途游Android面试题及参考答案
对 Java 面向对象的理解是什么?多态的实现方法有哪些?
Java 面向对象是一种编程思想,核心在于将现实世界中的事物抽象为 “对象”,每个对象由 “属性”(数据)和 “方法”(行为)组成,通过对象之间的交互完成功能。其核心特性包括封装、继承和多态:
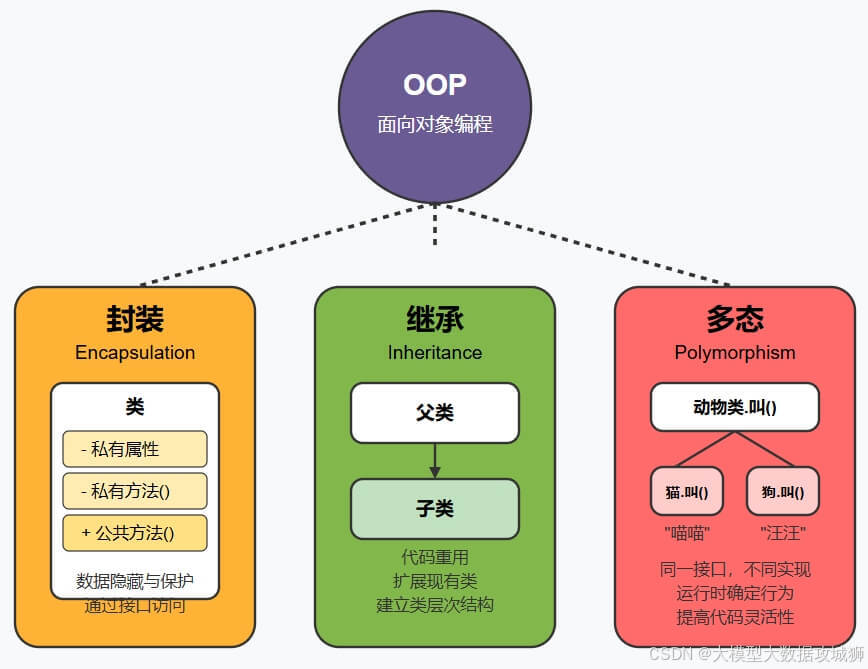
封装是指将对象的属性和方法隐藏在类内部,仅通过公共接口(如 getter/setter 方法)对外暴露,避免外部直接修改内部状态,提高代码安全性和可维护性。例如,一个 Person 类可以将 age 设为私有,通过 setAge() 方法控制赋值逻辑,防止传入负数。
继承是指子类通过 extends 关键字继承父类的属性和方法,同时可以新增或重写父类方法,实现代码复用和扩展。比如 Student 类继承 Person 类,复用 name 属性,新增 studentId 属性。
多态是指同一行为在不同对象上表现出不同形态,允许使用父类引用指向子类对象,调用方法时实际执行的是子类的实现。
多态的实现方法主要有三种:
- 继承重写:子类继承父类后重写父类的方法,父类引用调用该方法时,实际执行子类的重写版本。例如:
class Animal {void sound() {System.out.println("动物叫");}
}
class Dog extends Animal {@Overridevoid sound() {System.out.println("汪汪叫");}
}
public class Test {public static void main(String[] args) {Animal animal = new Dog(); // 父类引用指向子类对象animal.sound(); // 输出"汪汪叫",体现多态}
}
- 接口实现:多个类实现同一个接口,并重写接口中的抽象方法,接口引用可以指向不同的实现类对象,调用方法时执行具体实现。例如:
interface Shape {void draw();
}
class Circle implements Shape {@Overridepublic void draw() {System.out.println("画圆");}
}
class Square implements Shape {@Overridepublic void draw() {System.out.println("画正方形");}
}
- 方法重载:在同一个类中,方法名相同但参数列表(类型、个数、顺序)不同,编译器根据参数自动匹配对应的方法,属于编译时多态。例如:
class Calculator {int add(int a, int b) { return a + b; }double add(double a, double b) { return a + b; }
}
记忆法:可通过 “封继多” 记忆面向对象三大特性(封装、继承、多态);多态实现记 “重接重”(重写、接口、重载),对应继承重写、接口实现、方法重载三种方式。
引用有哪些类型?它们之间有何区别?
