从字节码层面剖析以太坊智能合约创建原理
1. 引言
阅读完本文之后,将能理解一下字节码含义:
608060405260405160893803806089833981016040819052601e916025565b600055603d565b600060208284031215603657600080fd5b5051919050565b603f80604a6000396000f3fe6080604052600080fdfea26469706673582212204a131c1478e0e7bb29267fd8f6d38a660b40a25888982bd6618b720d4498b6b464736f6c634300080700330000000000000000000000000000000000000000000000000000000000000001
本文解释了:
- 以太坊智能合约在 字节码层面 是如何被构造的,
- 以及构造函数参数是如何被解释的。
本文基本结构为:
- Solidity 中的 creationCode
- 初始化代码(Init code)
- 可支付(payable)构造函数合约
- 不可支付(non-payable)构造函数合约
- 运行时代码(Runtime code)
- 运行时代码解析
- 带参数的构造函数
从宏观上看,部署合约的钱包会向 空地址(null address) 发送一笔交易,交易数据分为三部分:
<init code> <runtime code> <constructor parameters>
三者合起来被称为 创建代码(creation code)。EVM 会首先执行 init code。如果 init code 编码正确,这段执行会把运行时代码存储到区块链上。
在 EVM 规范中,并没有强制要求布局必须是 init code、runtime code 和 constructor parameters。理论上可以是 init code、constructor parameters 然后 runtime code。这只是 Solidity 的约定。但是 init code 必须在最前面,否则 EVM 不知道从哪里开始执行。
本文假设读者已经了解以下内容:
- Solidity(可参看 Solidity 免费教程)。
- EVM 操作码基础
2. Solidity 中的 creationCode
Solidity 提供了一个机制,可以通过 creationCode 关键字获取合约创建交易中要部署的字节码。示例如下:
contract ValueStorage { uint256 public value; constructor(uint256 value_) { value = value_; }
}contract GetCreationCode { function get() external returns (bytes memory creationCode) { creationCode = type(Simple).creationCode; }
}
需要注意的是,这 不包含构造函数参数。参数会作为合约部署过程中运行的字节码一部分附加上去。至于 init code(creationCode)和参数是如何组织的,本文将进行解释。
3. Init code(初始化代码)
init code 是创建代码的一部分,负责部署合约。先看一个最简单的智能合约。稍后会解释为什么要加上一个 payable 构造函数。
3.1 Init code(初始化代码)——可支付(Payable)构造函数合约
pragma solidity 0.8.17; // optimizer: 200 runs
contract Minimal { constructor() payable {}
}
要获得编译结果,可以在 Remix 部署交易后,复制交易输入中的 “input” 字段来获取交易创建字节码:
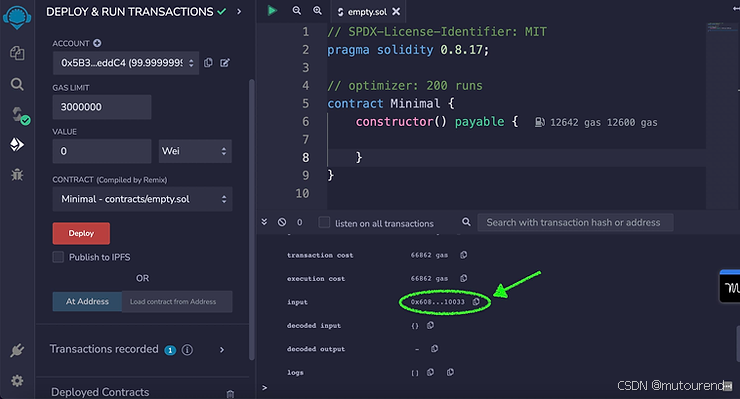
复制出高亮部分后,得到:
0x6080604052603f8060116000396000f3fe6080604052600080fdfea2646970667358221220d03248cf82928931c158551724bebac67e407e6f3f324f930c4cf1c36e16328764736f6c63430008110033
当然,这串字节码很难直接阅读。但可以把它拆成两部分。
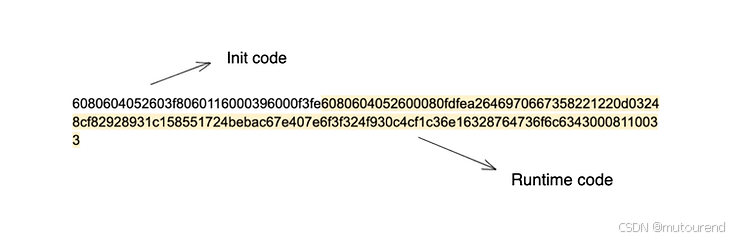
看起来似乎在随机分割字节码,但稍后会更清楚地解释。
如果把第一部分复制到 EVM Codes,并把字节码转换为助记符(mnemonics),就会得到以下输出(已添加注释):
// 分配自由内存指针
PUSH1 0x80
PUSH1 0x40
MSTORE// 运行时代码的长度
PUSH1 0x3f
DUP1// 运行时代码开始的位置
PUSH1 0x11
PUSH1 0x00 // 从 calldata 复制运行时代码到内存
CODECOPY// 此步骤会部署运行时代码
PUSH1 0x00
RETURN
INVALID
在上图中被高亮的部分就是 运行时代码,其大小为 63 字节(十六进制 0x3f)。它从内存的第 17 个索引(十六进制 0x11)开始。这也解释了上面助记符解析中 0x3f 和 0x11 的来源。
从宏观上看,这段 init code 中主要做了三件事:
- 设置自由内存指针(用于记录下一个可写入的内存位置)。
- 使用
