2025年SEVC SCI2区,基于深度强化学习与模拟退火的多无人机侦察任务规划,深度解析+性能实测
目录
- 1.摘要
- 2.问题定义
- 3.SA-NNO-DRL方法
- 4.结果展示
- 5.参考文献
- 6.算法辅导·应用定制·读者交流

1.摘要
无人机(UAV)因其高自主性和灵活性,广泛应用于侦察任务,多无人机任务规划在交通监控和数据采集等任务中至关重要,但现有方法在计算需求上较高,导致常常无法得到最优解。为解决这一问题,本文提出了一种分治框架将任务分为两个阶段:目标分配和无人机路径规划,从而有效降低了计算复杂度。本文提出混合方法SA-NNO-DRL结合了基于最近邻最优的深度强化学习(NNO-DRL)和模拟退火(SA)算法。在路径规划阶段,NNO-DRL为每个无人机构建路径;在目标分配阶段,SA重新分配未覆盖的目标。两个阶段交替进行,直到满足终止条件。
2.问题定义
MURMPP的目标是为无人机群体规划路径,最大化其在监控目标时的总利润。每个无人机从同一中心出发并返回,成功监控指的是访问或经过目标。目标的利润预先定义,且仅在成功监控后收取。由于电池限制,部分目标可能无法覆盖。MURMPP是一个复杂的组合优化问题,随着目标数量增加,其难度呈指数级增长,该问题可通过混合整数线性规划(MILP)形式化,其中涉及多个无人机、目标、利润、路径分配和飞行范围的约束。
