Redis详解--基本篇
本篇将介绍:
- 我们为什么要使用NoSql数据库,
- NoSql数据库的基本概述,
- Redis的简单信息,
- Redis常用的数据类型操作,
- Redis的配置文件,
- 关于Redis简单的发布及订阅。
我们为什么要使用NoSql数据库?
当我们开发一个项目,我们除了要掌握功能性、扩展性的技术,我们还要掌握解决性能问题的技术——这项需求方案,目的旨在:
解决项目开发完成之后,受众用户可能会有很多,随着用户量的不断增加的场景。
Nginx负载均衡和Session问题
Nginx负载均衡
随着用户访问量的不断增加,原本一对一的服务模式不复存在。
就像一家奶茶店,抠门的店长只请了一个服务员,在工作日有十个客户排队的话服务员还能应付,但是在休息日,店里涌入了100个客户,这时店员就会手忙脚乱,这时服务员可能会出错,效率降低,在节假日,店里挤了1000个客户,这时候服务员就会直接崩溃,客户将全部跑光。
当抠门的店长发现生意越来越好,客户对服务员的数量需求越来越大的时候,店长决定多请几个服务员了,为了管理这些服务员,店长还请了领班,领班不管奶茶口味,也不招人,他的工作只是公平分配任务给服务员,高峰期让服务员全部到岗,低峰期让一些服务员放假,只保留基本的服务员框架。
这件事换到计算机场景,就是所谓的突破性能瓶颈,单台服务器的 CPU、内存、带宽、磁盘 I/O 都有上限。请求一旦超过这个上限,系统响应时间飙升,甚至直接宕机。为解决这个问题,我们采用 Nginx 负载均衡,把“一位店员”扩展成“多位店员”,通过Nginx进行管理。
- 横向扩容:把同样的业务代码部署到多台服务器,形成“店员团队”。
- 统一入口:所有用户请求先到 Nginx,再由它按策略分发给不同的服务器。
- 动态伸缩:高峰期多开几台服务器,低谷期关掉几台,节省成本。
- 高可用:某台服务器挂了,Nginx 自动把它踢出队列,用户无感知。
Session问题
继续刚才的例子:
当一个顾客第一次到店时,领班给他办一张实体会员卡,并把卡号、积分等信息只存在1号店员的收银机里。
顾客第二次来,被领班领到 3 号店员——3 号店员收银机里没有这张卡的记录,只能让顾客重新办卡、积分清零。
这就是 Session 问题:卡(Session)只在某一台收银机(服务器)里,换台机器就认不出来。
这件事换到计算机场景,就是所谓的Session问题:
当Nginx负载均衡将用户的访问压力分摊到不同的web服务器上时,每台服务器各自存一份 Session,如果用户前后的请求被Nginx分到不同服务器,就会读到两份不一样的 Session——数据瞬间清零,这就是 Session 问题。
解决办法就是将用户第一次访问的信息发送给nosql(缓存数据库),然后实现所有web服务器对它的共享
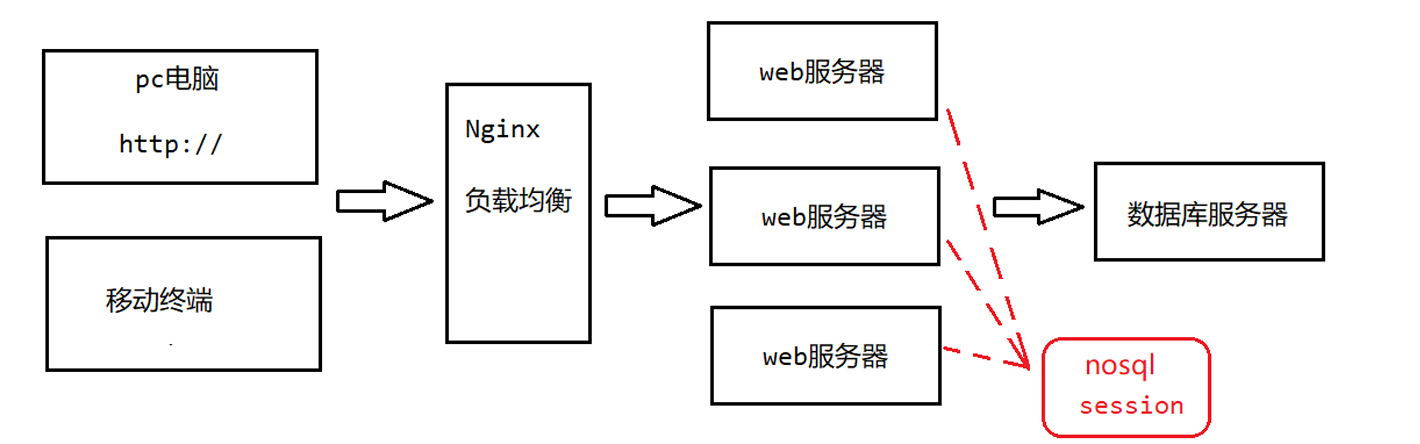
按刚才的例子来说,就是把会员卡信息放到所有店员都能查到的总机(Redis);
无论顾客被分到哪位店员,只要报出卡号,店员都能瞬间查到同一份资料,会员卡永远有效。
IO压力
继续上面的例子,解决了session问题,我们发现各台 Web 服务器虽然都能共享同一份 session 数据,但是效率还是很慢的,因为项目数据的日积月累,数据库里面的数据也越来越庞大,每一次的用户访问行为,Web服务器都要去缓存数据库查找一次,当用户访问量的增大,这消耗了大量的资源,这就是IO压力,针对这个问题,我们会把频繁查询的数据放入缓存,以后我们从缓存中取出数据即可,减少对数据库的访问压力。
如果还没明白的话,我依然搬出那个奶茶店的例子,一看就懂。
就像在服务员在听到进店的顾客报出他的会员卡号的时候,他就去翻一本厚厚的会员登录账本,顾客每一次刷卡,服务员都要去账本找,随着顾客和顾客的需求越来越多,店长发现了这个问题,他想了一个办法,解决了IO压力,
他把“最常被查的会员资料”先影印一份,贴在收银台前面的小黑板(缓存 Redis)上。以后顾客有要刷卡点单之类的需求,服务员先看小黑板,黑板上记录着积分和余额之类的数据(session),非常方便不需要再翻账本,只有黑板上没有的资料,才会去翻账本,翻完会补写到黑板,以供下一次方便取用。此时,IO压力骤降。
NoSql数据库的基本概述
什么是nosql数据库
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库。 NoSQL 不依赖业务 逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
nosql数据库有以下特点:(牺牲严格规矩,换来极限速度)
不遵循SQL标准。 不支持ACID(原子性,一致性,隔离性,持久性)。 远超于SQL的性能。
nosql的适用场景有:
对数据高并发的读写。 海量数据的读写。 对数据高可扩展性的。
但是,nosql的不适用场景如下:
需要事务支持。
基于sql的结构化查询存储,处理复杂的关系,需要sql查询。
常见的NoSql数据库
以下的特点分三方面来讲:数据放哪和持久化策略、数据结构、典型用途
Memcached
- 纯内存、不持久化
- 简单 key-value 缓存
- 典型用途:给持久化数据库做高速缓存
Redis
- 内存为主,支持 RDB/AOF 持久化
- key-value + 列表、集合、哈希、有序集合等数据结构
- 典型用途:缓存、计数器、消息队列、分布式锁等
MongoDB
- 文档型(类 JSON/BSON),schema-free
- 内存+磁盘混合存储,自动落盘
- 典型用途:内容管理、用户资料、日志、商品目录
