大语言模型中的幻觉
目录
一、幻觉的定义与类型
1、定义
2、几个属性
3、类型
(1)内在幻觉:
(2)外在幻觉
(3)事实性幻觉
(4)忠实性幻觉
二、幻觉的成因
1、数据角度
(1)错误信息与偏见
(2)知识边界
2、训练角度
(1)预训练
(2)对齐
3、推理角度
三、幻觉的检测
1、针对事实性幻觉
2、检测忠实性幻觉
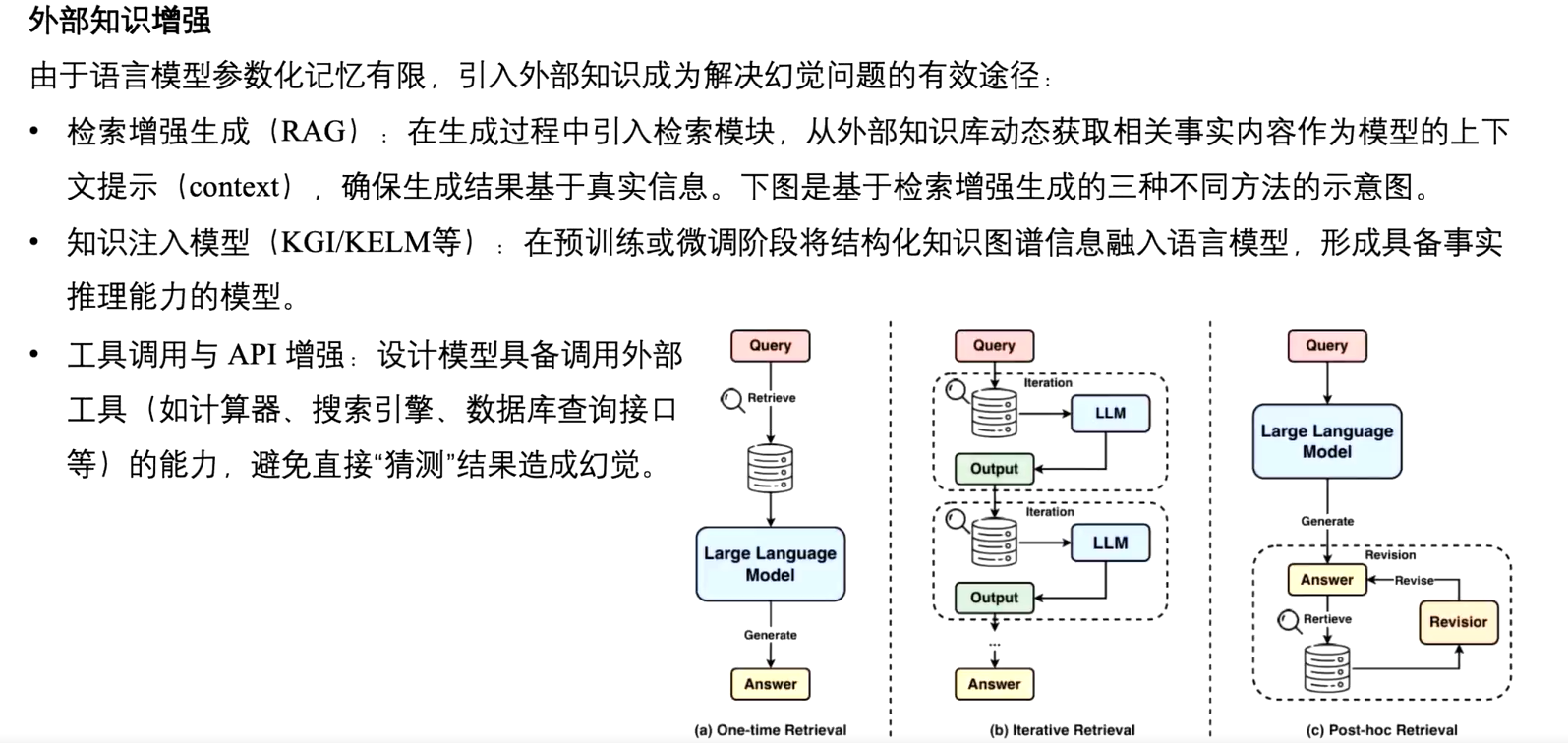
四、幻觉的缓解
五、挑战与未来
在AI领域,“幻觉”指的是大语言模型生成了不真实、不准确,甚至是完全错误的信息,但它们表现得很自信,好像是真的一样~~~【正儿八经说假话hhhh】
一、幻觉的定义与类型
1、定义
在自然语言生成(NLG)中,幻觉指模型生成了与现实世界事实、输入上下文或基础知识不一致的内容,尽管这些内容通常语言流畅、结构合理,甚至逻辑自治,但本质上却是虚假的错误的或无法证实的。简而言之,幻觉是指模型在缺乏支持证据的情况下所产生的虚构输出。
2、几个属性
(1)语言流畅性强,内容表面上合理易读,难以直接辨识
(2)真实性缺失,与事实或输入存在明显出入,或完全无中生有
(3)自信表达,模型倾向于以肯定句式输出幻觉内容,增强其迷惑性
(4)缺乏可验证性,幻觉内容往往无法从输入或外部知识源进行查证
(5)具有潜在危害性,在医疗、法律、金融等高风险场景中,幻觉可能误导用户判断,导致严重
3、类型
通常,自然语言生成任务中的幻觉可以分为两种主要类型:内在幻觉和外在幻觉
(1)内在幻觉:
指模型输出的内容与输入中提供的信息存在直接冲突或事实矛盾。例如,在文本摘要任务中,原文提到“该公司成立于2010年",而模型却生成了"该公司成立于2005年”。这类幻觉可通过对比输入输出内容进行显式识别。
(2)外在幻觉
指模型输出的内容在输入中找不到直接依据或支持,即生成了超出原始信息范围的内容。尽管这些内容可能不明显错误,但由于缺乏证据,其真实性无法确认。例如,模型在回答问
题时凭空补充用户未提及的细节或情节
然而,在大语言模型时代,模型的多功能能力促进了其在各个领域的广泛应用,突出了现有特定任务分类范例的局限性。考虑到大语言模型非常强调以用户为中心的交互,并优先考虑与用户指令的-致性,再加上幻觉主要在事实层面上浮现的事实,幻觉分为事实性幻觉和忠实性幻觉。
(3)事实性幻觉
事实性幻觉分为两种主要类型:事实矛盾和事实虚构。
事实矛盾(生成内容与客观事实直接冲突)
- 例子 :用户问 “爱因斯坦发明了什么?”,模型回答 “爱因斯坦发明了电灯”(实际电灯由爱迪生发明,与事实矛盾)
、 事实虚构(生成不存在的虚假信息)、
- 例子 :用户问 “《三体》的作者是谁?”,模型回答 “《三体》的作者是刘慈欣和王小明”(王小明为虚构人物,实际作者仅刘慈欣)。
(4)忠实性幻觉
忠实性幻觉分为三种类型:指令不一致,上下文不一致和逻辑不一致
-
指令不一致:生成内容违背用户明确的指令要求。
- 例:用户要求 “用中文总结这篇英文论文”,模型却用英文生成了完整翻译(未遵守 “中文总结” 的指令)。
-
上下文不一致:生成内容与对话历史或给定上下文信息冲突。
- 例:上文提到 “小明今年 10 岁”,模型后续回答 “小明上大学了”(与前文年龄信息矛盾)。
-
逻辑不一致:生成内容内部存在逻辑矛盾,无法自洽。
- 例:模型描述 “这个箱子是空的,但里面装着一本书”(“空的” 与 “装着书” 逻辑冲突)。
二、幻觉的成因
1、数据角度
(1)错误信息与偏见
- 数据中可能潜藏错误信息:比如输入数据本身包含事实错误、虚假信息。
-
语言模型容易模仿训练数据中的虚假信息(模仿性虚假信息)。
-
社会偏见:种族、性别、地域等偏见会被无意中放大,导致模型输出带有歧视或刻板印象。
-
重复偏见:训练数据中重复出现的偏见内容会强化模型的偏见倾向。
比如当有一个人审理法审核法律文本的时候,大模型会判谁有罪,你会发现大模型明显的倾向于判黑人有罪。。。
(2)知识边界
-
大模型知识来源有限,知识截止于训练数据的时间点。
-
对于长尾知识(少见或专业领域信息),模型可能缺乏足够学习。
-
最新知识(训练后出现的新信息)无法及时掌握。
-
版权保护的内容限制模型访问和生成相关信息
2、训练角度
(1)预训练