CODECOPY操作码把运行时代码复制到该内存位置。 - 最后,把包含运行时代码的内存区域返回给 EVM,EVM 会把它存储为新合约的运行时字节码。
3.2 Init code(初始化代码)——不可支付(Non-payable)构造函数合约
pragma solidity 0.8.17; // optimizer: 200 runs
contract Minimal {constructor() {}
}
来看一下当构造函数不是 payable 时生成的字节码,并分析其中的区别。以下是编译器的输出:
6080604052348015600f57600080fd5b50603f80601d6000396000f3fe6080604052600080fdfea2646970667358221220a6271a05446e269126897aea62fd14e86be796da8d741df53bdefd75ceb4703564736f6c63430008070033
将其拆分为 初始化代码(init code) 和 运行时代码(runtime code),如下图所示:

把 payable 和 nonpayable 的 init code 放在一起对比:
0x6080604052603f8060116000396000f3fe // payable
0x6080604052348015600f57600080fd5b50603f80601d6000396000f3fe // nonpayable
可以注意到:payable 合约的 init code 更短,而 non-payable 的要长一些。
将较长的字节序列(non-payable)放入 EVM playground,得到如下输出(已加上注释):
// 初始化自由内存指针
PUSH1 0x80
PUSH1 0x40
MSTORE // 检查发送的以太数量(wei)
CALLVALUE
DUP1
ISZERO // 跳转到 0x0f(合约部署步骤)
PUSH1 0x0f
JUMPI // 如果发送了 wei > 0,就 revert
PUSH1 0x00
DUP1
REVERT // 跳转目标 (0x0f)
JUMPDEST
POP // 运行时代码长度
PUSH1 0x3f
DUP1 // runtime code 开始位置
PUSH1 0x1d
PUSH1 0x00
CODECOPY
PUSH1 0x00
RETURN
INVALID
接下来,将解释“Payable 与 Non-payable 构造函数的区别”,以便于深入理解以上初始化代码的区别。
-
1)非 payable 构造函数会在部署时校验 callvalue
-
init code 会在 callvalue > 0 时 revert,否则继续执行。
-
在 non-payable 的合约中,会额外插入一段 12字节 的字节码序列:
348015600f57 600080fd 5b50它位于初始化内存指针和返回 runtime code 的字节码之间:
<init bytecode> <额外12字节序列> <返回runtime字节码> <runtime字节码>这段额外的代码负责检查在部署时是否附带了 value(wei)。
- 如果发送了 wei,就 revert。
- 如果没发送 wei,就继续部署 runtime code。
其中:
348015600f57→ 检查 value 是否为 0,否则跳转。600080fd→ 否则revert。5b50→ JUMPDEST + POP。POP用于丢弃 callvalue(因为它还在栈上,不再需要)。
JUMPDEST是跳转目标,没有它的话,JUMP 或 JUMPI 无法落地,会导致 revert。
-
-
2)运行时代码的内存偏移不同
注意:runtime code 的长度没有变化,但 拷贝的偏移量 变了。
因为 non-payable 的 init code 更长,所以 runtime code 被推后了。- Non-payable 的偏移量:
0x1d - Payable 的偏移量:
0x11
差值:
0x1d – 0x11 = 0x0c(即 12),这正好对应那段额外的检查字节序列。 - Non-payable 的偏移量:
4. 运行时代码
4.1 空合约的运行时代码
即便合约是空的(没有函数),runtime code 依然不是空的。
原因是 solidity 编译器会在运行时代码后附加合约的元数据。
fe(INVALID) 会被加在元数据之前,防止其被当成可执行字节码。
更多合约元数据信息,可参看:Solidity metadata.json playground。
(在 Solidity 0.8.18 中,引入了 --no-cbor-metadata 编译选项,可以不在合约字节码中附加这些元数据。)
4.1.1 在纯 Yul 合约中,编译器默认不会添加元数据
如果合约是用纯 Yul 编写的,那么它将没有元数据。
但是,可以通过在全局对象中包含 .metadata 来添加元数据。
// 该合约的编译输出默认不会包含元数据
object "Simple" { code { datacopy(0, dataoffset("runtime"), datasize("runtime")) return(0, datasize("runtime")) }object "runtime" { code { mstore(0x00, 2) return(0x00, 0x20) } }
}
编译器的输出如下:
6000600d60003960006000f3fe
转换为助记符(mnemonics)后,得到:
// 将 runtime 代码复制到内存
PUSH1 00
PUSH1 0d
PUSH1 00
