Python----大模型(从预训练到分布式优化的核心技术解析)
一、大型语言模型(LLM)的训练
预训练 → 监督微调 → 奖励模型训练 → 强化学习微调
1.1、Pretraining — 预训练阶段
这是大模型训练的第一个,也是最基础的阶段。
目标: 通过海量的无标签文本数据,让模型进行自监督学习,从而掌握语言的结构、语法和基本世界知识。模型学习的核心任务是预测给定上下文中下一个词是什么。
过程:
数据准备: 收集并处理来自网页、书籍、新闻等多样化的海量文本数据。
模型训练: 基于自监督学习方法,使用语言建模损失函数(如交叉熵损失)来训练模型,使其理解文本中的上下文关系。
产物: 这一阶段的成果是“基座大模型”(Foundation Model)。它具备初步的语言理解和生成能力,但缺乏对特定任务的指令遵循能力。
1.2、Supervised Finetuning(SFT) — 监督微调,也叫指令微调阶段
该阶段旨在让模型学会理解并遵循人类指令。
目标: 弥补预训练模型在任务执行上的不足,通过高质量的标注数据,让模型学习如何根据指令生成期望的输出。
过程:
数据准备: 构建包含指令和对应期望输出的高质量数据集,例如问答对、对话或代码生成任务。
监督学习: 使用这些标注数据对模型进行训练,通过最小化模型输出与期望输出之间的差异来优化其生成质量。
产物: 经过监督微调的模型通常以
-instruct或-chat的形式命名,它们已经具备了基本的对话和指令遵循能力。
1.3、Reward Modeling — 奖励模型训练阶段
此阶段为后续的强化学习提供“裁判”。
目标: 训练一个奖励模型(Reward Model, RM),使其能够根据人类偏好,为大模型的生成结果打分。这个分数将作为指导模型优化的奖励信号。
过程:
数据准备: 收集一组大模型的输出,并由人工或自动化方法对这些输出按质量优劣进行排序。
模型训练: 使用这些排序数据来训练奖励模型,使其能为高质量的输出预测更高的分数。
产物: 一个能够评估大模型输出质量的奖励模型,它能像一个“裁判”一样,判断模型的回答是否符合人类的价值观和期望。
1.4、Reinforcement Learning(RL)— 增强学习微调阶段
这是让模型最终与人类偏好对齐的关键阶段,通常被称为“人类反馈强化学习”(RLHF)。
目标: 利用奖励模型的反馈,通过强化学习算法进一步优化大模型的生成策略,使其能够持续生成获得高分(即更符合人类偏好)的文本。
过程:
基于奖励反馈: 让模型生成不同的输出,并由奖励模型进行评分。
