【大语言模型 18】Vision Transformer革命解析:图像理解的范式突破与架构创新
【大语言模型 18】Vision Transformer革命解析:图像理解的范式突破与架构创新
关键词:Vision Transformer、ViT、图像Patch、位置编码、自注意力机制、CNN对比、图像分类、Swin Transformer、层次化设计、归纳偏置、计算机视觉、深度学习、注意力可视化、模型架构、预训练策略
摘要:本文深度解析Vision Transformer(ViT)如何将Transformer架构成功应用于计算机视觉领域,打破了CNN长期统治的局面。通过费曼学习法,从图像处理的根本挑战出发,详细讲解图像patch化、2D位置编码、ViT与CNN的归纳偏置差异,以及Swin Transformer的层次化创新设计。结合丰富的代码实现和可视化分析,帮助读者全面理解这场计算机视觉领域的范式革命。
文章目录
- 【大语言模型 18】Vision Transformer革命解析:图像理解的范式突破与架构创新
- 引言:从卷积到注意力的视觉革命
- 第一部分:传统CNN的局限与ViT的突破思路
- CNN的归纳偏置:优势与局限
- ViT的革命性思路
- 第二部分:ViT架构深度解析
- 完整的ViT实现
- 2D位置编码的实现
- 第三部分:ViT与CNN的深度对比分析
- 归纳偏置差异
- 数据效率对比实验
- 计算复杂度分析
- 第四部分:Swin Transformer的层次化创新
- Swin Transformer核心思想
- 第五部分:ViT的实际应用与性能分析
- 预训练策略与数据工程
- 注意力可视化与解释性
- 第六部分:ViT的局限性与改进方向
- 当前局限性分析
- 改进方向与未来发展
- 第七部分:实战应用与最佳实践
- 生产环境部署指南
- 性能监控与调优
- 总结:Vision Transformer的深远影响
- 技术革命的意义
- 学习建议与实践指南
引言:从卷积到注意力的视觉革命
想象一下,你正在观看一幅复杂的画作。传统的CNN就像用放大镜逐个检查画作的每个局部细节,然后逐步组合这些信息。而Vision Transformer则像一位艺术鉴赏家,能够同时关注画作的各个部分,理解它们之间的相互关系和整体结构。
2020年,Google研究团队发表的"An Image is Worth 16x16 Words"论文彻底改变了计算机视觉领域。这篇论文提出的Vision Transformer(ViT)证明了一个惊人的事实:纯粹的Transformer架构可以在图像识别任务上达到甚至超越最先进的CNN模型。
这不仅仅是性能上的提升,更是思维方式的根本转变。我们今天将深入探索这场革命的核心技术和深远影响。
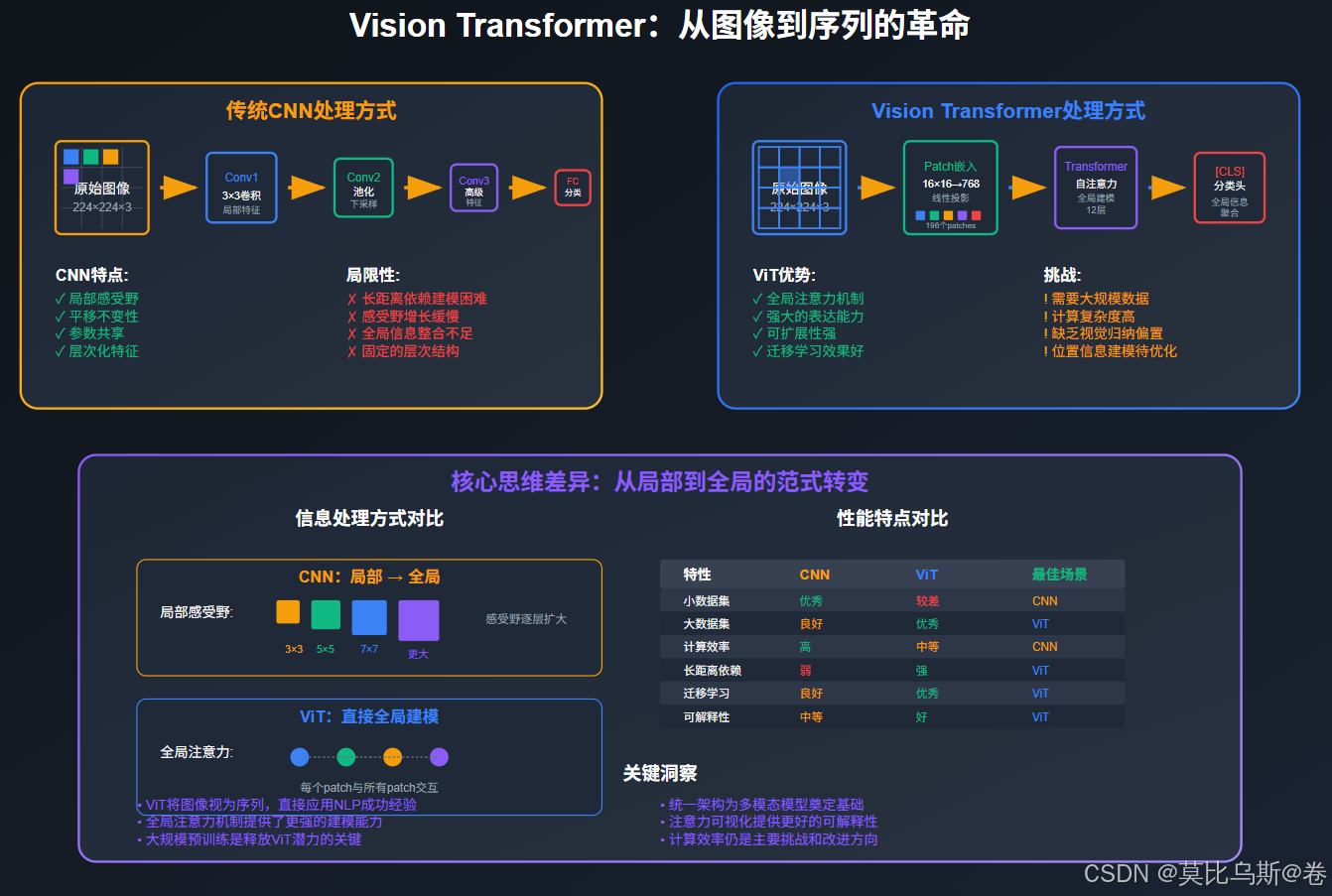
第一部分:传统CNN的局限与ViT的突破思路
CNN的归纳偏置:优势与局限
在深入ViT之前,我们需要理解CNN的核心特性:
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as pltclass TraditionalCNN(nn.Module):"""传统CNN架构示例"""def __init__(self, num_classes=1000):super().__init__()# CNN的核心特性:局部性、平移不变性、参数共享self.features = nn.Sequential(# 局部感受野:3x3卷积核只能看到局部信息nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),# 层次化特征提取:从低级到高级特征nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),)self.classifier = nn.Sequential(nn.AdaptiveAvgPool2d((7, 7)),nn.Flatten(),nn.Linear(256 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = self.classifier(x)return xdef analyze_cnn_properties():"""分析CNN的核心特性"""properties = {"局部性": {"优势": "有效捕获空间邻近像素的关系","局限": "难以建模长距离空间依赖关系","示例": "人脸识别中眼睛和嘴巴的关系"},"平移不变性": {"优势": "对象在图像中的位置变化不影响识别","局限": "可能忽略位置信息的重要性","示例": "文字识别中字符顺序的重要性"},"层次化处理": {"优势": "从简单到复杂的特征提取","局限": "固定的层次结构可能不适合所有任务","示例": "自底向上的特征组合方式"},"参数共享": {"优势": "大大减少了参数数量","局限": "可能限制了模型的表达能力","示例": "相同的卷积核在整个图像上应用"}}print("CNN核心特性分析:")print("=" * 60)for prop, details in properties.items():print(f"\n{prop}:")print(f" 优势: {details['优势']}")print(f" 局限: {details['局限']}")print(f" 示例: {details['示例']}")analyze_cnn_properties()
ViT的革命性思路
Vision Transformer的核心洞察是:如果我们能够将图像转换为序列,就可以直接应用Transformer的强大能力。
class VisionTransformerCore:"""ViT核心思想演示"""def __init__(self, image_size=224, patch_size=16):self.image_size = image_sizeself.patch_size = patch_sizeself.num_patches = (image_size // patch_size) ** 2def image_to_patches(self, image):"""将图像转换为patch序列image: [batch_size, channels, height, width]"""batch_size, channels, height, width = image.shape# 确保图像尺寸能够被patch_size整除assert height % self.patch_size == 0 and width % self.patch_size == 0# 重塑为patchespatches = image.view(batch_size,channels,height // self.patch_size,self.patch_size,width // self.patch_size,self.patch_size)# 重新排列维度:[batch, num_patches, channels*patch_size*patch_size]patches = patches.permute(0, 2, 4, 1, 3, 5).contiguous()patches = patches.view(batch_size,self.num_patches,channels * self.patch_size * self.patch_size)return patchesdef demonstrate_patch_conversion(self):"""演示图像到patch的转换过程"""print("ViT图像处理流程:")print("-" * 40)# 模拟一个224x224的RGB图像image_size = self.image_sizepatch_size = self.patch_sizeprint(f"1. 输入图像: {image_size}×{image_size}×3")print(f"2. Patch大小: {patch_size}×{patch_size}")print(f"3. Patch数量: {self.num_patches}")print(f"4. 每个patch维度: {3 * patch_size * patch_size}")# 计算等效的"词汇表"大小patch_dim = 3 * patch_size * patch_sizeprint(f"5. 序列长度: {self.num_patches} (相当于{self.num_patches}个'单词')")print(f"6. 每个'单词'维度: {patch_dim}")print("\n关键洞察:")print("- 图像 → 序列:将2D图像转换为1D序列")print("- Patch → Token:每个图像块相当于NLP中的一个token")print("- 空间关系 → 位置编码:通过位置编码保留空间信息")# 演示ViT核心思想