CODECOPY // 返回一个零大小的区域,因为没有 runtime 代码
PUSH1 00
PUSH1 00
RETURN
INVALID
在这种情况下,返回的内存区域大小为零,因为既没有 runtime 代码,也没有元数据。
(编译器从 0x0d 开始,复制 0x00 字节的 runtime 代码到内存偏移 0x00 的位置,然后返回 0x00 字节。)
4.2 非空合约的 Runtime 代码
现在给合约加上最简单的逻辑。
pragma solidity 0.8.7;
contract Runtime { address lastSender; constructor () payable {}receive() external payable { lastSender = msg.sender; }
}
其输出的创建代码为:
608060405260578060116000396000f3fe608060405236601c57600080546001600160a01b03191633179055005b600080fdfea2646970667358221220e9b731ab28726d97cbf5219f1e5eaec508f23254c60b15ed1d3456572547c5bf64736f6c63430008070033
可以拆分为:
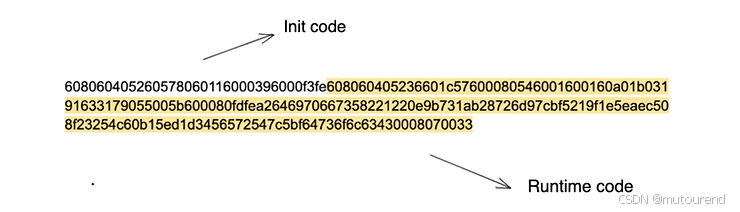
接下来将详细看看其中的 runtime 代码。
由于这是一个 Solidity 合约,可以像之前解释的那样,将其分为 可执行字节码 和 合约元数据。
Runtime code :=
0x608060405236601c57600080546001600160a01b03191633179055005b600080fdfeMetadata :=
0xa2646970667358221220e9b731ab28726d97cbf5219f1e5eaec508f23254c60b15ed1d3456572547c5bf64736f6c63430008070033
使用 evm.codes 输出 来分析 runtime 代码。它已被拆分以便于理解。
首先,初始化空闲内存指针:
[00] PUSH1 80
[02] PUSH1 40
[04] MSTORE
接下来检查交易是否带有数据,如果有,则跳转到程序计数器 (PC) 0x1c 并执行回退(revert)。
合约能够接收数据的合法方式只有两种:调用函数和 fallback。
这里只有 receive 函数,所以没有合法方式接收 calldata。
[05] CALLDATASIZE
[06] PUSH1 1c
[08] JUMPI
然后是存储 msg.sender 的代码:
[09] PUSH1 00
[0b] DUP1
[0c] SLOAD
[0d] PUSH1 01
[0f] PUSH1 01
[11] PUSH1 a0
[13] SHL
[14] SUB
[15] NOT
[16] AND
[17] CALLER
[18] OR
[19] SWAP1
[1a] SSTORE
[1b] STOP
最后,这是当 calldata 被传入时跳转到的 JUMPDEST 0x1c,交易会回退:
[1c] JUMPDEST
[1d] PUSH1 00
[1f] DUP1
[20] REVERT
[21] INVALID
5. 带参数的构造函数
带构造函数参数的合约在编码时会有一些不同。构造函数的参数会被追加到创建代码(creation code)的末尾(在运行时代码 runtime code 之后),并且是以 ABI 编码 的形式追加的。
Solidity 还会额外增加一个检查:
- 确保构造函数参数的长度至少等于预期的构造函数参数长度,否则会直接 revert。
来看一个简单的例子。这里不包含任何运行时代码(runtime code),只在构造函数中写逻辑(构造函数代码不会存在于运行时代码中):
// optimizer: 200
contract MinimalLogic { uint256 private x; constructor (uint256 _x) payable { x = _x; }
}
生成的创建代码是:
608060405260405160893803806089833981016040819052601e916025565b600055603d565b600060208284031215603657600080fd5b5051919050565b603f80604a6000396000f3fe6080604052600080fdfea26469706673582212204a131c1478e0e7bb29267fd8f6d38a660b40a25888982bd6618b720d4498b6b464736f6c63430008070033
拆解:
- Init code(初始化代码):
0x608060405260405160893803806089833981016040819052601e916025565b600055603d565b600060208284031215603657600080fd5b5051919050565b603f80604a6000396000f3fe - Runtime code(仅包含 metadata):
0x6080604052600080fdfea26469706673582212204a131c1478e0e7bb29267fd8f6d38a660b40a25888982bd6618b720d4498b6b464736f6c63430008070033 - 缺少构造函数参数!
