华东师范上海AiLab商汤!NaviMaster:学习适用于GUI和具身导航任务的统一策略
- 作者:Zhihao Luo1,2^{1,2}1,2, Wentao Yan1^{1}1, Jingyu Gong1^{1}1, Min Wang3^{3}3, Zhizhong Zhang1^{1}1, Xuhong Wang2^{2}2 , Yuan Xie1^{1}1, Xin Tan1,2^{1,2}1,2
- 单位:1^{1}1华东师范大学,2^{2}2上海人工智能实验室,3^{3}3商汤
- 论文标题:NaviMaster: Learning a Unified Policy for GUI and Embodied Navigation Tasks
- 论文链接:https://arxiv.org/pdf/2508.02046v1
主要贡献
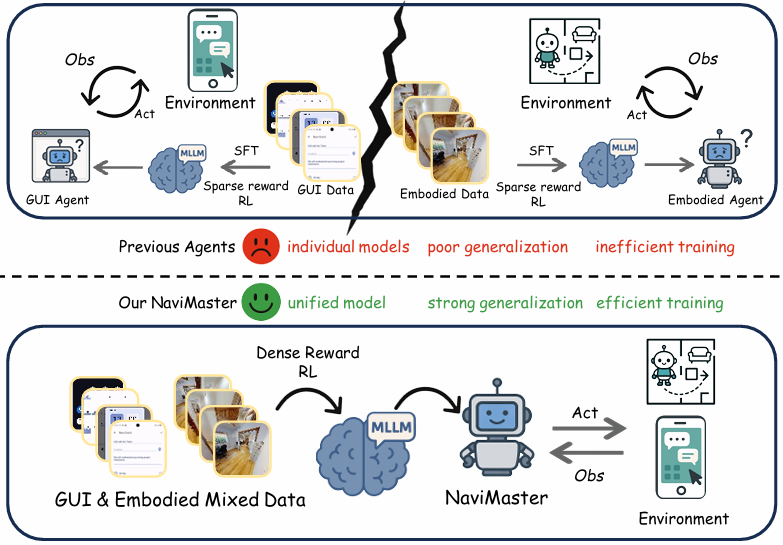
- 提出首个统一导航智能体NaviMaster,能够将基于GUI的导航和具身导航整合到一个通用框架中的统一导航智能体,打破了以往两者在数据集和训练范式上的孤立局面。
- 开发视觉目标轨迹收集管道流程,通过引入视觉目标,将GUI和具身导航轨迹统一为一种形式,增加了数据多样性,增强了模型的泛化能力。
- 设计距离感知密集奖励和统一强化学习框架,与传统的稀疏二元奖励相比,这种奖励设计能够根据响应与真实值的接近程度分配分数,从而提高导航智能体的训练效率和性能。
研究背景
- GUI导航与具身导航的现状:图形用户界面(GUI)导航智能体和具身导航智能体分别用于在虚拟和物理环境中导航。尽管两者在多模态大语言模型(MLLMs)的推动下取得了一定进展,但它们长期以来在数据集和训练策略上相互独立,导致了三个主要挑战:需要两个独立模型进行导航,增加了训练和部署成本,且无法实现任务间的协同交互;在特定任务数据内扩展数据虽能提升性能,但在跨任务时因对OOD数据的适应能力差而受限;强化学习优化效率低,因为以往的基于稀疏奖励信号的模型使得训练过程不够高效。