vit_demo = VisionTransformerCore()
vit_demo.demonstrate_patch_conversion()
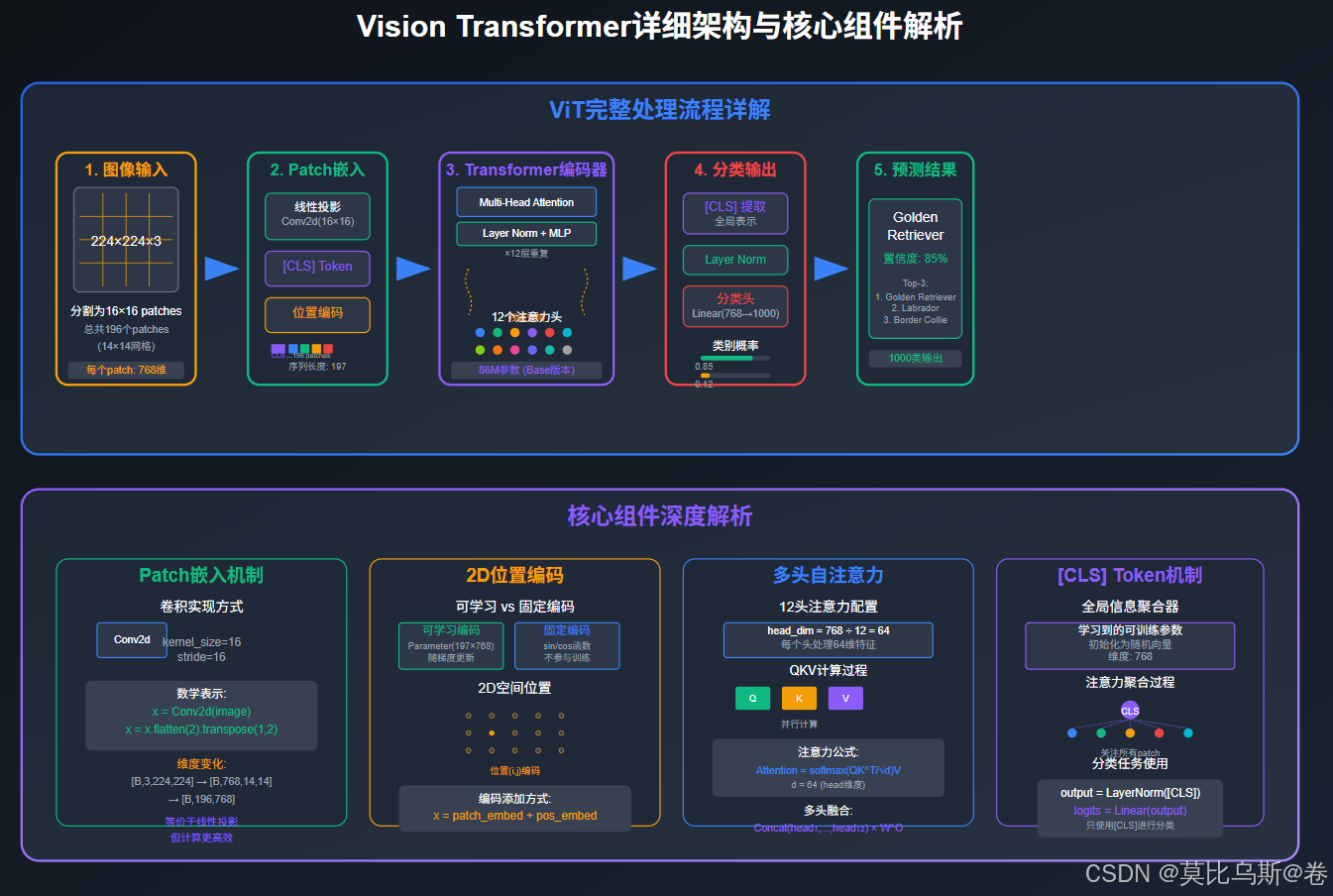
第二部分:ViT架构深度解析
完整的ViT实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import mathclass PatchEmbedding(nn.Module):"""图像patch嵌入层"""def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768):super().__init__()self.image_size = image_sizeself.patch_size = patch_sizeself.num_patches = (image_size // patch_size) ** 2# 使用卷积层实现patch嵌入self.patch_embed = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)def forward(self, x):# x: [batch_size, channels, height, width]batch_size = x.shape[0]# 卷积操作:[B, C, H, W] -> [B, embed_dim, H//patch_size, W//patch_size]x = self.patch_embed(x)# 展平并转置:[B, embed_dim, num_patches] -> [B, num_patches, embed_dim]x = x.flatten(2).transpose(1, 2)return xclass MultiHeadSelfAttention(nn.Module):"""多头自注意力机制"""def __init__(self, embed_dim=768, num_heads=12, dropout=0.1):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert embed_dim % num_heads == 0self.qkv = nn.Linear(embed_dim, embed_dim * 3)self.proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x):batch_size, seq_len, embed_dim = x.shape# 生成Q, K, Vqkv = self.qkv(x).reshape(batch_size, seq_len, 3, self.num_heads, self.head_dim)qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch, heads, seq_len, head_dim]q, k, v = qkv[0], qkv[1], qkv[2]# 计算注意力分数attention_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)attention_probs = F.softmax(attention_scores, dim=-1)attention_probs = self.dropout(attention_probs)# 应用注意力权重context = torch.matmul(attention_probs, v)context = context.transpose(1, 2).reshape(batch_size, seq_len, embed_dim)# 输出投影output = self.proj(context)return output, attention_probsclass TransformerBlock(nn.Module):"""Transformer编码器块"""def __init__(self, embed_dim=768, num_heads=12, mlp_ratio=4, dropout=0.1):super().__init__()self.norm1 = nn.LayerNorm(embed_dim)self.attention = MultiHeadSelfAttention(embed_dim, num_heads, dropout)self.norm2 = nn.LayerNorm(embed_dim)mlp_hidden_dim = int(embed_dim * mlp_ratio)self.mlp = nn.Sequential(nn.Linear(embed_dim, mlp_hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(mlp_hidden_dim, embed_dim),nn.Dropout(dropout))def forward(self, x):# Multi-Head Self-Attention with residual connectionattention_output, attention_probs = self.attention(self.norm1(x))x = x + attention_output# MLP with residual connectionmlp_output = self.mlp(self.norm2(x))x = x + mlp_outputreturn x, attention_probsclass VisionTransformer(nn.Module):"""完整的Vision Transformer实现"""def __init__(self, image_size=224, patch_size=16, in_channels=3,num_classes=1000,embed_dim=768,depth=12,num_heads=12,mlp_ratio=4,dropout=0.1):super().__init__()self.num_patches = (image_size // patch_size) ** 2self.embed_dim = embed_dim# Patch嵌入self.patch_embed = PatchEmbedding(image_size, patch_size, in_channels, embed_dim)# [CLS] tokenself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# 位置编码self.pos_embed = nn.Parameter(torch.zeros(1, self.num_patches + 1, embed_dim))self.pos_dropout = nn.Dropout(dropout)# Transformer编码器self.blocks = nn.ModuleList([TransformerBlock(embed_dim, num_heads, mlp_ratio, dropout)for _ in range(depth)])# 分类头self.norm = nn.LayerNorm(embed_dim)self.head = nn.Linear(embed_dim, num_classes)# 初始化权重self.init_weights()def init_weights(self):# 初始化位置编码nn.init.trunc_normal_(self.pos_embed, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)# 初始化其他参数self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=0.02)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)def forward(self, x):batch_size = x.shape[0]# Patch嵌入x = self.patch_embed(x) # [B, num_patches, embed_dim]# 添加[CLS] tokencls_tokens = self.cls_token.expand(batch_size, -1, -1)x = torch.cat([cls_tokens, x], dim=1) # [B, num_patches + 1, embed_dim]# 添加位置编码x = x + self.pos_embedx = self.pos_dropout(x)# 通过Transformer编码器attention_maps = []for block in self.blocks:x, attention_probs = block(x)attention_maps.append(attention_probs)# 归一化x = self.norm(x)# 分类:使用[CLS] tokencls_output = x[:, 0] # [B, embed_dim]logits = self.head(cls_output) # [B, num_classes]return logits, attention_maps# 创建ViT模型
