五大主流ETL数据集成平台推荐
企业每日所面临的数据量呈爆炸式增长的态势,企业必须应对海量且持续增长的数据存储及处理需求。不仅如此,这些数据来源于诸多渠道,包括传统人为输入、传感器输入、社交媒体以及线上线下应用等。
这些海量且未经分类的数据如果仍然保留用户手工录入的方式,很容易产生质量参差不齐的问题。且企业内部处理数据的系统也多种多样,从ERP、CRM、MES等业务系统,到 MySQL、Oracle 等各异数据库,以及 SaaS 等云端平台,数据结构、存储形式与接口标准不同,相互间难以互联互通,极易造成数据孤岛的局面。

如何高效、准确地将不同系统间海量、混乱的数据整合到统一平台进行分析,是企业不得不解决的核心痛点。
一、为什么ETL是企业的“数据血脉”?
在当前的技术环境下,ETL技术是帮助企业高效整合数据的最好工具。
ETL 是大数据与数据仓库领域的核心数据处理流程,全称为Extract(抽取)、Transform(转换)、Load(加载),本质是将分散、异构的原始数据,标准化处理后整合到目标数据存储(如数据仓库、数据湖)的过程,为后续数据分析、报表生成提供高质量、一致性的数据基础。
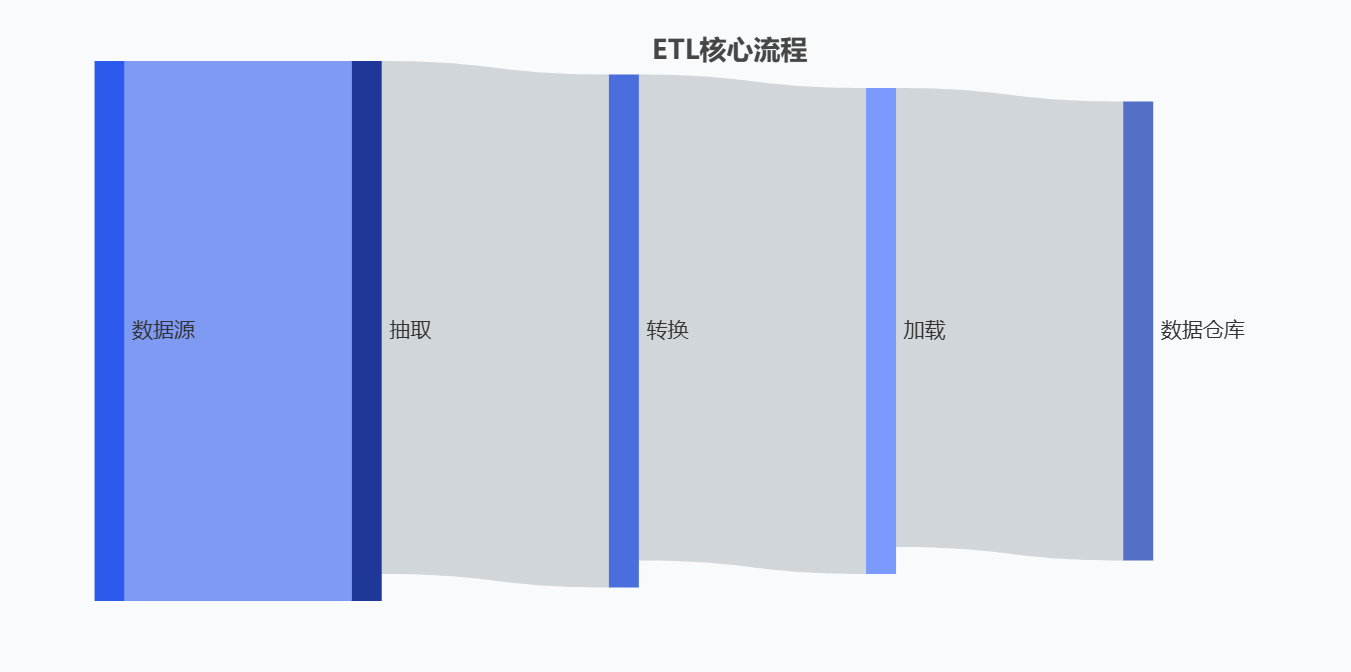
ETL对于企业来说,承担着“数据血脉”的作用。它能够像人体血脉输送养分一样,实现企业数据的“流转、净化、供给”,—— 解决企业数据从 “分散无序” 到 “集中可用” 的关键问题,为业务运转、决策优化提供持续且高质量的数据支撑。
1.破除数据孤岛,实现数据互联互通
企业内部的数据天然分散ERP、CRM、日志系统、API 接口中,人体各器官的血液若不流通便无法协同,企业内部各核心系统也是如此。而ETL工具通过“抽取(Extract)”环节将所有异构数据源连接起来,再通过“加载(Load)”将数据汇聚,打通企业数据的循环通道,实现企业内部数据互联互通,各系统协同并行。
2.提升数据质量,输出数据可用养分
企业内部的原始数据来源参差不齐,存在着一系列问题,比如含重复值、格式错误、存在缺失值等。而ETL 的核心环节 “转换(Transform)则承担着“数据净化”的重要职责,它能够对数据进行清洗、格式统一、关联计算等操作,持续输出高质量数据,为企业各种业务决策、分析提供**“数据养分”**。
3.保障数据实时性,支撑业务稳定运转
人体器官若是没有24小时持续输送血液,将会停止运作。而企业的业务决策,日常运营也是如此,ETL 通过定时调度(如每日凌晨抽取前一天数据)或实时同步(如流处理 ETL)机制,为企业提供稳定、持续的数据输出,支撑企业各业务稳定运转。
二、如何选择一款合适的ETL工具?
