Mysql深入学习:InnoDB执行引擎篇
InnboDB存储引擎
mysql大概的架构如下
第1层:连接层
主要负责对客户端发起的连接请求进行权限验证,并将连接的相关信息保存到连接池中,方便下次复用连接资源。
第2层:Server服务层:
提供包括NoSQL和SQL接口的支持,负责SQL语句的解析、优化以及缓存等核心组件的处理。
第3层:存储引擎层:
该层支持多种可插拔式存储引擎,负责完成数据的读写操作,并与磁盘中的数据文件和日志文件进行交互。用户可以根据实际需求选择不同的存储引擎。
第4层:文件系统层:
此层涵盖了具体的数据文件、日志文件以及MySQL运行所需的程序文件。
在上述四层结构中,MySQL的核心架构由两大关键部分组成:服务层(Server Layer)与存储引擎层(Storage Engine Layer)。其中,服务层承担主要的逻辑处理任务,而存储引擎层则专注于底层的数据存储与访问操作。
一条sql执行的总体流程
一条sql语句的执行流程大概可以分为下面几个步骤
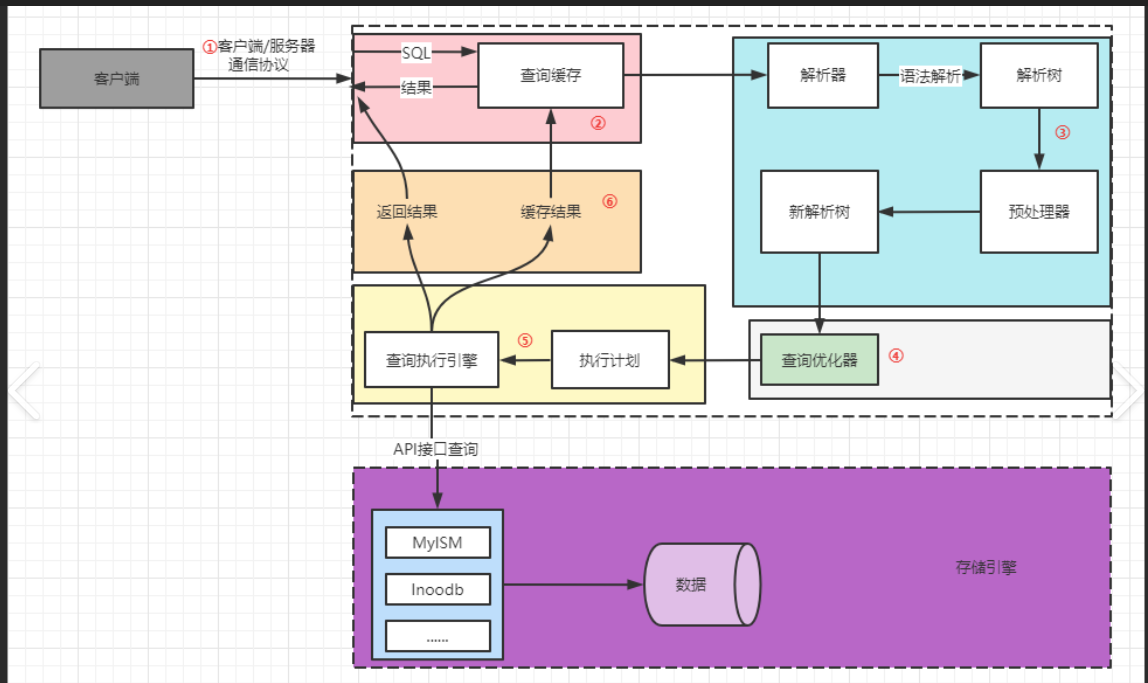
Client层:接收用户提交的SQL语句,并将查询结果返回给用户进行展示。
Server层:负责对SQL语句进行语法检查、语言解析、优化处理与执行操作,最终将执行结果反馈给客户端。
连接器:主要完成用户身份验证与权限控制,同时建立并管理与客户端的连接。
缓存模块:用于保存查询结果,当相同请求再次出现时,优先返回命中的缓存结果以提升查询效率。
分析器:负责对SQL语句进行词法和语法上的解析,形成抽象语法树。
优化器:制定执行策略,生成高效的执行计划,并确定是否使用索引进行数据检索。
执行器:调用底层存储引擎(如 InnoDB)进行实际数据操作,并通过文件系统返回结果集。
文件系统层:对数据进行持久化
MySql中SQL语句核心执行流程如下:
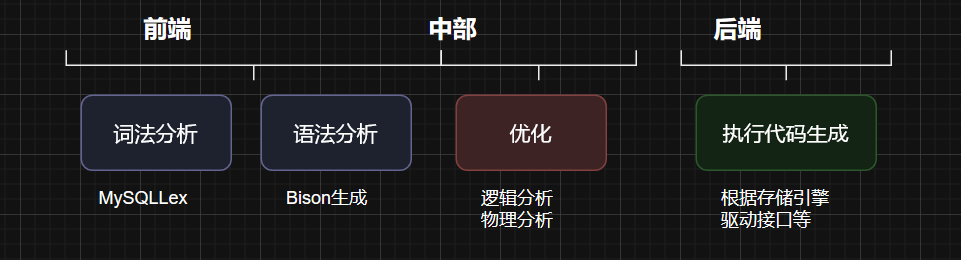
SQL语句输入 → 解析阶段(包括词法分析 → 语法分析 → 语义分析)→ 构建抽象语法树(AST) → 预处理阶段(进一步语义检查)→ 优化器阶段(逻辑优化 → 物理优化) → 生成物理查询计划 → 执行引擎执行 → 将结果返回客户端。
具体关键步骤如下:
- 词法分析:将完整的SQL语句拆解为一个个最小的语义单元(如字段名、操作符、关键字等),形成Token列表;
- 语法分析:检查Token序列是否满足SQL语法规则,并基于此构造抽象语法树(AST),用于表达SQL的结构;
- 预处理阶段:按照MySQL内部规则进一步分析语法树的合法性,例如检查字段是否存在、别名是否重复等;
- 逻辑优化:在语义层面上对SQL进行优化,例如重写嵌套查询、合并表达式、移除无效字段等,输出逻辑执行计划;