- 马尔可夫决策过程(MDP)的启发:GUI和具身导航任务都可以被表述为马尔可夫决策过程,这为它们的统一提供了基础。在这种统一的表述下,状态是每一步的观测,动作空间涵盖了与虚拟界面或物理环境的交互,且动作仅在当前状态下执行,满足马尔可夫性质。
NaviMaster
概述
NaviMaster 的核心在于将 GUI 和具身导航任务统一到一个框架中,具体通过以下三个关键组件实现:
- 视觉目标轨迹收集:通过引入视觉目标,将 GUI 和具身导航任务的轨迹统一为一种形式,并保留历史信息。
- 统一强化学习框架:同时优化跨场景的策略,使模型能够同时处理 GUI 和具身导航任务。
- 距离感知奖励:通过考虑输出点与目标点之间的距离来更新模型参数,提高训练效率和空间定位能力。
视觉目标轨迹收集
视觉目标轨迹收集是 NaviMaster 的基础,它包含三个主要部分:统一动作空间定义、轨迹初始化和推理思想生成。
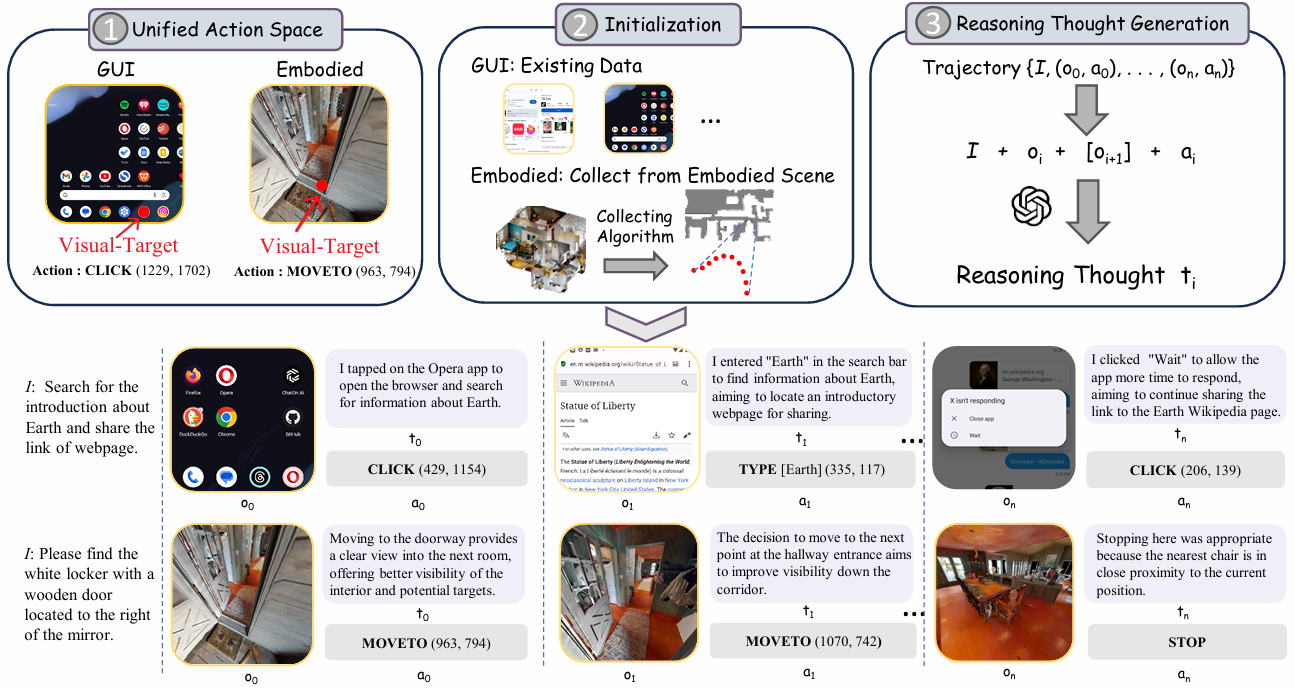
统一动作空间定义
- 现有的 GUI 和具身导航轨迹数据集在动作空间上存在显著差异。GUI 任务中的定位动作是通过 [CLICK (x, y)] 实现的,其中 (x, y) 表示目标位置;而具身导航任务中的定位动作是通过 [MOVEFORWARD] 实现的,不需要明确的目标位置。
- 为了弥合这种差异,NaviMaster 引入了视觉目标轨迹。在每一步的观测中定义一个具体的视觉目标,并将具身导航任务中的定位动作从 [MOVEFORWARD] 改为 [MOVETO (x, y)],其中 (x, y) 表示目标位置。这样,两种导航任务的动作空间就被统一了。
轨迹收集初始化
- GUI 任务:直接使用现有的 GUI 数据集(如 GUI-Odyssey)获取轨迹数据。这些数据集提供了用户指令、观测和动作的序列,可以直接用于训练。
- 具身导航任务:现有的具身导航数据集通常只提供初始位置和目标位置,而不提供中间轨迹。为了生成中间轨迹,NaviMaster 使用 A* 搜索算法从初始位置到目标位置提取最短路径上的点集 (s0, s1, …, sm)。每个点 sk (0 ≤ k ≤ m) 是一个全局坐标系中的 3D 坐标。
