【机器学习深度学习】归一化层
目录
前言
一、什么是归一化?
为什么需要归一化层?
二、为什么向量模长要归一化?
三、余弦相似度的计算过程(类比版)
四、归一化层在哪些模型中用?
五、常见归一化类型
六、归一化的实际好处
七、可视化理解
八、类比理解
1. 物理类比:速度
2. 文本向量类比(NLP 里)
3. 图像特征类比
九、总结

前言
在深度学习、向量检索、图像处理等领域,“归一化”几乎无处不在。它像一个幕后裁判,悄悄地调整数据的“尺度”,让模型的计算和比较更加稳定、公平。
本文将带你深入理解归一化的意义、类型、数学原理,以及它在向量模型中的特殊地位,并通过生活类比帮你记牢。
一、什么是归一化?
归一化(Normalization) 是一种数据预处理或网络层操作,用来将输入数据按照一定规则调整到相同或可比的尺度。
目的:
-
消除无关因素的影响:不同特征值范围差异大,会让模型偏向某些特征。
-
加快训练收敛速度:数据分布稳定,优化更平稳。
-
提升比较的公平性:在向量相似度计算中尤为重要。
类比:归一化就像体育比赛前的“量级分组”,让选手在公平的条件下比拼实力,而不是比体重。
二、为什么需要归一化层?
归一化层的作用
本质是让数据分布更稳定、更可比,这样模型的计算和比较才不会被一些“无关因素”干扰。
生活类比:
想象你在跑步比赛里比速度,但有人跑的是 100 米,有人跑的是 200 米——直接比“用的时间”是不公平的,因为距离不一样。
归一化层就像是统一赛道长度,这样大家只比真正想比的部分(速度),而不是被其他因素(距离不同)干扰。在向量模型里,这个“赛道长度”就是向量的模长。
类比:
想象你和朋友比谁的箭射得方向更接近靶心。如果箭长短不一,光看箭尖位置不公平。归一化就是先把箭都剪成一样长,再比角度。
三、为什么向量模长要归一化?
在向量检索里,我们经常用余弦相似度衡量两个向量的相似度:
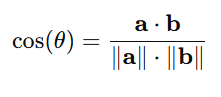
是两个向量的点积
是各自的模长(向量的“长度”)
如果不归一化:
模长大的向量会“天然”在点积里占便宜,即使方向不一样,相似度可能也会变高。
模长小的向量,即使方向完全一致,分数也可能低。
归一化就是把每个向量的模长都调成 1:
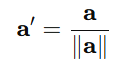
这样余弦相似度计算时:
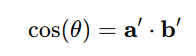
模长完全不影响分数,比较只看方向差异。
四、余弦相似度的计算过程(类比版)
数学版步骤:
计算点积
计算各自的模长
代入公式
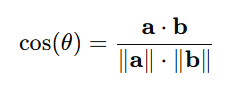
生活类比:
想象你和朋友各自拿着一支箭(箭的方向是向量的方向,箭的长度是向量的模长):
箭的方向 → 表示“语义的意思”
箭的长度 → 表示“语义的强度”
余弦相似度就是看两支箭的夹角:
如果方向完全一样(夹角 0°),相似度 = 1
如果方向相反(夹角 180°),相似度 = -1
如果方向垂直(夹角 90°),相似度 = 0
归一化就是把所有箭都修剪成一样长,这样比较的时候只看方向,不受长度影响。
| 向量属性 | 生活类比 | 在相似度里的作用 |
|---|---|---|
| 方向 | 箭头的指向 | 表示“语义内容” |
| 长度(模长) | 箭的长度 | 表示“语义强度” |
| 归一化 | 把箭剪成统一长度 | 让比较公平,只看方向差别 |
| 余弦相似度 | 箭的夹角余弦值 | 越接近 1 → 越相似 |
五、归一化层在哪些模型中用?