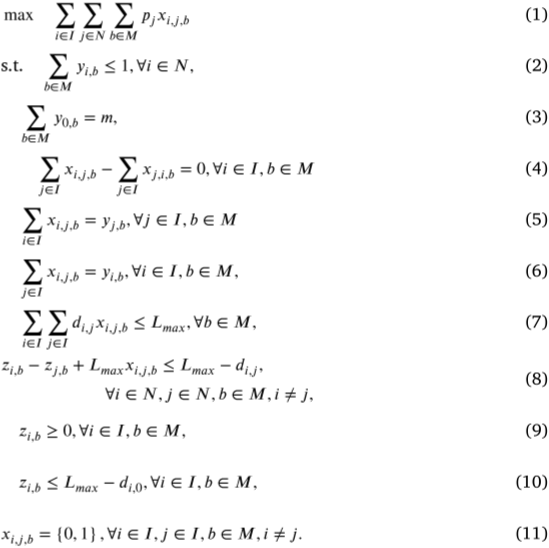
3.SA-NNO-DRL方法
为解决MURMPP,论文提出了一种迭代的两阶段框架——SA-NNO-DRL,在该框架中目标分配和无人机路径规划交替进行并相互作用。
单无人机NNO-DRL路径规划方法
路径规划可视为一个顺序决策问题,通过马尔可夫决策过程来实现。无人机智能体根据环境状态(如目标信息和剩余飞行范围)决定下一步行动 (即选择访问的目标节点),并获得相应的奖励。NNO-DRL的目标是学习一个策略pθp_\thetapθ,构建路径τ\tauτ,最大化总利润,同时遵循约束条件。生成路径的概率通过链式法则表示:
pθ(τ∣s)=∏t=1Tpθ(τt∣s,τ1:t−1)p_\theta\left(\tau|s\right)=\prod_{t=1}^Tp_\theta\left(\tau_t|s,\tau_{1:t-1}\right) pθ(τ∣s)=t=1∏Tpθ(τt∣s,τ1:t−1)
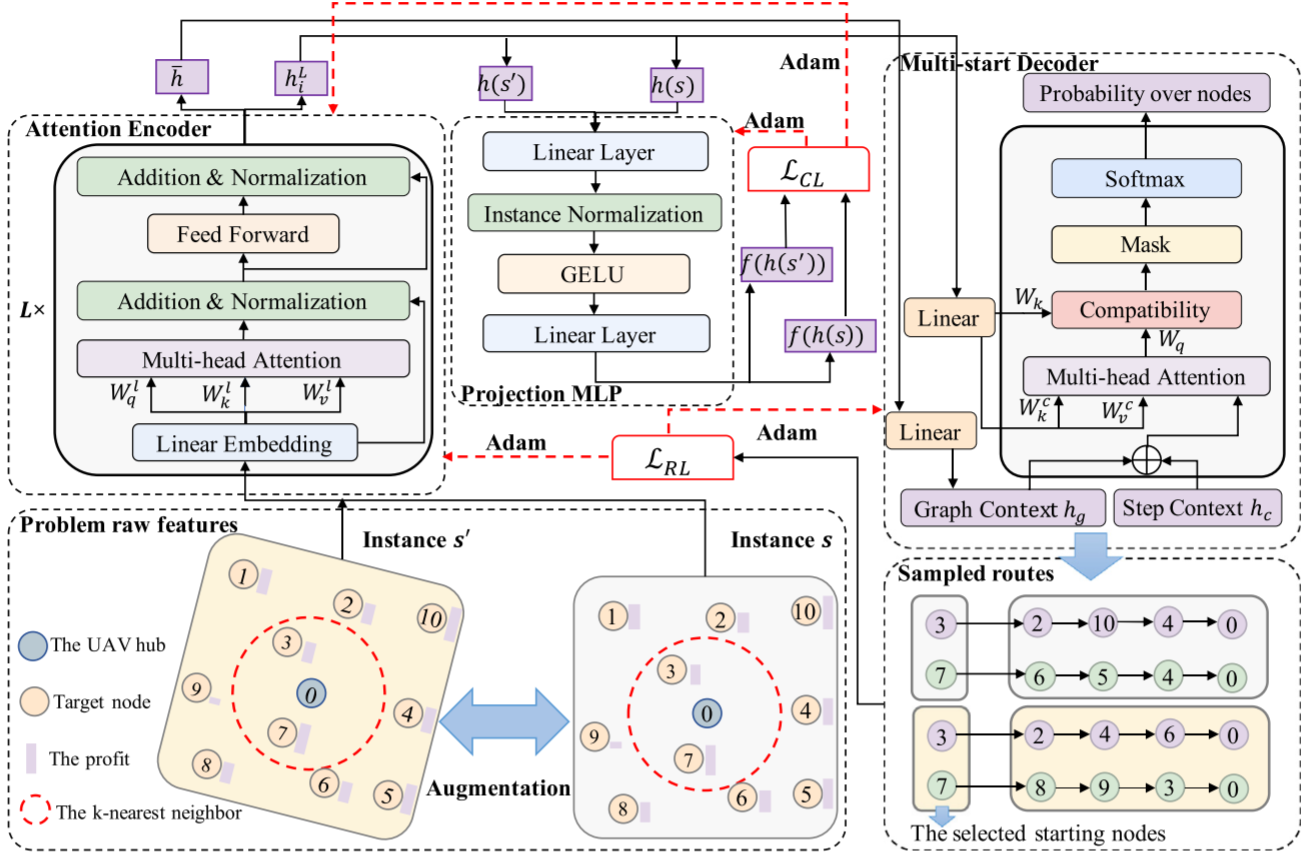
NNO-DRL由改进注意力模型和投影MLP组成,用于解决路径规划问题。其创新之处在于结合投影MLP和对比学习(CL)进行复杂问题表示,并通过kkk最近邻策略的多启动解码器提高解空间探索效率。通过最大化原始实例和增强版本节点嵌入的余弦相似度,增强了表示的鲁棒性。多启动解码器采用kkk最近邻策略,生成多个轨迹,以避免因电池限制产生次优解。