Java 中引用分为四种类型:强引用、软引用、弱引用、虚引用,它们的核心区别在于被垃圾回收器(GC)回收的时机不同,适用于不同的场景。
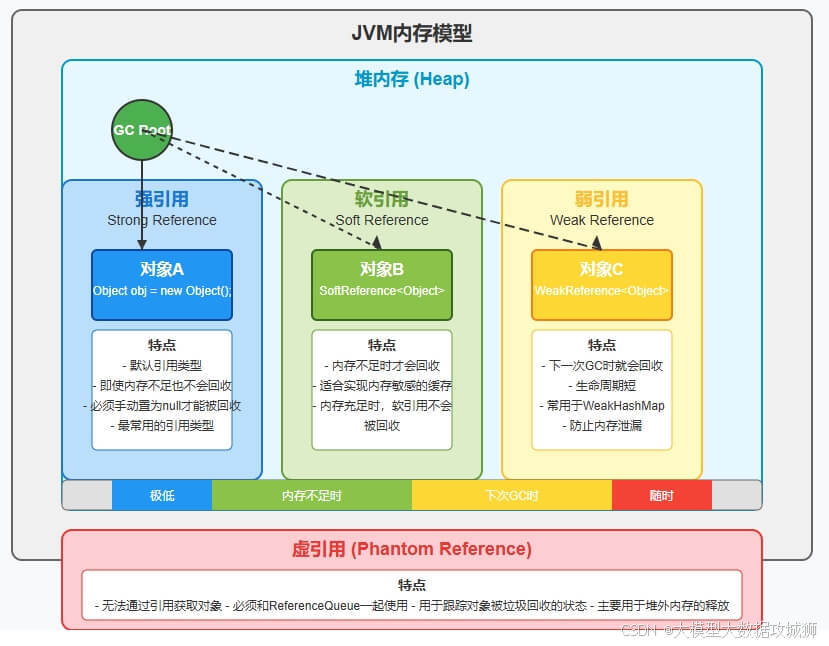
强引用是最常见的引用类型,通过 Object obj = new Object() 创建,只要强引用存在,被引用的对象就不会被 GC 回收,即使内存不足也会抛出 OutOfMemoryError。例如,普通的对象赋值都属于强引用,这是默认的引用方式,用于确保对象在使用期间不被回收。
软引用(SoftReference)用于描述非必需但仍有用的对象。当内存充足时,软引用的对象不会被回收;当内存不足时,GC 会回收软引用关联的对象。软引用常与 ReferenceQueue 配合使用,当对象被回收后,软引用会被加入队列,便于清理无效引用。适合用于缓存场景,如图片缓存,内存充足时保留缓存,内存不足时释放以避免 OOM。
弱引用(WeakReference)的生命周期比软引用更短,无论内存是否充足,只要 GC 触发,弱引用关联的对象就会被回收。弱引用同样可配合 ReferenceQueue 使用,常用于存储非必需的临时数据,如 ThreadLocal 中的 Entry 就使用弱引用存储键,避免内存泄漏。
虚引用(PhantomReference)是最弱的引用类型,无法通过虚引用获取对象实例,唯一作用是跟踪对象被 GC 回收的过程。虚引用必须与 ReferenceQueue 结合使用,当对象被回收时,虚引用会被加入队列,用于在对象销毁前执行必要的清理操作(如释放直接内存),典型应用是 DirectByteBuffer 的回收机制。
四种引用的区别可总结如下:
| 引用类型 | 回收时机 | 是否可获取对象 | 主要用途 |
|---|---|---|---|
| 强引用 | 永不回收(除非引用消失) | 是 | 普通对象引用 |
| 软引用 | 内存不足时 | 是 | 缓存(如图片缓存) |
| 弱引用 | GC 触发时 | 是 | 临时数据存储(如 ThreadLocal) |
| 虚引用 | GC 触发时 | 否 | 跟踪对象回收(如直接内存清理) |
记忆法:可通过 “强不丢,软缺丢,弱必丢,虚跟踪” 记忆。“强不丢” 指强引用不被回收;“软缺丢” 指软引用在内存不足时回收;“弱必丢” 指弱引用遇 GC 必回收;“虚跟踪” 指虚引用仅用于跟踪回收。
单例模式有哪几种实现方法(如饿汉式、懒汉式、双重检查、静态内部类、枚举)?