| 模型类型 | 是否常用归一化层 | 用途 |
|---|---|---|
| 向量模型(Embedding / Sentence-BERT) | ✅ 几乎必用 | 确保向量模长一致,方便余弦相似度计算 |
| 图像分类(CNN) | ✅ 常用 BN | 稳定训练,提升精度 |
| NLP 语言模型(Transformer) | ✅ 常用 LN | 防梯度爆炸/消失,稳定训练 |
| GAN / 图像生成 | ✅ 常用 BN / IN | 保持生成分布稳定 |
| 推荐系统 | ✅ 可能用 L2 Norm | 确保特征空间可比性 |
六、常见归一化类型
| 类型 | 数学定义 | 应用场景 |
|---|---|---|
| L2 归一化 | 向量检索、Embedding | |
| Batch Normalization(BN) | 按 mini-batch 计算均值和方差,标准化后再缩放偏移 | CNN、图像分类 |
| Layer Normalization(LN) | 对每个样本的所有特征归一化 | Transformer、NLP |
| Instance Normalization(IN) | 对单个样本的每个通道独立归一化 | 图像风格迁移 |
| Group Normalization(GN) | 按组归一化 | 小 batch 训练的 CNN |
七、归一化的实际好处
-
训练稳定:防止梯度爆炸或消失(尤其在深层网络)
-
收敛更快:减少输入分布变化(内部协变量偏移)
-
结果可比性强:向量检索中比较公平
-
泛化能力更好:减少因尺度差异导致的过拟合
八、可视化理解
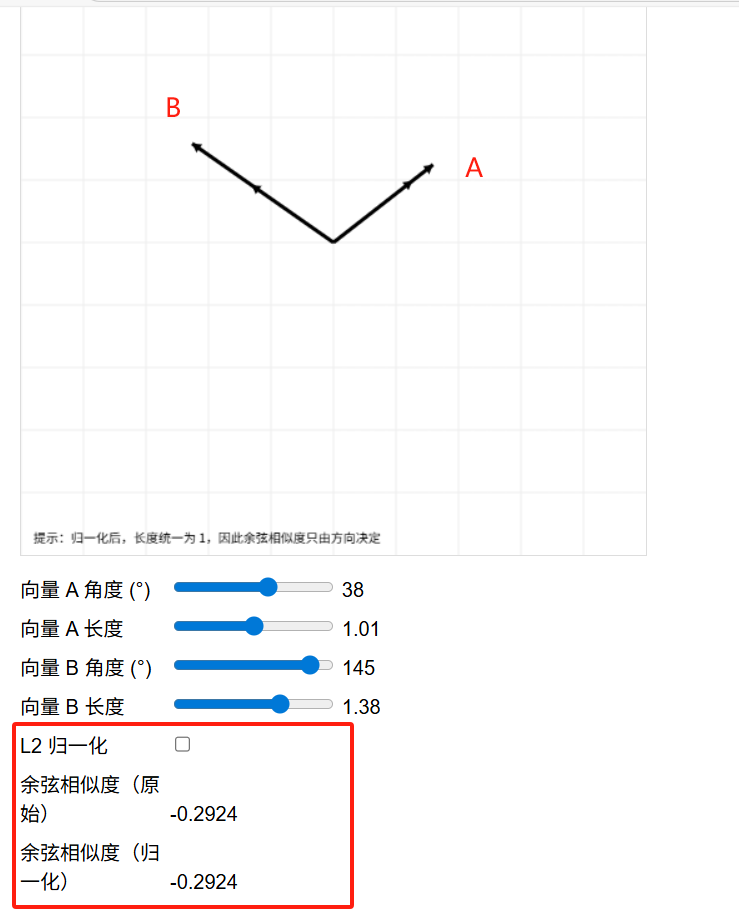
A和B夹角越小,说明方向越接近,余弦相似度越接近1;
A和B夹角越大,说明方向偏差越大,余弦相似度越接近于偏离于1;
方向接近时
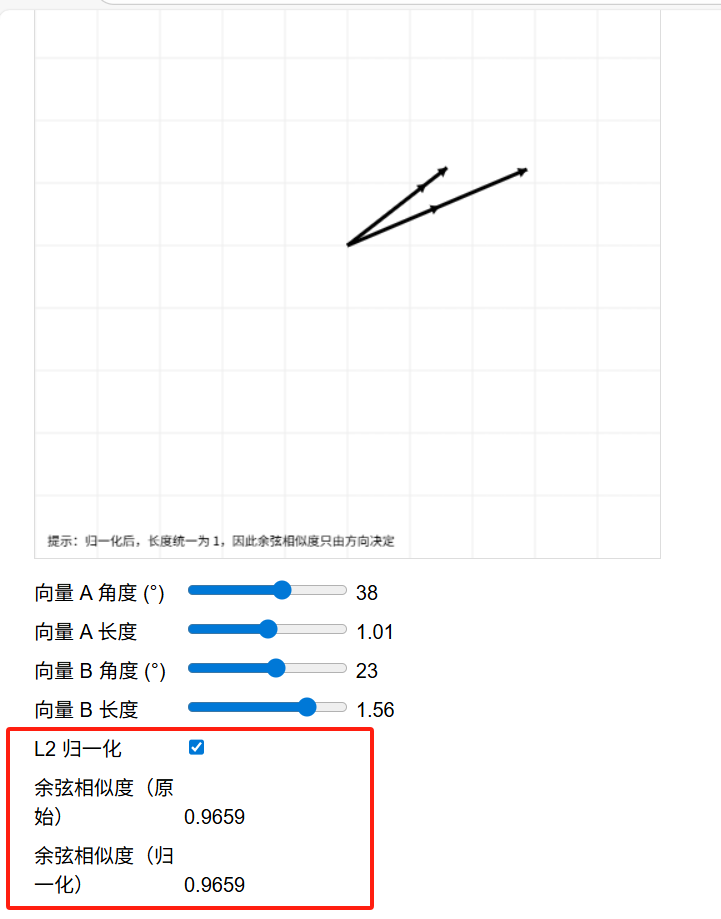
方向偏离较大时
可视化代码(html)
以下代码是上方图片中的动态演示示例,可以自行运行调整理解。
<!doctype html>
<html lang="zh-CN">
<head><meta charset="utf-8" /><title>归一化交互示例</title><style>body { font-family: Arial, sans-serif; display:flex; gap:20px; padding:20px; }#left { width:520px; }canvas { background:#fff; border:1px solid #ddd; }.controls { margin-top:10px; }.row { margin-bottom:8px; }label { display:inline-block; width:120px; }</style>
</head>
<body><div id="left"><canvas id="c" width="500" height="500"></canvas><div class="controls"><div class="row"><label>向量 A 角度 (°)</label><input id="aAngle" type="range" min="-180" max="180" value="30"><span id="aAngleV">30</span></div><div class="row"><label>向量 A 长度</label><input id="aLen" type="range" min="0" max="2" step="0.01" value="1.2"><span id="aLenV">1.20</span></div><div class="row"><label>向量 B 角度 (°)</label><input id="bAngle" type="range" min="-180" max="180" value="70"><span id="bAngleV">70</span></div><div class="row"><label>向量 B 长度</label><input id="bLen" type="range" min="0" max="2" step="0.01" value="0.7"><span id="bLenV">0.70</span></div><div class="row"><label>L2 归一化</label><input id="norm" type="checkbox" checked></div><div class="row"><label>余弦相似度(原始)</label><span id="cosOrig">—</span></div><div class="row"><label>余弦相似度(归一化)</label><span id="cosNorm">—</span></div></div></div><script>const canvas = document.getElementById('c');const ctx = canvas.getContext('2d');const w = canvas.width, h = canvas.height;const cx = w/2, cy = h/2;const aAngle = document.getElementById('aAngle');const aLen = document.getElementById('aLen');const bAngle = document.getElementById('bAngle');const bLen = document.getElementById('bLen');const norm = document.getElementById('norm');const aAngleV = document.getElementById('aAngleV');const aLenV = document.getElementById('aLenV');const bAngleV = document.getElementById('bAngleV');const bLenV = document.getElementById('bLenV');const cosOrig = document.getElementById('cosOrig');const cosNorm = document.getElementById('cosNorm');function deg2rad(d){ return d * Math.PI / 180; }function l2(v){ return Math.hypot(v[0], v[1]); }function normalize(v){const n = l2(v);if(n===0) return [0,0];return [v[0]/n, v[1]/n];}function drawArrow(x, y, vx, vy, width) {ctx.beginPath();ctx.moveTo(x, y);ctx.lineTo(x + vx, y + vy);ctx.lineWidth = width;ctx.stroke();// simple arrowheadconst angle = Math.atan2(vy, vx);const headLen = 8;ctx.beginPath();ctx.moveTo(x + vx, y + vy);ctx.lineTo(x + vx - headLen*Math.cos(angle - Math.PI/6), y + vy - headLen*Math.sin(angle - Math.PI/6));ctx.lineTo(x + vx - headLen*Math.cos(angle + Math.PI/6), y + vy - headLen*Math.sin(angle + Math.PI/6));ctx.closePath();ctx.fill();}function render(){ctx.clearRect(0,0,w,h);// draw axes gridctx.strokeStyle = '#eee';for(let i=0;i<w;i+=50){ctx.beginPath(); ctx.moveTo(i,0); ctx.lineTo(i,h); ctx.stroke();}for(let j=0;j<h;j+=50){ctx.beginPath(); ctx.moveTo(0,j); ctx.lineTo(w,j); ctx.stroke();}ctx.strokeStyle = '#000';ctx.fillStyle = '#000';// read valuesconst Aang = deg2rad(+aAngle.value);const Alen = +aLen.value;const Bang = deg2rad(+bAngle.value);const Blen = +bLen.value;aAngleV.innerText = aAngle.value;aLenV.innerText = (+Alen).toFixed(2);bAngleV.innerText = bAngle.value;bLenV.innerText = (+Blen).toFixed(2);// vectors in canvas coords (scale factor for visibility)const scale = 100;const v1 = [Alen*Math.cos(Aang)*scale, -Alen*Math.sin(Aang)*scale];const v2 = [Blen*Math.cos(Bang)*scale, -Blen*Math.sin(Bang)*scale];// original cosconst dot = v1[0]*v2[0] + v1[1]*v2[1];const l1 = l2(v1), l2v = l2(v2);const cosOriginal = (l1===0 || l2v===0) ? NaN : dot/(l1*l2v);cosOrig.innerText = isNaN(cosOriginal) ? 