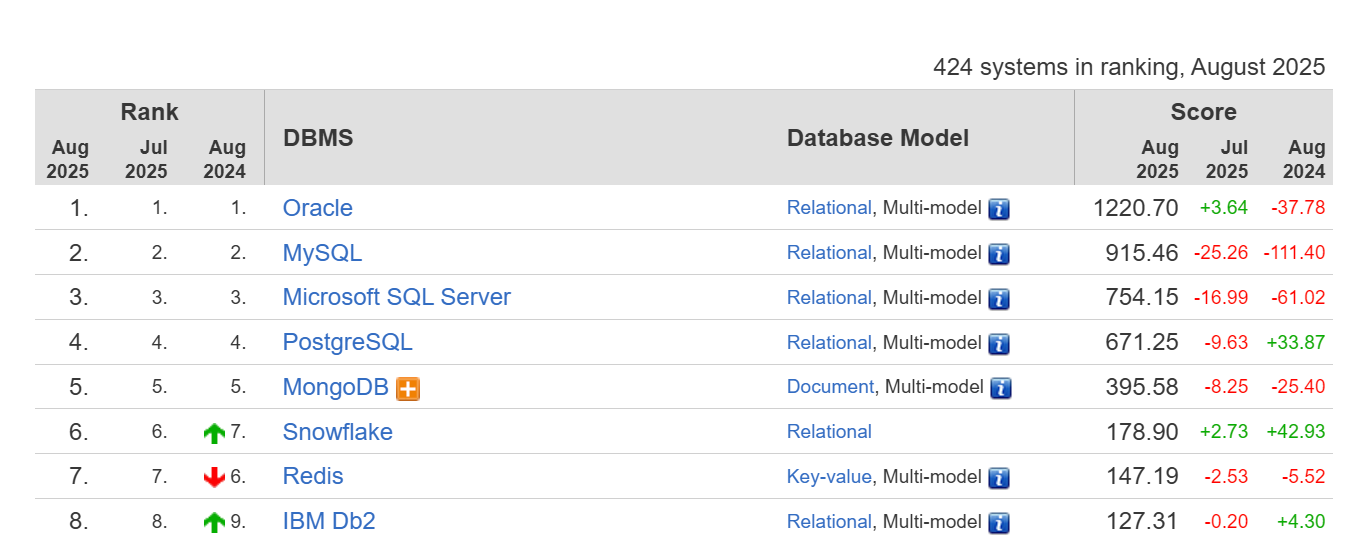
我们可以通过此链接查询最新的数据库排名:http:// https://db-engines.com/en/ranking
Redis的简单信息
Redis的全称为 Remote Dictionary Server,意为:远程字典服务。
类型为:开源 key-value 存储系统
支持的数据类型有:String、list、set、zset、hash
其特点为:
所有类型支持原子性读写、集合运算、排序等操作
数据常驻内存,保证高吞吐
周期性 RDB 快照或追加 AOF 日志实现持久化
支持主从复制(master-slave)
Redis的应用场景
| 应用场景 | 核心数据结构 | 实现思路与说明 |
|---|---|---|
| 获取最新数据 | List | 通过List实现按自然时间排序的数据 |
| 排行榜 | Zset (有序集合) | 使用 ZADD 添加成员及其分数(Score),自动排序。通过 ZRANGE 等命令获取排名。 |
| 时效性数据 | (所有类型) | 使用 EXPIRE为任何类型的 Key 设置过期时间,到期自动删除,适用于验证码、会话等。 |
| 计数器/秒杀 | String | 使用 INCR/DECR 等原子性操作命令,在高并发下安全地实现计数、库存扣减等。 |
| 去重 | Set (集合) | 利用 Set 内元素唯一的特性,使用 SADD 添加元素,天然实现去重。常用于过滤重复内容。 |
| 构建队列 | List | 使用 LPUSH 生产消息,RPOP 或 BRPOP 消费消息,实现简单的先进先出(FIFO)队列。 |
| 发布订阅 | Pub/Sub | 使用 SUBSCRIBE 订阅频道,PUBLISH 向频道发布消息,实现一对多的实时消息广播。 |
Redis的默认端口号为什么是6379?有兴趣可以参考下面这篇博文
https://blog.csdn.net/corleone_4ever/article/details/104120007
Redis安装在Linux操作系统
为什么Redis要安装在Linux操作系统上?因为Linux 本身就是 Redis 的开发、测试和默认部署环境,官方只给它打 Linux 版安装包和性能优化补丁;换别的系统,要么得自己编译、要么缺内核特性(如 epoll),速度也慢一截。
这里省略Redis的安装流程,默认的安装目录在/usr/local/bin
[root@noy001 redis-6.2.1]# cd /usr/local/bin
[root@noy001 bin]# ll
总用量 18844
-rwxr-xr-x. 1 root root 4833352 10月 1 18:13 redis-benchmark
lrwxrwxrwx. 1 root root 12 10月 1 18:13 redis-check-aof -> redis-server
lrwxrwxrwx. 1 root root 12 10月 1 18:13 redis-check-rdb -> redis-server
-rwxr-xr-x. 1 root root 5003368 10月 1 18:13 redis-cli
lrwxrwxrwx. 1 root root 12 10月 1 18:13 redis-sentinel -> redis-server
-rwxr-xr-x. 1 root root 9450208 10月 1 18:13 redis-server
了解这几个文件的用途:
redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何
redis-check-aof:修复有问题的AOF文件,rdb和aof后面再讲
redis-check-dump:修复有问题的dump.rdb文件
redis-sentinel:Redis集群使用
redis-server:Redis服务器启动命令
redis-cli:客户端,操作入口
Redis启动方案
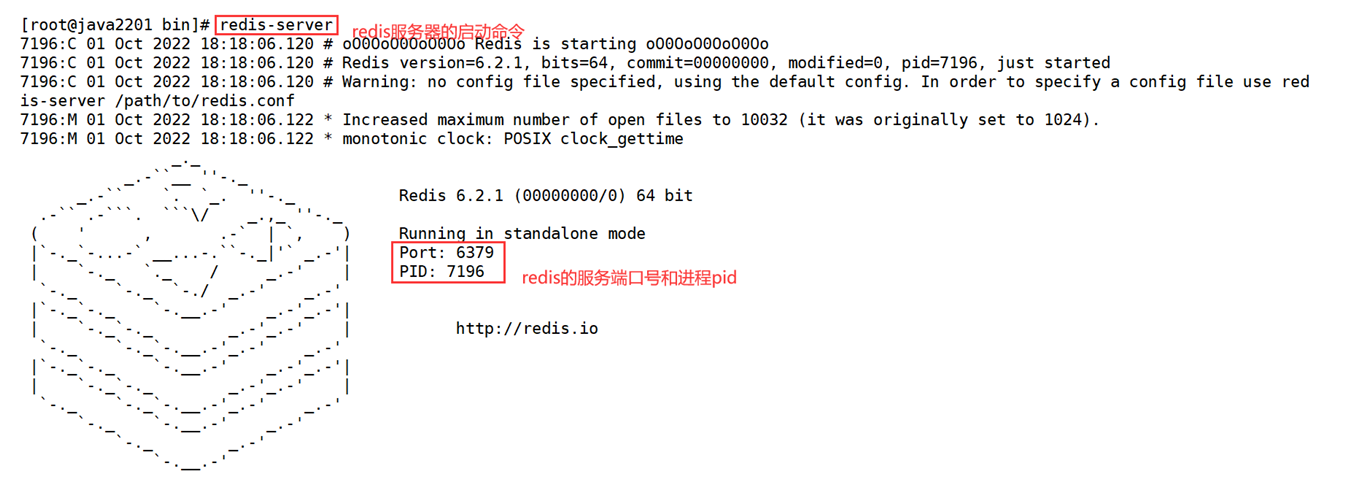
Redis前台启动(不推荐)
前台启动,命令行窗口不能关闭,否则服务器停止。
[root@noy001 bin]# redis-server将出现以下界面:
Redis前台启动(推荐)
[root@noy001 bin]# cd /opt/redis-6.2.1/
[root@noy001 bin]# cp redis.conf /usr/local/bin
[root@noy001 bin]# cd /usr/local/bin
[root@noy001 bin]# ll
这时bin目录就会有redis.conf文件了
编辑此文件,将后台启动设置daemonize no改成yes
[root@noy001 bin]# vim redis.conf
接下来启动redis:
[root@noy001 bin]# redis-server redis.conf
[root@noy001 bin]# ps -ef | grep redis # 查看redis的服务进程
root 7616 1 0 18:32 ? 00:00:00 redis-server 127.0.0.1:6379
root 7631 2427 0 18:32 pts/0 00:00:00 grep --color=auto redis
使用客户端连接redis 并且ping一下看看连上没有
