王树森深度强化学习DRL(一)RL基本概念+价值学习
【王树森】深度强化学习(DRL)_哔哩哔哩_bilibili
目录
一、基本概念 状态、动作、奖励
二、实践:倒立杆+悬崖漫步
三、DQN Deep Q-Network 近似Q*
3.1 Temporal Difference (TD) Learning TD训练
3.2 DQN-倒立杆实战
一、基本概念 状态、动作、奖励
状态(State):以《超级马里奥》游戏为例,状态可被定义为描述游戏在某一时刻下的完整信息集合。例如,马里奥所处的具体空间位置、剩余生命值、关卡剩余时间等均可构成状态变量。状态刻画了环境的瞬时特征,为智能体的决策提供了依据。
动作(Action):动作指智能体在给定状态下可执行的操作集合。在马里奥游戏中,这些操作通常由玩家通过控制器输入触发,例如向左或向右移动、跳跃、下蹲等。每一个动作都会改变游戏的进程并可能引发不同的状态转移。
奖励(Reward):奖励是环境在智能体执行某一动作后返回的数值反馈信号,用于评价该动作在当前状态下的优劣。在马里奥的情境中,奖励可能体现为获得增益(如吃到蘑菇增加生命值),或成功躲避敌人从而存活。奖励函数的设计直接影响智能体策略的优化方向。
状态转移(State Transition):状态转移描述了环境在智能体执行特定动作后由当前状态演化至下一状态的过程。在马里奥中,这可能表现为角色通过跳跃跨越障碍、进入传送管道切换场景,或与敌人交互后导致状态变量(如生命值)发生变化。
策略(Policy):策略是智能体在不同状态下选择动作的映射规则。它决定了在特定情境下应采取何种行动以实现目标。例如,当面临深坑时,最优策略可能为执行跳跃操作以避免失败。在强化学习框架下,策略可通过交互经验逐步更新,以最大化长期累积奖励。
环境(Environment):环境包含了所有与智能体交互的外部因素与约束条件,包括游戏场景(平台、管道)、非玩家控制角色(敌人)、物理机制以及奖励信号生成机制。智能体与环境的交互构成了马尔可夫决策过程(MDP)的基本要素。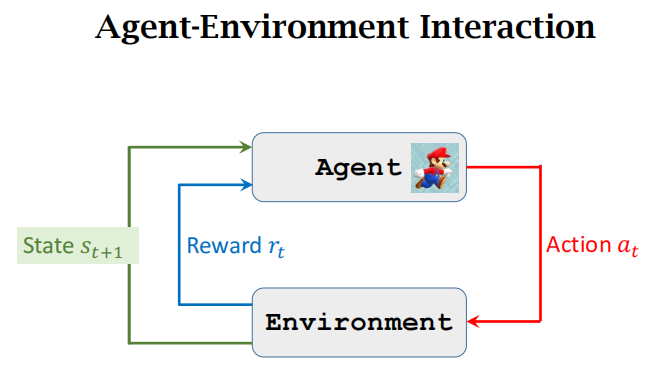
整个过程就是:在状态state 选择一个动作action 得到奖励reward 进入状态s'(不断重复)
目的是最大化从现在开始的 奖励ΣR,但是现在比未来更值钱 所以未来会乘以系数γ
(比如是现在给你100 还是说几天后给你100 以后的价值乘以比例系数)
![]()
1. policy策略 π(a|s) = P(A=a|S=s) 在状态s下进行行动a的概率
2. state transition状态转移 在状态s进行a后 转换到s'的概率
上两者是 行动的随机性+状态转移的随机性
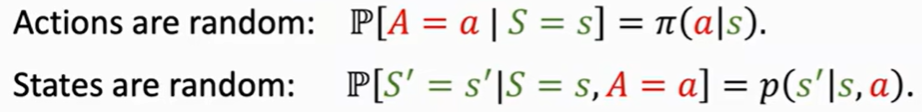
3. 动作价值函数 已知当前策略π 评估(在状态s执行状态a)的价值U (衡量动作a的好坏)
U还需要知道未来的s和未来的a 对未来的概率进行积分 其实就是U的期望值

4. 最优-动作价值函数 所有π中最大的Q(仅和现在的s a 有关)
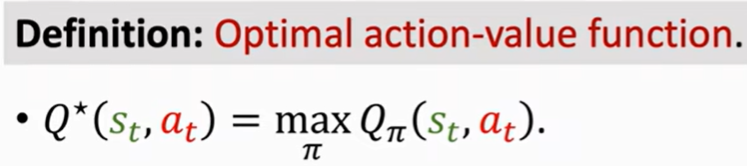
5. 状态价值函数 对随机变量A求期望;衡量策略π下 当前的状态s的好坏

Vπ 是衡量S的;而好的π可以发挥出当前S的优势;
对随机变量S求期望 下面的E可以衡量π的好坏
![]()
