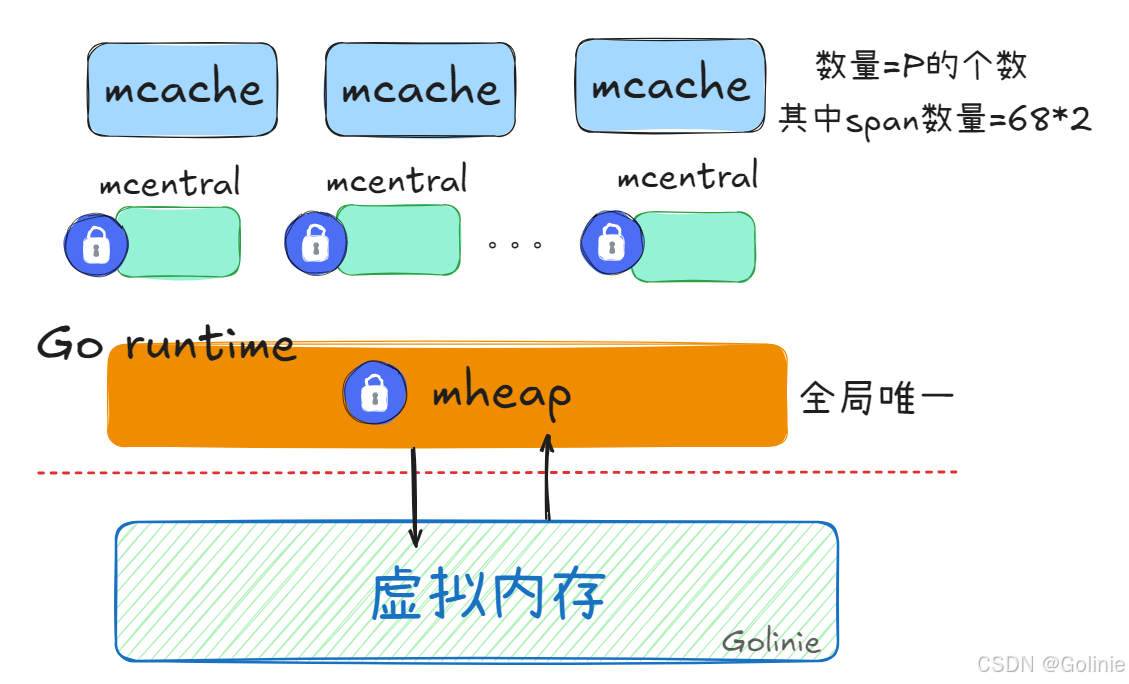
稍微细化一下:
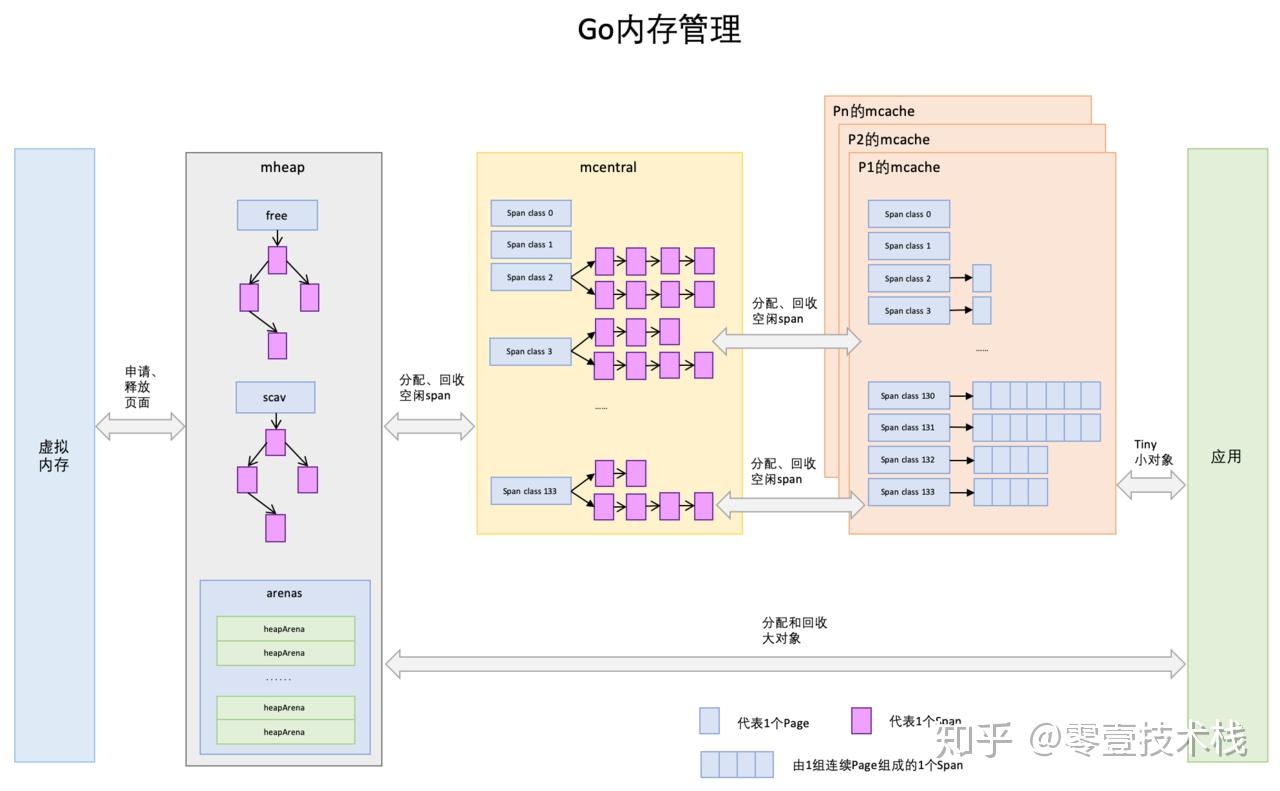
总述:每个 P 都有自己的内存缓存mcache,用于小对象的快速分配。当 mcache 用完时,P 会从中心缓存(mcentral)获取内存。如果 mcentral 也不足,内存分配器会向操作系统请求更多内存。
详解
mspan:内存管理的基本单位。它不是一块简单的内存,而是一个包含起始地址、span规格、页数等信息的结构体。一个mspan是连续内存页的集合,这些页被分割成一个个大小相同的对象(object) 供分配使用。Go预设了约70种不同大小的span规格(class),例如8B, 16B, 24B, …, 32KB,以减少内存碎片。mcache:Per-P(处理器)级别的本地缓存。这是实现无锁快速分配的关键。每个P都有一个mcache。当Goroutine需要分配小对象(通常<=32KB)时,它会直接从当前P的mcache中获取所需的mspan。因为这个缓存是P本地的,所以此操作完全无需加锁。mcentral:全局的中心缓存。它为所有mcache提供后备支持。每种规格的span都有对应的两个mcentral:partial sweep:包含至少一个未分配对象的空闲mspan链表。full sweep:不包含任何空闲对象的mspan链表(已被分配完)。
当mcache中某个规格的span用完了,它不会立即向操作系统申请,而是先到对应规格的mcentral中去申请一个新的mspan。访问mcentral需要加锁。
mheap:堆内存的抽象,管理着所有的操作系统内存。当mcentral中的mspan也不够用时,mheap会向操作系统申请新的内存(通常以一大块连续内存页,即arena为单位)。mheap中还维护着空闲内存页的基数树(radix tree)结构,用于查找和合并空闲内存,避免碎片化。
Golang 内存分配的机制
对象大小分类
Go 将对象按大小分为三类,采用不同的分配策略:
- 微小对象 (Tiny objects, <16B):使用特殊的 tiny allocator,将多个微小对象合并到一个 16B 的内存块中,极大减少内存浪费
- 小对象 (Small objects, 16B ~ 32KB):通过 mcache -> mcentral -> mheap 的三级分配器进行分配
- 大对象 (Large objects, >32KB):直接从 mheap 分配,绕过前两级缓存
大小类 (Size Class)
Go 定义了约 70 种规格等级(Size Class),如 8B、16B、24B、32B、48B…32KB。当分配对象时,会向上取整到最近的规格,用空间换管理效率。
分配流程
- 小对象(一般小于 32KB)的分配:
- 先检查当前 P 的 mcache 中对应规格的 span
- 如果有空闲对象,直接无锁分配
- 如果 mcache 中没有,向 mcentral 申请新的 span
- 如果 mcentral 也没有,向 mheap 申请
- 如果 mheap 页不足,向操作系统申请内存
- 大对象(一般大于 32KB)的分配:
- 直接从 mheap 分配
- 不经过 mcache 和 mcentral 两级缓存
- 分配时需要加锁
内存分配一句话记忆:
能放栈就放栈,必须放堆才走分配器,小对象不能放mcache就向上申请,大对象直连堆。
内存分配优化
- 大小类分配:为了减少内存碎片和提高内存重用,Go 将对象分为不同的大小类。每个大小类的对象都会分配到对应的 span 中。
- 对象对齐:Go 保证对象在内存中对齐,有助于提高 CPU 缓存的效率。
- 批量分配:当 mcache 中的 span 用完时,不是一次只获取一个新的 span,而是批量地从 mcentral 获取多个 span,可以减少与 mcentral 的交互次数。
- 无锁分配:通过 P 级别的 mcache,95%以上的分配操作无需加锁,极大提升并发性能
内存分配的优化实践
为了优化内存分配,可以从以下几个方面着手:
- 重用对象:通过重用对象来减少分配次数。
- 池化资源:使用 sync.Pool 来池化可重用的对象。
- 避免内存逃逸:通过减少指针的使用和闭包捕获来避免不必要的内存逃逸。
- 合理的数据结构:选择合适的数据结构来减少内存的占用和碎片。
- 预分配:对于 slice、map 等,如果知道大致容量,使用 make() 时预先指定容量,避免扩容带来的重新分配
- 值传递 vs 指针传递:小对象使用值传递,避免指针带来的堆分配和GC压力
额外补充:
- sync.Pool 的作用:
sync.Pool 适合存放临时对象(如 buffer、临时切片),GC 会在下一次垃圾回收时清空其中的对象,避免长期占用。 - 减少 GC 压力:
大量小对象逃逸到堆上会导致 GC 频率升高。可以通过减少指针引用、减少闭包、合理使用值传递来降低 GC 压力。
垃圾回收的配合
Go 的垃圾回收器与内存分配器紧密协作:
- 标记阶段:GC 遍历所有根对象,标记所有存活对象
- 清扫阶段:遍历所有mspan,回收未标记对象的内存
- 内存重用:回收的内存不会立即返还操作系统,而是放回 mcentral 或 mheap 的空闲链表供重用
总结
Go 的内存分配体系可以总结为三层:
- 栈分配:goroutine 独占,快速,自动回收;
- 堆分配:基于 tcmalloc 思路的三级分配器(mcache → mcentral → mheap),保证并发性能和低碎片;
- GC 回收:三色标记法 + 并发回收,确保堆对象的自动管理。
–
ref:
详解Go语言的内存模型及堆的分配管理 - 知乎