[root@noy001 bin]# redis-cli # 使用redis自带客户端连接redis
127.0.0.1:6379> ping # 查看是否ping通redis服务器
PONG
关闭redis服务
[root@noy001 bin]# redis-cli shutdown # 关闭redis服务
[root@noy001 bin]# ps -ef | grep redis
root 7667 2427 0 18:37 pts/0 00:00:00 grep --color=auto redis
如果reids是多实例,,也可以指定端口关闭:
[root@noy001 bin]# redis-cli -p 6379 shutdown
在防火墙开放redis端口号6379的远程访问权限,这样就可以与外部的应用进行连接
[root@noy001 bin]# firewall-cmd --permanent --add-port=6379/tcp
success
[root@noy001 bin]# firewall-cmd --reload
success
[root@noy001 bin]# firewall-cmd --list-ports
3306/tcp 8080/tcp 6379/tcp
redis常用数据类型操作
redis基于key(键)的操作
127.0.0.1:6379> keys * # 查看当前数据库中所有的key值
(empty array)
127.0.0.1:6379> set k1 eric # 设置key值 值是string类型
OK
127.0.0.1:6379> set k2 james
OK
127.0.0.1:6379> set k3 kobe
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
3) "k3"
127.0.0.1:6379> type k2 # 查看指定key的数据类型
string
127.0.0.1:6379> exists k1 # 判断指定的key是否存在 存在就为1 不存在就为0
(integer) 1
127.0.0.1:6379> exists k4
(integer) 0
127.0.0.1:6379> del k3 # 删除指定的key值
(integer) 1
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
127.0.0.1:6379> expire k1 10 # 给key设置过期时间
(integer) 1
127.0.0.1:6379> ttl k1 # 查看指定key值的存活时期 不存在就为负数
(integer) 6
127.0.0.1:6379> ttl k1
(integer) -2
127.0.0.1:6379> select 0 # 切换到指定的数据库
OK
127.0.0.1:6379> dbsize # 查看当前数据库的key的数量
(integer) 1
127.0.0.1:6379> flushdb # 清空当前数据库
OK
127.0.0.1:6379> flushall # 清空所有的数据库
OK
redis中string的操作
Redis 的 String 类型是一种 key-value 结构,是Redis最基本的类型,一个 key 映射一个 value,value 可以是任何二进制数据,最大容量 512 MB,且完全二进制安全。
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set k1 eric # 给key设置String类型的值
OK
127.0.0.1:6379> set k2 kobe
OK
127.0.0.1:6379> get k1 # 根据key获取对象的value值
"eric"
127.0.0.1:6379> get k2
"kobe"
127.0.0.1:6379> set k1 james # 如果给一个已经存在的key设置值就是覆盖原来的值
OK
127.0.0.1:6379> get k1
"james"
127.0.0.1:6379> append k1 123 # 在指定key的值后面追加内容
(integer) 8 # 追加之后字符串的长度
127.0.0.1:6379> get k1
"james123"
127.0.0.1:6379> strlen k1 # 获取key的长度
(integer) 8
127.0.0.1:6379> setnx k1 miller # 当key不存在时value才会设置成功,否则设置不成功
(integer) 0 # 0表示没有设置成功
127.0.0.1:6379> get k1 # k1的值没有发生变化,因为key已经存在
"james123"
127.0.0.1:6379> setnx k3 curry # k3的值设置成功,因为之前不存在key3这个键
(integer) 1 # 1表示设置成功
127.0.0.1:6379> get k3
"curry"
127.0.0.1:6379> set num1 100
OK
127.0.0.1:6379> incr num1 # incr命令操作的值必须是数字类型;incr:对key自增1
(integer) 101
127.0.0.1:6379> get num1
"101"
127.0.0.1:6379> decr num1 # 对key进行自减操作
(integer) 100
127.0.0.1:6379> get num1