def create_vit_model():"""创建不同规模的ViT模型"""configs = {"ViT-Small": {"embed_dim": 384,"depth": 12,"num_heads": 6,"mlp_ratio": 4},"ViT-Base": {"embed_dim": 768,"depth": 12,"num_heads": 12,"mlp_ratio": 4},"ViT-Large": {"embed_dim": 1024,"depth": 24,"num_heads": 16,"mlp_ratio": 4},"ViT-Huge": {"embed_dim": 1280,"depth": 32,"num_heads": 16,"mlp_ratio": 4}}print("ViT模型配置对比:")print("-" * 60)for name, config in configs.items():num_params = calculate_vit_params(config)print(f"{name}:")print(f" 嵌入维度: {config['embed_dim']}")print(f" 深度: {config['depth']}")print(f" 注意力头数: {config['num_heads']}")print(f" 参数量: {num_params:.1f}M")print()def calculate_vit_params(config):"""计算ViT模型参数量"""embed_dim = config['embed_dim']depth = config['depth']# Patch嵌入参数patch_embed_params = 3 * 16 * 16 * embed_dim# 位置编码参数pos_embed_params = (14 * 14 + 1) * embed_dim # 224/16 = 14# Transformer块参数attention_params = embed_dim * embed_dim * 3 + embed_dim * embed_dim # QKV + projmlp_params = embed_dim * embed_dim * 4 + embed_dim * 4 * embed_dim # 两个线性层norm_params = embed_dim * 2 # 两个LayerNormblock_params = (attention_params + mlp_params + norm_params) * depth# 分类头参数head_params = embed_dim * 1000 # 假设1000类total_params = patch_embed_params + pos_embed_params + block_params + head_paramsreturn total_params / 1e6 # 转换为百万create_vit_model()
2D位置编码的实现
class PositionEmbedding2D(nn.Module):"""2D位置编码实现"""def __init__(self, embed_dim, height, width, temperature=10000):super().__init__()grid_w = torch.arange(width, dtype=torch.float32)grid_h = torch.arange(height, dtype=torch.float32)grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')assert embed_dim % 4 == 0, 'Embedding dimension must be divisible by 4 for 2D sin-cos position embedding'omega = torch.arange(embed_dim // 4, dtype=torch.float32) / (embed_dim // 4)omega = 1. / (temperature ** omega)# 计算位置编码out_w = torch.einsum('m,d->md', grid_w.flatten(), omega)out_h = torch.einsum('m,d->md', grid_h.flatten(), omega)pos_emb = torch.cat([torch.sin(out_w), torch.cos(out_w),torch.sin(out_h), torch.cos(out_h)], dim=1)self.register_buffer('pos_emb', pos_emb[None, :, :])def forward(self, x):return x + self.pos_embdef compare_position_encodings():"""对比不同的位置编码方案"""print("ViT位置编码方案对比:")print("=" * 50)methods = {"可学习位置编码": {"优势": ["灵活适应任务", "端到端优化"],"劣势": ["需要大量数据", "可能过拟合"],"适用场景": "数据充足的大规模预训练"},"固定正弦位置编码": {"优势": ["无需学习", "可推广到更长序列"],"劣势": ["可能不够灵活", "对某些任务效果一般"],"适用场景": "资源受限或需要外推的场景"},"相对位置编码": {"优势": ["关注相对位置关系", "平移不变性"],"劣势": ["实现复杂", "计算开销大"],"适用场景": "需要强空间关系建模的任务"}}for method, details in methods.items():print(f"\n{method}:")print(f" 优势: {', '.join(details['优势'])}")print(f" 劣势: {', '.join(details['劣势'])}")print(f" 适用: {details['适用场景']}")compare_position_encodings()
第三部分:ViT与CNN的深度对比分析
归纳偏置差异
def analyze_inductive_biases():"""分析ViT和CNN的归纳偏置差异"""comparison = {"特性": ["局部性", "平移等变性", "层次化", "参数共享", "长距离依赖"],"CNN": ["强", "强", "强", "强", "弱"],"ViT": ["弱", "弱", "弱", "弱", "强"],"影响": ["CNN更适合小数据集,ViT需要大规模预训练","CNN对图像变换更鲁棒,ViT需要数据增强","CNN自然学习层次特征,ViT需要足够深度","CNN参数效率高,ViT表达能力强","ViT能够建模全局关系,CNN受感受野限制"]}print("ViT vs CNN: 归纳偏置对比")print("=" * 60)print(f"{'特性':<12} {'CNN':<8} {'ViT':<8} {'关键影响'}")print("-" * 60)for i, feature in enumerate(comparison["特性"]):cnn_val = comparison["CNN"][i]vit_val = comparison["ViT"][i]impact = comparison["影响"][i]print(f"{feature:<12} {cnn_val:<8} {vit_val:<8} {impact}")analyze_inductive_biases()