6. AI 如何控制 Agent呢?或者说 如何在当前状态s下选取行动a呢?
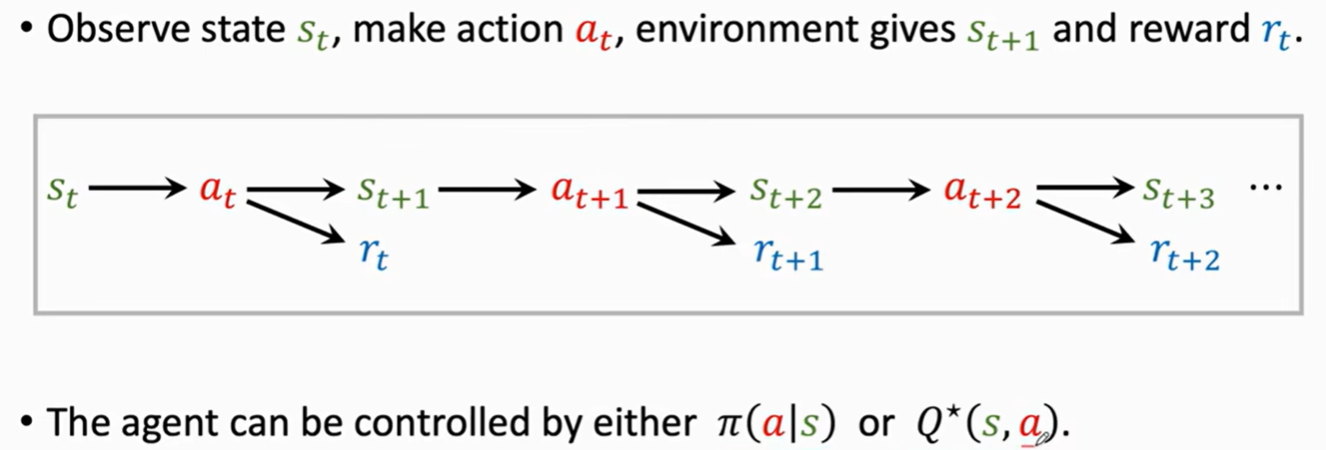
第一种是策略学习 假设已知π(a|s) 每次我可以知道s下A的概率分布 并随机抽样得到行为a
第二种是价值学习 假设已知最优-动作价值函数 Q* 每次都执行价值最优的那个a
7. 关键概念总结为下图


二、实践:倒立杆+悬崖漫步
CartPole 小车-倒立杆实践(控制小车左右使得杆子不倒)
# pip install gymnasium pygame 安装库
import gymnasium as gymenv = gym.make('CartPole-v1', render_mode="human") # 创建小车-倒立杆环境
state = env.reset() # 初始化环境,返回初始状态print(env.action_space) # Discrete(2) 动作空间为离散的2个动作for _ in range(1000):env.render()action = env.action_space.sample() # 随机选择一个动作observation, reward, terminated, truncated, info = env.step(action)# 执行动作 返回信息# observation环境状态 [小车位置 小车速度 杆子角度 杆子角速度]# reward是奖励值,terminated表示是否游戏结束,truncated表示是否被截断print(observation, reward, terminated, truncated)if terminated or truncated: # 如果游戏结束或被截断,则退出循环breakenv.close()
CliffWalking(悬崖漫步)


import gymnasium as gym# - render_mode='ansi' 表示返回字符网格,直接 print 即可看到地图
env = gym.make('CliffWalking-v1', render_mode='ansi')# observation 是离散状态编号(0..47),info 是附加信息