单例模式是一种创建型设计模式,确保一个类仅有一个实例,并提供全局访问点。常见实现方法有以下五种:
- 饿汉式:在类加载时就创建实例,线程安全但可能提前占用资源。
public class Singleton {// 类加载时初始化实例private static final Singleton INSTANCE = new Singleton();// 私有构造方法,防止外部实例化private Singleton() {}// 提供全局访问点public static Singleton getInstance() {return INSTANCE;}
}
优点:实现简单,类加载时完成初始化,天然线程安全;缺点:类加载时即创建实例,若实例从未使用,会造成资源浪费。
- 懒汉式(基础版):延迟初始化,仅在首次调用
getInstance()时创建实例,但线程不安全。
public class Singleton {private static Singleton instance;private Singleton() {}// 线程不安全,多线程同时调用可能创建多个实例public static Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}
}
优点:延迟加载,节省资源;缺点:多线程环境下存在并发问题,可能创建多个实例,不适合生产环境。
- 懒汉式(同步方法版):通过
synchronized修饰getInstance()方法保证线程安全,但性能较差。
public class Singleton {private static Singleton instance;private Singleton() {}// 同步方法,确保线程安全但效率低public static synchronized Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}
}
优点:解决线程安全问题;缺点:每次调用方法都需同步,频繁调用时性能开销大。
- 双重检查锁(DCL):结合懒加载和同步机制,仅在实例未初始化时同步,兼顾线程安全和性能。
public class Singleton {// volatile 防止指令重排序,确保实例初始化完成后再被访问private static volatile Singleton instance;private Singleton() {}public static Singleton getInstance() {// 第一次检查,避免不必要的同步if (instance == null) {synchronized (Singleton.class) {// 第二次检查,防止多线程同时通过第一次检查后重复创建if (instance == null) {instance = new Singleton();}}}return instance;}
}
优点:延迟加载,线程安全,性能优秀;注意:instance 需用 volatile 修饰,避免指令重排序导致的未初始化实例被访问。
- 静态内部类:利用类加载机制实现延迟初始化和线程安全,推荐使用。
public class Singleton {private Singleton() {}// 静态内部类,仅在调用 getInstance() 时加载private static class SingletonHolder {private static final Singleton INSTANCE = new Singleton();}public static Singleton getInstance() {return SingletonHolder.INSTANCE;}
}
优点:延迟加载(内部类按需加载),线程安全(类加载过程是线程安全的),实现简单,性能好。
- 枚举:天然防止反射和序列化破坏单例,是最安全的实现方式。
public enum Singleton {INSTANCE;// 可以添加方法public void doSomething() {// 业务逻辑}
}
优点:枚举实例在类加载时创建,线程安全;反射无法创建枚举实例,序列化不会破坏单例;缺点:无法延迟加载,若实例初始化开销大,可能提前占用资源。
记忆法:按 “加载时机 + 安全性” 记忆,“饿汉立即安全,懒汉延迟危险,双重检查兼顾,静态内部类巧妙,枚举最安全”。其中,静态内部类和枚举是推荐在实际开发中使用的方式。
常用的数据结构有哪些?
Java 中常用的数据结构可分为集合框架(Collection)和映射(Map)两大类,每种结构基于不同的底层实现,适用于不同场景:
List(列表):有序可重复的集合,允许通过索引访问元素,主要实现类有
ArrayList、LinkedList、Vector。ArrayList:底层基于动态数组实现,支持随机访问(通过索引获取元素),查询效率高(时间复杂度 O (1)),但增删元素(尤其是中间位置)需要移动元素,效率低(O (n))。适合频繁查询、较少增删的场景。LinkedList:底层基于双向链表实现,不支持随机访问,查询效率低(O (n)),但增删元素仅需修改指针,效率高(O (1))。适合频繁增删、较少查询的场景,同时实现了Deque接口,可作为队列或栈使用。Vector:与ArrayList类似,但方法加了synchronized修饰,是线程安全的,不过性能较差,现已被ArrayList替代,多线程场景推荐使用Collections.synchronizedList()或CopyOnWriteArrayList。
Set(集合):无序不可重复的集合,不允许重复元素,主要实现类有
HashSet、LinkedHashSet、TreeSet。HashSet:底层基于哈希表(HashMap)实现,存储元素的哈希值,查询、增删效率高(平均 O (1)),元素无序。判断元素是否重复依赖hashCode()和equals()方法。LinkedHashSet:继承自HashSet,底层通过链表维护元素插入顺序,兼具哈希表的高效性和有序性,性能略低于HashSet。TreeSet:底层基于红黑树实现,元素会按自然顺序或自定义比较器排序,查询、增删效率为 O (log n),适合需要排序的场景。
Map(映射):存储键值对(key-value),key 不可重复,主要实现类有
HashMap、LinkedHashMap、TreeMap、Hashtable。HashMap:底层基于数组 + 链表 / 红黑树(JDK 1.8+)实现,key 允许为 null(仅一个),value 允许为 null,线程不安全,查询、增删效率高(平均 O (1))。当链表长度超过阈值(8)时转为红黑树,优化查询性能。LinkedHashMap:继承自HashMap,通过链表维护键值对的插入顺序或访问顺序(LRU 策略),适合需要保留顺序的场景(如缓存)。TreeMap:底层基于红黑树实现,key 按自然顺序或自定义比较器排序,查询、增删效率 O (log n),适合需要排序的键值对场景。Hashtable:线程安全(方法加synchronized),key 和 value 均不允许为 null,性能较差,已被HashMap替代,多线程场景推荐ConcurrentHashMap。
队列(Queue):遵循先进先出(FIFO)原则,主要实现类有
ArrayDeque、LinkedList、PriorityQueue。ArrayDeque:基于动态数组实现的双端队列,效率高于LinkedList,可作为栈(push/pop)或队列(add/poll)使用。PriorityQueue:基于堆实现的优先级队列,元素按自然顺序或比较器排序,每次出队的是优先级最高的元素,不遵循 FIFO。
栈(Stack):遵循后进先出(LIFO)原则,
Stack类继承自Vector,线程安全但性能差,推荐使用ArrayDeque的push/pop方法替代。数组(Array):固定长度的容器,存储相同类型元素,支持随机访问(O (1)),但长度不可变,增删需创建新数组,适合长度固定的场景。
链表(Linked List):由节点组成的线性结构,节点包含数据和指针,长度可变,增删高效但查询低效,
LinkedList是其典型实现。
记忆法:按 “接口 - 特点 - 实现” 三层记忆,例如 “List 有序可重复,Array 快查 Linked 快删;Set 无序不可重复,Hash 高效 Tree 有序;Map 键值对,Hash 快查 Tree 排序”。通过场景联想(如查询多用 ArrayList,排序用 TreeSet/TreeMap)加深记忆。
说下 JVM 的内存结构,其中哪些是线程私有的?