策略优化: 使用强化学习算法(如PPO)调整模型的生成策略,使其倾向于生成能获得更高奖励分数的文本。
产物: 经过RLHF后,模型最终版本具备了强大的任务完成能力和高度优化的输出质量,能够更好地与人类意图对齐。
预训练 → 监督微调 → 奖励模型训练 → 强化学习微调
二、分布式训练
加速主要体现在两个方面:
可以训练更大的模型;
训练速度更快
而影响因素主要是:
模型参数,训练更大的模型的时候除了要将模型参数加载到GPU中还需要保存中 间过程等等(GPU内存问题);
网络通信,使用分布式训练时数据需要在GPU之间传输(GPU带宽问题)
2.1、数据并行 (DataParallel)
把整个模型复制到每个GPU上,让每块GPU处理数据的不同部分。
例如,把数据分成N个部分,每块GPU独立计算它那一部分的数据(前向传播和反向 传播),得出梯度后,再同步所有GPU的梯度以更新模型参数。但他需要在每一张卡 上都保存一个模型,因此如果一张卡装不下模型的话还是会OOM。
2.2、张量并行/模型并行(TensorParallel)
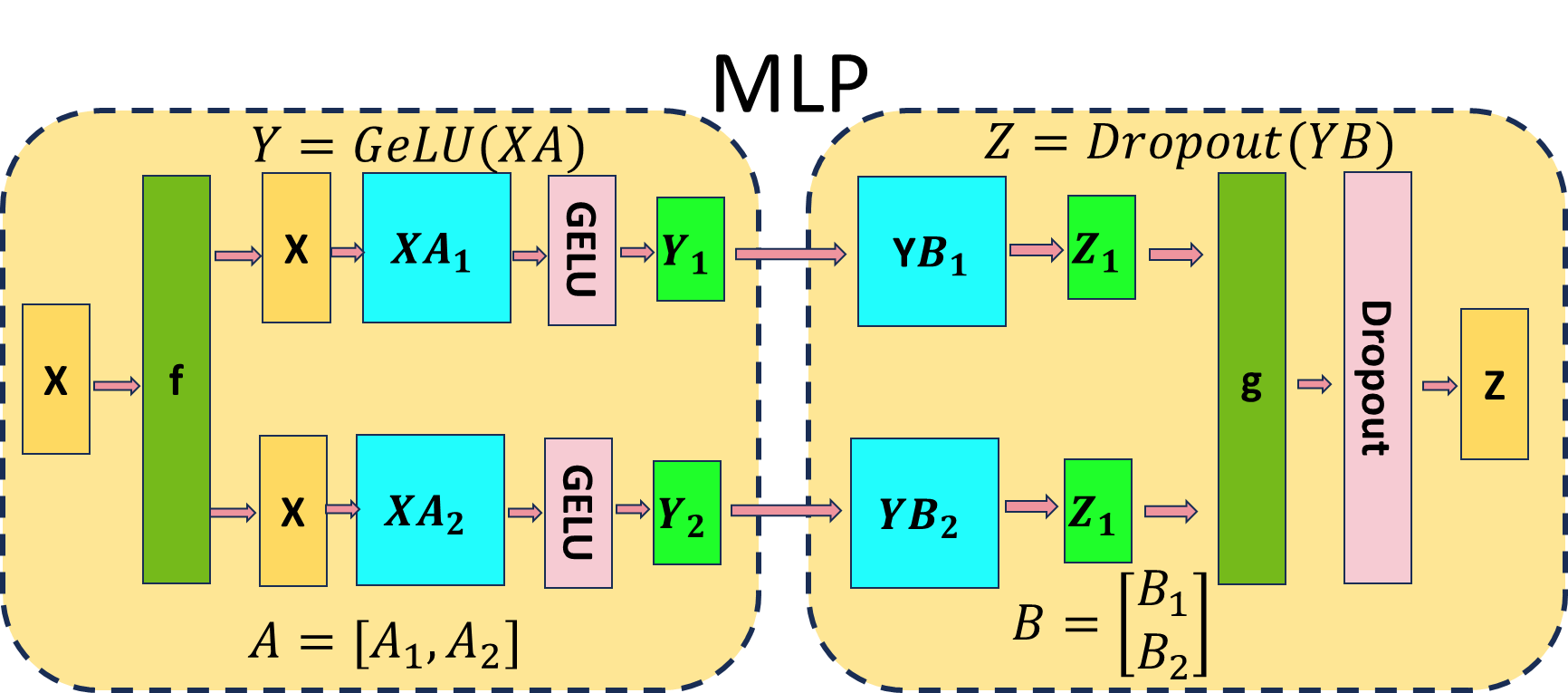
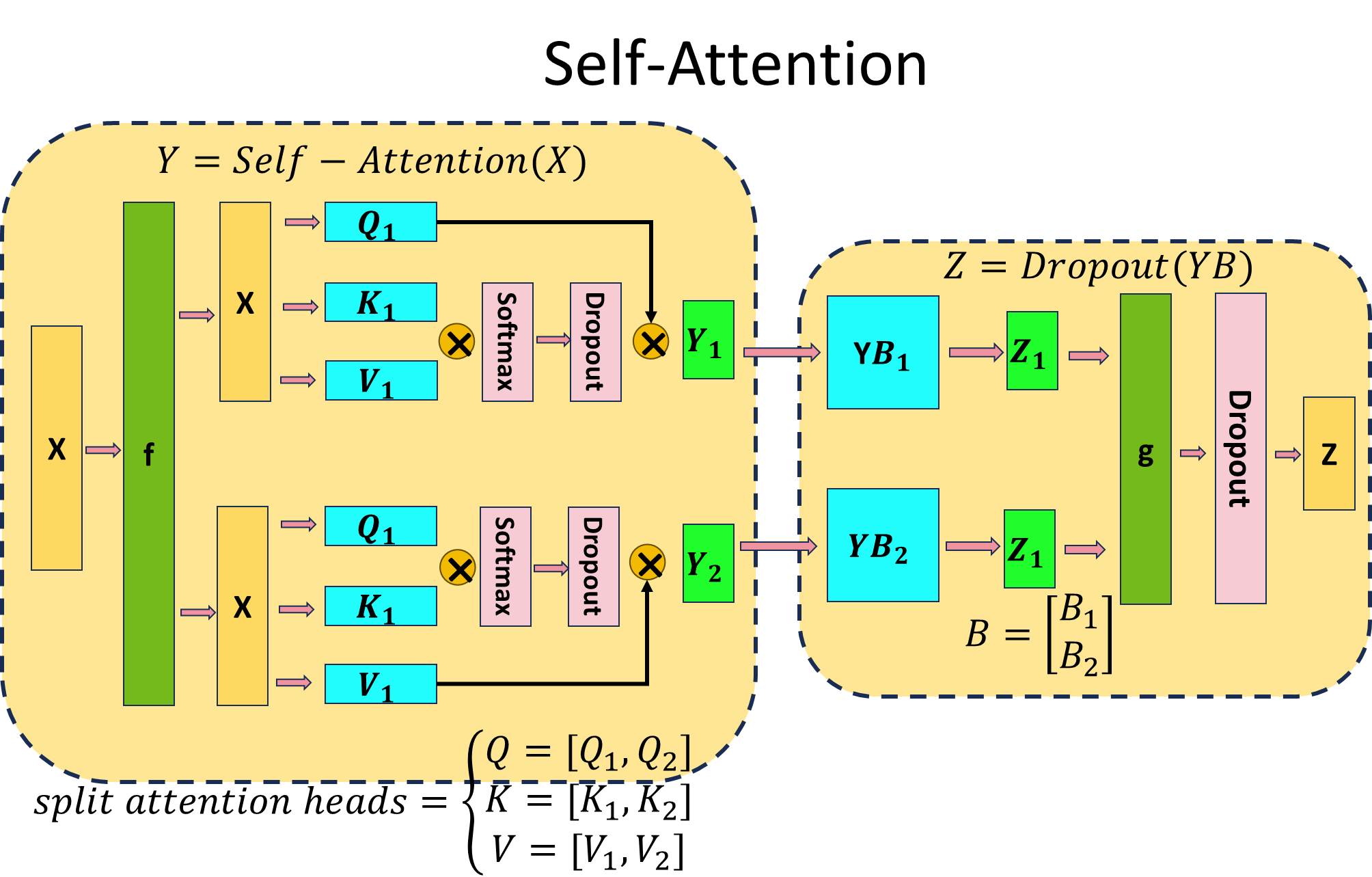
2.3、流水线并行 (PipelineParallel)
在模型并行的基础上增加数据并行。经典的流水线并行范式有Google推出的Gpipe, 和微软推出的PipeDream。
2.4、通信机制
NCCL 是 NVIDIA 提供的一种通信库,专为多 GPU 系统设计。它支持高效的多卡通信 操作,能够充分利用 GPU 间的高速互连(如 NVLink),并支持常见的通信模式(如 Broadcast、Reduce、AllReduce)。NCCL 已成为在多 GPU 上进行分布式深度学习 训练时的首选通信库。
分布式训练中最常用的通信操作有以下几种:
Broadcast(广播):把数据从一个设备传递到所有其他设备上。一般用于将主 GPU 的模型参数传递给其他 GPU,使它们的初始参数一致。例如,一个模型的 权重在开始训练时可能存储在主 GPU 上,通过 Broadcast 操作,所有 GPU 都能 获得这组参数的初始值。
Reduce(规约):将所有设备上的数据聚合(例如求和或求平均,SUM、MIN、 MAX、PROD、LOR ),然后把结果存储到一个指定的设备上。通常用于梯度聚 合,即每个设备计算完自己的梯度后,通过 Reduce 操作将梯度汇总到主设备, 再进行一次统一的参数更新。