- 具体步骤:
- 根据当前位置 sk 和下一个位置 sk+1,计算 sk+1 在当前坐标系中的相对位置 s′k+1。
- 将 s′k+1 投影到当前观测图像 oi 中,得到像素坐标 (xi, yi)。
- 如果投影坐标不在观测图像范围内,调整相机角度(如左转、右转、转身、向下看等),直到目标点出现在观测范围内。
- 生成具身导航轨迹,使其与 GUI 导航轨迹具有相同的形式。
推理思想生成
- 历史信息对智能体性能至关重要。大多数现有方法仅使用动作作为历史信息,但这种方式可能导致歧义。例如,仅凭 [CLICK (x, y)] 动作无法明确表示交互的上下文或目的。
- NaviMaster 为每个动作生成推理思想,以增强推理能力和优化内存使用。具体来说,将任务指令 I、观测 oi 和动作 ai 提供给大型语言模型(如 GPT-4o),生成从第一人称视角解释执行该动作原因的意图 ti。例如,动作 [CLICK (x, y)] 可能对应推理思想 “我应该先打开 Chrome 以开始搜索”。
- 具体步骤:
- 对于每个初始化的轨迹,构建数据生成管道:⟨I,oi,ai,[oi+1]⟩→Mti\langle I, o_i, a_i, [o_{i+1}] \rangle \xrightarrow{\mathcal{M}} t_i⟨I,oi,ai,[oi+1]⟩Mti。
- 大型语言模型 M 根据输入生成推理思想 ti。
- 最终,视觉目标轨迹表示为 τ={I,(o0,t0,a0),…,(on,tn,an)}\tau = \{I, (o_0, t_0, a_0), \ldots, (o_n, t_n, a_n)\}τ={I,(o0,t0,a0),…,(on,tn,an)}。
统一强化学习框架
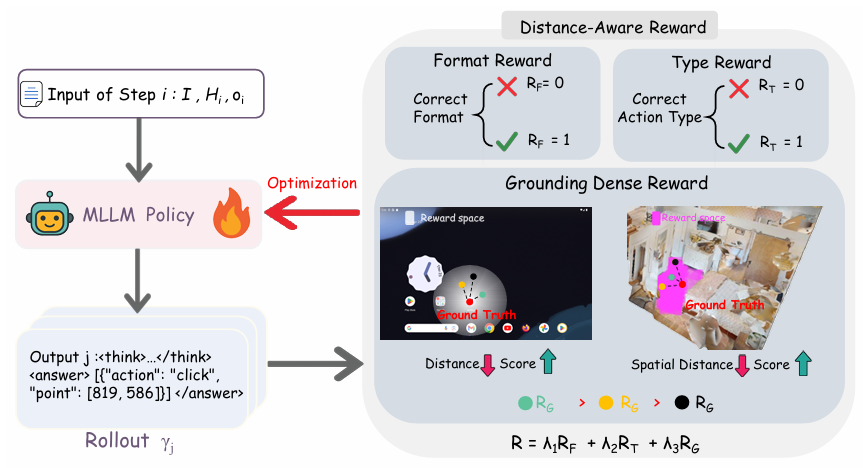
NaviMaster 采用强化学习(RL)来训练模型,因为 RL 通常比监督微调(SFT)具有更强的泛化能力。具体来说,NaviMaster 采用 R1-Zero 训练策略,直接在收集的数据集上使用组相对策略优化(GRPO)进行训练。
- R1-Zero:省略冷启动预训练,直接在收集的数据集上进行训练。