"100"
127.0.0.1:6379> incrby num1 5 # 对key进行增加,指定增加5
(integer) 105
127.0.0.1:6379> decrby num1 10 # 对key进行递减,指定减去10
(integer) 95127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # 批量设置k-v
OK
127.0.0.1:6379> mget k1 k2 k3 # 批量获取值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v11 k5 v5 # 只有所有的key都不存在才会设置,任意一个key存在都不会设置值
(integer) 0
127.0.0.1:6379> msetnx k4 v4 k5 v5
(integer) 1
127.0.0.1:6379> mget k4 k5
1) "v4"
2) "v5"
127.0.0.1:6379> set name LebronJames
OK
127.0.0.1:6379> getrange name 0 6 # 根据指定区间获取字符串的值 索引值从0开始
"LebronJ"
127.0.0.1:6379> getrange name 0 5
"Lebron"
127.0.0.1:6379> setrange name 0 kobe # 从指定索引值开始替换值
(integer) 11
127.0.0.1:6379> get name
"kobeonJames"
127.0.0.1:6379> setex k6 20 v6 # 设置key的值的同时,也设置过期时间
OK
127.0.0.1:6379> ttl k6
(integer) 16
127.0.0.1:6379> get name
"kobeonJames"
127.0.0.1:6379> getset name green # 使用新值替换旧值,但是返回旧值
"kobeonJames"
127.0.0.1:6379> get name
"green"
需要注意的是:incr命令是原子操作。也就是指不会被线程调度机制打断的操作。这种操作一旦开始,就一直运行到结束,中间不会有任何线程上下文切换。
在单线程中, 能够在单条指令中完成的操作都可以认为是"原子操作"。
而,Java中的i++不属于原子性操作
因为Java中的自增经历了以下三步:
- 第一步:取值 i = 0;
- 第二步:自加操作 i++;
- 第三步:将自加的操作结果赋予给i。
这里有一个经典的问题:
i = 0,两个线程对i分别进行i++100次。值是多少?(2-200)
最好的情况下两个线程互不打扰,一个线程结束另一个线程继续对i的操作,最后返回的值是200
而最坏的情况下,线程A和B几乎总是同时读到了相同的值。
它们都读到 i=0,都算出 1,都写回 1。两次操作只加了1次。
它们又都读到 i=1,都算出 2,都写回 2。又两次操作只加了1次。
... 如此重复。
因为 i++ 不是一步到位的操作,它被拆成了“读、改、写”三步。两个线程的这三步会随机交织在一起,导致某些增加操作被覆盖和丢失。
redis中list的操作
List列表是单键多值的列表。Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素 到列表的头部(左边)或者尾部(右边)。它的底层实际是个双向链表,对两端的操作性能很高,但是 通过索引下标操作中间的节点性能会较差。

127.0.0.1:6379> lpush k1 v1 v2 v3 # 从列表的左边追加元素 键是k1 值是v1 v2 v3
(integer) 3
127.0.0.1:6379> lrange k1 0 -1 # 查询列表中的所有元素
1) "v3"
2) "v2"
3) "v1"
127.0.0.1:6379> rpush k1 v4 v5 v6 # 从列表的右边追加元素 键是k1 值是v4 v5 v6
(integer) 6
127.0.0.1:6379> lrange k1 0 -1
1) "v3"
2) "v2"
3) "v1"
4) "v4"
5) "v5"
6) "v6"
127.0.0.1:6379> lpop k1 # 从左边弹出一个值并返回
"v3"
127.0.0.1:6379> rpop k1 # 从右边弹出一个值并返回
"v6"
127.0.0.1:6379> lpush k2 s1 s2 s3 # 创建k2列表 并追加值
(integer) 3
127.0.0.1:6379> lrange k2 0 -1
1) "s3"
2) "s2"
3) "s1"
127.0.0.1:6379> lrange k1 0 -1
1) "v2"
2) "v1"
3) "v4"
4) "v5"
127.0.0.1:6379> rpoplpush k1 k2 # 将k1列表最右边的值取出来,追加到k2列表的最左边
"v5"
127.0.0.1:6379> lrange k1 0 -1 # k1最右边的元素没有了
1) "v2"
2) "v1"
3) "v4"
127.0.0.1:6379> lrange k2 0 -1 # 查看k2集合,k2元素的最左边追加了元素v5
1) "v5"
2) "s3"
3) "s2"
4) "s1"
127.0.0.1:6379> lindex k2 2 # 根据指定下标获取元素
"s2"
127.0.0.1:6379> llen k2 # 获取指定列表的长度
(integer) 4