(2)对齐

3、推理角度

三、幻觉的检测
大模型有时会“胡说八道”,说出不真实或错误的信息,这会影响它的可信度。检测幻觉就是要发现这些错误,保证结果靠谱。
大模型「幻觉」,看这一篇就够了 | 哈工大华为出品 - 知乎 ---可以看这个中的幻觉检测,从检测忠实性幻觉和事实性幻觉;
1、针对事实性幻觉
已有检索外部事实和不确定性估计两种方法。
- 检索外部事实是将模型生成的内容与可靠的知识来源进行比较。
-
基于不确定性估计的幻觉检测方法,可以分为两类:基于内部状态的方法和基于行为的方法。 基于内部状态的方法主要依赖于访问大模型的内部状态。例如,通过考虑关键概念的最小标记概率来确定模型的不确定性。基于行为的方法则主要依赖于观察大模型的行为,不需要访问其内部状态。例如,通过采样多个响应并评估事实陈述的一致性来检测幻觉。
2、检测忠实性幻觉
- 基于事实的度量,测量生成内容和源内容之间事实的重叠程度来评估忠实性。
- 分类器度量:使用训练过的分类器来区分模型生成的忠实内容和幻觉内容。
- 问答度量:使用问答系统来验证源内容和生成内容之间的信息一致性。
- 不确定度估计:测量模型对其生成输出的置信度来评估忠实性。
- 提示度量:让大模型作为评估者,通过特定的提示策略来评估生成内容的忠实性。
四、幻觉的缓解


五、挑战与未来