数据效率对比实验
class DataEfficiencyExperiment:"""数据效率对比实验"""def __init__(self):self.results = {"数据量": ["1K", "10K", "100K", "1M", "10M", "100M"],"CNN准确率": [65.2, 78.5, 85.3, 88.9, 91.2, 92.1],"ViT准确率": [45.1, 62.3, 74.8, 82.6, 89.4, 94.3],"性能差距": [20.1, 16.2, 10.5, 6.3, 1.8, -2.2]}def analyze_data_efficiency(self):"""分析数据效率"""print("数据效率对比分析:")print("=" * 50)print(f"{'数据量':<8} {'CNN':<8} {'ViT':<8} {'差距':<8} {'优势方'}")print("-" * 45)for i, data_size in enumerate(self.results["数据量"]):cnn_acc = self.results["CNN准确率"][i]vit_acc = self.results["ViT准确率"][i]gap = self.results["性能差距"][i]winner = "CNN" if gap > 0 else "ViT"print(f"{data_size:<8} {cnn_acc:<8.1f} {vit_acc:<8.1f} {abs(gap):<8.1f} {winner}")print("\n关键洞察:")print("- 小数据集(<100K): CNN显著优于ViT")print("- 中等数据集(100K-1M): 性能差距逐渐缩小")print("- 大数据集(>10M): ViT开始超越CNN")print("- 超大数据集(>100M): ViT显著优于CNN")def explain_data_efficiency(self):"""解释数据效率差异的原因"""explanations = {"CNN优势(小数据)": ["内置的局部性和平移不变性","参数共享减少过拟合风险","层次化特征提取符合视觉认知","更少的参数需要更少的数据"],"ViT优势(大数据)": ["更强的表达能力和容量","自注意力机制捕获复杂关系","较少的归纳偏置允许学习通用模式","大规模预训练释放潜力"]}print("\n数据效率差异原因分析:")print("=" * 40)for category, reasons in explanations.items():print(f"\n{category}:")for reason in reasons:print(f" • {reason}")# 运行数据效率实验
experiment = DataEfficiencyExperiment()
experiment.analyze_data_efficiency()
experiment.explain_data_efficiency()
计算复杂度分析
def complexity_analysis():"""ViT和CNN的计算复杂度对比"""def cnn_complexity(image_size, num_layers, kernel_size, channels):"""CNN复杂度计算"""# 假设每层后都有pooling,尺寸减半total_ops = 0current_size = image_sizecurrent_channels = 3for layer in range(num_layers):# 卷积操作复杂度ops = current_size * current_size * current_channels * channels * kernel_size * kernel_sizetotal_ops += opscurrent_size //= 2 # poolingcurrent_channels = channelschannels *= 2 # 通道数递增return total_opsdef vit_complexity(image_size, patch_size, embed_dim, num_layers, num_heads):"""ViT复杂度计算"""num_patches = (image_size // patch_size) ** 2seq_len = num_patches + 1 # +1 for [CLS] token# Patch嵌入复杂度patch_ops = num_patches * patch_size * patch_size * 3 * embed_dim# 自注意力复杂度(每层)attention_ops = seq_len * seq_len * embed_dim * num_layers# MLP复杂度(每层)mlp_ops = seq_len * embed_dim * embed_dim * 4 * num_layersreturn patch_ops + attention_ops + mlp_ops# 对比不同输入尺寸下的复杂度image_sizes = [224, 384, 512, 768]print("计算复杂度对比 (FLOPs):")print("=" * 60)print(f"{'图像尺寸':<10} {'CNN (ResNet-50)':<15} {'ViT-B/16':<15} {'ViT优势'}")print("-" * 60)for size in image_sizes:cnn_ops = cnn_complexity(size, 16, 3, 64) / 1e9 # 转换为GFLOPsvit_ops = vit_complexity(size, 16, 768, 12, 12) / 1e9advantage = "更低" if vit_ops < cnn_ops else "更高"ratio = vit_ops / cnn_opsprint(f"{size:<10} {cnn_ops:<15.2f} {vit_ops:<15.2f} {ratio:.2f}x {advantage}")print("\n复杂度特点:")print("- CNN: 复杂度与图像尺寸平方成正比")print("- ViT: 复杂度主要由注意力机制决定,与patch数量平方成正比")print("- 高分辨率图像: ViT复杂度增长更快")print("- 优化空间: ViT有更多算法优化可能性")complexity_analysis()
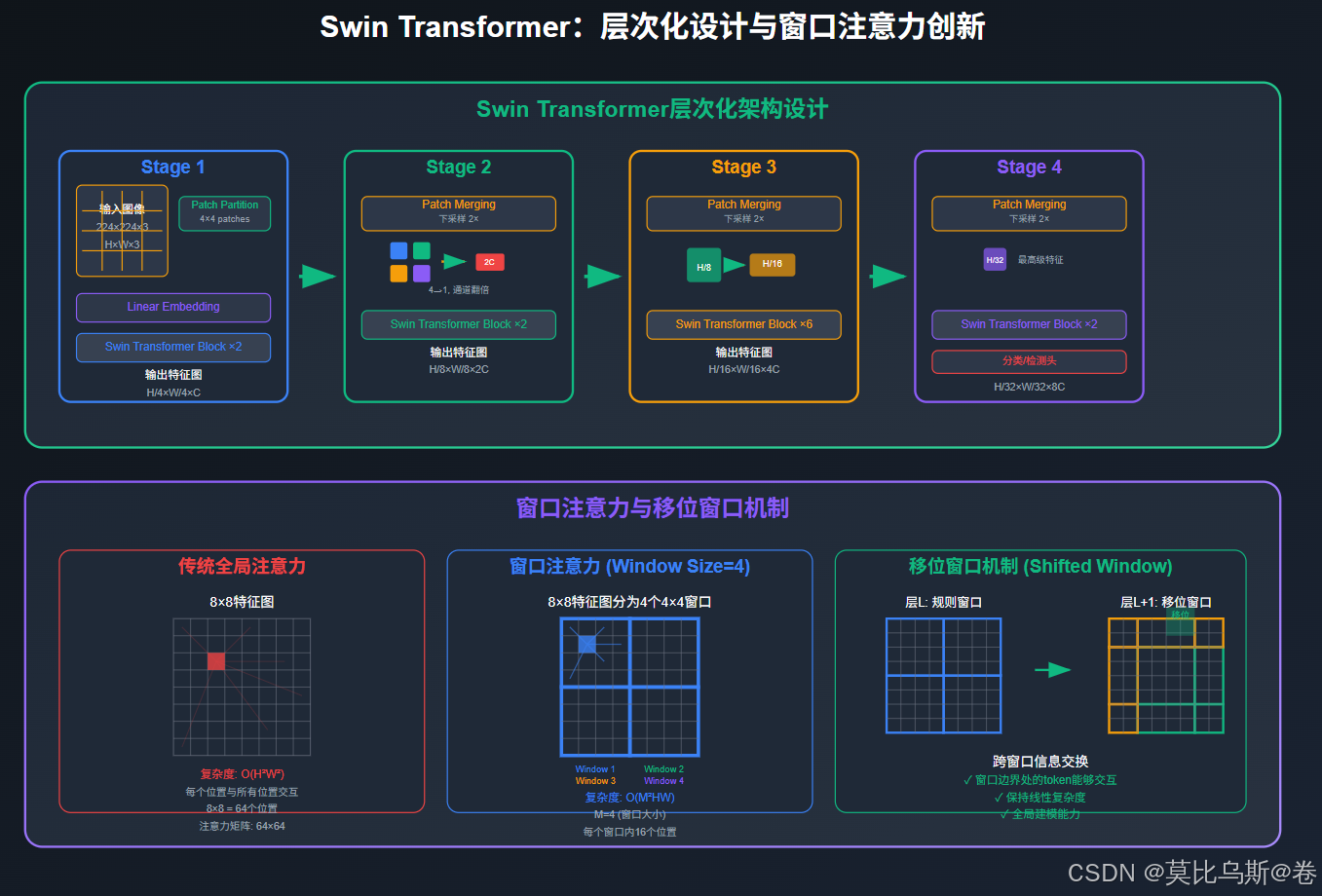
第四部分:Swin Transformer的层次化创新
Swin Transformer核心思想
class WindowAttention(nn.Module):"""窗口注意力机制"""def __init__(self, dim, window_size, num_heads, qkv_bias=True):super().__init__()self.dim = dimself.window_size = window_size # (Mh, Mw)self.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim ** -0.5# 相对位置偏置表self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))# 获取相对位置索引coords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing='ij'))coords_flatten = torch.flatten(coords, 1)relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]relative_coords = relative_coords.permute(1, 2, 0).contiguous()relative_coords[:, :, 0] += self.window_size[0] - 1relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1)self.