127.0.0.1:6379> linsert k2 before s2 v2 # 在k2列表中的s2元素前面追加元素v2
(integer) 5
127.0.0.1:6379> lrange k2 0 -1
1) "v5"
2) "s3"
3) "v2"
4) "s2"
5) "s1"
127.0.0.1:6379> lrem k2 1 s2 # 从左边删除指定个数的元素s2
(integer) 1
127.0.0.1:6379> lrange k2 0 -1
1) "v5"
2) "s3"
3) "v2"
4) "s1"
127.0.0.1:6379> lset k2 2 s2 # 将指定索引位置上的元素替换(将k2列表中2号索引位置上的元素替换成s2)
OK
127.0.0.1:6379> lrange k2 0 -1
1) "v5"
2) "s3"
3) "s2"
4) "s1"
list的数据结构
Redis 的 List 在元素少时用一整块连续内存的 ziplist 紧凑存放,
元素多时就切成若干段 ziplist,再用双向指针把这些段串成 quicklist,既省掉普通链表的每个节点 16 B prev/next 指针开销,又保留 O(1) 的插入删除效率。

redis中的set操作
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动去重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,
并且set提供了判断某个成员是否在一个set集合内的命令,这个也是list所不能提供的。 Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是 O(1)。(随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变)
127.0.0.1:6379> sadd s1 v1 v2 v3 # 向s1中添加元素 v1 v2 v3
(integer) 3
127.0.0.1:6379> smembers s1 # 查询集合中的所有元素
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> sadd s1 v3 # 添加重复元素,未成功
(integer) 0
127.0.0.1:6379> smembers s1
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> sismember s1 v1 # 判断集合是否存在某元素:存在返回1,不存在返回0
(integer) 1
127.0.0.1:6379> sismember s1 v7
(integer) 0
127.0.0.1:6379> scard s1 # 返回集合中元素的个数
(integer) 3
127.0.0.1:6379> srem s1 v1 v2 # 删除集合中指定的元素
(integer) 2
127.0.0.1:6379> smembers s1
1) "v3"# 以下演示需要 s1 先恢复为 v2 v3 v5,假设已恢复
127.0.0.1:6379> spop s1 # 随机弹出并移除集合中的一个元素
"v5"
127.0.0.1:6379> smembers s1
1) "v2"
2) "v3"# 再次恢复 s1 为 v2 v3 v5
127.0.0.1:6379> srandmember s1 2 # 随机查看2个元素,不移除
1) "v2"
2) "v5"
127.0.0.1:6379> smembers s1
1) "v2"
2) "v3"
3) "v5"127.0.0.1:6379> smove s1 s2 v5 # 将s1中的v5移动到s2
(integer) 1
127.0.0.1:6379> smembers s1
1) "v2"
2) "v3"
127.0.0.1:6379> smembers s2
1) "v1"
2) "v2"
3) "v3"
4) "v5"127.0.0.1:6379> sinter s1 s2 # 取s1与s2的交集
1) "v2"
2) "v3"
127.0.0.1:6379> sunion s1 s2 # 取s1与s2的并集
1) "v1"
2) "v2"
3) "v3"
4) "v5"
127.0.0.1:6379> sdiff s2 s1 # 取s2相对于s1的差集
1) "v1"
2) "v5"
set的数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
redis中的hash操作
Redis hash 是一个键值对集合。Redis hash是一个string类型的field和value的映射表,hash特别适合 用于存储对象。类似Java里面的Map。
根据这个需求做出解决方案:
需求:在redis里面保存一个用户对象( {id:1001,username:"eric",age=23} )。
方案1: 将user对象转换成一个json字符串,使用string来存储这个json字符串。
但是缺点是每次修改这个对象里面的数据,都需要把这个字符串转换成java对象修改,修改之后再转换成json字符串,比较麻烦,不适合频繁修改数据的场景。
方案2:通过key和对象属性拼接的方式存储数据:
key value
user:id 1001
user:username eric
user:age 23缺点:存储的数据分散,如果对象的属性过多,在redis中的key也会非常的多