如果直接执行这份创建代码,会在 init code 中失败(revert),因为它期望在运行时代码后至少有 32 字节的数据来作为 uint256 _x 的值。
为了解决这个问题,可以把 ABI 编码后的 uint256(1) 追加到创建代码末尾,作为构造函数参数_x。
修正后的字节码:
608060405260405160893803806089833981016040819052601e916025565b600055603d565b600060208284031215603657600080fd5b5051919050565b603f80604a6000396000f3fe6080604052600080fdfea26469706673582212204a131c1478e0e7bb29267fd8f6d38a660b40a25888982bd6618b720d4498b6b464736f6c634300080700330000000000000000000000000000000000000000000000000000000000000001
字节码解析(通过 EVM playground 来演示):
-
1)Step 1: 初始化 free memory pointer
和所有 solidity 合约一样,先用6080604052初始化空闲内存指针。 -
2)Step 2: 获取构造函数参数的长度
// 6040 51 6089 38 03 PC OPCODE[05] PUSH1 40 [07] MLOAD [08] PUSH1 89 [0a] CODESIZE [0b] SUB这里
PUSH1 40 MLOAD会将 自由内存指针(free memory pointer)加载到栈上,以便后续使用。接着通过PUSH1 89将 创建代码长度(不包含构造函数参数部分) 压入栈中,然后调用CODESIZE(它包含了构造函数参数)。通过两者相减来得到 构造函数参数的长度。 -
3)Step 3: 把构造函数参数复制到内存
// 80 6089 83 39 PC OPCODE[0c] DUP1 [0d] PUSH1 89 [0f] DUP4 [10] CODECOPY这里为 CODECOPY 做栈准备。首先使用
DUP1复制前面减法得到的结果,然后通过PUSH1 89将 创建代码长度(不包含构造函数参数) 压入栈中。最后,使用DUP4将内存偏移量放到栈顶。现在调用 CODECOPY,把构造函数参数复制到内存中的 自由内存指针 位置。 -
4)Step 4:更新自由内存指针
在把代码写入内存后,Solidity 会按如下方式更新 自由内存指针:// 81 01 6040 81 90 52 PC OPCODE[11] DUP2 [12] ADD [13] PUSH1 40 [15] DUP2 [16] SWAP1 [17] MSTORE这里通过把之前复制的 构造函数参数长度 (0x20) 加到 自由内存指针 (0x80) 上来实现更新。然后用
Dup1和Swap1来调整栈结构,最后调用MSTORE 40把新的值 (0xa0) 存储为新的自由内存指针。接下来会有一系列的 动态操作和 JUMP,这些不会顺序执行,而是取决于条件分支。
这些步骤都有编号,可以按编号顺序理解,而不需要自己去找对应的 JUMPDEST。也可以用这个 playground 链接 来运行这个字节码。
-
5)Step 5:跳转到 SSTORE 的 JUMPDEST
// 601e 91 6025 56 PC OPCODE[18] PUSH1 1e [1a] SWAP2 [1b] PUSH1 25 [1d] JUMP // jump to JUMPDEST 0x25在此,想跳转到执行存储构造函数参数的代码位置。
这里先把1e压入栈中。1e对应的正是 SSTORE 实际执行的位置。但在这之前,需要先检查构造函数参数是否至少有 32 字节。这个检查过程从 PC =0x25(即上面的 JUMPDEST)开始。 -
8)Step 8:把构造函数参数存储到存储槽 0
这是JUMPDEST 0x1e。不过要注意,JUMPDEST 0x25会先执行(见下面步骤 6)。
另外要注意,这里是 Step 8,而上一个还是 Step 5。它之所以乱序,是因为只有 Step 6 和Step 7 条件满足后,这里才会真正执行。为了和编译后的字节码保持一致,在这里提前引入。// 5b 6000 55 603d 56 PC OPCODE[1e] JUMPDEST [1f] PUSH1 00 [21] SSTORE [22] PUSH1 3d [24] JUMP这里把
0x00压栈,作为存储槽编号,把_x存入其中,然后调用 SSTORE。接着压入0x3d,作为最后一次 CODECOPY 和 RETURN 的跳转目标。 -
