【图像算法 - 14】精准识别路面墙体裂缝:基于YOLO12与OpenCV的实例分割智能检测实战(附完整代码)
摘要: 裂缝是结构健康的重要隐患,传统人工巡检耗时耗力且易遗漏。本文将带您利用当前最先进的YOLO12实例分割模型,构建一个高效、准确、更高精度的裂缝检测系统。我们将从数据准备、模型训练到结果可视化,手把手实现一个完整的项目,代码开源,开箱即用!
关键词: YOLO12, 实例分割, 裂缝检测, 计算机视觉, 深度学习, PyTorch, OpenCV
【图像算法 - 14】精准识别路面墙体裂缝:基于YOLO12与OpenCV的实例分割智能检测实战(附完整代码)
1. 引言:裂缝检测的挑战与AI的机遇
桥梁、道路、建筑墙体等基础设施的裂缝是评估其安全状况的关键指标。及时发现并量化裂缝信息对于预防性维护至关重要。然而,传统的人工目视检查方法存在效率低、主观性强、危险性高等缺点。
近年来,深度学习,特别是目标检测和语义/实例分割技术,为自动化裂缝检测提供了强大的工具。相比于目标检测只能给出裂缝的边界框,实例分割能够精确到像素级别,不仅能定位裂缝,还能描绘其精确的轮廓、长度、宽度甚至面积,为后续的损伤评估提供更丰富的信息。
在众多先进的模型中,YOLO12凭借其速度快、精度高、易于部署的特点脱颖而出。其暂无内置的分割模型。在保持YOLO系列高效推理速度的同时,实现了卓越的分割性能,非常适合部署在无人机、巡检机器人或边缘设备上进行实时检测。
本文将详细介绍如何使用 YOLO12 网络来训练一个专门用于裂缝检测的实例分割模型。

2. 技术选型:为什么是YOLO12实例分割?
- YOLO12 (You Only Look Once 12): 是YOLO系列的最新迭代。YOLO12 引入了一种以注意力为中心的架构,它脱离了之前 YOLO 模型中使用的传统 CNN 方法,但保留了许多应用所必需的实时推理速度。该模型通过在注意力机制和整体网络架构方面的创新方法,实现了最先进的目标检测精度,同时保持了实时性能。
- 实例分割 (Instance Segmentation): 不仅区分前景(裂缝)和背景,还能区分不同个体的裂缝(即使它们靠得很近)。这对于密集裂缝场景(如混凝土表面)尤为重要。
- Ultralytics库: 提供了极其简洁的API,使得数据准备、模型训练、验证和推理变得异常简单,大大降低了开发门槛。
3. 数据准备:高质量标注是成功的关键
数据是深度学习的基石。对于裂缝分割,我们需要带有像素级掩码标注的数据集。(资源下载)
本次使用的裂缝分割数据集分为三个子集:
- 训练集: 包含 3717 张带有相应注释的图像。
- 测试集:112 张带有相应注释的图像。
- 验证集:包含 200 张带有相应注释的图像。

3.1 数据集获取
- 公开数据集:
- Crack500: 常用的裂缝检测数据集,包含500张图像。
- CFD (Crack Forest Dataset): 包含200张高分辨率图像,常用于裂缝分割和密度估计。
- DeepCrack: 包含3000+张图像,规模较大。
- Concrete Crack Images for Classification: 虽然主要用于分类,但可作为补充。