JVM(Java 虚拟机)的内存结构主要分为五大区域,根据是否线程共享可分为线程私有和线程共享两类,各自承担不同的功能:
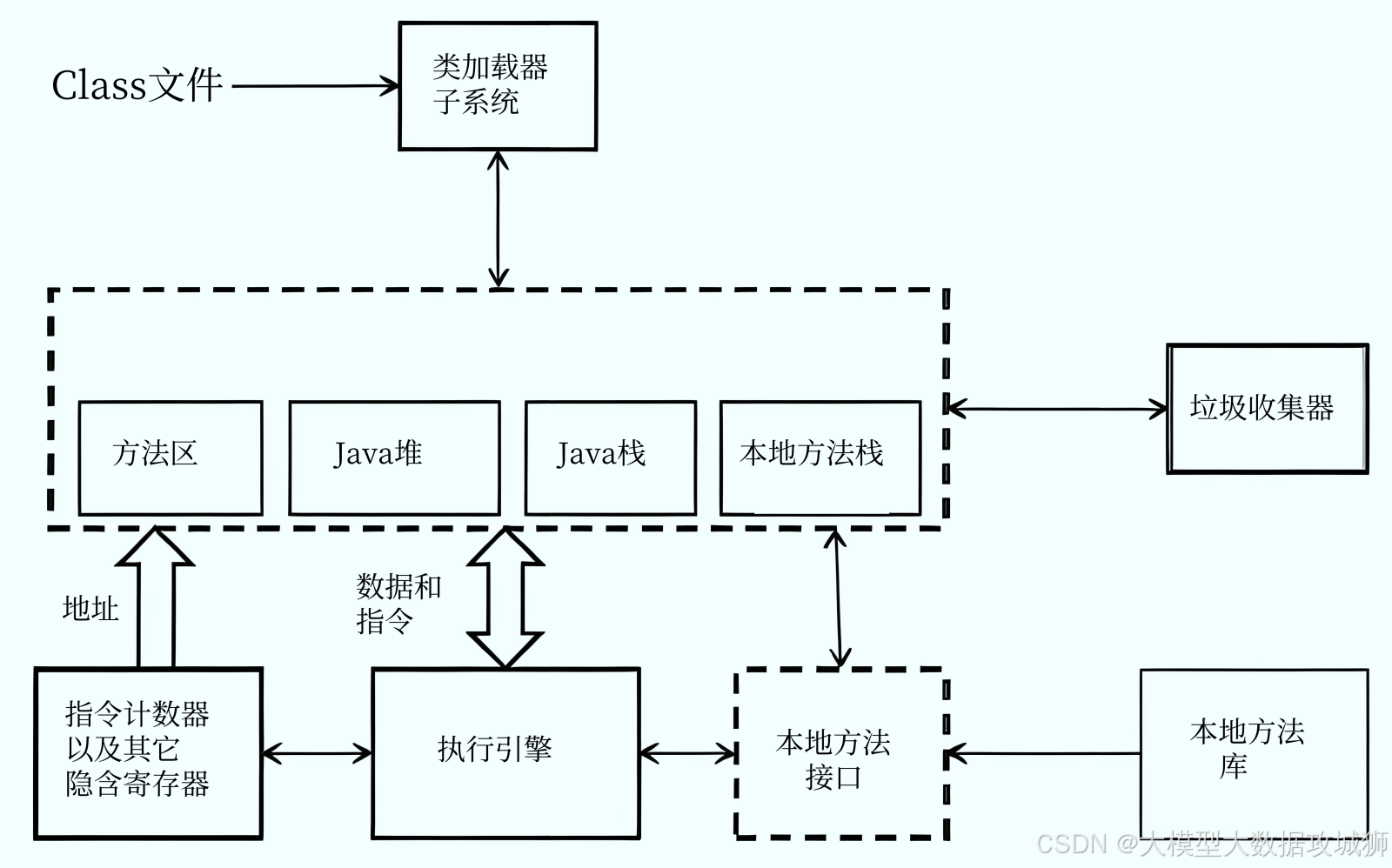
程序计数器(Program Counter Register):线程私有,是一块较小的内存空间,用于记录当前线程执行的字节码指令地址(行号)。在多线程环境中,线程切换后需通过程序计数器恢复执行位置,确保线程切换后能正确继续执行。若线程执行的是 Java 方法,计数器记录当前指令地址;若执行的是 native 方法,计数器值为 undefined。该区域是 JVM 规范中唯一没有规定 OutOfMemoryError 的区域。
虚拟机栈(VM Stack):线程私有,与线程生命周期一致,每个方法执行时会创建一个栈帧(Stack Frame),用于存储局部变量表、操作数栈、动态链接、方法出口等信息。局部变量表存放基本数据类型(boolean、byte 等)和对象引用,其大小在编译期确定。若线程请求的栈深度超过虚拟机允许的最大深度,会抛出 StackOverflowError;若虚拟机栈可动态扩展但无法申请到足够内存,会抛出 OutOfMemoryError。
本地方法栈(Native Method Stack):线程私有,功能与虚拟机栈类似,区别是为 native 方法(非 Java 语言实现的方法)提供服务。不同虚拟机对本地方法栈的实现不同(如 HotSpot 虚拟机将其与虚拟机栈合并),同样可能抛出 StackOverflowError 和 OutOfMemoryError。