- GRPO:给定一个 n 步轨迹,将每一步 i 作为一个数据样本。每个样本包括用户指令 I、当前观测 oi、历史推理思想和动作 Hi={(t0,a0),(t1,a1),…,(ti−1,ai−1)}H_i = \{(t_0, a_0), (t_1, a_1), \ldots, (t_{i-1}, a_{i-1})\}Hi={(t0,a0),(t1,a1),…,(ti−1,ai−1)}。NaviMaster 使用 GRPO 学习统一策略。
- 奖励计算:
- 奖励函数 R(i,j)R(i, j)R(i,j) 用于评估响应的正确性。
- 优势值 Adv 通过标准化奖励计算:
Adv=R(i,j)−mean({R(i,j)}j=1G)std({R(i,j)}j=1G) Adv = \frac{R(i, j) - \text{mean}(\{R(i, j)\}_{j=1}^G)}{\text{std}(\{R(i, j)\}_{j=1}^G)} Adv=std({R(i,j)}j=1G)R(i,j)−mean({R(i,j)}j=1G) - 其中,G 是由策略模型 πθold\pi_{\theta_{\text{old}}}πθold 生成的样本数量。
距离感知奖励
NaviMaster 的奖励设计旨在提高模型的训练效率和空间定位能力。奖励被分解为三个部分:格式奖励、类型奖励和定位密集奖励。
-
格式奖励:
- 确保输出格式正确。每个响应必须先提供推理阶段,然后是一个有效的 JSON 字符串作为最终答案。如果满足格式要求,格式奖励 RF(i,j)R_F(i, j)RF(i,j) 为 1,否则为 0。
-
类型奖励:
- 评估模型的动作选择是否正确。这是一个二元奖励,用于监督模型在小的离散动作空间中做出高精度决策。如果预测的动作类型与真实动作类型匹配,则类型奖励 RT(i,j)R_T(i, j)RT(i,j) 为 1,否则为 0。
-
定位密集奖励:
- 指导模型的空间定位能力。这个奖励基于预测点与真实点之间的距离设计,避免了不必要的探索,并为训练提供有效指导。具体公式为:
RG(i,j)={1−djθd,如果 dj<θd 且 pj<θh,0,其他情况 R_G(i, j) = \begin{cases} 1 - \frac{d_j}{\theta_d}, & \text{如果 } d_j < \theta_d \text{ 且 } p_j < \theta_h, \\ 0, & \text{其他情况} \end{cases} RG(i,j)={1−θddj,0,如果 dj<θd 且 pj<θh,其他情况 - 其中,θd\theta_dθd 和 θh\theta_hθh 分别是距离和深度差异的阈值。djd_jdj 表示预测点 (x^j,y^j)(\hat{x}_j, \hat{y}_j)(x^j,y^j) 与真实点 (xi,yi)(x_i, y_i)(xi,yi) 之间的像素级距离,pjp_jpj 表示深度差异:
dj=(x^j−xi)2+(y^j−yi)2 d_j = \sqrt{(\hat{x}_j - x_i)^2 + (\hat{y}_j - y_i)^2} dj=(x^j−xi)2+(y^j−yi)2
pj=∣hi(x^j,y^j)−hi(xi,yi)∣ p_j = |h_i(\hat{x}_j, \hat{y}_j) - h_i(x_i, y_i)| pj=∣hi(x^j,y^j)−hi(xi,yi)∣
- 指导模型的空间定位能力。这个奖励基于预测点与真实点之间的距离设计,避免了不必要的探索,并为训练提供有效指导。具体公式为:
-
总奖励函数:
- 总奖励函数是三个奖励部分的加权组合:
R(i,j)=λ1RF(i,j)+λ2RT(i,j)+λ3RG(i,j) R(i, j) = \lambda_1 R_F(i, j) + \lambda_2 R_T(i, j) + \lambda_3 R_G(i, j) R(i,j)=λ1RF(i,j)+λ2RT(i,j)+λ3RG(i,j) - 其中,λ1,λ2,λ3\lambda_1, \lambda_2, \lambda_3λ1,λ2,λ3 是控制每个奖励部分相对重要性的超参数。
- 总奖励函数是三个奖励部分的加权组合:
实验
实验设置