- 自建数据集: 使用无人机、相机拍摄真实场景的裂缝图片,更具实际应用价值。
3.2 数据标注
- 工具推荐: LabelMe, CVAT, Roboflow。
- labelme数据标注保姆级教程:从安装到格式转换全流程,附常见问题避坑指南(含视频讲解)
- 标注要求: 为每一张图像中的每一条裂缝绘制精确的多边形轮廓(Polygon)。标注工具会生成对应的JSON或COCO格式的标注文件。
- 数据格式: YOLO12支持 COCO格式 或其自定义的 YOLO格式(文本文件,每行代表一个实例:
class_id center_x center_y width height+ 多个x y坐标对表示分割点)。我们通常使用COCO格式。
3.3 数据集划分与组织 将数据集划分为训练集(train)、验证集(val)和测试集(test)。典型的划分比例是 70%:15%:15% 或 80%:10%:10%。
组织目录结构如下:
crack_dataset/
├── images/
│ ├── train/ # 训练集图像
│ ├── val/ # 验证集图像
│ └── test/ # 测试集图像
└── labels/├── train/ # 训练集标签 (COCO JSON 或 YOLO txt)├── val/ # 验证集标签└── test/ # 测试集标签
3.4 数据增强 (Data Augmentation) Ultralytics YOLO12在训练时默认应用了强大的数据增强策略(如Mosaic, MixUp, 随机旋转、缩放、裁剪、色彩抖动等),这有助于提高模型的泛化能力,防止过拟合,尤其在数据量有限时效果显著。
- Mosaic
- 当你看到 mosaic: 1.0,这意味着在数据增强过程中使用了 Mosaic 技术,并且其强度或概率设置为最大值(1.0)。Mosaic 数据增强方法通过将四张图片随机裁剪并拼接成一张图片来创建新的训练样本。这有助于模型学习如何在不同的环境中识别目标,特别是当对象只占据了图像的一部分时。
- MixUp
- 对于 mixup: 0.0,这表示不使用 Mixup 方法或者该方法的应用概率为最低(0.0)。Mixup 是一种更温和的数据增强策略,它通过线性插值的方式在两张图片及其标签之间生成新的训练样本。例如,如果你有两张图片 A 和 B,Mixup 可能会生成一个新的图片 C,其中 C 的像素是 A 和 B 像素的加权平均值。
4. 模型训练:使用YOLO12
4.1 环境搭建
【图像算法 - 01】保姆级深度学习环境搭建入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)
4.2 配置文件 (data.yaml) 创建一个 crack_segmentation.yaml 文件,描述数据集路径和类别信息:
# 数据集路径
path: ./crack_dataset # 数据集根目录
train: images/train # 训练集图像相对路径
val: images/val # 验证集图像相对路径
test: images/test # 测试集图像相对路径 (可选)# 类别信息
names:0: crack # 类别名称,索引从0开始