obs, info = env.reset()# 只有在未封装环境上才有 P(状态转移字典),因此用 env.unwrapped.P
# 结构:P[s][a] = [(prob, next_state, reward, terminated), ...]
P = env.unwrapped.Pfor step in range(100):# 随机动作空间 Discrete(4):0=上, 1=右, 2=下, 3=左action = env.action_space.sample()# 与环境交互一步,返回:# - obs: 下一个状态编号(0..47)# - reward: 奖励(普通一步 -1;掉悬崖 -100)# - terminated: 是否自然终止(掉崖或到达终点) - truncated: 是否达步数上限而被截断obs, reward, terminated, truncated, info = env.step(action)# 文本渲染(字符网格),包含智能体当前位置、起点、终点、悬崖等frame = env.render()print(frame, end="") # 直接打印网格到终端# 打印一步的关键信息,帮助理解执行过程print(f"step={step}, obs={obs}, reward={reward}, terminated={terminated}, truncated={truncated}")# 终止或截断就退出循环if terminated or truncated:break# 清理环境资源
env.close()
三、DQN Deep Q-Network 近似Q*
value-based 价值学习 假设已知Q* (Q是给动作的打分)
像一个先知 知道怎么做期望最大 就这样action。
比如怎么买股票 有一个先知说 知道所有股票涨的期望 那我们一定就买 涨的期望最大的股票。

challenge:不知道Q* 用Q(s,a,w)近似
状态s是输入 输出对不同action的打分 评判标准是reward奖励。

训练过程就像是 玩一万次超级玛丽 通过reward信息训练网络。
(强化学习就是通过奖励更新模型参数 让模型越来越强)
经过卷积 Dense输出每个类别(每个动作)打分
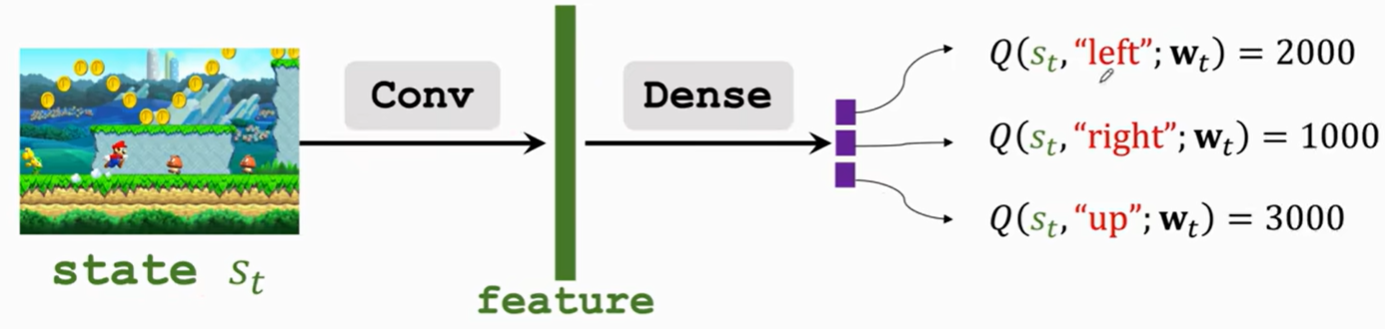
训练好网络Q后就可以:对s选a* 再状态转移到s' 再选a'* 一直往后
3.1 Temporal Difference (TD) Learning TD训练
比如一个距离计算问题 网络预测 A->C 的距离调优 网络预测1000 实际860
可以用平方差作为 loss 再梯度下降学习训练。
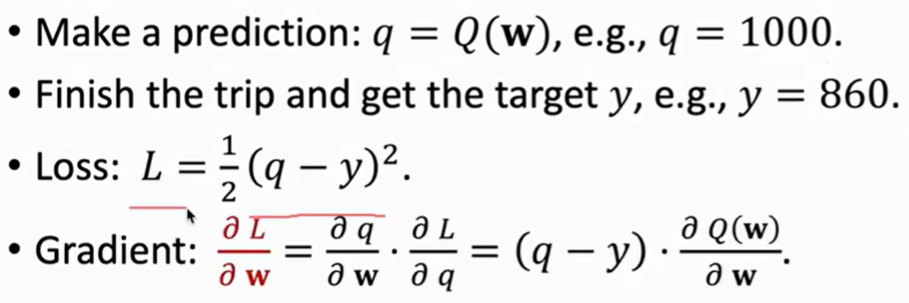
但如果我知道 A->B 实际是300 B->C 预测是600
所以这个300(实际)+600(预测)比原来的1000更靠谱 可以作为参数更新,
可以用900 对 1000进行上面的平方差梯度下降学习。
把这种用 真实actual(1-2)+估计estimate(2-3) 更新 估计estimate(1-3)的思想拿过来

现在得到R 后面一个时间段的U整体提出一个γ
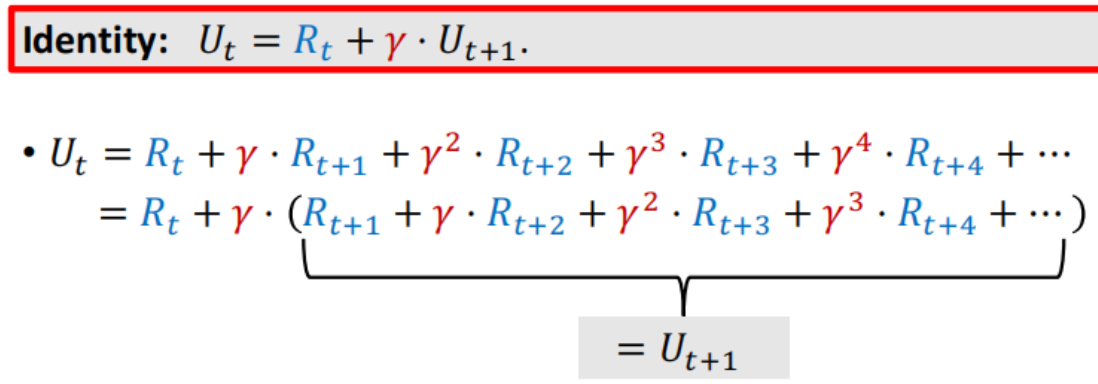
Q=E(U) 上式两边取期望 t时刻预测; 之后奖励r结算+ t+1时刻预测 进行更新


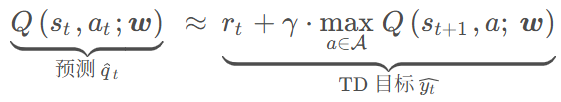
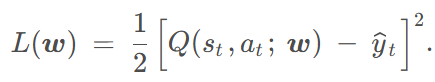
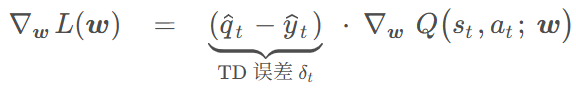 即差值乘原导数
即差值乘原导数

3.2 DQN-倒立杆实战
HyperParams.py 参数设定