- 模型训练:使用EasyR1框架,以Qwen2.5VL-7B模型作为基础模型,在8个NVIDIA A800 GPU上训练10个周期,全局批量大小为128,学习率为1×10^-6。训练仅使用了7000个样本,包括3500个GUI样本和3500个具身样本。
- 基准测试和评估指标:
- GUI任务:使用AC High/Low、AITW、GUIAct-Phone、LlamaTouch和AITZ等五个不同的智能体基准进行评估,主要评估指标为成功率(SR),同时报告类型(预测动作类型的准确性)结果,但指出该指标由于数据集偏差不可靠。
- 具身任务:通过空间可供性预测和具身导航两个任务评估模型性能。空间可供性预测任务使用RoboReflT、Where2Place、RoboSpatial和RefSpatial等基准,以预测点落在真实掩模内的平均成功率为评估指标;具身导航任务在ObjectNav基准上评估,使用SR和SPL(按逆路径长度加权的成功率)作为评估指标。
主要结果
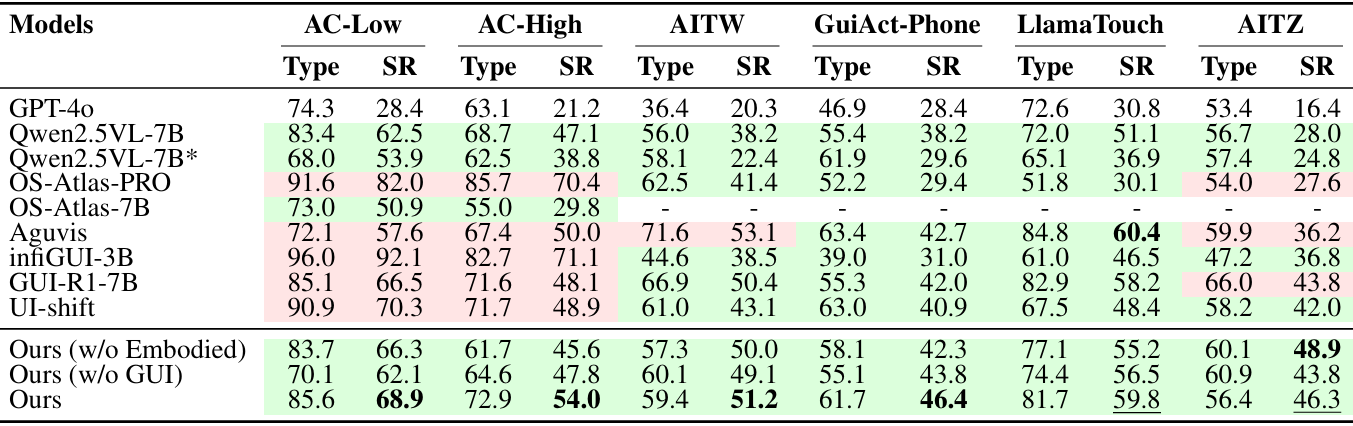
- GUI导航:在完全OOD的测试数据上,NaviMaster在SR指标上优于现有的最先进基线,展现出强大的泛化能力。与仅在GUI数据或具身导航数据上训练的模型相比,NaviMaster在混合数据上训练的模型在所有测试数据集上都取得了最高性能,证明了视觉目标轨迹和统一训练框架的有效性。
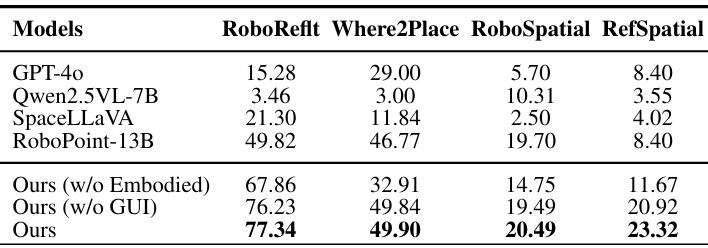
- 空间可供性预测:在四个空间可供性预测基准上,NaviMaster在所有基准上都取得了最佳性能,平均成功率为77.34%,49.90%,20.49%和23.32%,表明其在对象级和自由空间级的视觉 - 空间对齐方面表现出色。
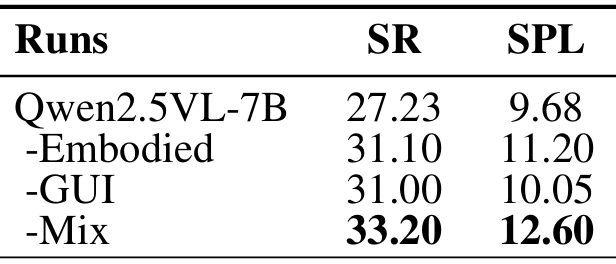
- 具身导航:由于是首次在VLMNav框架下训练能够泛化的智能体模型,没有直接的先前导航模型进行比较。NaviMaster在ObjectNav基准上取得了33.10%的最高SR和12.60%的SPL,相较于基础模型(27.23%SR/9.68%SPL)有显著提升。仅在具身数据或GUI数据上训练的模型SR略低(31.10%和31.00%),说明混合训练策略有效地利用了两种数据的互补优势。