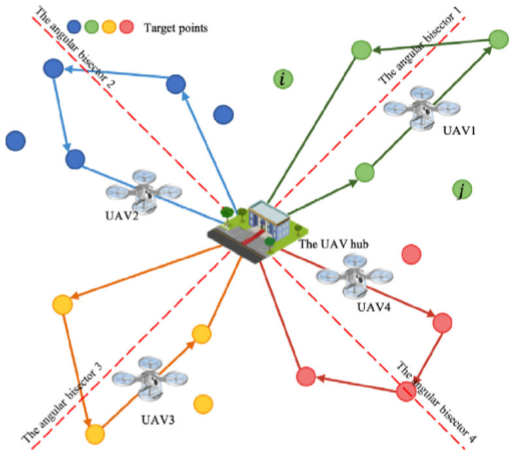
目标分配SA方法
给定位于区域中心的无人机中心,论文根据目标节点与水平轴之间的角度,将区域内的所有目标均匀地分成mmm组,角度定义为:
anglei=arctanlocyi−locy0locxi−locy0angle_i=arctan\frac{loc_y^i-loc_y^0}{loc_x^i-loc_y^0} anglei=arctanlocxi−locy0locyi−locy0

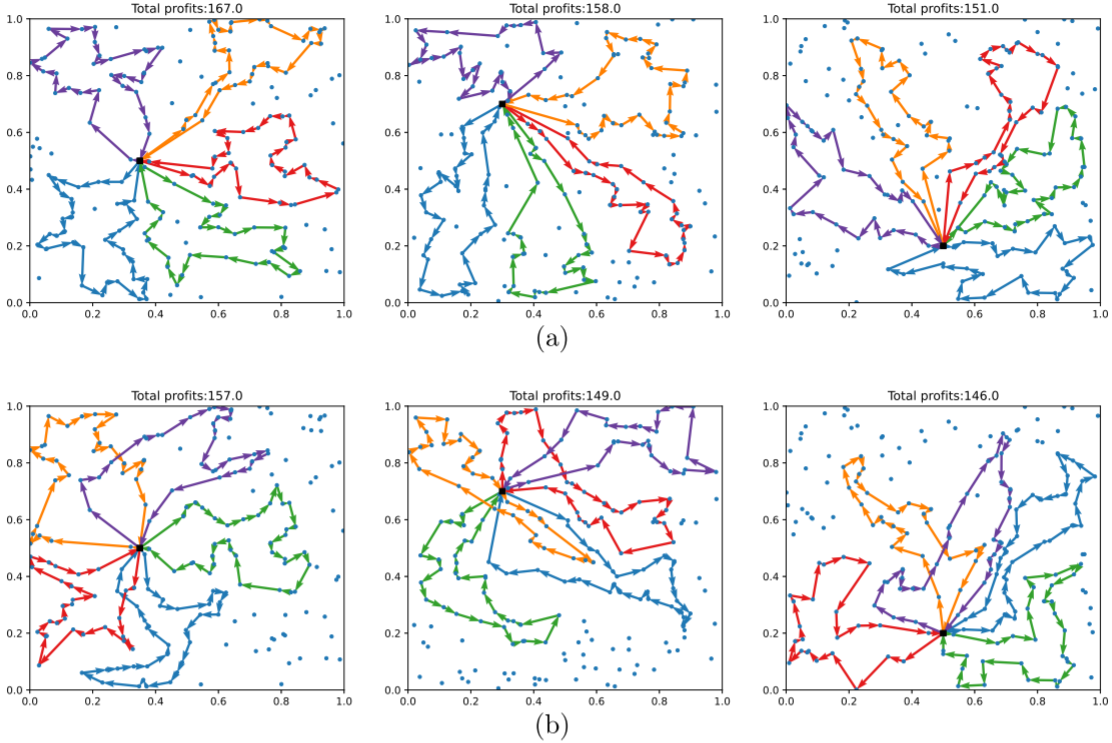
4.结果展示
5.参考文献
[1] Fan M, Liu H, Wu G, et al. Multi-UAV reconnaissance mission planning via deep reinforcement learning with simulated annealing[J]. Swarm and Evolutionary Computation, 2025, 93: 101858.
6.算法辅导·应用定制·读者交流
xx