import torchclass HyperParams:lr = 3e-3 # 学习率num_episodes = 300 # 训练回合数hidden_dim = 128 # 神经网络隐藏层的维度gamma = 0.97 # 折扣因子,控制未来奖励的折扣程度eps = 0.01 # epsilon-greedy 策略中的 epsilon(探索的概率)target_update_frequency = 10 # 每多少回合更新目标网络的权重buffer_capacity = 1000 # 经验回放缓存的容量batch_size = 64 # 每次训练时抽取的经验批量大小minimal_size = 500 # 经验回放缓存的最小大小,直到可以开始训练device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")ReplayBuffer.py 存储智能体与环境交互中产生的经验,并从中随机抽取一批经验进行训练
# 经验回放(Experience Replay)存储智能体与环境交互中产生的经验,并从中随机抽取一批经验进行训练
from collections import deque
from random import sample
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity) # 使用双端队列(deque)来存储经验,最大长度为capacitydef add(self, state, action, reward, next_state, terminated, truncated):self.buffer.append([state, action, reward, next_state, terminated, truncated])# 将一个经验元组添加到缓冲区中def sample_batch(self, batch_size):transitions = sample(self.buffer, batch_size) # 从缓冲区中随机抽取一批经验return transitionsdef size(self):return len(self.buffer)Qnet.py网络 通过全连接层、激活函数、批归一化和 Dropout 计算输出 Q 值。
使用 kaiming_normal_ 进行He 初始化每一层的权重;
LeakyReLU(x)=max(αx,x) 替代 ReLU(x)=max(0,x) 使得负数也有小斜率
from torch.nn import Linear, Module, LayerNorm, LeakyReLU, Dropout
from torch.nn.init import kaiming_normal_class Qnet(Module):def __init__(self, state_dim, hidden_dim, action_card):super(Qnet, self).__init__()self.fc1 = Linear(state_dim, hidden_dim)self.fc2 = Linear(hidden_dim, hidden_dim)self.fc3 = Linear(hidden_dim, action_card)self.leaky_relu = LeakyReLU(negative_slope=0.01)self.dropout = Dropout(0.5)self.layer_norm1 = LayerNorm(hidden_dim) # 使用 LayerNormself.layer_norm2 = LayerNorm(hidden_dim)kaiming_normal_(self.fc1.weight, mode='fan_in', nonlinearity='leaky_relu')kaiming_normal_(self.fc2.weight, mode='fan_in', nonlinearity='leaky_relu')kaiming_normal_(self.fc3.weight, mode='fan_in', nonlinearity='leaky_relu')def