AllReduce(全规约):将每个设备的数据聚合后,将结果分发到所有设备上。 AllReduce 是分布式训练中最常用的操作,尤其是在数据并行训练中。每个 GPU 计算自己的梯度后,通过 AllReduce 进行求和或平均,然后每个 GPU 获得相同 的全局梯度并更新参数。
AllGather(全收集):每个设备将自己的数据发送给其他所有设备,所有设备最 后都拥有来自所有设备的数据。在需要各设备获得其他设备上的中间结果时, AllGather 是非常有效的选择。
Scatter(分散):Scatter 是将一个大的数据集分成多个小块,并将每个小块发 送到不同的设备上。Scatter 常用于分布式数据加载阶段,确保每个设备处理不同 的数据分块。
ReduceScatter(规约-分散):首先将每个设备上的数据进行规约操作(如求 和),然后将结果分发到不同设备上。ReduceScatter 可以节省通信量,常用于 梯度分布式优化中。
2.5、训练工具
2.5.1、torch.nn.DataParallel
DataParallel (DP) 是一种较为简单的多 GPU 并行方式,它将模型复制到每个 GPU 上,并将输入数据按 batch 维度分割后分发到不同的 GPU 进行并行计算。然后,主 GPU 收集所有 GPU 的计算结果并进行汇总。
DP 的缺点:
单进程多线程: DP 使用单进程多线程的方式实现并行,受到 Python 全局解释 器锁 (GIL) 的限制,无法充分利用多核 CPU 的性能。
主 GPU 瓶颈: 所有输入数据都需要先加载到主 GPU,然后由主 GPU 分发到其 他 GPU。计算完成后,所有 GPU 的结果也需要汇总到主 GPU。这导致主 GPU 负载过重,成为性能瓶颈。
不适合多机多卡: DP 只能在单台机器上的多个 GPU 上进行并行计算,无法扩展 到多台机器。
2.5.2、torch.nn.parallel.DistributedDataParallel
DistributedDataParallel (DDP) 是一种更先进、更高效的分布式训练方法。它使用多 进程的方式,每个进程对应一个 GPU。每个进程都拥有模型的完整副本和独立的优 化器。
DDP 的优势:
多进程: DDP 使用多进程的方式,每个进程独立运行,避免了 GIL 限制,充分 利用多核 CPU 的性能。
本地计算和更新: 每个 GPU 都有独立的模型副本和优化器,梯度计算和参数更 新都在本地进行,减少了主 GPU 的负担,提高了训练效率。
