F006 vue+flask python 垃圾分类可视化系统+爬虫
文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
✅ 编号:F006
数据来源:https://lajifenleiapp.com/sk 网站来 获取数据
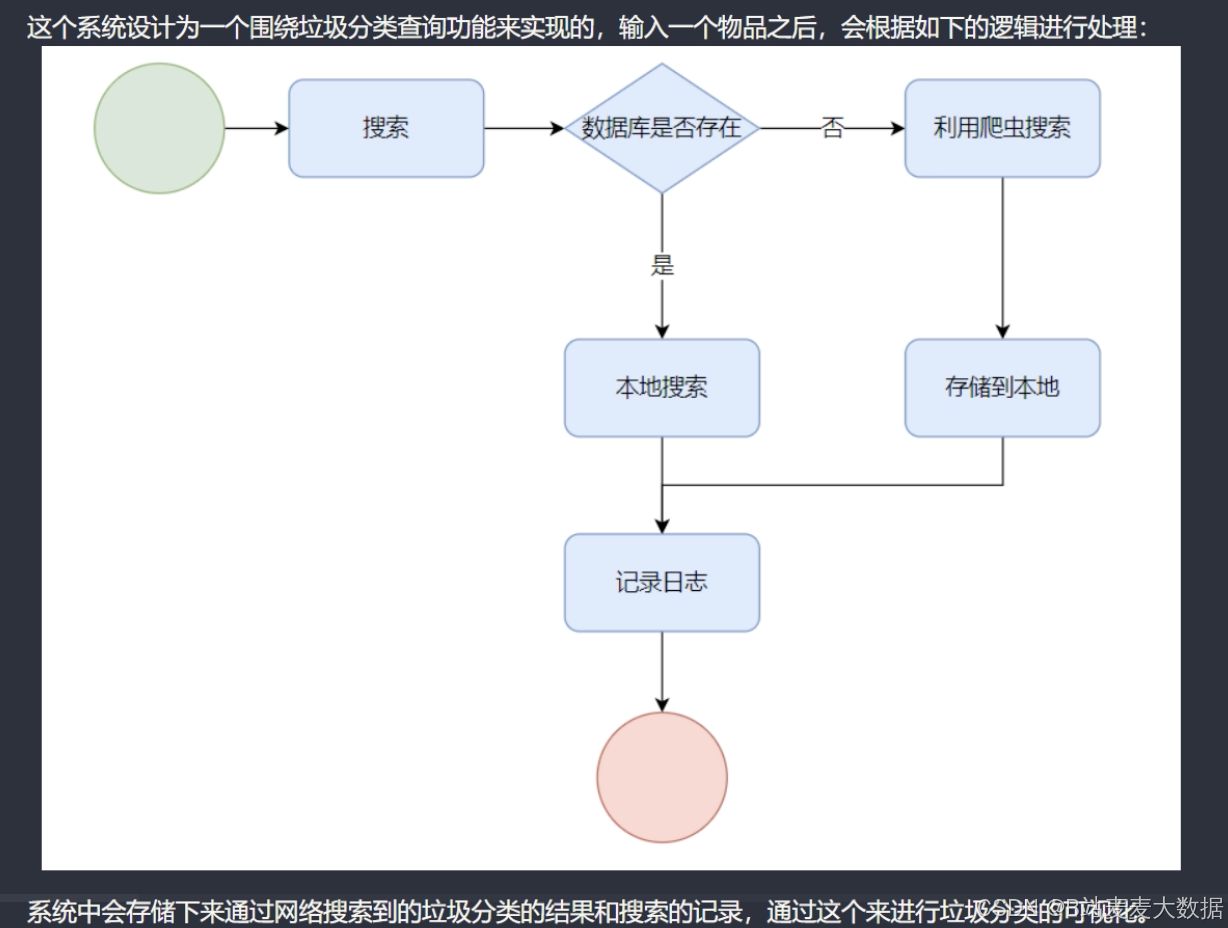
先爬取一部分数据,然后做一个搜索功能,每次搜索之后的结果可以存储到数据库里面
爬取图片可以,还有具体的城市
视频
vue+flask python 垃圾分类可视化
1 功能简介
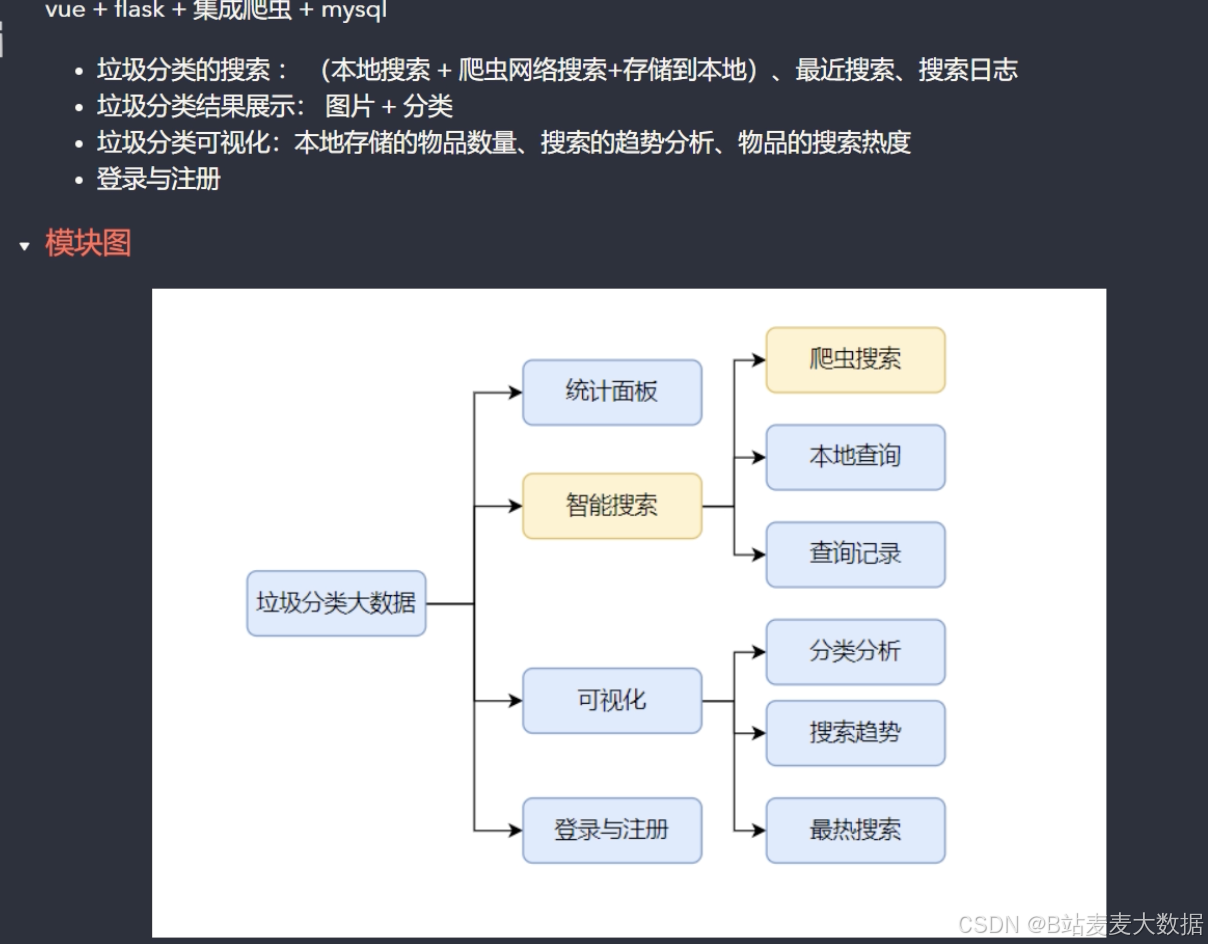
1.1 系统处理流程图
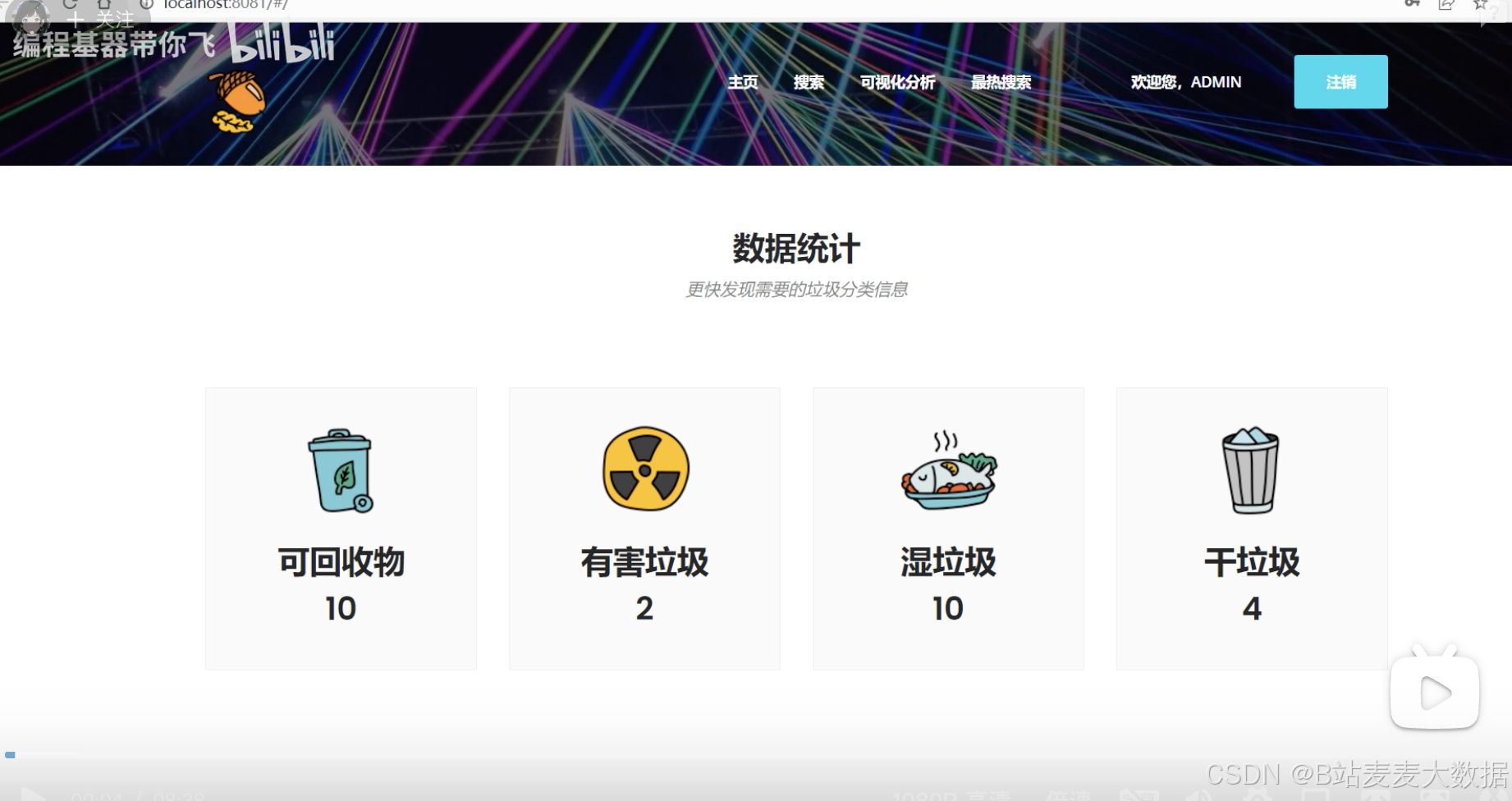
1.2 主页可视化
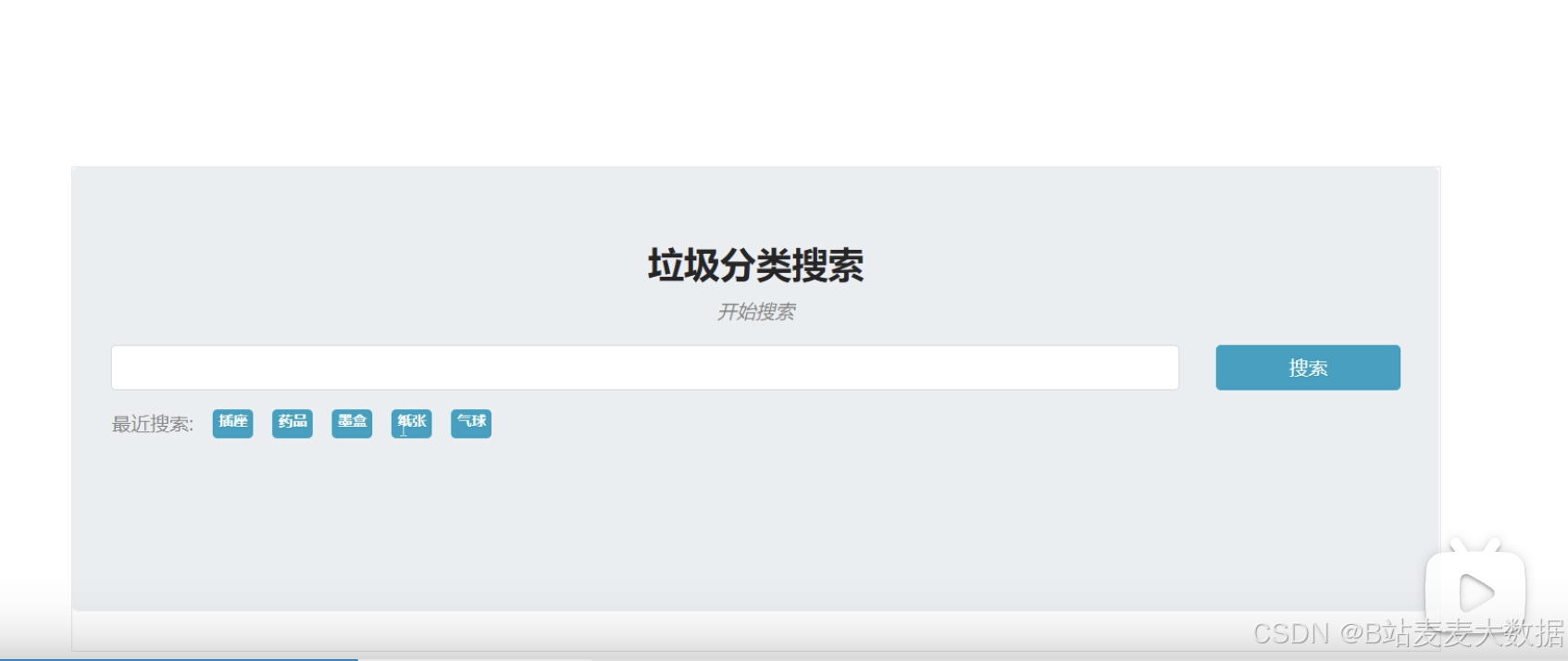
1.3 垃圾分类搜索
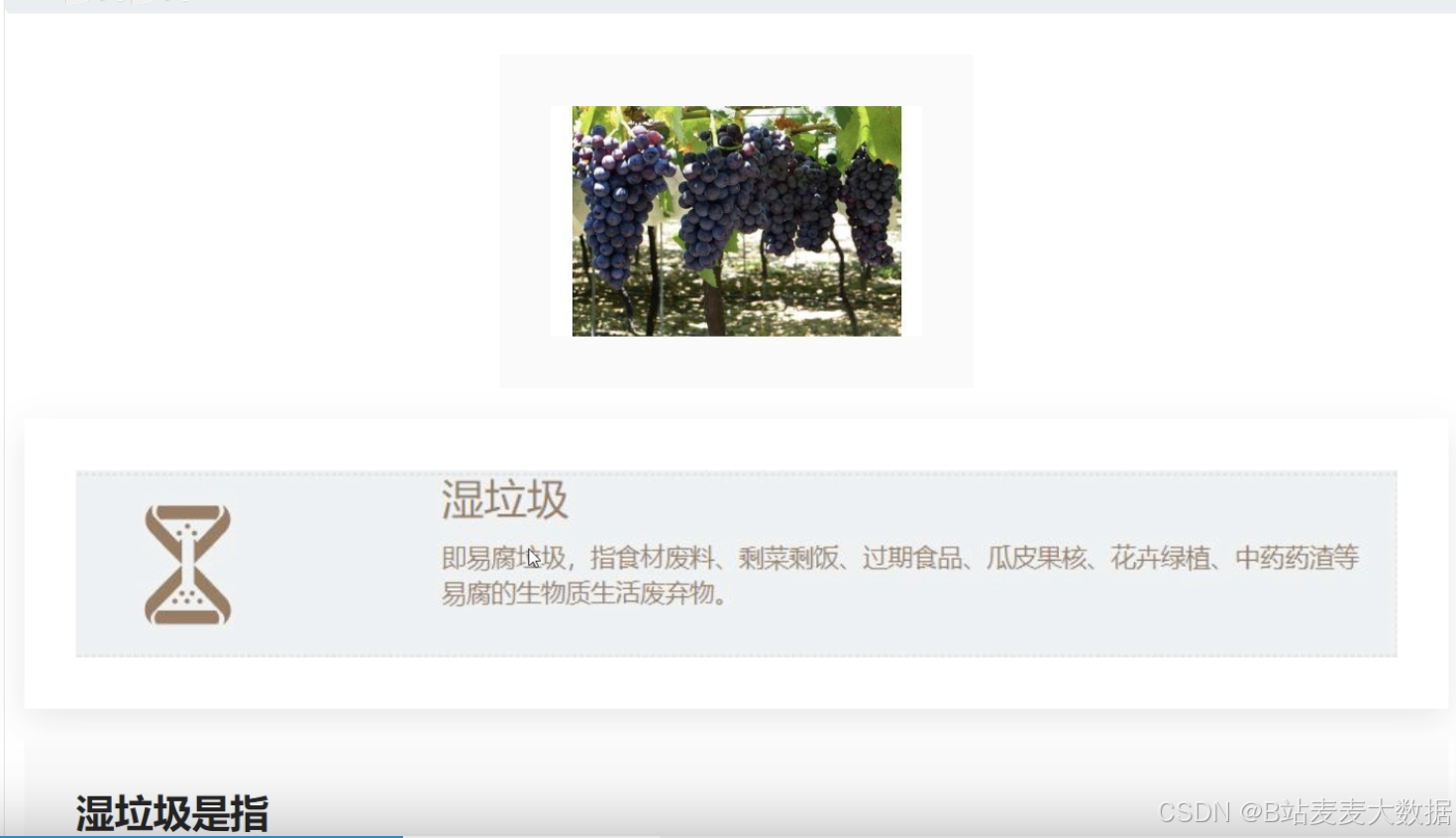
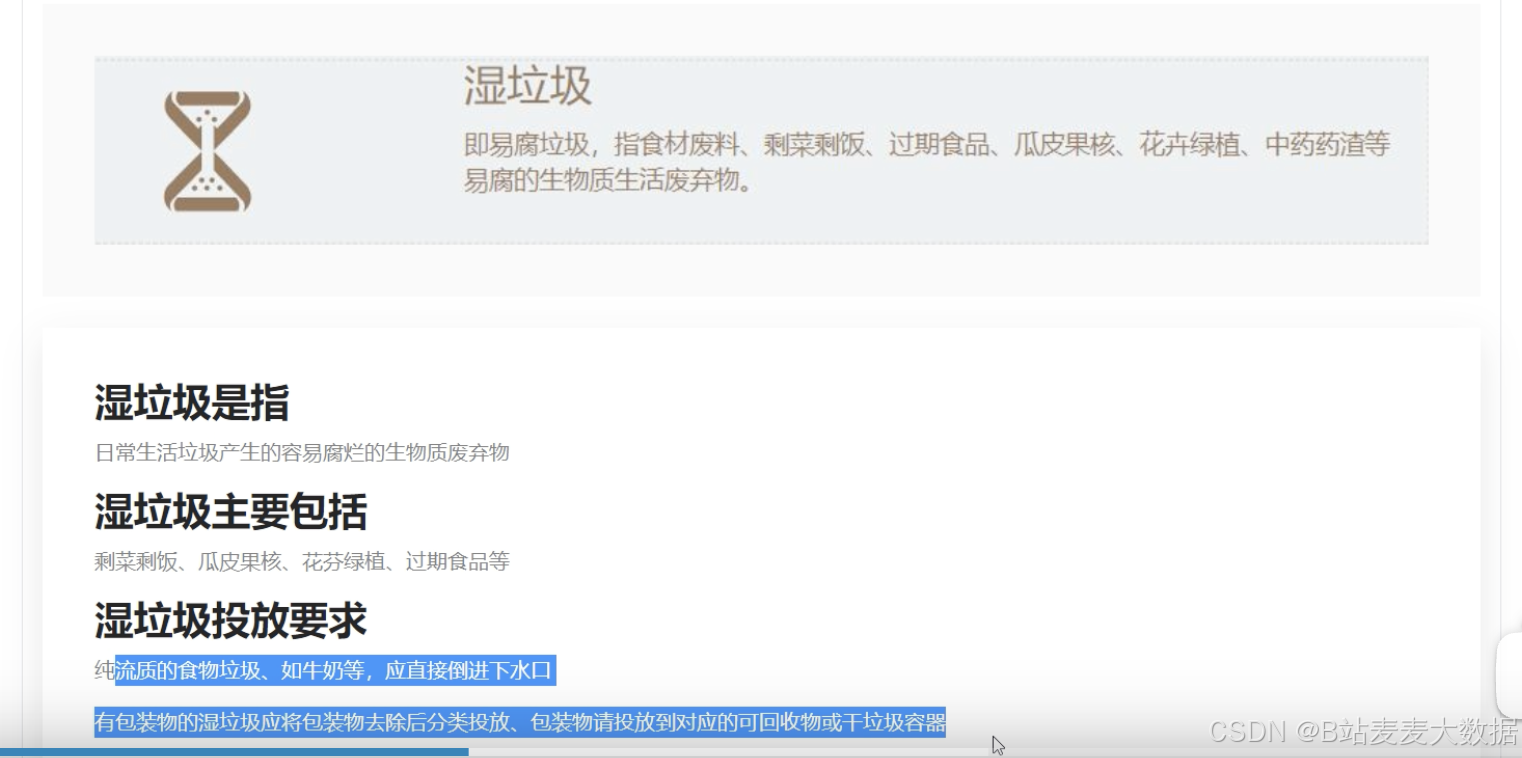
1.4 搜索结果(以葡萄为例)
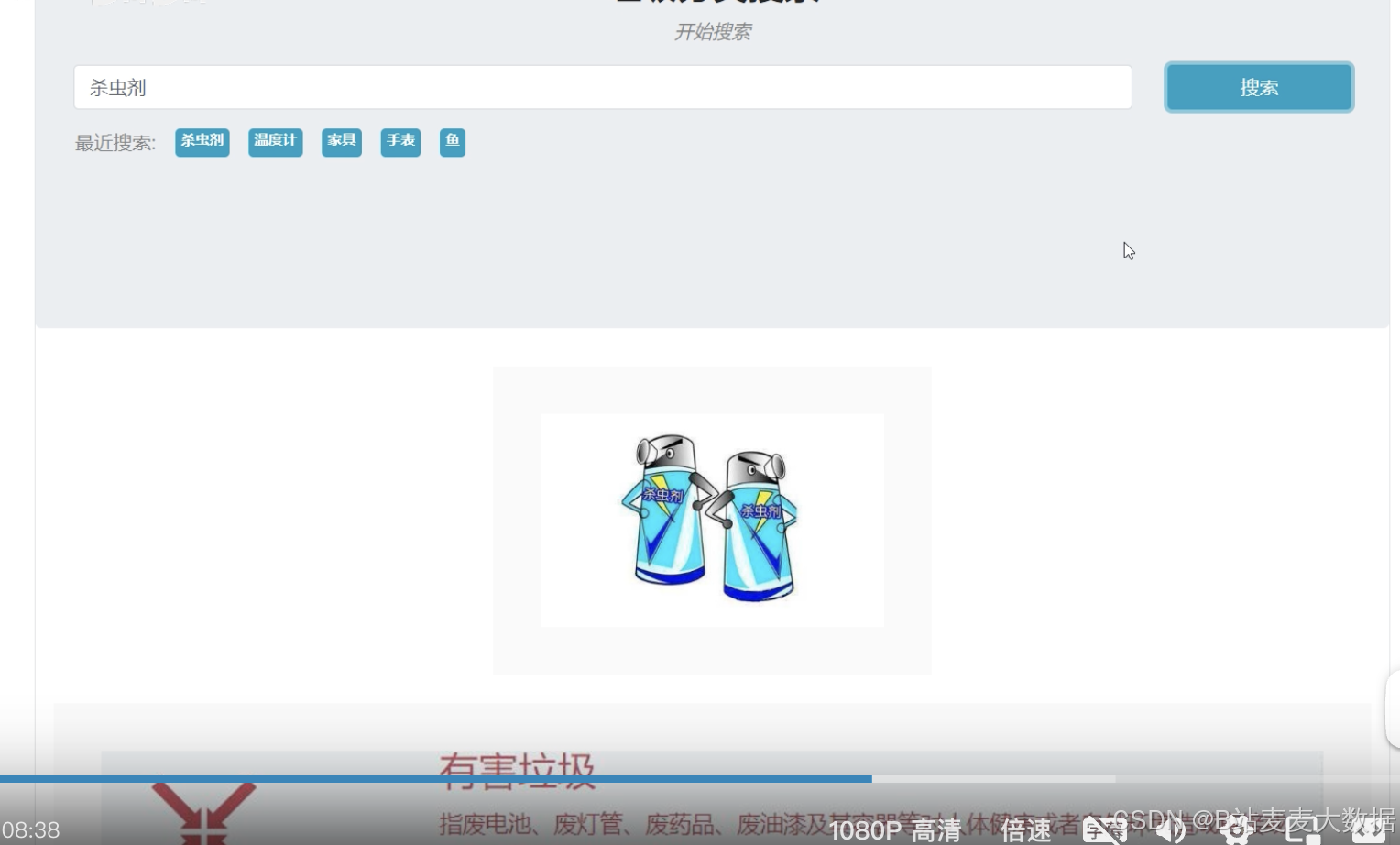
1.4 查询【杀虫剂】
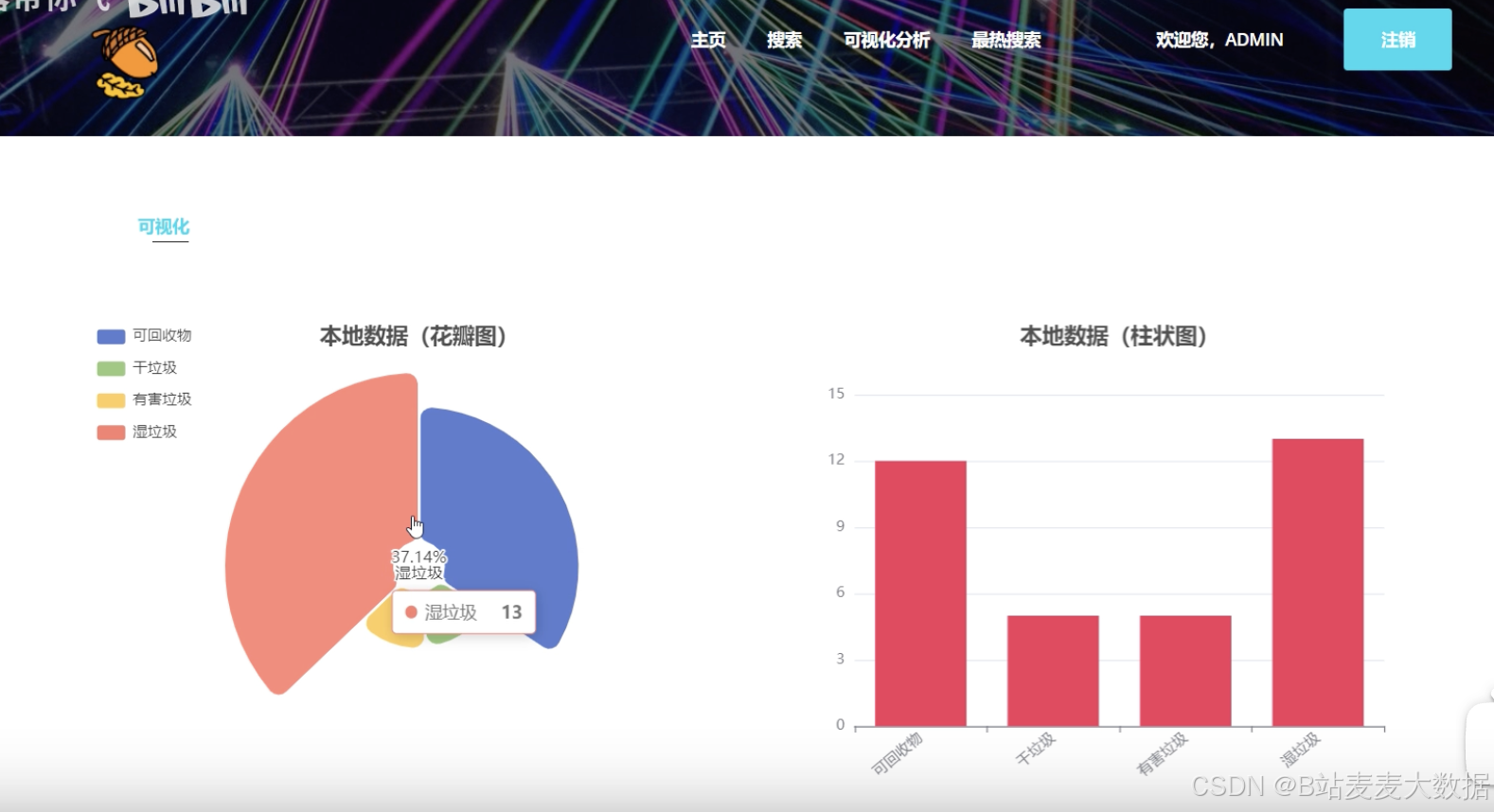
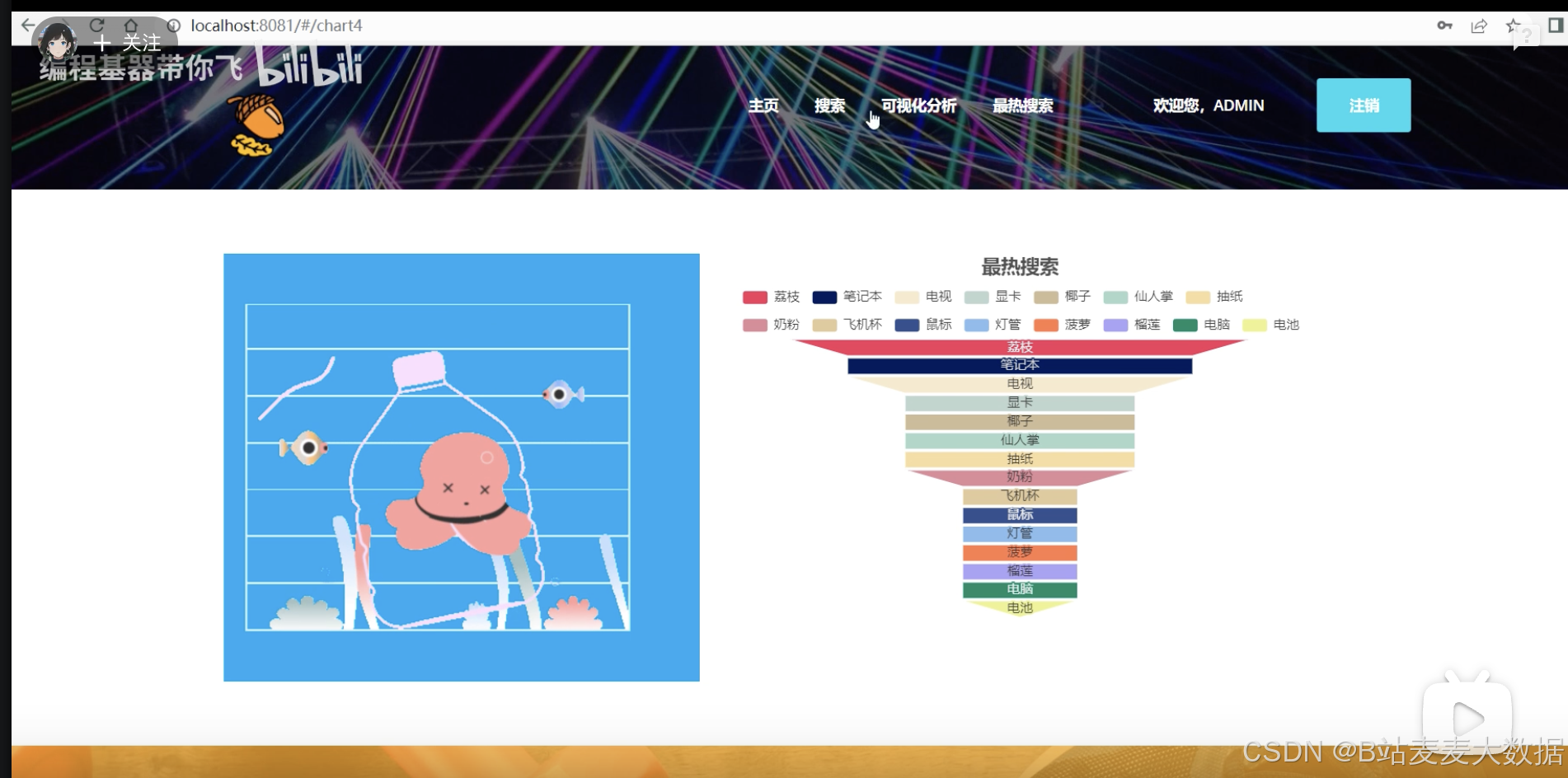
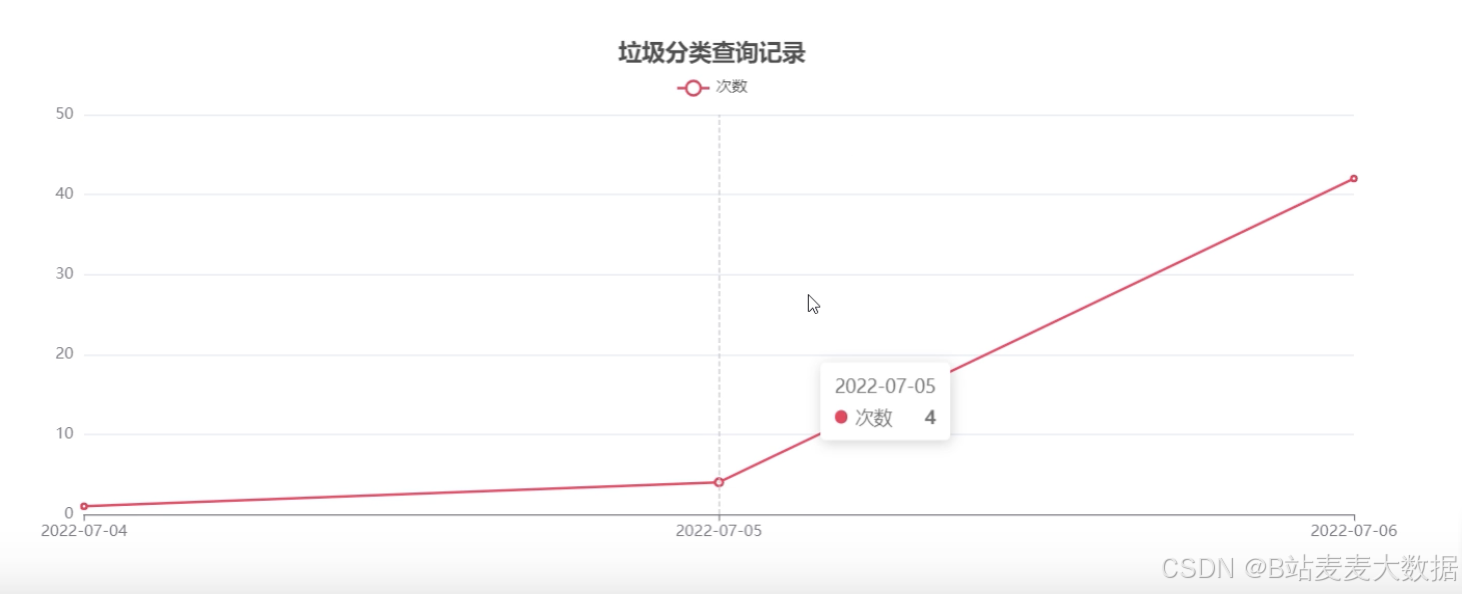
