【NER学习笔记】:基于AdaSeq的NER模型训练笔记
基于AdaSeq的NER模型训练笔记
github:/modelscope/AdaSeq
魔塔模型:RaNER命名实体识别-中文-新闻领域-base
前提:github 拉 AdaSeq 项目
一、AdaSeq的demo训练推理测试
0、报错记录(已解决!)
报错1:AttributeError: ‘Dataset’ object has no attribute ‘_hf_ds’
Adaseq 框架已未维护,依赖包 datasets 库未指定版本,导致存在一些不适配,多方调查测试解决了这个问题
报错2:ValueError: unknown url type: ‘adaseq-0.6.6-py3-none-any.whl.metadata’
这是训练模型后,进行模型推理的报错,需要重新下载插件,替换路径
1、更新依赖包
datasets==2.16.0
Pillow
修改依赖包后下载依赖
pip install -r requirements.txt -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
2、环境下代码改动
参考路径:/anaconda3/envs/adaseq/lib/python3.10/site-packages/modelscope/utils/checkpoint.py
checkpoint.py 124行,改动后:
checkpoint = torch.load(filename, map_location='cpu', weights_only=False)
参考路径:/anaconda3/envs/adaseq/lib/python3.10/site-packages/adaseq/data/dataset_manager.py
dataset_manager.py 193行,改动后:
datasets = {k: getattr(v, '_hf_ds', v) for k, v in msdataset.items()}
3、训练模型
demo.yaml 为默认配置文件
adaseq train -c demo.yaml
训练完成显示
...
Total test samples: 100%|███████████████████████████████████████████████████████████████████| 80/80 [00:00<00:00, 1065.52it/s]
Total test samples: 100%|███████████████████████████████████████████████████████████████████| 80/80 [00:00<00:00, 1026.80it/s]
Total test samples: 100%|████████████████████████████████████████████████████████████████████| 80/80 [00:00<00:00, 305.92it/s]
2025-08-26 10:11:14,864 - INFO - adaseq.training.default_trainer - test: {"precision": 0.8,"recall": 0.6896551724137931,"f1": 0.7407407407407408,"accuracy": 0.8324022346368715
}

4、模型推理
下载插件:adaseq-0.6.6-py3-none-any.whl