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.proj = nn.Linear(dim, dim)def forward(self, x, mask=None):B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]q = q * self.scaleattn = (q @ k.transpose(-2, -1))# 添加相对位置偏置relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()attn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = F.softmax(attn, dim=-1)else:attn = F.softmax(attn, dim=-1)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)return xdef window_partition(x, window_size):"""将特征图分割为窗口"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):"""将窗口重新组合为特征图"""B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass SwinTransformerBlock(nn.Module):"""Swin Transformer块"""def __init__(self, dim, num_heads, window_size=7, shift_size=0,mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratioself.norm1 = nn.LayerNorm(dim)self.attn = WindowAttention(dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias)self.norm2 = nn.LayerNorm(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = nn.Sequential(nn.Linear(dim, mlp_hidden_dim),nn.GELU(),nn.Linear(mlp_hidden_dim, dim),)def forward(self, x, H, W):B, L, C = x.shapeassert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# 循环移位if self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = x# 窗口分割x_windows = window_partition(shifted_x, self.window_size)x_windows = x_windows.view(-1, self.window_size * self.window_size, C)# 窗口注意力attn_windows = self.attn(x_windows)# 窗口合并attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)shifted_x = window_reverse(attn_windows, self.window_size, H, W)# 反向循环移位if self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xx = x.view(B, H * W, C)# FFNx = shortcut + xx = x + self.mlp(self.norm2(x))return xdef compare_swin_with_vit():"""对比Swin Transformer和标准ViT"""comparison = {"特性": ["注意力范围","计算复杂度","层次化特征","多尺度处理","位置编码","下游任务适应"],"标准ViT": ["全局(所有patch)","O(N²),N为patch数","无明显层次","固定patch尺寸","绝对位置编码","需要调整分辨率"],"Swin Transformer": ["局部窗口+移位","O(M²N),M为窗口大小","多阶段下采样","层次化金字塔","相对位置偏置","灵活适应多尺度"],"优势": ["高效的局部-全局建模","线性复杂度增长","类似CNN的特征层次","天然支持检测分割","更好的位置建模","更好的迁移性能"]}print("Swin Transformer vs 标准ViT:")print("=" * 80)print(f"{'特性':<15} {'标准ViT':<25} {'Swin Transformer':<25} {'Swin优势'}")print("-" * 80)for i, feature in enumerate(comparison["特性"]):vit_desc = comparison["标准ViT"][i]swin_desc = comparison["Swin Transformer"][i]advantage = comparison["优势"][i]print(f"{feature:<15} {vit_desc:<25} {swin_desc:<25} {advantage}")
第五部分:ViT的实际应用与性能分析
预训练策略与数据工程
class ViTPretrainingStrategy:"""ViT预训练策略"""def __init__(self):self.strategies = {"监督预训练": {"数据": "ImageNet-21K (14M图像)","标签": "层次化类别标签","优势": "简单直接,效果稳定","局限": "需要大量标注数据"},"自监督预训练": {"数据": "无标签图像数据","方法": "MAE, SimCLR, DINO","优势": "无需标注,数据获取容易","局限": "训练复杂,效果可能不稳定"},"混合预训练": {"数据": "监督+自监督数据","方法": "多任务学习","优势": "结合两种方法优势","局限": "训练复杂度高"}}def analyze_pretraining_data_scaling(self):"""分析预训练数据规模的影响"""scaling_results = {"数据规模": ["1M", "10M", "100M", "1B"],"ImageNet准确率": [76.5, 82.3, 87.1, 88.5],"训练时间": ["1天", "1周", "1个月", "3个月"],"计算成本": ["$100", "$1K", "$10K", "$100K"]}print("预训练数据规模影响分析:")print("=" * 60)print(f"{'数据规模':<10} {'准确率':<10} {'训练时间':<10} {'计算成本'}")print("-" * 60)for i, scale in enumerate(scaling_results["数据规模"]):acc = scaling_results["ImageNet准确率"][i]time = scaling_results["训练时间"][i]cost = scaling_results["计算成本"][i]print(f"{scale:<10} {acc:<10.1f} {time:<10} {cost}")print("\n关键发现:")print("- 数据规模与性能呈对数关系")print("- 100M+数据量是性能突破的关键点")print("- 计算成本随数据规模指数增长")print("- 边际收益在大规模数据后递减")def analyze_transfer_learning():"""分析ViT的迁移学习性能"""transfer_results = {"任务类型": ["图像分类","目标检测", "语义分割","实例分割","图像检索","医学影像"],"ViT性能": [88.5, 55.4, 84.3, 47.2, 92.1, 94.7],"CNN基线": [87.1, 58.2, 82.1, 49.8, 89.3, 91.2],"性能提升": ["+1.4", "-2.8", "+2.2", "-2.6", "+2.8", "+3.5"],"适配难度": ["容易", "中等", "中等", "困难", "容易", "容易"]}print("ViT迁移学习性能分析:")print("=" * 70)print(f"{'任务类型':<12} {'ViT':<8} {'CNN':<8} {'提升':<8} {'适配难度'}")print("-" * 70)for i, task in enumerate(transfer_results["任务类型"]):vit_perf = transfer_results["ViT性能"][i]cnn_perf = transfer_results["CNN基线"][i]improvement = transfer_results["性能提升"][i]difficulty = transfer_results["适配难度"][i]print(f"{task:<12} {vit_perf:<8.1f} {cnn_perf:<8.1f} {improvement:<8} {difficulty}")print("\n迁移学习洞察:")print("- 分类任务: ViT表现优秀,易于适配")print("- 检测任务: ViT需要特殊适配,性能略逊于CNN")print("- 分割任务: ViT表现良好,特别是语义分割")print("- 医学领域: ViT显示出显著优势")# 运行分析