堆(Heap):线程共享,是 JVM 中最大的内存区域,用于存储对象实例和数组,是垃圾回收(GC)的主要区域。堆在 JVM 启动时创建,可通过
-Xms(初始堆大小)和-Xmx(最大堆大小)参数调整。堆内存不足时会抛出 OutOfMemoryError。从垃圾回收角度,堆可分为新生代(Eden 区、From Survivor 区、To Survivor 区)和老年代,不同区域采用不同的 GC 算法。方法区(Method Area):线程共享,用于存储已被虚拟机加载的类信息(类名、字段、方法等)、常量、静态变量、即时编译器编译后的代码等数据。JVM 规范将其描述为堆的一部分,HotSpot 虚拟机在 JDK 8 及以后用元空间(Metaspace)实现方法区,元空间使用本地内存,默认无大小限制(可通过
-XX:MetaspaceSize等参数限制),内存不足时抛出 OutOfMemoryError。
总结:线程私有的内存区域为程序计数器、虚拟机栈、本地方法栈,它们的生命周期与线程一致,随线程创建而创建,随线程销毁而释放;堆和方法区是线程共享的,被所有线程共同使用,生命周期与 JVM 一致。
记忆法:可通过 “私三共二” 记忆,“私三” 指三个线程私有区域(程序计数器、虚拟机栈、本地方法栈),“共二” 指两个线程共享区域(堆、方法区)。结合功能联想:线程私有区域与线程执行直接相关(如指令地址、方法栈帧),共享区域存储全局数据(对象、类信息)。
说说类加载的流程,解析阶段对应哪三个阶段?