支持多机多卡: DDP 可以扩展到多台机器上的多个 GPU,适用于大规模的分布 式训练。
三、DP (Data Parallel)
意为数据并行,这种训练方式使用的是单个程序内的多个线程(单 进程多线程)来并行处理任务,而不是真正的分布式系统,所以它只适用于同一台机 器上的多个GPU。
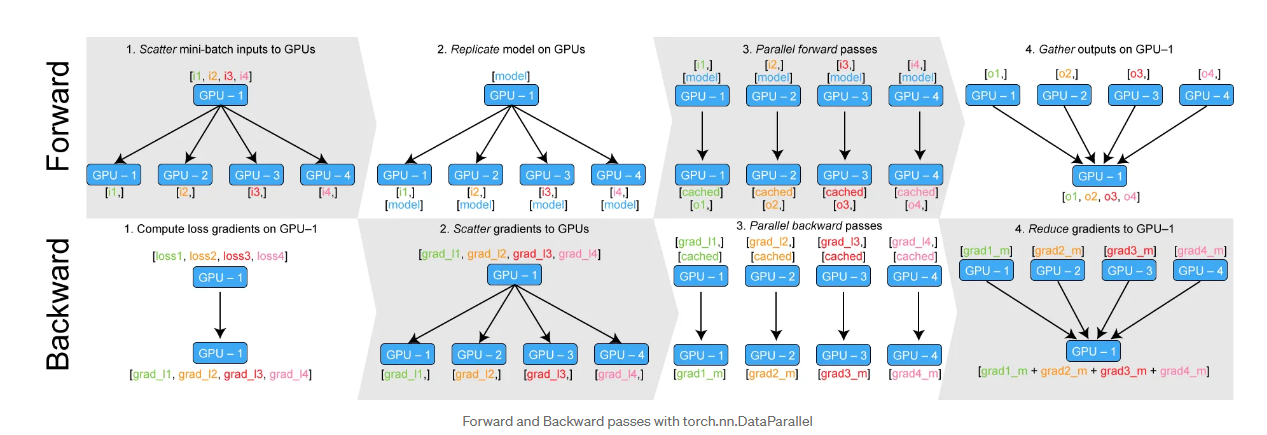
基本流程
数据划分与分发:训练数据被划分为mini-batches,并分发到多个GPU上处理
模型复制:每个GPU上维护相同的模型副本
并行前向传播:各GPU独立计算前向传播,生成输出
结果汇总:所有GPU的输出被返回到主GPU进行汇总
损失计算:主GPU计算汇总损失值及其梯度
梯度分发:主GPU将梯度分发到所有副GPU
参数更新:各GPU根据接收到的梯度进行反向传播和参数更新
参数同步:更新后的参数合并到主GPU,确保模型一致性
主要瓶颈
通信开销:
辅助GPU完成计算后必须将结果发送回主GPU
主GPU计算梯度后需要将更新参数分发给所有辅助GPU
频繁的数据交换增加了通信负担,降低训练效率
主GPU负载不均衡:
所有结果汇总到主GPU,使其计算负载显著高于其他GPU
在大语言模型训练中,这种不均衡现象更为严重
model = nn.DataParallel(model)四、DDP
DDP核心设计原理
DDP(Distributed Data Parallel)是PyTorch提供的高效分布式训练方法,与传统的DP(Data Parallel)相比具有显著优势:
进程模型:
每个GPU运行在独立的进程中(每个节点启动独立Python训练脚本)
每个进程维护自己的模型副本
每个进程从磁盘独立加载数据
数据分发:
数据集被切分为多个子集分配给不同进程
实现真正的数据并行,充分利用多GPU计算资源
训练流程机制
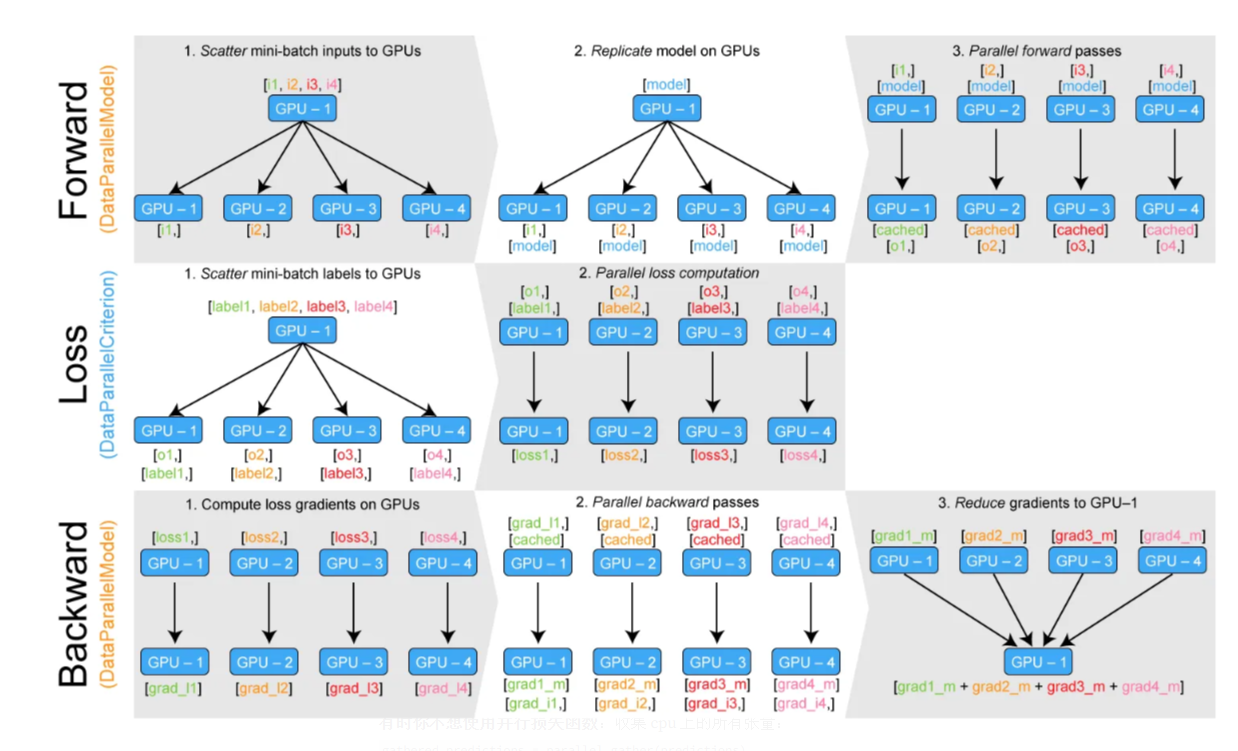
局部计算阶段:
各进程在其数据子集上执行完整的前向传播和反向传播
计算出局部梯度(不能直接用于参数更新)
梯度同步阶段:
使用All-Reduce操作同步所有进程的梯度
通过求和/平均实现梯度聚合
确保全局梯度一致性
参数更新阶段:
所有进程根据同步后的全局梯度更新参数
保持各进程模型副本始终一致
性能优势分析
并行效率:
避免Python全局解释器锁(GIL)限制
实现真正的多进程并行计算
通信优化:
与DP相比总通信量相同
但避免了DP的主GPU瓶颈问题
DP因负载不均导致更多数据搬运时间
扩展性优势:
适合大规模分布式训练场景
在多节点环境下表现优异
