8 反向引用
第7章介绍了子表达式的基本用途之一:把一组字符编组为一个字符集合。这样的字符集合,主要用于需要精确设定,需要重复匹配的文本及其重复次数。
本章将学习子表达式的另一种重要用途——反向引用(back-reference)。
8.1 理解反向引用
要想理解为什么需要反向引用,最好的方法是看一个例子。
HTML程序员使用标题标签(<h1>到<h6>,以及配对的结束标签)来定义和排版Web页面里的标题文字。假设你现在需要把某个Web页面里的所有标题文字全都查找出来,不管是几级标题。下面就是这个例子:
文本
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
</body>
正则表达式
<[hH]1>.*<\/[hH]1>
结果
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
</body>
分析
模式<[hH]1>.*</[hH]1>匹配一级标题(从<h1>到</h1>),也可以匹配<H1>(HTML不区分字母大小写)。但我们刚才说的是匹配任意级别的标题(HTML文档里的标题总共有6个级别),这应该怎么办呢?一种做法是用一个简单的区间来代替1,如下所示:
文本
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
</body>
正则表达式
<[hH][1-6]>.*?<\/[hH][1-6]>
结果
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
</body>
分析
看起来管用。<[hH][1-6]>匹配任意级别标题的开始标签(在这个例子中是<h1>和<h2>),</[hH][1-6]>匹配任意级别标题的结束标签(在这个例子中是</h1>和</h2>)。
注意 这里使用的是.*?(懒惰型)而不是.*(贪婪型)。
我们在第5章里讲过,*和其他的几个元字符,都是贪婪型的,所以模式<[hH][1-6]>.* [hH][1-6]>可能会从第2行的起始<h1>标签开始,一直匹配到第6行的结束\标签。使用懒惰型量词.*?可以解决这个问题。
之所以说“可能”(could)而不是“就会”(would),是因为在这个特定的例子里,即便是使用了贪婪型量词也不一定会有问题。元字符.通常无法匹配换行符,而上例中的每个标题都各自占据一行。但在这里使用懒惰型元字符没有任何坏处,事前小心总比事后后悔好。
现在没问题了吗?未必。看看下面这个例子(使用的还是刚才那个模式):
文本
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
正则表达式
<[hH][1-6]>.*?<\/[hH][1-6]>
结果
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
分析
有一处标题的标签是以<h2>开头、以</h3>结束的,这显然是一个无效的标题,但也能和我们使用的模式匹配上。问题在于,用于匹配结束标签的第二部分,对用于匹配开始标签的第一部分,没有关联。这正是反向引用大显身手的地方了。
8.2 反向引用匹配
我们等会儿再去解决匹配HTML标题的问题。先来看一个比较简单的例子,这个问题如果不使用反向引用,根本无法解决。
假设你有一段文本,你想把这段文本里所有连续重复出现的单词(打字错误,同一个单词输了两遍)找出来。显然,在搜索某个单词的第二次出现时,这个单词必须是已知的。反向引用允许正则表达式模式引用之前匹配的结果(具体到这个例子,就是前面匹配到的单词)。
理解反向引用的最好方法,就是看看它的实际应用。下面这段文本中包含3组重复的单词,我们要将其全部找出来:
文本
This is a block of of text.
here are are several words,and and they should not be.
正则表达式
[ ]+(\w+)[ ]+\1
结果
This is a block of of text.
here are are several words,and and they should not be.
分析
该模式看起来奏效了,但它的工作原理是什么?[ ]+匹配一个或多个空格,\w+匹配一个或多个字母数字字符,[ ]+匹配结尾的空格。注意,\w+是出现在括号里的,所以它是一个子表达式。该子表达式并不是用来进行重复匹配的,这里也没什么要重复匹配的。它只是对模式分组,将其标识出来以备后用。
模式最后一部分是\1,这是对前面那个子表达式的反向引用。\1匹配的内容与第一个分组匹配的内容一样。因此,如果(\w+)匹配的是单词of,那么\1也匹配单词of;如果(\w+)匹配的是单词and,那么\1也匹配单词and。
注意 术语“反向引用”指的是,这些实体引用的是先前的子表达式。
\1到底是什么意思?它匹配模式中所使用的第一个子表达式,\2匹配第二个子表达式、\3匹配第三个,以此类推。所以,在上面那个例子中,[ ]+(\w+)[ ]+\1匹配连续两次重复出现的单词。
警告 遗憾的是,在不同的正则表达式实现中,反向引用的语法差异不小。
JavaScript使用\来标识反向引用(除了在替换操作中用的是$),vi也是如此。
Perl使用的是$(所以写作$1,而不是\1)。
.NET正则表达式将返回一个对象,该对象的Groups属性包含所有的匹配。
C#语言中,match.Groups[1]对应着第一个匹配;.