- 物理优化:基于逻辑计划选择具体的物理执行方式,如索引选择、连接策略、数据访问路径等,生成最终物理执行计划;
- 执行阶段:执行器将物理计划转译为可运行指令(可能是字节码或底层操作),驱动数据库系统完成数据处理,并将结果传回客户端。
InnoDB存储引擎
在 MySQL 中,数据最终是保存在磁盘上的,具体存储到哪些文件中,则取决于所使用的存储引擎。
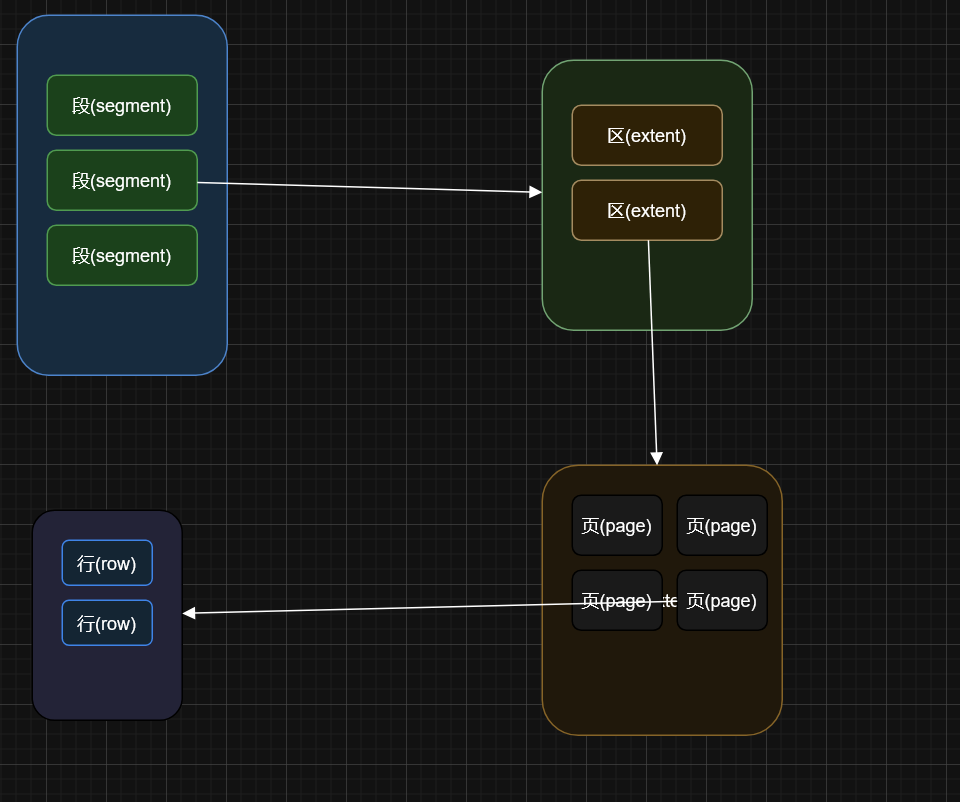
MySQL 支持多种存储引擎,不同引擎在数据组织方式上各有差异。其中 InnoDB 是最常见且默认启用的存储引擎,下面重点介绍其存储结构。InnoDB 的整体结构分为以下四个层级:
- 表空间(Tablespace):这是管理表数据的最顶层逻辑单位,由多个段构成,通常对应一个或多个磁盘上的物理数据文件。
- 段(Segment):表空间中的组成部分,逻辑上表示一类数据集合,如数据段、索引段等。每个段由若干个“区”构成。
- 区(Extent):这是 InnoDB 分配空间的基本单位,默认大小为 1MB,由连续的 64 个页面组成,目的是提升分配效率,避免频繁的单页申请。
- 页(Page):最小的磁盘读写单元,默认大小为 16KB,用于存放具体的表数据或索引信息。InnoDB 在内存与磁盘之间的读写操作就是以页为单位进行的。
在以上四级结构中,最核心的是“页”的设计。虽然数据保存在磁盘上,但 InnoDB 的实际处理过程发生在内存中。为了提升性能,InnoDB 并不是对单条记录进行操作,而是以整个“页”为单位进行读取和写入。页的大小由参数 innodb_page_size 决定,常见设置包括 64KB、32KB、16KB(默认值)、8KB 和 4KB。也就是说,每次读写操作的最小粒度就是一页的大小。
总结一句话:InnoDB 的存储层级结构就像一本书:书本(表空间)→ 章节(段)→ 小节(区)→ 页面(页),而实际的数据就像书页上的文字,真正的内容就记录在这些页中。
InnoDB行格式
在 InnoDB 中,行数据在磁盘上的存储结构被称为行格式。目前,InnoDB 支持以下 四种行格式:
- Compact
- Redundant
- Dynamic
- Compressed
你可以通过以下 SQL 语句来设置或查看表的行格式:
-- 创建表时指定行格式
CREATE TABLE 表名 (列定义) ROW_FORMAT=行格式名称;-- 修改表的行格式
ALTER TABLE 表名 ROW_FORMAT=行格式名称;-- 查看表当前使用的行格式
SHOW TABLE STATUS LIKE '表名';不同 MySQL 版本下的默认行格式:
- MySQL 5.0 以前:默认采用