调用本地训练好的模型,找到最佳训练模型的配置文件 configuration.json
参考路径:/AdaSeq/experiments/resume/250716164951.721455/output_best/configuration.json
experiments:存放训练结果的目录
resume:配置文件里设置的项目名
250716164951.721455:训练日期时间
找到 plugins:
"plugins": ["adaseq"
]
修改后:(插件下载到本地的绝对路径)
"plugins": ["/Downloads/adaseq-0.6.6-py3-none-any.whl"
]
运行推理代码:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasksp = pipeline(Tasks.named_entity_recognition,'/AdaSeq/experiments/resume/250716164951.721455/output_best', # 绝对路径
)
result = p('1984年出生,中国国籍,汉族,硕士学历')print(result)
输出
{'output': [{'type': 'NAME', 'start': 0, 'end': 5, 'prob': 0.93576854, 'span': '1984年'}, {'type': 'CONT', 'start': 8, 'end': 12, 'prob': 0.025677418, 'span': '中国国籍'}, {'type': 'RACE', 'start': 13, 'end': 15, 'prob': 0.3731443, 'span': '汉族'}, {'type': 'EDU', 'start': 16, 'end': 20, 'prob': 0.36481333, 'span': '硕士学历'}]}
二、自定义数据训练推理
LabelStudio 使用教程参考:LabelStudio数据标注详细方法
使用 Label Studio 标注好数据,以 JSON-MIN 导出
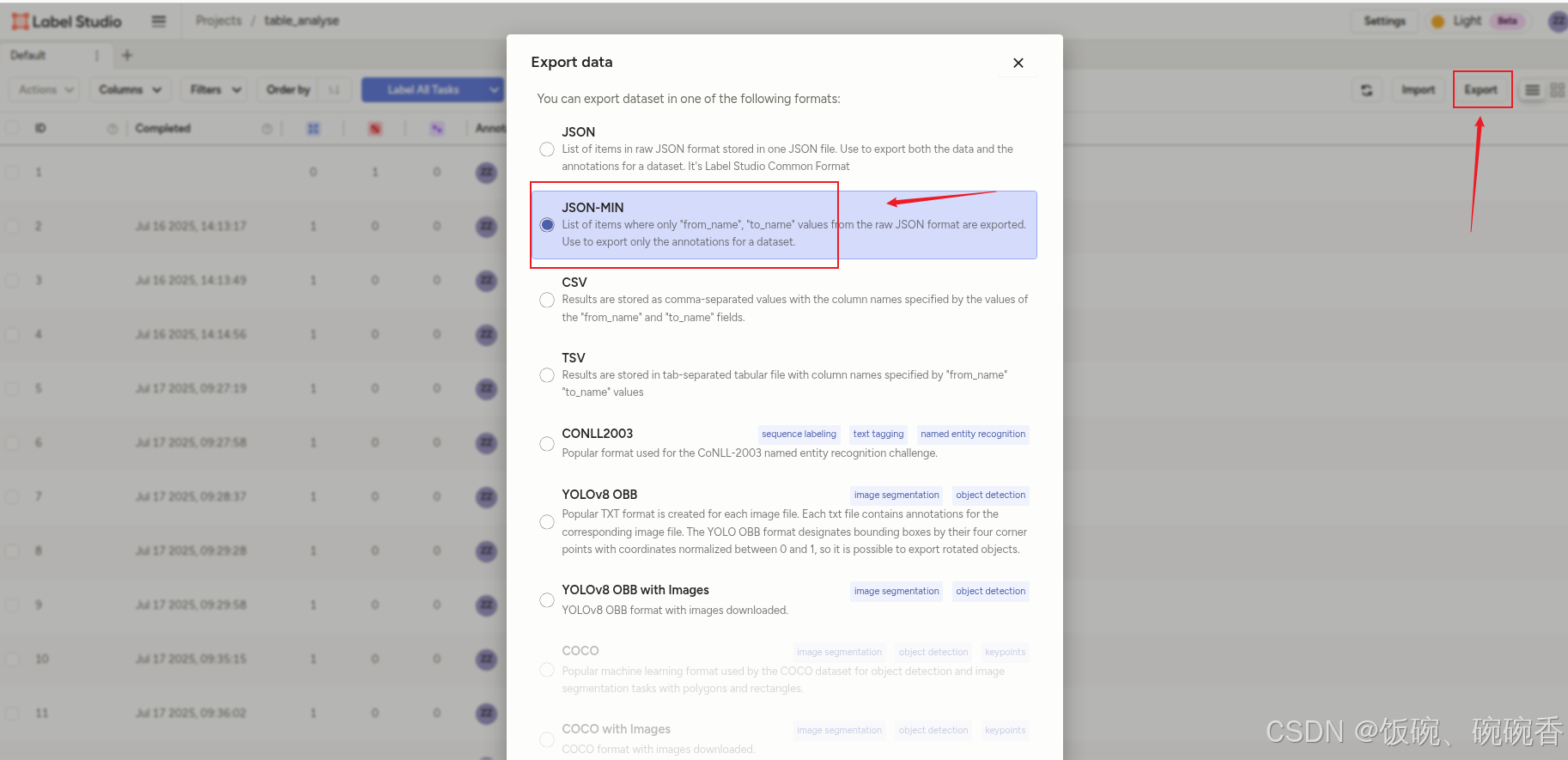
1、JSON-MIN数据格式示例
[{"text": "xxxx中心xx组x部x月与y月xxxxxx问题","id": 2,"label": [{"start": 0,"end": 6,"text": "xxxx中心","labels": ["ORG"]},{"start": 6,"end": 9,"text": "xx组","labels": ["GROUP"]},{"start": 9,"end": 11,"text": "x部","labels": ["DEPT"]},{"start": 11,"end": 13,"text": "x月","labels": ["DATE"]},{"start": 18,"end": 20,"text": "y月","labels": ["DATE"]},{"start": 20,"end": 28,"text": "xxxxxx问题","labels": ["QUERY"]}],"annotator": 1,"annotation_id": 2,"created_at": "2025-07-16T06:13:17.245421Z","updated_at": "2025-07-16T06:13:17.245434Z","lead_time": 52.428},...