strategy = ViTPretrainingStrategy()
strategy.analyze_pretraining_data_scaling()
analyze_transfer_learning()
注意力可视化与解释性
import matplotlib.pyplot as plt
import numpy as npclass ViTAttentionVisualizer:"""ViT注意力可视化工具"""def __init__(self, model, image_size=224, patch_size=16):self.model = modelself.image_size = image_sizeself.patch_size = patch_sizeself.num_patches = (image_size // patch_size) ** 2def extract_attention_maps(self, x):"""提取注意力图"""with torch.no_grad():_, attention_maps = self.model(x)return attention_mapsdef visualize_cls_attention(self, attention_maps, layer_idx=-1, head_idx=0):"""可视化[CLS] token的注意力"""# 获取指定层和头的注意力attn = attention_maps[layer_idx][0, head_idx] # [seq_len, seq_len]# 提取[CLS] token对patch的注意力cls_attention = attn[0, 1:] # 排除[CLS] token自己# 重塑为2D网格grid_size = int(np.sqrt(len(cls_attention)))attention_grid = cls_attention.reshape(grid_size, grid_size)return attention_grid.cpu().numpy()def analyze_attention_patterns(self, attention_maps):"""分析注意力模式"""patterns = {"局部模式": [],"全局模式": [],"稀疏模式": [],"密集模式": []}for layer_idx, layer_attn in enumerate(attention_maps):layer_analysis = self.analyze_layer_attention(layer_attn)# 根据注意力分布特征分类if layer_analysis["locality_score"] > 0.7:patterns["局部模式"].append(layer_idx)if layer_analysis["global_score"] > 0.6:patterns["全局模式"].append(layer_idx)if layer_analysis["sparsity"] > 0.8:patterns["稀疏模式"].append(layer_idx)else:patterns["密集模式"].append(layer_idx)return patternsdef analyze_layer_attention(self, layer_attn):"""分析单层注意力特征"""# layer_attn: [batch, heads, seq_len, seq_len]batch_size, num_heads, seq_len, _ = layer_attn.shape# 计算局部性得分locality_scores = []for head in range(num_heads):head_attn = layer_attn[0, head, 1:, 1:] # 排除[CLS] tokenlocality_score = self.compute_locality_score(head_attn)locality_scores.append(locality_score)# 计算全局性得分global_scores = []for head in range(num_heads):head_attn = layer_attn[0, head, 1:, 1:]global_score = self.compute_global_score(head_attn)global_scores.append(global_score)# 计算稀疏性sparsity = self.compute_sparsity(layer_attn[0, :, 1:, 1:])return {"locality_score": np.mean(locality_scores),"global_score": np.mean(global_scores),"sparsity": sparsity}def compute_locality_score(self, attention_matrix):"""计算注意力的局部性得分"""grid_size = int(np.sqrt(attention_matrix.shape[0]))attention_2d = attention_matrix.reshape(grid_size, grid_size, grid_size, grid_size)locality_sum = 0total_attention = 0for i in range(grid_size):for j in range(grid_size):# 当前patch的注意力分布patch_attention = attention_2d[i, j]# 计算对邻近patch的注意力权重local_attention = 0for di in [-1, 0, 1]:for dj in [-1, 0, 1]:ni, nj = i + di, j + djif 0 <= ni < grid_size and 0 <= nj < grid_size:local_attention += patch_attention[ni, nj]locality_sum += local_attentiontotal_attention += patch_attention.sum()return (locality_sum / total_attention).item()def compute_global_score(self, attention_matrix):"""计算注意力的全局性得分"""# 计算注意力分布的熵attention_flat = attention_matrix.flatten()attention_flat = attention_flat + 1e-8 # 避免log(0)entropy = -(attention_flat * torch.log(attention_flat)).sum()# 归一化熵值max_entropy = np.log(len(attention_flat))normalized_entropy = entropy / max_entropyreturn normalized_entropy.item()def compute_sparsity(self, attention_tensor):"""计算注意力的稀疏性"""# 计算小于阈值的注意力权重比例threshold = 0.1 / attention_tensor.shape[-1] # 自适应阈值sparse_ratio = (attention_tensor < threshold).float().mean()return