消融研究
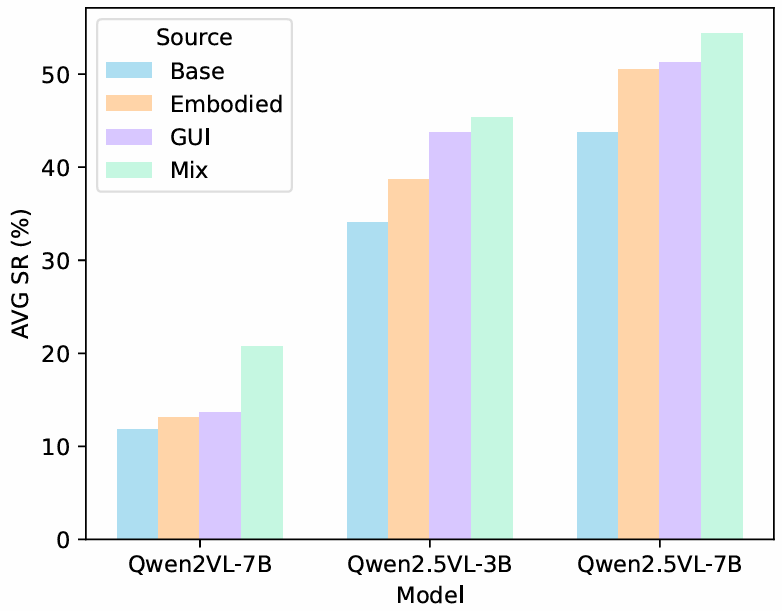
- 基础模型:在不同参数规模和预训练知识量的基础模型上评估框架,如Qwen2.5VL-3B和Qwen2VL-7B,结果表明,使用混合数据训练的模型在不同基础模型上都能取得一致的性能提升,且混合数据训练策略优于单数据类型训练策略。
-
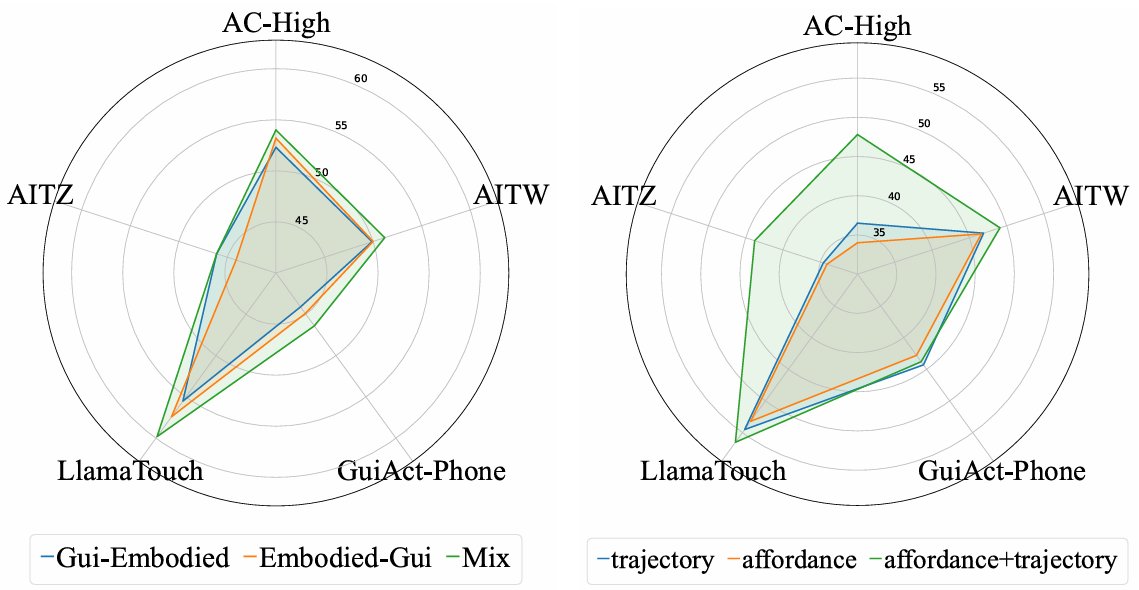
数据使用策略:比较了将不同类型数据或任务混合到一个训练阶段(Mix)和采用多阶段计划(GUI-Embodied或Embodied-GUI)两种策略。Mix策略在各种基准测试中表现优于两阶段训练策略,表明混合数据单阶段训练能使模型有效利用互补信息,实现更好的性能和泛化能力。
-
具身数据源:具身数据包括构建的轨迹数据和RoboPoint的空间可供性预测数据。实验结果表明,将两种数据源结合(affordance+trajectory)在总数据量相等的情况下,训练性能最佳。
-
奖励设计:将提出的定位密集奖励替换为稀疏奖励进行重新训练。结果表明,使用密集奖励训练的模型性能优于使用稀疏奖励的模型,且密集奖励设置下的奖励曲线上升更快,表明训练更高效。
结论与未来工作
- 结论:
- NaviMaster作为首个将GUI和具身导航整合到单一强化学习框架中的统一导航智能体,通过将两种导航类型重新表述为视觉目标轨迹格式,弥合了两个领域之间的差距,实现了联合训练和跨任务泛化。
- 此外,提出的距离感知密集奖励设计提高了学习效率和空间定位能力。广泛的实验结果表明,NaviMaster在OOD泛化方面优于现有的最先进方法。
- 未来工作:
- 尽管NaviMaster在GUI和具身导航任务的性能上取得了显著提升,但它仍然将GUI和具身导航视为两个不同的任务,且由于收集难度,轨迹数据集中缺乏将GUI和具身导航任务交错的单一轨迹。
- 未来的工作应致力于构建能够同时与GUI和具身环境交互的导航智能体。