4.3 开始训练 使用一行命令即可启动训练!Ultralytics提供了丰富的参数供调整。
from ultralytics import YOLO# 加载已训练的YOLO12分割模型
model = YOLO('yolo12-seg.yaml') # 推荐使用s或m版本在精度和速度间平衡# 开始训练
results = model.train(data='crack_segmentation.yaml', # 指定数据配置文件epochs=100, # 训练轮数imgsz=640, # 输入图像尺寸batch=16, # 批次大小 (根据GPU显存调整)name='crack_seg_v1', # 实验名称,结果保存在 runs/segment/crack_seg_v1/device=0, # 使用GPU 0, 多GPU用 [0, 1, 2]# 以下为可选高级参数# optimizer='AdamW', # 优化器# lr0=0.01, # 初始学习率# lrf=0.01, # 最终学习率 (lr0 * lrf)# patience=20, # EarlyStopping 耐心值# augment=True, # 是否使用Mosaic等增强 (默认True)# fraction=1.0, # 使用数据集的比例# project='my_projects', # 结果保存的项目目录
)
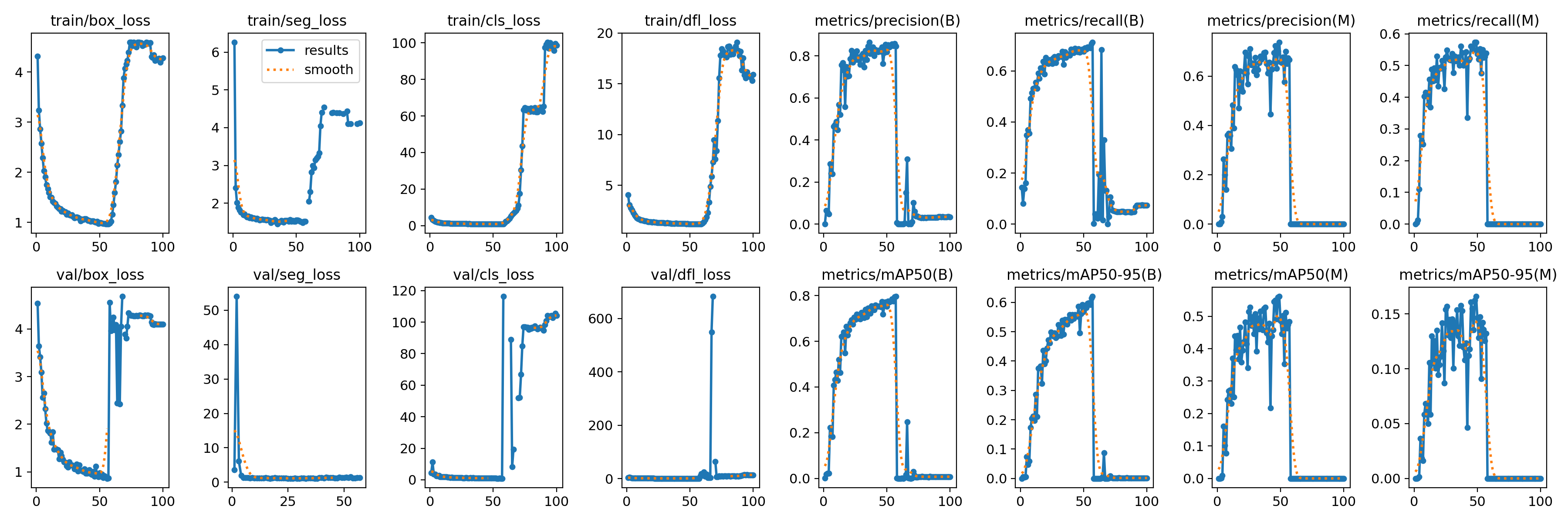
4.4 训练过程监控
- 训练过程中,Ultralytics会实时打印损失值(
box_loss,seg_loss,cls_loss,dfl_loss)和评估指标(precision,recall,mAP50,mAP50-95)。 - 在
runs/segment/crack_seg_v1/目录下会生成详细的训练日志、指标曲线图(如results.png)和最佳权重文件(weights/best.pt)。
5. 模型验证与推理
5.1 验证模型性能 训练完成后,使用验证集评估模型:
# 加载训练好的最佳模型
model = YOLO('runs/segment/crack_seg_v1/weights/best.pt')# 在验证集上评估
metrics = model.val()
print(metrics.box.map) # mAP50 for detection
print(metrics.seg.map) # mAP50 for segmentation
print(metrics.box.map50_95) # mAP50-95 for detection
print(metrics.seg.map50_95) # mAP50-95 for segmentation
5.2 进行推理 (检测新图像)
# 加载模型
model = YOLO('runs/segment/crack_seg_v1/weights/best.pt')# 对单张图像进行预测
results = model('path/to/your/test_image.jpg', imgsz=640, conf=0.25) # conf: 置信度阈值# 结果可视化