方案3:通过redis中的hash类型的数据保存

通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。
hash的常用命令
127.0.0.1:6379> hset user id 1001 # 向hash中存储数据:key=user, field=id, value=1001
(integer) 1
127.0.0.1:6379> hget user id # 获取指定field的值
"1001"
127.0.0.1:6379> hmset user username eric age 23 # 批量添加field-value
OK
127.0.0.1:6379> hmget user username age # 批量获取field对应的value
1) "eric"
2) "23"
127.0.0.1:6379> hexists user username # 判断field是否存在:存在返回1,不存在返回0
(integer) 1
127.0.0.1:6379> hkeys user # 获取所有field
1) "id"
2) "username"
3) "age"
127.0.0.1:6379> hvals user # 获取所有value
1) "1001"
2) "eric"
3) "23"
127.0.0.1:6379> hdel user age # 删除指定field及其value
(integer) 1
127.0.0.1:6379> hget user age
(nil)
127.0.0.1:6379> hincrby user id 1 # 对field的值自增1
(integer) 1002
127.0.0.1:6379> hincrby user id -1 # 对field的值自减1
(integer) 1001
127.0.0.1:6379> hsetnx user age 25 # field不存在时设置成功,存在则失败
(integer) 1
127.0.0.1:6379> hsetnx user username james
(integer) 0
127.0.0.1:6379> hget user age
"25"
127.0.0.1:6379> hget user username
"eric"
hash的数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
redis中 的zset操作
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集 合中的成员。集合的成员是唯一的,但是评分可以是重复了。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
127.0.0.1:6379> zadd user 99 kobe 88 durant 82 curry # 添加元素到zset集合中
(integer) 3
127.0.0.1:6379> zrange user 0 -1 # 升序查看所有成员
1) "curry"
2) "durant"
3) "kobe"
127.0.0.1:6379> zrange user 0 -1 withscores # 升序查看所有成员及其分数
1) "curry"
2) "82"
3) "durant"
4) "88"
5) "kobe"
6) "99"
127.0.0.1:6379> zrangebyscore user 80 89 # 升序查看 80-89 分区间成员
1) "curry"
2) "durant"
127.0.0.1:6379> zrangebyscore user 80 89 withscores # 同上,含分数
1) "curry"
2) "82"
3) "durant"
4) "88"
127.0.0.1:6379> zrevrangebyscore user 100 1 # 降序查看所有成员
1) "kobe"
2) "durant"
3) "curry"
127.0.0.1:6379> zincrby user 12 kobe # 给 kobe 增加 12 分
"111"
127.0.0.1:6379> zrange user 0 -1 withscores
1) "curry"
2) "82"
3) "durant"
4) "88"
5) "kobe"
6) "111"
127.0.0.1:6379> zrem user kobe # 删除 kobe
(integer) 1
127.0.0.1:6379> zrange user 0 -1
1) "curry"
2) "durant"
127.0.0.1:6379> zcount user 0 100 # 统计 0-100 分区间的成员数
(integer) 2
127.0.0.1:6379> zrank user durant # 查看 durant 的排名(从 0 开始)
(integer) 1
127.0.0.1:6379> zrank user curry # 查看 curry 的排名
(integer) 0
zset的数据结构
zset底层使用了两个数据结构:
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素 value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
跳跃表是什么?