那么企业应该如何选择出一款适合自己的ETL工具呢,我认为可以从以下几个维度入手:
功能完整性:即ETL工具是否支持全流程ELT/ETL、以及实时同步、数据清洗转换等必要功能。
连接能力:考察ETL工具支持的数据源和目标库种类(传统数据库、云服务、API等)和数量是否达标。
易用性与学习曲线:既要能靠可视化界面 “点一点就用”,又要平衡对代码编写的需求——避免界面太简单满足不了复杂操作,也避免全靠代码让新手难上手。
扩展性与性能:即工具处理大规模数据的能力、稳定性与速度。
成本效益:许可模式(开源免费 vs. 商业付费)、总体拥有成本(TCO)。
厂商支持与社区生态:评判文档完善度是否达标、技术支持是否足够完备以及社区活跃度如何。
三、五大主流ETL平台深度解析与推荐
1. ETLCloud (RestCloud) - 国产化全能之星
核心定位:谷云科技推出的新一代全域数据集成平台,提供离线和实时数据集成、数据服务API开发的一体化解决方案。
-
完全自主可控:100%自主研发,支持信创环境(麒麟、统信OS、达梦、人大金仓等国产数据库),无版权风险。
-
高性能与高稳定:采用自研分布式传输引擎,支持自动分片、多通道传输和断点续传,经单一客户日传输200亿条数据的验证,在618/双11等大促场景中保持零故障记录。
-
开箱即用:提供可视化拖拽式开发界面,降低使用门槛,支持超过100种数据源,并具备整库迁移、自动建表、字段映射等强大功能。
-
实时与离线融合:不仅提供强大的离线ETL能力,还内置轻量级CDC实时数据捕获引擎,支持实时流与批量数据合并处理,满足实时数据分析需求。
-
强大的生态与社区:拥有国内最大的数据集成社区之一(etlcloud.cn),超20000家企业用户,经过大量实战场景验证。
适用场景:对数据安全、国产化、性能稳定性有高要求的企业,特别是金融、零售、制造、政务等涉及信创改造或拥有海量数据同步需求的行业。
成本提示:提供社区版(免费)和企业版(商业许可),支持多种部署方式(私有化、云),总体拥有成本(TCO)可控。

2. Apache NiFi (开源之星)
核心定位:强大的开源数据流管理工具,专注于数据路由和转换的自动化。
-
可视化数据流设计,拖拽即可实现复杂流程。
-
数据溯源(Data Provenance)功能极其强大,可追溯每个数据点的来源和处理过程。
-
高度可扩展和可配置,拥有庞大的处理器生态。
适用场景:物联网(IoT)数据接入、实时数据流处理、对数据溯源有极高要求的企业。
成本提示:开源免费,但需要自建基础设施和投入运维人力。
3. Talend (综合王者)
核心定位:提供开源和商业版的全能型数据集成平台。
-
产品矩阵丰富(Talend Open Studio, Data Integration, Big Data等),覆盖所有集成场景。
-
同时支持ETL和ELT,对云数据仓库(如Snowflake, BigQuery)优化极佳。
-
强大的数据质量和管理功能。
适用场景:中大型企业,需要处理复杂混合云环境(On-premise + Cloud)的数据集成项目。
成本提示:开源版免费,企业版功能强大但价格较高。
4. Informatica PowerCenter (企业级标杆)
核心定位:老牌、成熟、稳定的企业级数据集成解决方案。
-
极高的性能、稳定性和安全性,久经大型项目考验。
-
处理超大规模、复杂数据转换的能力无与伦比。
-
完善的元数据管理和治理功能。
适用场景:金融、电信等对数据可靠性、安全性和性能有极端要求的大型传统企业。
成本提示:传统的商业软件许可模式,总体拥有成本较高。
5. Fivetran / Stitch (ELT新贵)
核心定位:以“零运维”、“全托管”为特色的云原生ELT服务。
-
开箱即用,预置了数百个数据源连接器,配置简单。
-
完全托管,用户无需关心基础设施和运维,专注数据分析。
-
按使用量(如同步任务次数)付费,成本灵活。
适用场景:追求效率、希望快速上手、IT资源有限的中小企业或初创公司。
成本提示:SaaS模式,按需付费,初始成本低,但随着数据量增长费用会增加。
四、最适合您的,才是最好的
选择工具无绝对“最优”,只有“适配”—— 需贴合企业数据规模、业务场景与团队技术能力。
建议先启动 PoC(概念验证):用真实业务数据测试工具的核心功能(如 ETL 的抽取效率、分析工具的计算速度),验证是否匹配需求,亲身体验后再决策,避免盲目选型。