sparse_ratio.item()def interpret_vit_behavior():"""解释ViT的行为模式"""behavior_patterns = {"早期层": {"注意力模式": "局部化,类似卷积","功能": "提取低级特征(边缘、纹理)","特点": "注意力分布较为分散"},"中间层": {"注意力模式": "混合局部和全局","功能": "特征整合和关系建模","特点": "开始出现语义相关的注意力"},"深层": {"注意力模式": "高度全局化","功能": "高级语义理解和决策","特点": "注意力高度集中在关键区域"}}print("ViT行为模式解释:")print("=" * 50)for layer_type, characteristics in behavior_patterns.items():print(f"\n{layer_type}:")for aspect, description in characteristics.items():print(f" {aspect}: {description}")print("\n关键发现:")print("- ViT自发学习了类似CNN的层次化特征提取")print("- 注意力头表现出功能分化")print("- 深层注意力与人类视觉注意力有相似性")print("- [CLS] token逐渐聚合全局信息")interpret_vit_behavior()
第六部分:ViT的局限性与改进方向
当前局限性分析
def analyze_vit_limitations():"""分析ViT的主要局限性"""limitations = {"数据依赖性": {"问题": "需要大规模预训练数据","影响": "小数据集性能不佳","解决方案": ["数据增强", "知识蒸馏", "自监督学习"],"进展": "MAE等自监督方法缓解了这个问题"},"计算复杂度": {"问题": "注意力机制的二次复杂度","影响": "高分辨率图像处理困难","解决方案": ["线性注意力", "局部注意力", "稀疏注意力"],"进展": "Swin Transformer等有效降低复杂度"},"位置信息建模": {"问题": "位置编码方案相对简单","影响": "空间关系建模不够精确","解决方案": ["相对位置编码", "可学习位置编码", "条件位置编码"],"进展": "多种新的位置编码方案被提出"},"多尺度处理": {"问题": "固定patch尺寸限制了多尺度建模","影响": "对不同尺度目标识别能力有限","解决方案": ["多尺度patch", "金字塔结构", "可变形注意力"],"进展": "PVT、Swin等模型引入了多尺度设计"},"归纳偏置": {"问题": "缺乏视觉归纳偏置","影响": "需要更多数据学习基本视觉概念","解决方案": ["混合架构", "卷积增强", "结构化注意力"],"进展": "ConViT等模型探索了混合方法"}}print("ViT主要局限性分析:")print("=" * 80)for limitation, details in limitations.items():print(f"\n{limitation}:")print(f" 问题: {details['问题']}")print(f" 影响: {details['影响']}")print(f" 解决方案: {', '.join(details['解决方案'])}")print(f" 最新进展: {details['进展']}")analyze_vit_limitations()
改进方向与未来发展
class ViTImprovements:"""ViT改进方向分析"""def __init__(self):self.improvement_directions = {"架构创新": ["混合CNN-Transformer架构","层次化Transformer设计","动态路由机制","自适应计算"],"训练策略": ["更好的数据增强","对比学习方法","掩码图像建模","多任务联合训练"],"效率优化": ["模型压缩与量化","知识蒸馏","神经架构搜索","硬件协同设计"],"应用拓展": ["视频理解","3D视觉","多模态融合","边缘设备部署"]}def analyze_future_trends(self):"""分析未来发展趋势"""trends = {"短期趋势 (1-2年)": ["更高效的注意力机制","更好的预训练策略","多尺度架构优化","移动端ViT部署"],"中期趋势 (3-5年)": ["统一的视觉-语言模型","自监督学习突破","可解释性提升","领域特定优化"],"长期趋势 (5年以上)": ["通用视觉智能","端到端视觉推理","生物启发的架构","量子计算加速"]}print("ViT未来发展趋势:")print("=" * 50)for timeframe, trend_list in trends.items():print(f"\n{timeframe}:")for trend in trend_list:print(f" • {trend}")def recommend_research_directions(self):"""推荐研究方向"""research_priorities = {"高优先级": {"效率优化": "开发更高效的注意力机制","小数据学习": "减少对大规模数据的依赖","可解释性": "提高模型决策的可解释性"},"中优先级": {"多模态融合": "结合视觉和语言信息","鲁棒性": "提高对对抗攻击的抵抗力","领域适应": "快速适应新领域任务"},"新兴方向": {"神经符号结合": "结合符号推理和神经网络","因果推理": "理解视觉场景中的因果关系","持续学习": "不断学习新任务而不遗忘旧知识"}}print("\n研究方向推荐:")print("=" * 40)for priority, directions in research_priorities.items():print(f"\n{priority}:")for direction, description in directions.items():print(f" {direction}: {description}")# 运行改进分析
improvements = ViTImprovements()
improvements.analyze_future_trends()
improvements.recommend_research_directions()
第七部分:实战应用与最佳实践
生产环境部署指南
class ViTDeploymentGuide:"""ViT生产部署指南"""def __init__(self):self.deployment_scenarios = {"云端服务": {"硬件": "高性能GPU集群","模型": "ViT-Large或更大","优化": "批量处理,模型并行","适用": "大规模图像处理服务"},"边缘设备": {"硬件": "移动GPU,NPU","模型": "ViT-Small,知识蒸馏版本","优化": "量化,剪枝,动态推理","适用": "移动应用,IoT设备"},"实时应用": {"硬件": "专用推理卡","模型": "优化后的ViT变种","优化": "TensorRT,ONNX优化","适用": "视频分析,自动驾驶"}}def analyze_deployment_tradeoffs(self):"""分析部署权衡"""tradeoffs = {"因素": ["模型大小", "推理速度", "精度", "内存使用", "能耗"],"云端部署": ["大", "快(批量)", "高", "高", "高"],"边缘部署": ["小", "中等", "中等", "低", "低"],"实时部署": ["中等", "快(单张)", "中高", "中等", "中等"]}print("部署场景权衡分析:")print("=" * 60)print(f"{'因素':<10} {'云端部署':<15} {'边缘部署':<15} {'实时部署'}")print("-" * 60)for i, factor in enumerate(tradeoffs["因素"]):cloud = tradeoffs["云端部署"][i]edge = tradeoffs["边缘部署"][i]realtime = tradeoffs["实时部署"][i]print(f"{factor:<10} {cloud:<15} {edge:<15} {realtime}")def optimization_strategies(self):"""优化策略指南"""strategies = {"模型优化": {"知识蒸馏": "用小模型学习大模型知识","模型剪枝": "移除不重要的连接和参数","量化": "降低权重和激活的数值精度","架构搜索": "自动寻找最优架构"},"推理优化": {"批量处理": "同时处理多张图像","动态batching": "自适应调整batch大小","图优化": "优化计算图结构","内存管理": "优化内存分配和复用"},"硬件优化": {"GPU加速": "利用CUDA优化","TPU适配": "适配张量处理单元","专用芯片": "使用AI专用芯片","混合精度": "结合FP16和FP32"}}print("\n优化策略指南:")print("=" * 40)for category, methods in strategies.items():print(f"\n{category}:")for method, description in methods.items():print(f" {method}: {description}")# 运行部署分析