1.5 可视化分析
2 爬取代码
import requests
from bs4 import BeautifulSoup
import random
import time
import mysql.connector
from mysql.connector import Error
from urllib.parse import urljoindef create_database_connection():"""创建和返回数据库连接"""try:connection = mysql.connector.connect(host="localhost",user="your_username",password="your_password",database="garbage_classification")if connection.is_connected():print("成功连接到MySQL数据库")return connectionexcept Error as e:print(f"数据库连接错误: {e}")return Nonedef setup_database():"""设置数据库和表结构"""try:# 先连接而不指定数据库connection = mysql.connector.connect(host="localhost",user="your_username",password="your_password")cursor = connection.cursor()# 创建数据库(如果不存在)cursor.execute("CREATE DATABASE IF NOT EXISTS garbage_classification")cursor.execute("USE garbage_classification")# 创建垃圾分类表create_table_query = """CREATE TABLE IF NOT EXISTS garbage_items (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,category VARCHAR(50) NOT NULL,category_detail VARCHAR(100),description TEXT,source_url VARCHAR(255),created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,UNIQUE(name))"""cursor.execute(create_table_query)print("数据库表已准备好")cursor.close()connection.close()except Error as e:print(f"数据库设置错误: {e}")def get_user_agent():"""返回随机用户代理头"""user_agents = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36"]return {'User-Agent': random.choice(user_agents)}def