有效减少同步等待时间
DDP通过这种设计实现了高效、可扩展的分布式训练,特别适合大规模深度学习模型的训练需求。
初始化DDP环境
import torch.distributed as dist import osif use_DDP: # 如果使用分布式数据并行(DDP)# 初始化进程组,使用NCCL作为后端dist.init_process_group("nccl")# 获取DDP环境变量ddp_rank = int(os.environ['RANK']) # 全局进程排名ddp_world_size = int(os.environ['WORLD_SIZE']) # 总进程数ddp_local_rank = int(os.environ['LOCAL_RANK']) # 本地节点排名# 设置当前GPU设备device = f'cuda:{ddp_local_rank}'torch.cuda.set_device(device)
数据加载设置
# 使用DistributedSampler分配数据 sampler = DistributedSampler(dataset,num_replicas=ddp_world_size,rank=ddp_rank,shuffle=True # 默认启用shuffle )# 创建DataLoader (注意要设置shuffle=False) data_loader = DataLoader(dataset,batch_size=batch_size,sampler=sampler,shuffle=False # sampler已经处理了shuffle )
清理资源
# 训练结束后销毁进程组 dist.destroy_process_group()
五、Accelerate
在使用DDP的时候我们配置了大量的东西才启动了多卡训练,而Accelerate库就是集 合了上面分布式训练方法的优势,用较少的代码即可使用DDP。实际上就是集成了多 种分布式框架,给用户提供统一接口。
accelerate非常简单只需要将data_loader, model, optimizer使用 accelerator.prepare包装一下就可以使用了
from accelerate import Accelerator# 初始化 Accelerator
accelerator = Accelerator() # 使用 prepare 方法自动处理分布式设置