forward(self, x):x = self.layer_norm1(self.fc1(x)) # 批归一化x = self.leaky_relu(x) # LeakyReLU 激活函数x = self.dropout(x) # Dropout 防止过拟合x = self.layer_norm2(self.fc2(x)) # 第二层批归一化x = self.leaky_relu(x) # LeakyReLU 激活函数x = self.fc3(x) # 输出层return x__init__.py
class DQN init初始化赋值参数;
take_action 以 eps 的概率选择随机动作(探索)
以 1 - eps 的概率选择当前 Q 网络输出的最佳动作。
update 从经验回放缓存中抽取一批经验进行训练;损失函数;反向传播;
一段时间后更新目标网络(不太频繁 为了训练稳定性)
先Qnet和Targetnet 都初始化,固定Targetnet 训练Qnet,一段步数之后,把Qnet赋值给Targetnet
import sys
sys.path.append('D:/RL/mlimpl-master')
from numpy.random import random, randintimport gymnasium as gym
from torch import tensor, float32, empty, int64
from torch.nn.functional import mse_loss
from torch.optim import Adam
from ReinforcementLearning.DQN.Qnet import Qnet
from ReinforcementLearning.DQN.ReplayBuffer import ReplayBuffer
from ReinforcementLearning.DQN.HyperParams import HyperParamsclass DQN:def __init__(self, state_dim, hidden_dim, action_card, lr, gamma, eps, target_update_frequency, device="cuda:0"):# 初始化 DQN 智能体的参数self.action_card = action_card # 动作空间的大小self.state_dim = state_dim # 状态空间的维度self.gamma = gamma # 折扣因子,用于计算未来奖励self.eps = eps # epsilon-greedy 策略中的 epsilon,用于平衡探索和利用self.target_update_frequency = target_update_frequency # 更新目标网络的频率self.count = 0 # 记录目标网络更新的次数self.device = device # 设备选择,通常是 GPU 或 CPU# 创建 Q 网络和目标网络,分别用于当前的 Q 值估计和目标 Q 值的计算self.q_net = Qnet(self.state_dim, hidden_dim, self.action_card).to(device)self.target_net = Qnet(self.state_dim, hidden_dim, self.action_card).to(device)# 使用 Adam 优化器来优化 Q 网络self.optimizer = Adam(self.q_net.parameters(), lr=lr)def take_action(self, state):# 以 eps 的概率选择随机动作(探索)if random() < self.eps:action = randint(self.action_card)else: #以 1 - eps 的概率选择当前 Q 网络输出的最佳动作state = tensor(state, dtype=float32).to(self.device).unsqueeze(0) # 获取当前状态action = self.q_net(state).argmax().item() # 获取当前状态下的Q*对应最佳动作return actiondef update(self, transitions):# 从经验回放缓存中抽取一批经验进行训练batch_size = len(transitions)# empty创建张量states, actions, rewards, next_states, terminateds, truncateds = empty((batch_size, self.state_dim),device=self.device), empty(batch_size, dtype=int64, device=self.device), empty(batch_size, dtype=int64,device=self.device), empty((batch_size, self.state_dim), device=self.device), empty(batch_size, dtype=int64,device=self.device), empty(batch_size, dtype=int64, device=self.device)for i, transition in zip(range(batch_size), transitions):states[i], actions[i], rewards[i], next_states[i], terminateds[i], truncateds[i] = tensor(transition[0]), tensor(transition[1]), tensor(transition[2]), tensor(transition[3]), tensor(transition[4]), tensor(transition[5])# 损失函数 loss = 1/2nΣ[r + max_{a'}target_Q(s', a') - Q(s,a)]dqn_loss = mse_loss(self.q_net(states).gather(1, actions.view(-1, 1)).flatten(),(rewards + self.gamma * self.target_net(next_states).max(1)[0] * (1 - terminateds) * (1 - truncateds)))# 反向传播self.optimizer.zero_grad()dqn_loss.backward()self.optimizer.step()if self.count % self.target_update_frequency == 0: # 一段时间后更新目标网络self.target_net.load_state_dict(self.q_net.state_dict())self.count += 1main函数 创建环境;经验回放缓存;状态空间;动作空间
每次训练(玩一次):while循环直到 游戏结束或被截断
选择action,step转移,保存replay数据,加奖励;
replay中有足够的经验 则进行sample采样并update