]
2、数据标签说明
这是自定义用的标签
ORG:xx中心
GROUP:xx组
DEPT:x部
USERNAME:用户名
DATE:时间
BATCH:批次
QUERY:问题
DIM:用户名/部门/批次
3、标签JSON转CONLL
1)python 代码完成 JSON-MIN 转 CONLL 数据格式
import json# 读取 JSON 文件
def read_json_file(file_path):with open(file_path, 'r', encoding='utf-8') as file:return json.load(file)# 将 JSON 数据转换为 CONLL 格式(BIO 标注)
def convert_to_conll(json_data):conll_data = []for entry in json_data:text = entry['text']labels = entry['label']words = list(text)conll_entry = []# 标签的初始化:默认所有字符为 Olabel_list = ['O'] * len(words)# 给每个字符标注 B/I/Efor label_entry in labels:start, end = label_entry['start'], label_entry['end']entity_label = label_entry['labels'][0] # 获取标签,假设是一个标签# 为实体的第一个字符标注 B,最后一个字符标注 E,其他字符标注 Ifor i in range(start, end):if i == start:label_list[i] = f'B-{entity_label}' # 开始elif i == end - 1:label_list[i] = f'E-{entity_label}' # 结束else:label_list[i] = f'I-{entity_label}' # 中间部分# 组合为 CONLL 格式for word, label in zip(words, label_list):conll_entry.append(f"{word}\t{label}")conll_data.append("\n".join(conll_entry))return "\n\n".join(conll_data)# 将 CONLL 数据写入文件
def write_conll_to_file(conll_data, output_file_path):with open(output_file_path, 'w', encoding='utf-8') as file:file.write(conll_data)# 主函数
def main():input_json_file = 'input.json'output_conll_file = 'output.txt'json_data = read_json_file(input_json_file)conll_data = convert_to_conll(json_data)write_conll_to_file(conll_data, output_conll_file)print(f"CONLL数据转换成功:{output_conll_file}")if __name__ == '__main__':main()2)CONLL数据格式说明
语法:IOBES注释-标签名,IOBES 注释含义
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- E,即End,表示结尾
- S,即Single,表示单个字符
- O,即Other,表示其他,用于标记无关字符
示例
现 O
任 O
中 B-ORG
国 I-ORG
建 I-ORG
设 I-ORG
银 I-ORG
行 I-ORG
江 I-ORG
阴 I-ORG
支 I-ORG
行 I-ORG
行 B-TITLE
长 I-TITLE
4、训练数据分配
数据分配:测试、训练、验证
test: /AdaSeq/dataset/emo_analysis/test.txt
train: /AdaSeq/dataset/emo_analysis/train.txt
valid: /AdaSeq/dataset/emo_analysis/valid.txt
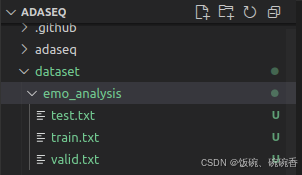
配置yaml文件数据集改为本地文件
dataset:data_file:test: /AdaSeq/dataset/emo_analysis/test.txttrain: /AdaSeq/dataset/emo_analysis/train.txtvalid: /AdaSeq/dataset/emo_analysis/valid.txtdata_type: conll5、调整项目名、模型、超参数等(可选)
参数改动
experiment-->exp_name
model-->embedder-->model_name_or_pathtrain
-->max_epochs
-->dataloader-->batch_size_per_gpu
-->lr_schedulerevaluation-->metrics
-->dump_format
-->model_type
-->type
6、训练验证模型
训练命令
adaseq train -c emo_analysis.yaml

推理输出
{'output': [{'type': 'ORG', 'start': 2, 'end': 8, 'prob': 0.9849806, 'span': 'xxxx中心'}, {'type': 'GROUP', 'start': 8, 'end': 11, 'prob': 0.17277028, 'span': 'xx组'}, {'type': 'DEPT', 'start': 11, 'end': 13, 'prob': 0.13815865, 'span': 'x部'}, {'type': 'DATE', 'start': 13, 'end': 18, 'prob': 0.15100664, 'span': '6月12日'}, {'type': 'DATE', 'start': 21, 'end': 26, 'prob': 0.01192809, 'span': '5月12日'}, {'type': 'QUERY', 'start': 26, 'end': 32, 'prob': 0.14288208, 'span': 'xxxx问题'}]}

写在最后
AdaSeq github 开源项目提供的训练指南挺全面的,其中包含配置 yaml 参数说明、如何训练、如何推理等,主要难点在于项目已两三年未更新,存在库版本不兼容问题,也没一个合理的解决方案,误打误撞解决了这个问题,记录一下