scrape_category_items(category_url):"""爬取指定分类下的物品列表"""try:print(f"正在爬取分类页面: {category_url}")response = requests.get(category_url, headers=get_user_agent(), timeout=10)soup = BeautifulSoup(response.content, 'html.parser')items = []term_list = soup.find('ul', class_='term-list')if term_list:for item in term_list.find_all('a'):item_name = item.get_text().strip()item_url = urljoin(category_url, item['href'])items.append((item_name, item_url))print(f"找到 {len(items)} 个物品")return itemsexcept Exception as e:print(f"爬取分类错误: {e}")return []def scrape_item_details(item_url):"""爬取物品详细信息"""try:print(f"正在爬取物品详情: {item_url}")response = requests.get(item_url, headers=get_user_agent(), timeout=15)soup = BeautifulSoup(response.content, 'html.parser')# 获取物品名称name = soup.find('h1', class_='term-title').get_text().strip() if soup.find('h1', class_='term-title') else ""# 获取垃圾分类信息category_span = soup.find('span', class_='term-category')category = category_span.find('a').get_text().strip() if category_span and category_span.find('a') else "未知"# 获取类别细节(如可回收物中的纸张类)category_detail_tag = soup.find('span', class_='term-type')category_detail = category_detail_tag.get_text().strip() if category_detail_tag else ""# 获取描述信息description_tag = soup.find('div', class_='term-description')description = description_tag.get_text().strip() if description_tag else ""return {'name': name,'category': category,'category_detail': category_detail,'description': description,'source_url': item_url}except Exception as e:print(f"爬取物品详情错误: {e}")return {}def save_to_database(connection, item_data):"""将物品数据保存到数据库"""try:cursor = connection.cursor()# 检查记录是否已存在check_query = "SELECT id FROM garbage_items WHERE name = %s"cursor.execute(check_query, (item_data['name'],))existing = cursor.fetchone()if existing:print(f"物品已存在,跳过: {item_data['name']}")return False# 插入新记录insert_query = """INSERT INTO garbage_items (name, category, category_detail, description, source_url) VALUES (%s, %s, %s, %s, %s)"""cursor.execute(insert_query, (item_data['name'],item_data['category'],item_data['category_detail'],item_data['description'],item_data['source_url']))connection.commit()print(f"保存成功: {item_data['name']} ({item_data['category']})")return Trueexcept Error as e:print(f"数据库保存错误: {e}")return Falsedef main():# 设置数据库setup_database()connection = create_database_connection()if not connection:print("无法连接到数据库,程序终止")returnbase_url = "https://lajifenleiapp.com/sk"try:# 获取主页面response = requests.get(base_url, headers=get_user_agent(), timeout=10)soup = BeautifulSoup(response.content, 'html.parser')# 查找所有分类的链接category_links = []category_nav = soup.find('div', class_='alpha-container')if category_nav:for link in category_nav.find_all('a'):category_links.append(urljoin(base_url, link['href']))# 添加热门分类(如果需要)popular_section = soup.find('div', class_='popular-terms')if popular_section:for link in popular_section.find_all('a'):full_url = urljoin(base_url, link['href'])if full_url not in category_links:category_links.append(full_url)print(f"找到 {len(category_links)} 个分类")# 处理每个分类for category_url in category_links:items = scrape_category_items(category_url)for item_name, item_url in items:item_data = scrape_item_details(item_url)if item_data:save_to_database(connection, item_data)# 随机延迟防止被封time.sleep(random.uniform(1.0, 3.0))except Exception as e:print(f"主函数错误: {e}")finally:if connection and connection.is_connected():connection.close()print("数据库连接已关闭")if __name__ == "__main__":main()