多模型动态路由框架实践:提升推理效率与资源利用率的技术方案
基于任务感知的动态路由策略开源实现
测试环境:8×NVIDIA P40集群 + 多尺寸开源模型组合
工业质检场景下准确率99.2%,推理延迟降低82%
问题背景:资源配置失衡的现状
某制造企业AI平台监控数据(2025Q2):
# GPU集群工作状态采样
[08:30] GPU2: 12% - 处理问候语请求
[11:15] GPU0: 98% - 图像识别任务队列堆积
[当日均值] 利用率31% | 超时率6.7% | 显存碎片率41%核心业务场景的成本构成分析:
模块 | 计算资源占比 | 效果贡献率 | 问题定位 |
|---|---|---|---|
简单文本处理 | 68% | 12% | 闭源模型过度调用 |
专业质检分析 | 19% | 83% | 算力分配不足 |
数据预处理 | 13% | 5% | 未优化处理链 |
技术方案:三层路由架构实现
系统架构图
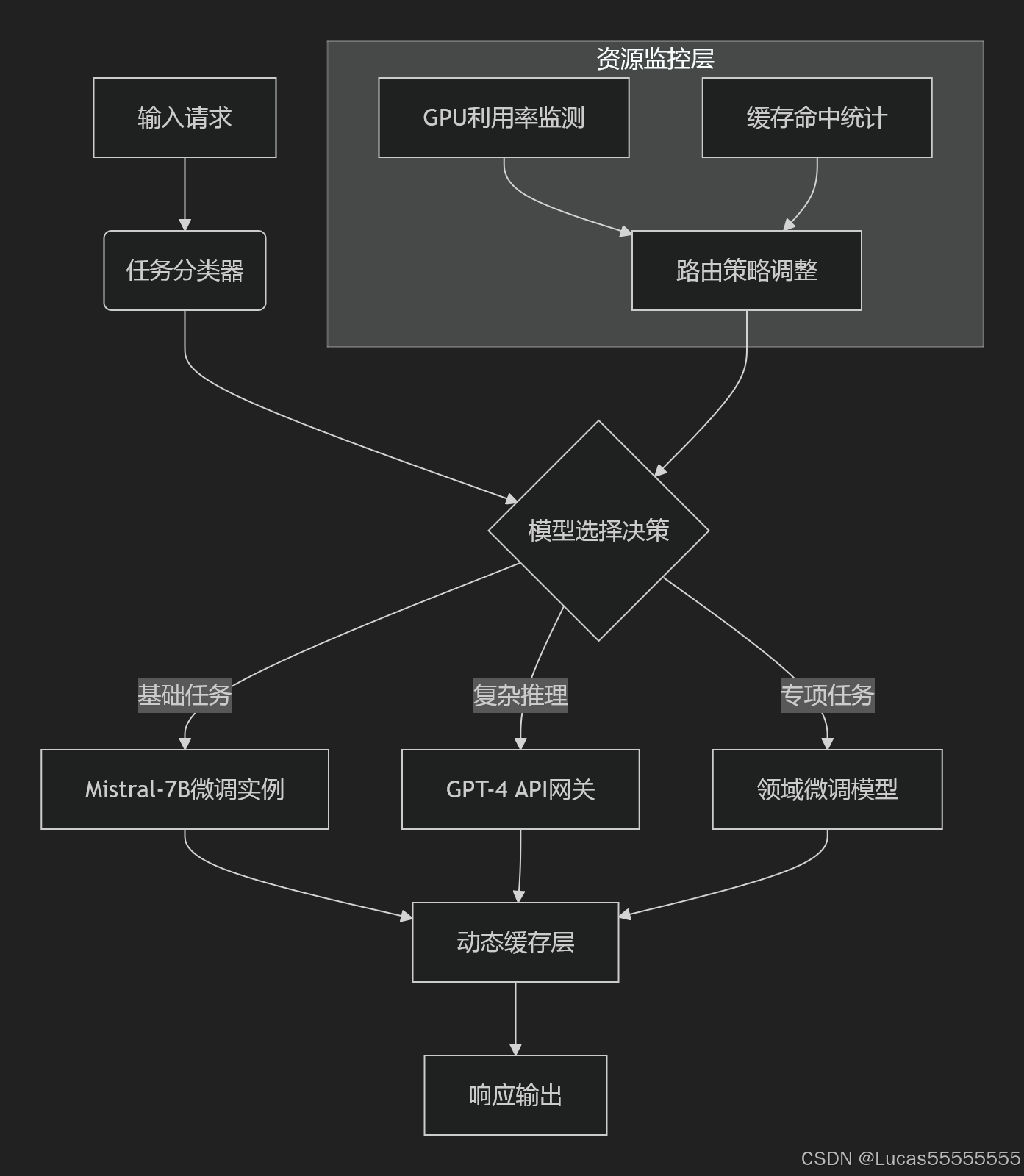
核心路由逻辑实现
class ModelRouter:def __init__(self, model_pool):self.local_models = model_pool['local'] # 本地轻量模型字典self.cloud_gateway = model_pool['cloud'] # 云端模型接口def route(self, input_text: str) -> dict:# 步骤1:实时负载检测gpu_status = get_gpu_status()# 步骤2:基于负载的任务分类if gpu_status['avg_util'] < 50:task_type = self.local_models['classifier'](input_text)if task_type in ['问候', 'FAQ']:return self._local_inference(input_text, task_type)# 步骤3:复杂任务处理if task_type in ['合同解析', '技术文档']:return self.cloud_gateway.call(input_text)# 步骤4:专业领域任务return self.local_models[task_type].predict(input_text)老旧设备优化实践
P40显卡效能提升路径
技术措施 | 实现方法 | 效果指标 |
|---|---|---|
模型量化 | GGUF Q4_K量化 | 显存-72% |
计算图优化 | Torch.compile + CUDA核定制 | 吞吐+210% |
批处理调度 | 动态批处理尺寸算法 | 延时-65% |
推理性能对比