6)Step 6:检查构造函数参数是否至少 32 字节
这是JUMPDEST 0x25:// 5b 6000 6020 82 84 PC OPCODE[25] JUMPDEST [26] PUSH1 00 [28] PUSH1 20 [2a] DUP3 [2b] DUP5// continue // 03 12 15 6036 57 [2c] SUB [2d] SLT [2e] ISZERO [2f] PUSH1 36 [31] JUMPI // Jump to 0x36 if ISZERO returns 1// else continue and revert // 6000 80 fd [32] PUSH1 00 [34] DUP1 [35] REVERT这里检查构造函数参数的大小是否至少为 32 字节。
- 先把
0x00压入栈(稍后会用到),再压入最小接受长度0x20 (32 字节)。 - 然后通过之前压入栈的 offset 和 自由内存指针 来计算参数实际长度。
DUP3得到 offsetDUP5得到当前自由内存指针
SUB相减得到长度并压栈。SLT检查是否小于 32 字节,返回 0(不小于)或 1(小于)。ISZERO对结果取反:如果参数长度 >= 32,则结果为 1。- 压入跳转目标
0x36,如果条件满足就跳转,否则执行REVERT来避免无效输入。
- 先把
-
7)Step 7:加载参数到栈,并准备写入存储
这是JUMPDEST 0x36:// 5b 50 51 91 90 50 56 PC OPCODE[36] JUMPDEST [37] POP [38] MLOAD [39] SWAP2 [3a] SWAP1 [3b] POP [3c] JUMP // jump to 0x1e这里先把之前压栈的
0(来自Step 6 的 [26])弹出,因为已经不需要了。
然后:- 使用
MLOAD把构造函数参数加载到栈顶 - 清理掉构造函数参数的内存偏移(已无用)
- 最后
JUMP到0x1e,进入 Step 8,执行真正的存储操作。
- 使用
-
9)Step 9:将运行时代码拷贝到内存并返回
这是JUMPDEST 0x3d,不过上面 JUMPDEST 0x1e 先执行。// 5b 603f 80 604a 6000 39 6000 f3 fe PC OPCODE[3d] JUMPDEST [3e] PUSH1 3f [40] DUP1 [41] PUSH1 4a [43] PUSH1 00 [45] CODECOPY [46] PUSH1 00 [48] RETURN [49] INVALID无执行能力的代码(合约元数据):
0x6080604052600080fdfea26469706673582212204a131c1478e0e7bb29267fd8f6d38a660b40a25888982bd6618b720d4498b6b464736f6c63430008070033这里按惯例从内存中返回合约的运行时代码。
RETURN 执行前的内存布局:
0x00到0x40:空的运行时代码和元数据字节码0x40:自由内存指针0x80:构造函数参数uint256(1)
内存详细分布:
0x00 <- 0x20 = 0x6080604052600080fdfea26469706673582212208f9ffa7a3ab43f0ff61d3033
0x20 <- 0x40 = 0x624bf0e9d398f9a91213656b13d9ffc8fd90fdbc64736f6c63430008070033
0x40 <- 0x60 = 0x0000000000000000000000000000000000000000000000000000000000000a0
0x60 <- 0x80 = 0x00000000000000000000000000000000000000000000000000000000000000
0x80 <- 0xa0 = 0x0000000000000000000000000000000000000000000000000000000000000001
6. 总结
智能合约部署包含了一些低级操作,这些通常被高级语言封装起来。
本文学习了:
- 智能合约如何通过发送 创建代码到零地址 来执行
- 创建代码的不同组成部分及其在部署中的作用
- 各部分如何协同工作完成合约部署
- 构造函数参数如何存储、验证,并用于初始化合约
通过这个流程,可以对智能合约的底层执行有更清晰的理解。
参考资料
[1] RareSkills团队2023年2月博客 Ethereum smart contract creation code