类加载流程是指将类的字节码数据加载到虚拟机并转化为可执行代码的过程,主要包括五个阶段:加载、验证、准备、解析、初始化。
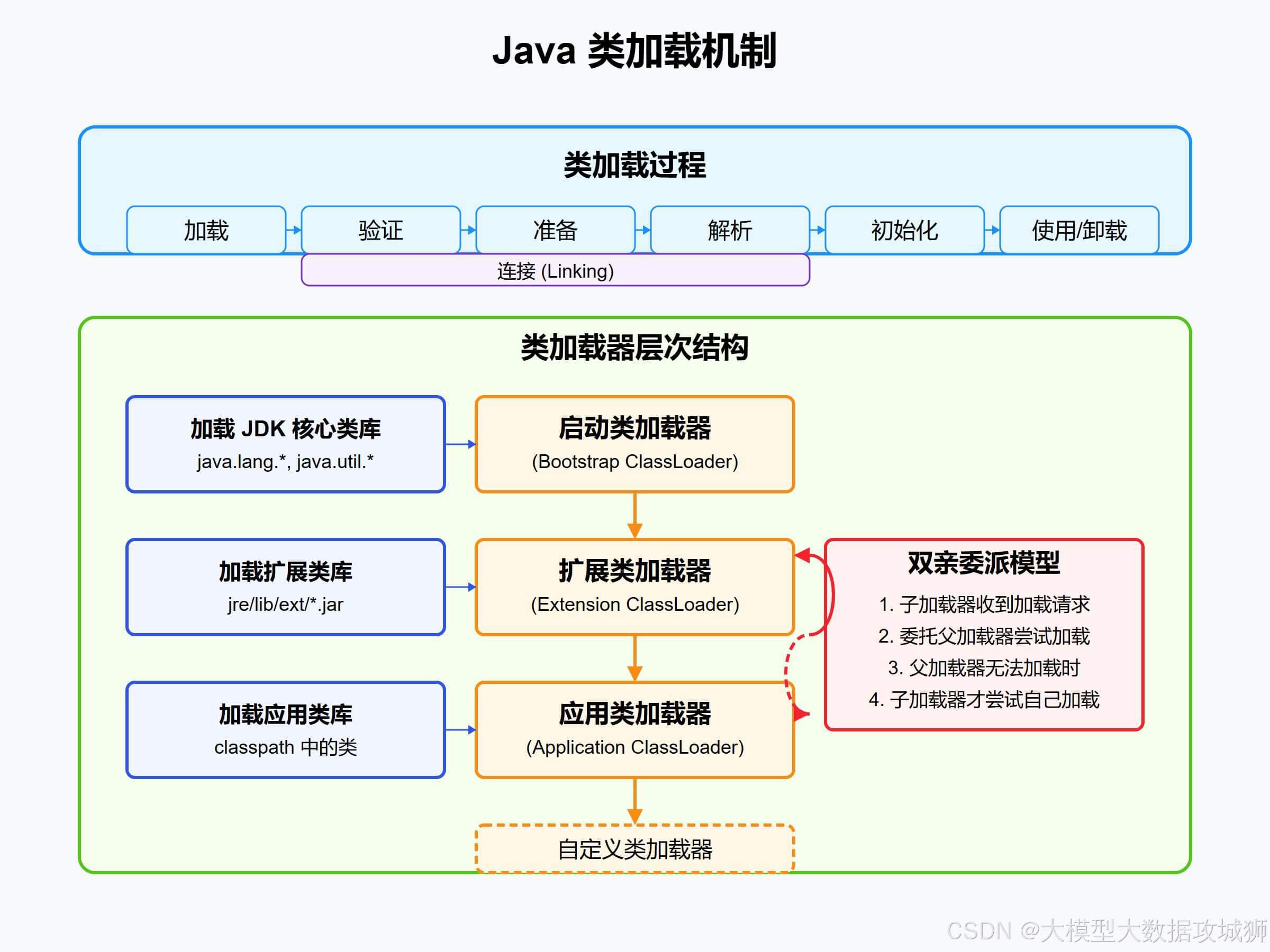
加载阶段是类加载的第一个阶段,虚拟机通过类的全限定名获取该类的二进制字节流(可从 Class 文件、网络、压缩包等来源获取),然后将字节流所代表的静态存储结构转化为方法区的运行时数据结构,并在内存中生成一个代表该类的 Class 对象(作为方法区中该类数据的访问入口)。
验证阶段是为了确保加载的字节流符合 Java 虚拟机规范,避免恶意或错误的字节流危害虚拟机安全。验证包括文件格式验证(如魔数、版本号是否合法)、元数据验证(类的继承关系、字段方法是否符合语法)、字节码验证(方法体指令是否合法,避免跳转到方法体外等)、符号引用验证(常量池中的符号引用是否能被正确解析)。
准备阶段是为类中的静态变量(被 static 修饰的变量)分配内存,并设置默认初始值(如 int 为 0,boolean 为 false,引用类型为 null)。这一阶段不执行代码,仅进行内存分配,例如 “public static int a = 10;” 在准备阶段 a 会被设为 0,赋值 10 的操作在初始化阶段执行。
解析阶段是将常量池中的符号引用转化为直接引用的过程。符号引用是用一组符号描述所引用的目标(如类名、方法名),直接引用是能直接指向目标的指针、偏移量等。解析阶段对应的三个阶段分别是:类或接口的解析(将符号引用中的类或接口名解析为对应的 Class 对象)、字段解析(根据字段所属类的符号引用,解析出字段的直接引用)、方法解析(解析方法的符号引用为直接引用,需区分是类方法还是接口方法)。
初始化阶段是类加载的最后一步,执行类构造器<clinit>() 方法。该方法由编译器自动收集类中所有静态变量的赋值语句和静态代码块合并而成,按代码顺序执行。初始化阶段会触发父类的初始化(父类<clinit>() 先于子类执行),且<clinit>() 方法是线程安全的(虚拟机保证同步执行)。
记忆法:类加载流程可通过 “加验准解初”(加载、验证、准备、解析、初始化)的谐音记忆;解析阶段的三个阶段可用 “类字方”(类或接口、字段、方法)联想记忆,对应解析的三类目标。
ArrayList 和 LinkedList 的区别是什么?