data_loader, model, optimizer = accelerator.prepare(data_loader, # 数据加载器model, # 模型optimizer # 优化器
)六、Deepspeed
6.1、核心架构与ZeRO技术
DeepSpeed是由微软开发的深度学习优化库,专注于提升大规模模型训练效率,其核心创新是ZeRO(Zero Redundancy Optimizer)技术,通过消除数据并行中的内存冗余来优化训练过程。
传统数据并存的显存消耗
模型参数:完整的模型副本
优化器参数:如Adam优化器中的一阶/二阶动量
梯度数据:反向传播产生的中间梯度
6.2、ZeRO三级优化策略
| 优化级别 | 分区对象 | 通信操作 | 内存节省效果 |
|---|---|---|---|
| ZeRO-1 | 优化器状态 | Allgather | 减少4倍内存 |
| ZeRO-2 | 梯度数据 | Allreduce | 减少8倍内存 |
| ZeRO-3 | 模型参数 | Broadcast/Gather | 内存需求与GPU数量线性下降 |
ZeRO-1:优化器状态分区
将优化器状态分片到不同GPU
每个GPU只更新自己负责的部分
通过Allgather同步更新后的参数
ZeRO-2:梯度数据分区
在ZeRO-1基础上增加梯度分片
反向传播后通过Allreduce汇总平均梯度
各GPU使用全局梯度更新参数
ZeRO-3:完整模型参数分区
最高级别优化,模型参数分片存储
按需通过通信获取缺失参数
实现真正的零冗余存储
6.3、扩展优化技术
ZeRO++ 增强功能
动态显存复用技术
优化数据分片策略
降低GPU间通信延迟
ZeRO-Offload 混合计算
将梯度和优化器状态卸载到CPU内存
支持NVMe SSD扩展存储
保持GPU核心计算效率
DeepSpeed Ulysses
超大规模分布式训练方案
支持模型和数据并行极限扩展
灵活的任务调度机制
6.4、技术优势对比
| 技术指标 | 传统数据并行 | ZeRO-1 | ZeRO-2 | ZeRO-3 |
|---|---|---|---|---|
| 模型参数 | 全复制 | 全复制 | 全复制 | 分片 |
| 梯度数据 | 全复制 | 全复制 | 分片 | 分片 |
| 优化器状态 | 全复制 | 分片 | 分片 | 分片 |
| 内存效率 | 1x | 4x | 8x | Nx(GPU数量) |
DeepSpeed通过这种分级优化策略,使训练模型规模可以随GPU数量线性扩展,为超大规模模型训练提供了切实可行的解决方案。
七、混合精度训练