Redundant - MySQL 5.0 到 5.7:默认为
Compact - MySQL 5.7 以后:默认为
Dynamic
Compact 行格式(使用最广泛)
Compact 行格式主要包含三部分额外信息:
- 变长字段长度列表:
记录每个变长字段(如 VARCHAR、TEXT 等)的实际长度,逆序排列,只记录非NULL字段的长度。 - NULL 值列表:
管理所有允许为NULL的列,每位用 1 表示为NULL,0 表示非NULL。
若表中没有NULL字段,该部分会被省略。
作用: 将 NULL 值集中存储,避免在数据区中浪费存储空间。
举例说明:
若有三列 col1, col2, col3 均允许为 NULL,插入 (NULL, 'abc', NULL),
NULL 值位图约为 101(二进制)。
- 记录头信息(Record Header):
用于描述记录的状态及结构,常见字段如下:
字段名 | 位数 | 描述 |
预留位1 | 1 | 未使用 |
预留位2 | 1 | 未使用 |
delete_mask | 1 | 标识记录是否被删除 |
min_rec_mask | 1 | 标记是否为非叶子节点中的最小记录(用于 B+ 树) |
n_owned | 4 | 当前记录拥有的记录数(页目录使用) |
heap_no | 13 | 在当前页中的记录位置 |
record_type | 3 | 记录类型(0 普通记录,1 B+树节点,2 最小,3 最大) |
next_record | 16 | 下一条记录的偏移量 |
Compressed 行格式
在 Dynamic 行格式的基础上,增加了zlib 压缩机制,用于压缩大字段(如 BLOB、TEXT 等),可节省磁盘空间。
但由于压缩与解压操作较重,会影响读写性能,因此一般不推荐用于对性能要求高的业务场景。
Redundant 行格式(旧格式)
Redundant 是 MySQL 5.0 之前的默认行格式,目前已较少使用。
与 Compact 的主要区别在于:
- 使用 偏移地址表 来代替变长字段长度表和 NULL 列位图;
- 记录头信息中新增
n_field和1byte_offs_flag字段; - 缺失
record_type字段。
Dynamic 行格式
这是 MySQL 5.7 以后的默认行格式,与 Compact 相似,最大区别在于:
- Compact:会存储字段前 768 字节 + 20 字节指向溢出页的地址;
- Dynamic:只保存 20 字节的溢出页地址,不保留字段前缀数据。
行溢出机制详解
当某列(如 TEXT 或 BLOB)超过一定大小限制时,InnoDB 不会将所有数据直接存入当前页,而是将其拆分:
- 当前页中保存前 768 字节内容(Compact 行格式)或仅保存地址(Dynamic 行格式);
- 超出部分存储在其他页中,这些被称为 溢出页(Uncompressed BLOB Page)。
行溢出的临界点计算:
InnoDB 规定每个页至少容纳两条记录,并预留约 132 字节的系统信息,加上每条记录额外的 27 字节开销。
单列数据小于约 8099 字节时通常不会发生溢出。
若包含多列,该阈值会相应减少。

InnoDB数据页格式
在 InnoDB 中,一个 数据页大小为 16KB,被划分为多个功能区域,各部分结构如下:
区域名称 | 描述 | 大小 |
File Header | 页的通用信息 | 38 字节 |
Page Header | 页的专有信息 | 56 字节 |
Infimum + Supremum | 最小/最大伪记录 | 26 字节 |
User Records | 实际存储的数据记录 | 可变 |
Free Space | 尚未使用的空闲空间 | 可变 |
Page Directory | 页内记录的索引结构 | 可变 |
File Trailer | 用于校验页完整性 | 8 字节 |
每当插入新记录时,会从 Free Space 区 中分配空间,将数据写入 User Records 区域。
当 Free Space 被填满时,意味着当前页已写满,后续写入操作将触发分配新数据页。
📄 示例:插入记录
CREATE TABLE test(a1 INT,a2 INT,a3 VARCHAR(100),PRIMARY KEY (a1)
) CHARSET=ascii ROW_FORMAT=Compact;INSERT INTO test VALUES (1, 10, 'aaa');
INSERT INTO test VALUES (2, 20, 'bbb');
INSERT INTO test VALUES (3, 30, 'ccc');
INSERT INTO test VALUES (4, 40, 'ddd');这些记录将按主键顺序被写入 User Records 部分。
InnoDB 记录头字段说明
InnoDB 中每条记录前都有一段记录头信息(Record Header),描述该条记录的状态,主要字段如下:
- delete_mask:记录删除状态,1 表示被删除(尚未物理清除),0 表示有效记录。已删除记录会进入垃圾链表,空间可复用。
- min_rec_mask:仅在 非叶子节点的最小记录中设置为 1,用于 B+ 树快速定位最小值。
- n_owned:一个页被划分成多个分组,每组的最后一条记录会记录该组中总记录数。
- heap_no:记录在页中的物理位置编号,从 2 开始计数(0 为 Infimum,1 为 Supremum)。