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。

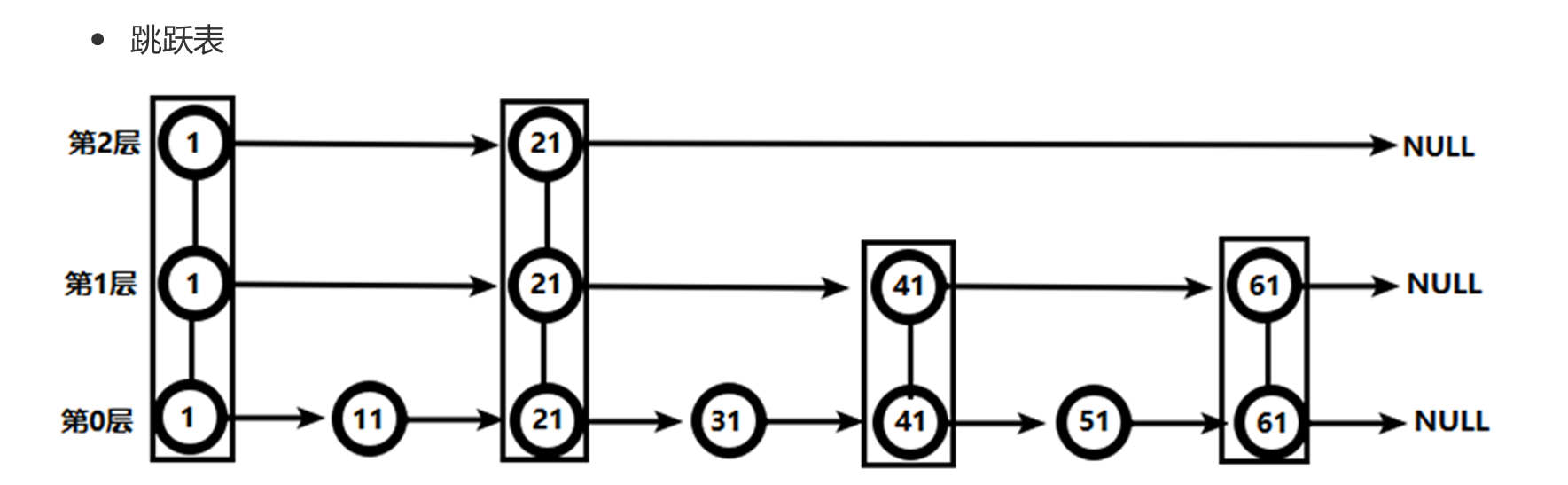
跳跃表像多层楼梯:最底层把所有节点排好序;上层隔几根柱子建“快速通道”,查询时先走高层大步跳,遇到比目标大的节点就降到下一层继续细找,直到最底层锁定位置,增删节点时同步维护这些层即可。
redis配置文件
redis.conf 就是 Redis 的启动脚本:一行一个指令,告诉它监听哪个端口、能占多大内存、多久把数据落盘、设什么密码,改完重启或 CONFIG REWRITE 就生效。
这里我的建议是尽量不要管它,有什么要改的多看看说明或者博客。
redis的发布和订阅
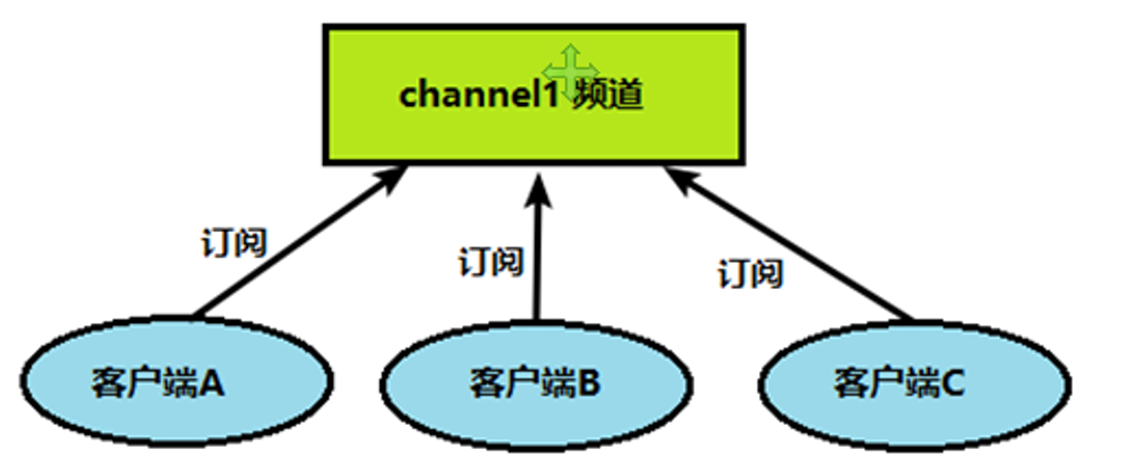
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。 Redis 客户端可以订阅任意数量的频道。