for r in results:# 方法1: 使用Ultralytics内置的plot方法 (快速显示)im_array = r.plot() # 绘制边界框、分割掩码、标签im = Image.fromarray(im_array[..., ::-1]) # BGR to RGBim.show() # 显示图像# 方法2: 获取分割掩码进行自定义处理masks = r.masks # Segmentation masks objectif masks is not None:mask_array = masks.data.cpu().numpy() # 形状: (num_instances, H, W)# 对mask_array进行后续处理,如计算裂缝长度、宽度、面积等# 例如,计算每条裂缝的像素面积:for i, mask in enumerate(mask_array):area = mask.sum() # 像素面积print(f"Crack {i} area: {area} pixels")

5.3 批量推理
# 对整个文件夹进行预测
results = model.predict(source='path/to/test_images_folder/', save=True, save_txt=True, imgsz=640, conf=0.25)
# save=True: 保存带标注的图像
# save_txt=True: 保存预测结果到txt文件 (可选)
6. 结果分析与应用
- 可视化效果: 训练好的模型能清晰地分割出裂缝的精确轮廓,即使裂缝非常细长或相互交叉。
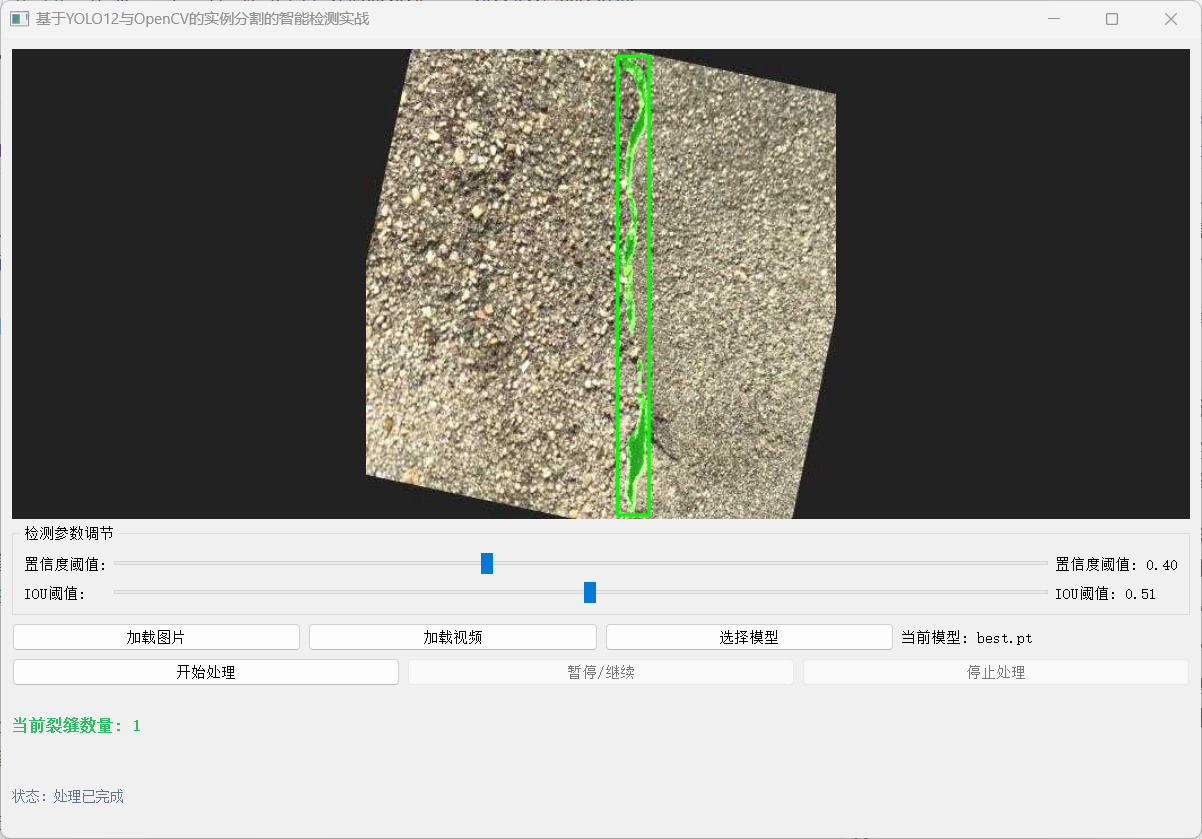
-
量化分析:
基于分割出的掩码,可以计算:
- 裂缝长度: 通过骨架化或主成分分析(PCA)估算。
- 裂缝宽度: 在垂直于长度的方向上测量。
- 裂缝面积: 直接统计掩码内像素总数。
- 裂缝密度: 单位面积内的裂缝长度或面积。
-
应用场景:
- 无人机自动巡检桥梁、大坝、风电叶片。
- 隧道、地铁墙体的自动化检测。
- 混凝土结构的健康监测系统。
- 与BIM模型结合,进行数字孪生管理。
7. 总结与展望
本文详细介绍了如何利用 YOLO12实例分割模型 构建一个高效的裂缝检测系统。通过高质量的数据标注、合理的模型选择和参数配置,我们能够训练出精度高、鲁棒性强的模型。
优势:
- 精度高: 像素级分割提供精确的裂缝轮廓。
- 速度快: YOLO12保证了实时或近实时的检测速度。
- 易用性: Ultralytics API 极大简化了开发流程。
- 可扩展: 框架可轻松迁移到其他分割任务。
挑战与改进方向:
- 小裂缝检测: 极细的裂缝可能难以检测,可尝试更高分辨率输入或专用小目标检测技术。
- 复杂背景: 阴影、污渍、纹理可能被误检,需要更丰富的训练数据和更强的特征提取能力。
- 泛化能力: 模型在不同光照、材质、拍摄角度下的表现需持续优化。
- 3D信息: 结合深度信息(如RGB-D相机)可估计裂缝深度。
未来展望: 随着YOLO系列和Transformer架构的不断发展,裂缝检测的精度和效率将进一步提升。结合边缘计算和5G技术,实时、大规模的基础设施智能巡检将成为现实。