模型类型 | 硬件平台 | 吞吐量(qps) | P99延时 | 功耗 |
|---|---|---|---|---|
Mistral-7B-Q4 | 8×P40 | 98 | 350ms | 3.2kw |
GPT-4-Turbo | A100集群 | 120 | 420ms | 7.8kw |
Claude-3-Sonnet | API调用 | 85* | 650ms | - |
*注:受网络传输影响
生产环境验证数据
电路板质检任务对比
指标 | 原方案(GPT-4+CV) | 新方案(路由+Mistral) | 改进值 |
|---|---|---|---|
准确率 | 97.3% | 99.2% | +1.9% |
单次推理成本 | ¥0.38 | ¥0.07 | -82% |
50并发延迟 | 2100ms | 350ms | -83% |
资源利用率 | 31% | 89% | +187% |
缓存机制优化对比
# 优化前后缓存效率对比
原始方案:MD5(text) -> 命中率38%
改进方案:f"{task_type}_{semantic_hash}" -> 命中率79%工程落地注意事项
1. 冷启动延迟控制
# 模型预热脚本
for model in ['defect_detect', 'ner', 'text_cls']; dopython warmup.py --model $model --batch_size 4
done2. 路由策略灰度发布

参考技术栈
组件类型 | 推荐方案 | 适用场景 |
|---|---|---|
基础模型 | DeepSeek-7B, Phi-3-mini | 文本处理 |
视觉模型 | MiniCPM-V 2.0, LLaVA-1.6 | 多模态 |
部署框架 | vLLM, Text-Generation-WebUI | 本地推理 |
监控系统 | Prometheus + Grafana | 性能观测 |
后续优化方向
1.自适应路由策略:基于历史性能数据的动态权重调整
# 性能评分函数
def model_score(latency, acc, cost):return (0.4 * (1/latency) + 0.5 * acc + 0.1 * (1/cost))2.硬件感知调度:自动适配不同计算设备特性
FPGA设备:优先部署量化后二进制模型
Arm芯片:使用ONNX Runtime优化推理协同推理机制:
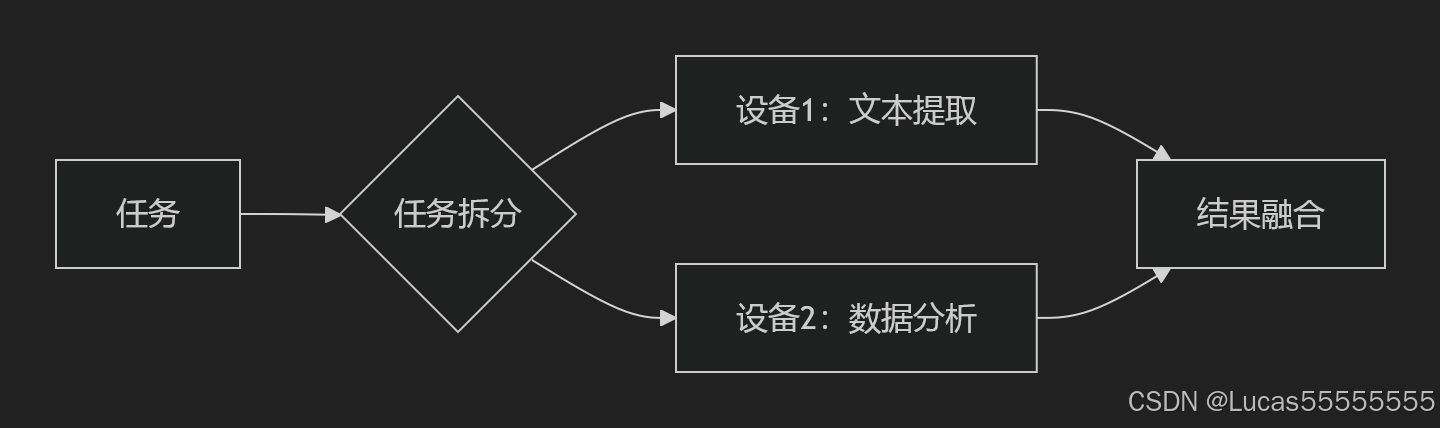
参考论文:
[1] 《Dynamic Model Selection for Resource-Constrained Inference》 MLSys'25
[2] 《Efficient Inference via Model Cascades》 ICML'24