ArrayList 和 LinkedList 都是 Java 集合框架中 List 接口的实现类,但在数据结构、性能表现、内存占用等方面有显著区别,具体如下:
从数据结构来看,ArrayList 基于动态数组实现,其内部维护一个 Object 类型的数组 elementData,通过索引(index)访问元素,数组的初始容量为 10,当元素数量超过当前容量时会自动扩容(通常扩容为原容量的 1.5 倍);LinkedList 基于双向链表实现,每个节点(Node)包含数据域(item)、前驱指针(prev)和后继指针(next),节点之间通过指针连接,不依赖连续内存空间。
在性能方面,随机访问(get (int index))时,ArrayList 通过索引直接定位元素,时间复杂度为 O (1),效率极高;而 LinkedList 需要从表头或表尾开始遍历节点,时间复杂度为 O (n),性能较差。
增删操作的性能因操作位置不同而有差异:在列表尾部添加或删除元素时,ArrayList 只需直接操作数组尾部(若无需扩容),时间复杂度 O (1);LinkedList 也只需修改尾节点指针,时间复杂度 O (1),两者性能接近。但在列表中间或头部操作时,ArrayList 需要移动后续元素(复制数组),时间复杂度 O (n),且若触发扩容(复制整个数组),性能开销更大;LinkedList 只需修改目标节点前后的指针,时间复杂度 O (1)(前提是已定位到目标节点),性能更优。
内存占用方面,ArrayList 的数组可能存在容量浪费(例如容量为 100 但仅存储 50 个元素),且无需存储指针信息;LinkedList 的每个节点需额外存储 prev 和 next 指针(在 64 位系统中每个指针占 8 字节),内存开销更大,且节点在内存中分散存储,可能影响缓存效率。
此外,ArrayList 支持快速随机访问(实现 RandomAccess 接口),适合频繁读取、少量增删且增删多在尾部的场景;LinkedList 不支持快速随机访问,适合频繁在中间位置增删的场景。
记忆法:可通过 “数性内场”(数据结构、性能、内存、适用场景)四个维度记忆两者区别,数据结构对应 “数组 vs 链表”,性能突出 “随机访问快 vs 中间增删快”。
说下 HashMap 的存储结构,put 方法的流程是怎样的?为什么 HashMap 的长度必须是 2 的指数?
HashMap 是 Java 中常用的哈希表实现,其存储结构和 put 方法流程与底层设计密切相关,具体如下:
存储结构方面,JDK1.8 及之后的 HashMap 采用 “数组 + 链表 + 红黑树” 的复合结构。底层数组称为 “哈希桶”(table),数组中的每个元素是一个节点(Node),节点包含 key、value、哈希值(hash)和下一个节点的引用(next)。当多个 key 计算出的哈希桶索引相同时,会形成链表(哈希冲突);当链表长度超过阈值(默认 8)且数组长度≥64 时,链表会转化为红黑树(提高查询效率,红黑树查询时间复杂度为 O (logn),链表为 O (n));若后续元素删除导致红黑树节点数少于 6,则会退化为链表。
put 方法的流程可分为以下步骤:1. 计算 key 的哈希值:通过 key 的 hashCode () 计算原始哈希值,再通过扰动函数((h = key.hashCode ()) ^ (h >>> 16))减少哈希冲突,将高 16 位与低 16 位异或,保留高位信息;2. 计算哈希桶索引:用扰动后的哈希值与数组长度减 1 进行与运算(index = (n - 1) & hash),得到数组索引;3. 处理哈希冲突:若索引位置为空,直接创建节点插入;若不为空,判断首个节点的 key 是否与当前 key 相同(equals 比较),相同则替换 value;不同则判断该位置是链表还是红黑树,链表则遍历节点,存在相同 key 则替换,否则尾插法添加节点,添加后若链表长度≥8 且数组长度≥64,转化为红黑树;红黑树则按红黑树规则插入;4. 扩容判断:插入后若元素数量(size)超过阈值(容量 × 负载因子,默认负载因子 0.75),则触发扩容,将数组长度翻倍(变为原长度的 2 倍),并重新计算所有节点的索引,迁移到新数组。
HashMap 的长度必须是 2 的指数,核心原因是确保哈希桶索引计算的均匀性。索引计算依赖 “(n - 1) & hash”,当 n 是 2 的指数时,n-1 的二进制表示为全 1(如 n=16 时,n-1=15 即 1111),与 hash 值进行与运算时,能保留 hash 值的低 k 位(k 为 n 的指数,如 16 是 2^4,保留低 4 位),确保索引在 [0, n-1] 范围内。若 n 不是 2 的指数,n-1 的二进制会有 0 位,导致某些索引永远无法被计算到(如 n=10 时,n-1=9 即 1001,与运算后结果的第 2、3 位永远为 0),加剧哈希冲突,降低效率。此外,扩容时(n 变为 2n),节点迁移可通过 “hash & oldCap” 判断是否需要移动(结果为 0 则索引不变,否则索引 = 原索引 + oldCap),简化迁移逻辑。
记忆法:存储结构用 “数链树”(数组、链表、红黑树)记忆;put 流程用 “哈希算索冲插扩”(哈希计算、索引计算、冲突处理、插入、扩容)串联;长度为 2 的指数原因记为 “与运算匀索引”(确保索引均匀分布)。
线程安全的 Map 有哪些?