- record_type:记录的类型,含义如下:
- 0:普通记录
- 1:B+树的非叶子记录
- 2:Infimum(最小伪记录)
- 3:Supremum(最大伪记录)
- next_record:指向下一条记录的偏移量,形成按主键排序的链表结构。
例如,next_record = 32表示下条记录在当前记录偏移 32 字节的位置。
因此,记录结构是一个有序的链表:
Infimum → 最小主键 → ... → 最大主键 → Supremum
Page Directory(页目录结构)
虽然记录形成了有序单链表,方便插入与删除,但查找效率不高。为此,InnoDB 引入了 页目录(Page Directory),提高查找效率。
工作机制如下:
- 分组逻辑:
所有有效记录(不含已删除)被划为多个组,每组最后一条记录的n_owned表示本组记录数。每个组的最后一条记录地址作为一个“槽(slot)”,方便查找。 - 分组规则:
- 第一组(最小记录组)只能包含一条记录
- 最后一组可容纳 1~8 条
- 中间组保持 4~8 条记录
- 动态调整:
初始状态仅有 Infimum 和 Supremum 两个伪记录;
插入新记录后,根据插入位置动态更新分组与 slot;
若某组记录数超过 8 条,会被拆分成两个新组(例如 4 条 + 5 条)。 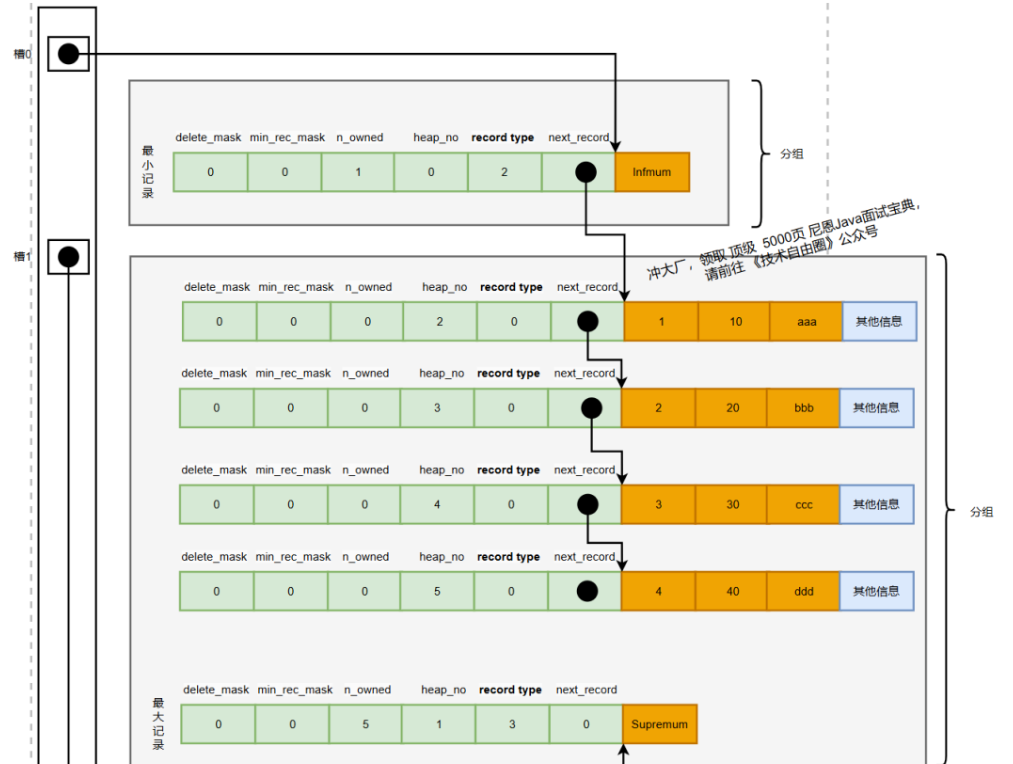
进一步插入记录(构造多组目录)
INSERT INTO test VALUES (5, 50, 'eee');
INSERT INTO test VALUES (6, 60, 'fff');
INSERT INTO test VALUES (7, 70, 'ggg');
INSERT INTO test VALUES (8, 80, 'hhh');
INSERT INTO test VALUES (9, 90, 'iii');
INSERT INTO test VALUES (10, 100, 'jjj');
INSERT INTO test VALUES (11, 110, 'kkk');
INSERT INTO test VALUES (12, 120, 'lll');此时页内形成多个记录组,并自动生成多个 slot,以支持高效查找。
查找记录的过程(主键 = 6)
查找流程如下:
- 二分查找目录槽:根据主键大小,在 slot 中二分查找缩小范围。
假设槽 1 对应主键为 4,而目标是主键 6 → 继续向右搜索。 - 遍历槽内记录:找到对应的槽组后,通过
next_record依次遍历记录,直到匹配目标。
如果目标记录在最后一个槽组中,则需先定位前一个槽位的末尾记录,再向后查找。