Visual Basic .NET中,match.Groups(1)对应着第一个匹配。
PHP在名为$matches的数组中返回这些信息,$matches[1]对应着第一个匹配(但这一行为会根据所使用的标志发生变化)。
Java和Python将返回一个匹配对象,其中包含名为group的数组。
相关的实现细节请参阅附录A。
提示 可以把反向引用想象成变量。
--PostgreSQL
with t1 as (
select
'This is a block of of text.
here are are several words,and and they should not be.' txt
)
select txt,regexp_replace(txt,'[ ]+(\w+)[ ]+\1', ' \1','g') rn1
from t1

看过反向引用的用法之后,再回到HTML标题的例子。利用反向引用,可以构造一个模式去匹配任何一级标题的开始标签以及相应的结束标签(忽略任何不配对的标签)。来看下面的例子:
文本
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
正则表达式
<[hH]([1-6])>.*?<\/[hH]\1>
结果
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
分析
又找到了3个匹配:1个一级标题(<h1>...</h1>)和2个二级标题(<h2>...</h2>)。和以前一样,<[hH]([1-6])>匹配任意级别标题的开始标签。但不同的是,我们这次把[1-6]放进了()里,使它成为了一个子表达式。
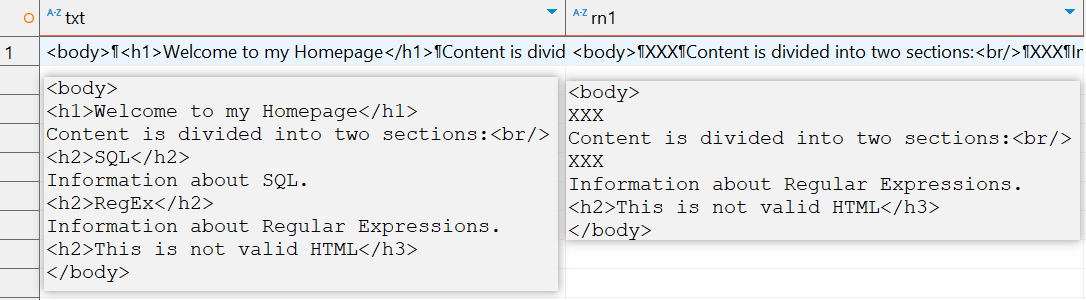
这样一来,我们就可以在用来匹配标题结束标签的</[hH]\1>里用\1来引用这个子表达式了。子表达式([1-6])匹配数字1~6,所以\1也只匹配与之相同的数字。<h2>This is not valid HTML</h3>因而就不会被匹配到了。
警告 反向引用只能用来引用括号里的子表达式。
提示 反向引用匹配通常从1开始计数(\1、\2等)。在许多实现里,第0个匹配(\0)可以用来代表整个正则表达式。
注意 正如看到的那样,子表达式是按照其相对位置来引用的:\1对应着第一个子表达式,以此类推,\5对应着第五个子表达式,等等。虽然受到普遍的支持,但这种语法存在着一个严重的不足:移动或编辑子表达式(子表达式的位置会因此改变)可能会使模式失效,删除或添加子表达式的后果甚至会更严重。
为了弥补这一不足,一些比较新的正则表达式实现还支持“命名捕获”(named capture):给某个子表达式起一个唯一的名称,随后用该名称(而不是相对位置)来引用这个子表达式。因为命名捕获还没有得到广泛支持,而且在已支持的实现中,语法差异也颇大,所以本书没有对此进行讨论。但如果你正在使用的正则表达式实现(例如.NET)支持命名捕获功能,那你一定要善加利用。
--PostgreSQL
with t1 as (
select
'<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>' txt
)
select txt,regexp_replace(txt,'<[Hh]([1-6]).*?</[Hh]\1>', 'XXX','g') rn1
from t1
8.3 替换操作
到目前为止,本书中所有的正则表达式都是用来搜索的,也就是在一段文本里查找特定的内容。的确,这可能是正则表达式最常干的事,但并不是它的全部功能。正则表达式还可以用来完成各种强大的替换操作。
简单的文本替换操作,用不着正则表达式。比如说,把所有的CA替换成California,或把所有的MI替换成Michigan,用正则表达式来完成就未免大材小用了。并不是不能用正则表达式来做这种事,只是这么做毫无价值可言。事实上,用普通的字符串处理功能反而会更容易(速度也更快)。
当用到反向引用时,正则表达式的替换操作才会变得让人印象深刻。下面是一个我们在第5章里见过的例子:
文本
Hello, ben@forta.com is my email address.
正则表达式
\w+[\w\.]*@[\w\.]+\.\w+
结果
Hello, ben@forta.com is my email address.
分析
该模式可以找出文本中的电子邮件地址(详细分析参见第5章)。
现在,假设你想把文本里的电子邮件地址全都转换为可点击的链接,该怎么办?在HTML文档里,你需要使用user@address.com这样的语法来创建一个可点击的电子邮件地址。能不能用正则表达式把一个电子邮件地址转换为这种可点击的地址格式呢?当然能,而且非常容易,但前提是,得使用反向引用,如下所示:
文本
Hello, ben@forta.com is my email address.