'NaN' : cosOriginal.toFixed(4);// normalizedconst nv1 = normalize(v1);const nv2 = normalize(v2);const cosN = (l2(nv1)===0 || l2(nv2)===0) ? NaN : (nv1[0]*nv2[0] + nv1[1]*nv2[1]);cosNorm.innerText = isNaN(cosN) ? 'NaN' : cosN.toFixed(4);// draw original (thick)ctx.lineWidth = 3;drawArrow(cx, cy, v1[0], v1[1], 3);drawArrow(cx, cy, v2[0], v2[1], 3);// draw normalized (thin) — scaled to unit-length visible size (80 px)ctx.lineWidth = 1;const unitScale = 80;drawArrow(cx, cy, nv1[0]*unitScale, nv1[1]*unitScale, 1);drawArrow(cx, cy, nv2[0]*unitScale, nv2[1]*unitScale, 1);// legendsctx.fillText('原始向量 (粗)', 10, 20);ctx.fillText('归一化后 (细, 单位长度)', 10, 38);ctx.fillText('提示:归一化后,长度统一为 1,因此余弦相似度只由方向决定', 10, h-10);}// wireup[aAngle, aLen, bAngle, bLen, norm].forEach(el => {el.addEventListener('input', render);});// if user toggles normalization off, we still show both values —// the visualization keeps displaying both original and normalized for clarity.render();</script>
</body>
</html>
说明与提示:
-
HTML 示例同时显示原始向量与归一化后的单位向量,方便直观对比(这是教学上常用的演示方式)。
-
页面显示两类余弦相似度:
-
“原始”余弦:使用原始长度计算(会受长度影响)。
-
“归一化”余弦:单位向量直接点积(只反映方向)。
-
九、类比理解
在我们这个向量归一化和余弦相似度的例子里,向量的长短(模长)表示的是该向量的大小 / 强度 / 量级,而方向表示的是特征模式。
我用三个不同的类比给你解释一下:
1. 物理类比:速度
-
方向:车往东开还是往北开
-
长度(模长):速度大小,比如 60 km/h 和 120 km/h
-
两辆车同方向,但速度不同 → 余弦相似度 = 1(方向完全一致),但点积会随速度增加而变大。
-
如果我们先归一化,就相当于只关心方向,不管你开多快。
2. 文本向量类比(NLP 里)
-
每篇文章变成一个向量,方向代表“主题分布”,模长代表“词频总量”或“信号强度”
-
长度大 → 词出现得多、信号更强
-
归一化后 → 比较的是文章主题的相似度(方向),而不是谁字多字少。
-
不归一化 → 字多的文章可能点积大,即使主题差距很大。
3. 图像特征类比
-
每张图提取一个特征向量
-
方向:图像的特征模式(颜色分布、纹理等)
-
长度:整体亮度、对比度或特征能量的大小
-
归一化后 → 只比特征模式,不受亮度变化影响
-
不归一化 → 亮度高的图像可能数值更大,即使内容相似度一般
✅ 所以在视图理解示例里:
-
方向 就是箭头的指向
-
长度 就是箭头的大小(模长),表示“量级”
-
归一化就是把所有箭头的长度变成 1,只比较方向
-
余弦相似度天然是只看方向的指标,和长度没关系
-
如果想让长度影响结果,就得用点积(dot product)或欧式距离等,不要除以模长
十、总结
归一化不是向量模型专属,但在向量模型中尤为重要。它能消除模长差异带来的干扰,让相似度计算只看方向差异。
在其他任务(CNN、Transformer)中,归一化更多是为了稳定训练和加快收敛。
记住类比:
模长 = 箭的长度(力度)
方向 = 箭的指向(语义)
归一化 = 把箭修成一样长,只比角度(语义方向)
归一化,看似简单的一步,却是深度学习中最隐形也最关键的“公平裁判”。
【一句话理解归一化】
归一化就是先把所有向量拉成相同长度,只比方向不比大小。
归一化就是把每个向量除以它的模长(
),把所有向量都拉成单位长度,这样在比较时(比如用余弦相似度)只看向量的方向/夹角,不会被原始的大小(如词频、亮度、信号强度)影响——换句话说,归一化把“谁更大”这个因素去掉,只比较“谁更像”。