混合精度训练是通过结合FP16(半精度)和FP32(单精度)浮点数来优化深度学习训练的技术方案。
浮点数格式对比
特性 | FP32 | FP16 | 优势比较 |
|---|---|---|---|
位数 | 32位 | 16位 | 内存减半 |
指数位 | 8位 | 5位 | |
尾数位 | 23位 | 10位 | |
表示范围 | ±3.4×10³⁸ | ±6.55×10⁴ | FP32范围更大 |
有效数字 | 约7位十进制 | 约3位十进制 | FP32精度更高 |
存储空间 | 4字节 | 2字节 | FP16内存占用少50% |
核心挑战与解决方案
数值溢出/下溢问题
现象:FP16范围有限导致大数溢出/小数归零
方案:动态损失缩放(Loss Scaling)
梯度消失问题
现象:小梯度在FP16下被截断
方案:维护FP32主权重副本
标准工作流程
保存FP32主权重副本
前向传播时转换为FP16计算
FP16计算损失并应用比例因子放大
FP16反向传播计算梯度
梯度除以比例因子还原
FP32更新主权重
性能提升维度
显存优化:同等显存可训练更大模型或batch size
计算加速:利用Tensor Core实现2-3倍速度提升
通信效率:分布式训练中减少50%通信量
GPU架构 | 支持特性 | 推荐场景 |
|---|---|---|
Turing | 基础Tensor Core支持 | 推理场景 |
Ampere | 增强Tensor Core + TF32支持 | 训练首选 |
Hopper | FP8支持 + 优化通信 | 超大模型训练 |
import torch# 自动混合精度上下文
with torch.autocast(device_type='cuda', dtype=torch.float16):outputs = model(**batch)loss = criterion(outputs, targets)# 带损失缩放的梯度计算
scaler = torch.cuda.amp.GradScaler()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()最佳实践建议
监控工具:定期检查梯度值范围,避免溢出/下溢
动态调整:根据训练稳定性自动调整损失缩放系数
精度验证:关键指标(如验证集准确率)需与FP32基准对比
混合策略:敏感操作(如softmax)可保持FP32计算
混合精度训练已成为现代深度学习训练的标配技术,合理应用可在几乎不损失模型精度的情况下显著提升训练效率。