正则表达式
(\w+[\w\.]*@[\w\.]+\.\w+)
替换
<A HREF="mailto:$1">$1</A>
结果
Hello, <A HREF="mailto:ben@forta.com">ben@forta.com</A> is my email address.
分析
替换操作需要用到两个正则表达式:一个用来指定搜索模式,另一个用来指定替换模式。
反向引用可以跨模式使用,在第一个模式里匹配的子表达式,可以用在第二个模式里。这里使用的模式(\w+[\w\.]*@[\w\.]+\.\w+)与以前用到的完全一样(匹配电子邮件地址),但这次把它写成了一个子表达式。这样一来,被匹配到的文本就可以用于替换模式了。$1使用了两次已匹配的子表达式:一次是在href属性里(用于指定mailto:),另一次是作为可点击文本。所以,ben@forta.com变成了ben@forta.com ,而这正是我们想要的结果。
警告 如前所述,你需要根据所使用的正则表达式实现修改反向引用指示符。例如,JavaScript用户需要用$来代替\。
提示 正如你在上面这个例子里看到的那样,同一个子表达式可以被多次引用,只需在用到的地方写出其反向引用形式即可。
--PostgreSQL
with t1 as (
select
'Hello, ben@forta.com is my email address.' txt
)
select txt,regexp_replace(txt,'(\w+[\w\.]*@[\w\.]+\.\w+)', '<A HREF="mailto:$1">$1</A>','g') rn1
from t1

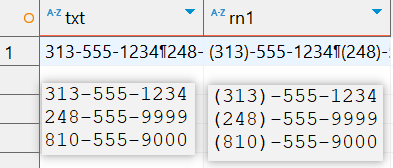
再来看一个例子。在一个保存用户信息的数据库里,电话号码的保存格式为313-555-1234。现在,你需要把电话号码的格式重新调整为(313) 555-1234。下面就是这个例子:
文本
313-555-1234
248-555-9999
810-555-9000
正则表达式
(\d{3})(-)(\d{3})(-)(\d{4})
替换
($1) $3-$5
结果
(313) 555-1234
(248) 555-9999
(810) 555-9000
分析
和刚才一样,这里也使用了两个正则表达式模式。第一个模式看起来很复杂,我们来分析一下。
(\d{3})(-)(\d{3})(-)(\d{4})用来匹配一个电话号码,它被划分为5个子表达式(彼此独立):第一个子表达式(\d{3})匹配前3位数字,第二个子表达式(-)匹配-字符,等等。最终的结果是一个电话号码被划分成了5个部分(每个部分对应着一个子表达式):区号、一个连字符、电话号码的前3位数字、又一个连字符、电话号码的后4位数字。这5个部分都可以单独拿出来使用,所以($1) $3-$5只用到了其中3个子表达式就完成了格式调整,剩下的2个没有用到,但这已足以把313-555-1234转换为(313) 555-1234。
提示 在调整文本格式的时候,把文本分解成多个子表达式的做法往往非常有用,这样可以更精细地控制文本。
--PostgreSQL
with t1 as (
select
'313-555-1234
248-555-9999
810-555-9000' txt
)
select txt,regexp_replace(txt,'(\d{3})(-\d{3}-\d{4})', '(\1)\2','g') rn1
from t1
大小写转换
有些正则表达式的实现中,允许我们使用表8-1列出的元字符,对字母进行大小写转换。

\l和\u可以放置在字符(或子表达式)之前,转换下一个字符的大小写。\L和\U可以转换其与\E之间所有字符的大小写。
来看一个简单的例子,即把一级标题<h1>转换为大写:
文本
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
正则表达式
(<[Hh]1>)(.*?)(<\/[Hh]1>)
替换
$1\U$2\E$3
结果
<body>
<h1>WELCOME TO MY HOMEPAGE</h1>
Content is divided into two sections:
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
分析
模式(<[Hh]1>)(.*?)(</[Hh]1>)把一级标题分成了3个子表达式:开始标签、标题文字、结束标签。
第二个模式再把文本重新组合起来:$1包含开始标签,\U$2\E把第二个子表达式(标题文字)转换为大写,$3包含结束标签。
PostgreSQL 17 文档: 9.7. 模式匹配 - Redrock Postgres
通过翻阅文档,PostgreSQL17中不支持,类似的实现大小写的转义字符
8.4 小结
子表达式,用来定义字符或表达式的集合。除了可以用于重复匹配(详见第7章),还可以在模式的内部被引用。这种引用被称为反向引用(遗憾的是,反向引用的语法在不同的正则表达式中存在差异)。在文本匹配和替换操作中,反向引用颇为有用。