这种设计结合链表的灵活性与目录的高效定位,是一种典型的“空间换时间”方案。
File Header(页头信息)
每个页的开头都有一个 File Header 区域,包含以下关键字段:
FIL_PAGE_OFFSET:当前页的页号(唯一标识)FIL_PAGE_PREV / FIL_PAGE_NEXT:当前页的前后页号,用于双向链表连接页
这些字段将所有页串联成一个链式结构,实现页之间的双向导航。

InnoDB 和 MyISAM对比
InnoDB 与 MyISAM 核心区别对比表
对比项 | InnoDB | MyISAM |
事务支持 | 支持,符合 ACID | 不支持 |
锁机制 | 行级锁(高并发) | 表级锁(写操作会阻塞整个表) |
外键支持 | 支持外键约束 | 不支持 |
崩溃恢复 | 有 redo log 自动恢复机制 | 崩溃后可能丢失数据,需手动修复 |
存储文件 |
(数据 + 索引) |
(数据)+ (索引) |
索引类型 | 聚簇索引(主键排序存储) | 非聚簇索引(索引与数据分离) |
全文索引 | 5.6 及以上版本支持 | 原生支持,性能优 |
COUNT(*) | 需扫描全表,性能较慢 | 直接读取行数,性能极高 |
压缩功能 | 不支持表压缩 | 支持表压缩,适合节省存储空间 |
典型场景 | 高并发事务场景,如订单、支付系统 | 读多写少的场景,如日志、分析型查询 |
核心差异详解
(1)事务与锁机制
- InnoDB:支持事务,采用行级锁,并发处理能力强,适合写操作频繁的业务。
- MyISAM:不支持事务,采用表级锁,在写入时会锁整个表,效率低,易产生阻塞。
(2)索引与存储设计
- InnoDB 使用 聚簇索引,数据按主键物理排序,主键查询效率极高;但二级索引需通过主键“回表”访问数据。
- MyISAM 的索引和数据存储是分离的,索引中保存数据地址,所有查询都需通过索引定位数据。
(3)性能权衡
- MyISAM 在执行
COUNT(*)和 全文检索方面表现更优,但牺牲了事务一致性与并发性能。 - InnoDB 提供了更强的安全性与并发控制,适合在线交易等对数据可靠性要求高的系统。
(4)故障恢复能力
- InnoDB 使用 redo log(重做日志),在数据库异常崩溃后可自动恢复,保障数据一致性。
- MyISAM 不具备崩溃自动恢复机制,数据损坏需手动执行
REPAIR TABLE恢复。
总结建议
- 选择 InnoDB:若业务需要事务支持、数据安全、高并发写入,如订单处理、支付系统等 OLTP 场景。
- 选择 MyISAM:适用于只读或写入极少的场景,如静态日志查询、临时数据分析。但在 MySQL 8.0+ 版本中,MyISAM 已不再推荐使用,官方也逐步弱化其支持。