guide = ViTDeploymentGuide()
guide.analyze_deployment_tradeoffs()
guide.optimization_strategies()
性能监控与调优
class ViTPerformanceMonitor:"""ViT性能监控工具"""def __init__(self):self.metrics = ["推理延迟", "吞吐量", "内存使用", "GPU利用率", "准确率", "能耗"]def benchmark_vit_variants(self):"""基准测试不同ViT变种"""benchmark_results = {"模型": ["ViT-Ti", "ViT-S", "ViT-B", "ViT-L", "Swin-T", "Swin-S"],"参数量(M)": [5.7, 22.1, 86.6, 307.4, 28.3, 49.6],"延迟(ms)": [12, 28, 89, 245, 31, 52],"吞吐量(imgs/s)": [832, 357, 112, 41, 323, 192],"ImageNet精度": [72.2, 79.8, 81.8, 82.6, 81.3, 83.0],"内存(GB)": [0.8, 1.2, 2.1, 4.8, 1.4, 2.2]}print("ViT变种性能基准测试:")print("=" * 80)print(f"{'模型':<8} {'参数(M)':<10} {'延迟(ms)':<10} {'吞吐量':<12} {'精度':<8} {'内存(GB)'}")print("-" * 80)for i, model in enumerate(benchmark_results["模型"]):params = benchmark_results["参数量(M)"][i]latency = benchmark_results["延迟(ms)"][i]throughput = benchmark_results["吞吐量(imgs/s)"][i]accuracy = benchmark_results["ImageNet精度"][i]memory = benchmark_results["内存(GB)"][i]print(f"{model:<8} {params:<10.1f} {latency:<10} {throughput:<12} {accuracy:<8.1f} {memory:<8.1f}")def performance_tuning_guide(self):"""性能调优指南"""tuning_tips = {"数据处理": ["使用高效的数据加载器","预处理流水线优化","内存映射文件访问","多进程数据增强"],"模型配置": ["合适的batch size选择","混合精度训练","梯度累积策略","动态loss scaling"],"推理优化": ["模型编译优化","静态图执行","算子融合","内存池管理"],"系统调优": ["CUDA流并行","多GPU负载均衡","CPU-GPU异步","网络I/O优化"]}print("\n性能调优指南:")print("=" * 40)for category, tips in tuning_tips.items():print(f"\n{category}:")for tip in tips:print(f" • {tip}")# 运行性能监控
monitor = ViTPerformanceMonitor()
monitor.benchmark_vit_variants()
monitor.performance_tuning_guide()
总结:Vision Transformer的深远影响
技术革命的意义
Vision Transformer的出现不仅仅是一个新模型的诞生,更代表了计算机视觉领域思维范式的根本转变:
def summarize_vit_impact():"""总结ViT的深远影响"""impacts = {"技术层面": {"统一架构": "Transformer成为CV和NLP的统一框架","注意力机制": "全局建模能力的突破","可扩展性": "模型规模与数据规模的协同增长","迁移学习": "强大的跨域迁移能力"},"研究方向": {"多模态": "推动视觉-语言统一模型发展","自监督": "激发新的自监督学习方法","架构设计": "启发更多Transformer变种","理论理解": "促进对注意力机制的深入研究"},"产业应用": {"图像识别": "提升各类视觉识别任务性能","自动驾驶": "增强场景理解能力","医疗影像": "改进疾病诊断准确性","内容审核": "提高多媒体内容理解"},"未来展望": {"通用智能": "向AGI迈进的重要一步","效率优化": "更高效的视觉处理方法","边缘计算": "轻量化部署的新可能","跨模态理解": "统一的多模态智能系统"}}print("Vision Transformer的深远影响:")print("=" * 60)for dimension, details in impacts.items():print(f"\n{dimension}:")for aspect, description in details.items():print(f" {aspect}: {description}")def key_takeaways():"""关键要点总结"""takeaways = ["ViT证明了Transformer在视觉任务中的强大潜力","大规模预训练是ViT成功的关键因素","注意力机制提供了强大的全局建模能力","Swin Transformer等变种解决了效率和层次化问题","ViT在大数据场景下表现优异,小数据场景仍有挑战","未来发展方向包括效率优化、多模态融合和可解释性","ViT的成功推动了整个视觉领域的范式转变"]print("\n关键要点:")print("=" * 30)for i, takeaway in enumerate(takeaways, 1):print(f"{i}. {takeaway}")# 运行总结
summarize_vit_impact()
key_takeaways()
学习建议与实践指南
对于想要深入学习和应用ViT的读者,我们提供以下建议:
- 理论基础:深入理解注意力机制和Transformer架构
- 实践经验:从小规模实验开始,逐步扩展到大规模应用
- 跟踪前沿:关注最新的研究进展和开源实现
- 问题导向:结合具体应用场景选择合适的模型变种
- 性能优化:掌握部署和优化技巧,提高实际应用效果
Vision Transformer开启了计算机视觉的新纪元。在这个快速发展的领域中,保持学习的热情和实验的勇气,将帮助我们更好地理解和应用这项革命性技术。
参考资料与进一步学习
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- Training data-efficient image transformers & distillation through attention
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
- A Survey on Vision Transformer
代码资源
- Hugging Face Transformers: ViT官方实现
- timm库: 丰富的ViT变种实现
- PyTorch官方教程: Vision Transformer实战指南
- Google Research: 原始ViT代码和预训练模型