if __name__ == "__main__":# 创建 CartPole 环境,render_mode="rgb_array" 表示返回环境图像env = gym.make("CartPole-v1", render_mode="rgb_array")# 创建一个经验回放缓存,用于存储智能体与环境的交互数据replay_buffer = ReplayBuffer(HyperParams.buffer_capacity)state_dim = env.observation_space.shape[0] # 状态空间的维度(状态向量的大小)action_card = env.action_space.n # 动作空间的大小(动作的数量)# 初始化 DQN 智能体,传入状态维度、隐藏层维度、动作空间大小等超参数agent = DQN(state_dim, HyperParams.hidden_dim, action_card, HyperParams.lr, HyperParams.gamma,HyperParams.eps, HyperParams.target_update_frequency, HyperParams.device)# 进行训练,循环多个回合for i in range(HyperParams.num_episodes):episode_return = 0 # 每个回合的总奖励state = env.reset()[0] # 获取环境的初始状态# 在每个回合中进行多次步进,直到回合结束while True:action = agent.take_action(state)next_state, reward, terminated, truncated, _ = env.step(action) # 执行动作,获得反馈 replay_buffer.add(state, action, reward, next_state, terminated, truncated)# 累加当前回合的奖励episode_return += rewardif terminated or truncated:breakstate = next_state# 如果回放缓存中积累了足够的经验(超过最小经验数量),开始更新网络if replay_buffer.size() > HyperParams.minimal_size:transitions = replay_buffer.sample_batch(HyperParams.batch_size) # 从回放缓存中随机抽取一个批次的经验agent.update(transitions) # 使用这个批次的经验来更新 Q 网络# 每 10 个回合输出一次当前回合的总奖励if (i + 1) % 10 == 0:print("episode:{}, episode_return:{}.".format(i, episode_return))# 关闭环境env.close()
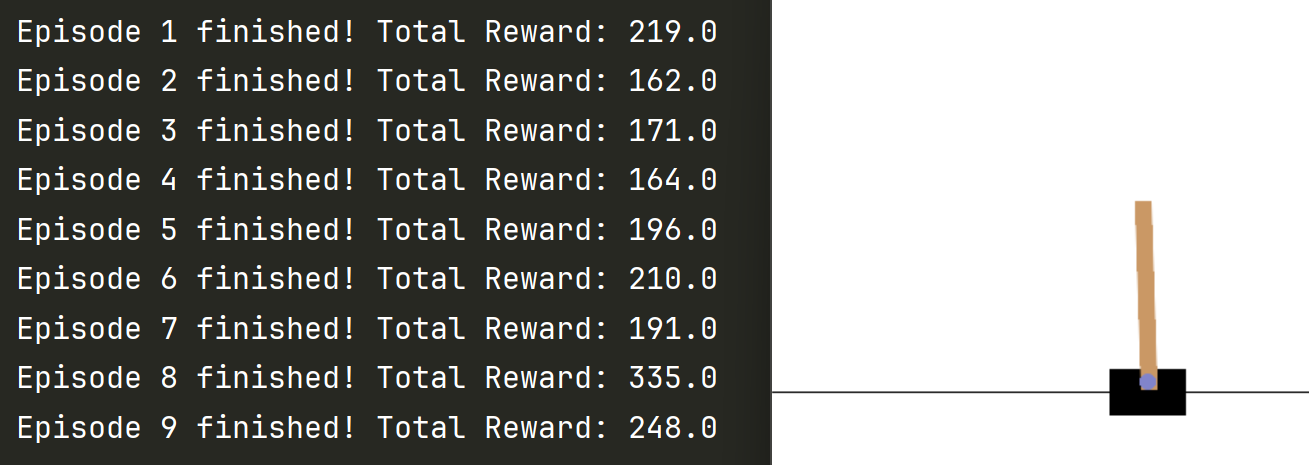
最后用训练好的DQN 可视化跑倒立杆
# 用训练好的DQN 可视化跑倒立杆env = gym.make("CartPole-v1", render_mode="human") # 创建环境并设置渲染模式为 "human"for i in range(10): # 运行10个回合进行评估state = env.reset()[0] # 获取初始状态episode_reward = 0 # 每个回合的总奖励while True:env.render() # 渲染环境以显示图形界面action = agent.take_action(state) # 获取智能体的动作next_state, reward, terminated, truncated, _ = env.step(action) # 执行动作并获取反馈episode_reward += reward # 累加当前回合的奖励# 如果回合结束或达到最大步数,则跳出循环if terminated or truncated:print(f"Episode {i + 1} finished! Total Reward: {episode_reward}")breakstate = next_state # 更新状态50个epoch后 就可以跑到200分左右