完成redis的发布和订阅需要两个步骤:
客户端(订阅者)需要订阅频道。
当发送者(生产者)给这个频道发布消息后,消息就会发送给订阅的客户端。
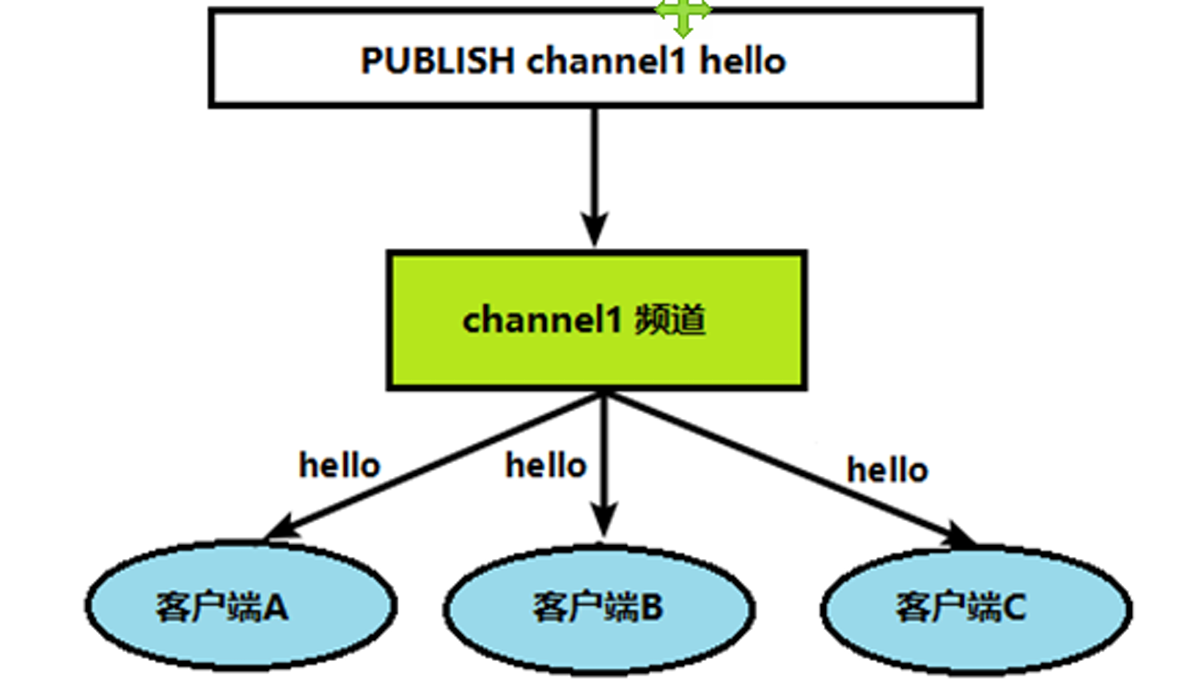
具体实现
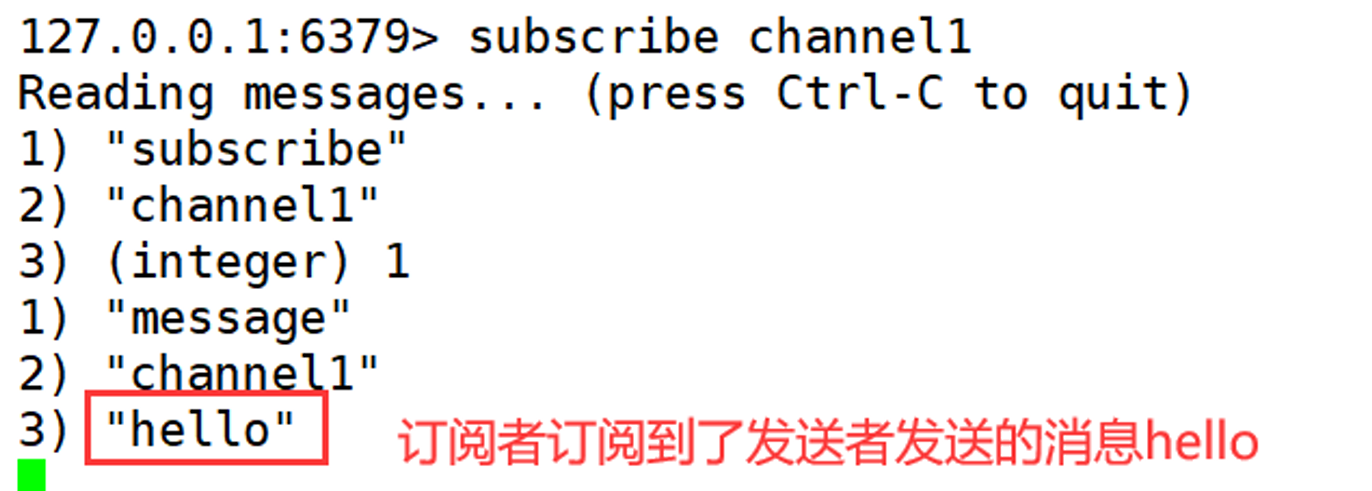
打开一个客户端1订阅channel1
[root@noy001 bin]# redis-cli
127.0.0.1:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
打开客户端2,发送消息hello
[root@noy001 bin]# redis-cli
127.0.0.1:6379> publish channel1 hello
(integer) 1
再次查看客户端1