在 Java 中,线程安全的 Map 实现类或工具类主要有以下几种,它们通过不同的同步机制保证多线程环境下的操作安全性:
Hashtable 是最早的线程安全 Map 实现,继承自 Dictionary 类,实现了 Map 接口。其线程安全通过在所有公共方法(如 put、get、remove 等)上添加 synchronized 关键字实现,即对整个 Hashtable 对象加锁。这导致多线程并发访问时,无论操作的是哪个键值对,都会竞争同一把锁,存在严重的锁竞争问题,效率较低,且不允许 key 或 value 为 null(否则抛出 NullPointerException)。
Collections.synchronizedMap () 是一个工具方法,可将非线程安全的 Map(如 HashMap)包装为线程安全的 Map。其内部通过一个同步代理类实现,代理类的所有方法都通过 synchronized 代码块对传入的 Map 对象加锁(锁对象可以指定,默认是被包装的 Map 本身)。与 Hashtable 类似,它也是对整个 Map 加锁,并发性能同样不高,但支持 key 或 value 为 null(取决于被包装的 Map,如包装 HashMap 时允许 null),且能适配各种 Map 实现(如 LinkedHashMap)。
ConcurrentHashMap 是并发性能更优的线程安全 Map,JDK1.7 和 JDK1.8 的实现机制不同。JDK1.7 中采用 “分段锁” 机制,将 Map 分为多个 Segment(每个 Segment 是一个小的哈希表),每个 Segment 独立加锁,多线程操作不同 Segment 时无需竞争锁,并发度为 Segment 的数量(默认 16);JDK1.8 中摒弃了分段锁,改用 “CAS+synchronized” 机制,对哈希桶中的首节点加锁,仅当多个线程操作同一哈希桶时才会竞争锁,进一步降低锁粒度,提升并发性能。此外,ConcurrentHashMap 支持并发的读操作(读无需加锁),且不允许 key 或 value 为 null,提供了更多原子操作(如 putIfAbsent、replace 等)。
ConcurrentSkipListMap 是基于跳表实现的有序线程安全 Map,实现了 NavigableMap 接口,支持按键的自然顺序或自定义比较器排序。其内部通过跳表的节点级锁(使用 CAS 操作)保证线程安全,并发性能较好,适用于需要有序遍历且并发访问的场景,查询、插入、删除的时间复杂度均为 O (logn)。
记忆法:线程安全的 Map 可通过 “哈同并跳”(Hashtable、synchronizedMap、ConcurrentHashMap、ConcurrentSkipListMap)谐音记忆,其中 “并” 突出 ConcurrentHashMap 的高并发特性,“跳” 对应跳表实现的 ConcurrentSkipListMap。
Android 四大组件了解吗?用自己的话介绍一下它们。
Android 四大组件是活动、服务、广播接收器、内容提供者,它们是 Android 应用的核心组成部分,各自承担不同角色,通过 Intent 进行通信,共同支撑应用的功能实现。
活动(Activity)是用户直接交互的界面载体,每个可见的屏幕界面通常对应一个 Activity。它有完整的生命周期,从创建(onCreate)、启动(onStart)、可见可交互(onResume),到暂停(onPause)、停止(onStop)、销毁(onDestroy),开发者可在不同生命周期方法中处理初始化(如加载布局、绑定数据)、资源释放等操作。一个应用通常包含多个 Activity,通过 Intent 跳转(如 startActivity (Intent)),例如微信的聊天界面、朋友圈界面分别对应不同的 Activity。
服务(Service)是运行在后台的组件,无用户界面,用于执行长时间运行的任务(如下载文件、播放音乐)。它分为两种启动方式:通过 startService 启动的服务,独立于启动它的组件运行,需调用 stopSelf 或 stopService 停止;通过 bindService 绑定的服务,与绑定的组件(如 Activity)生命周期关联,组件解绑后服务可能销毁。服务默认运行在主线程,若执行耗时操作需开启子线程,否则会导致 ANR(应用无响应),例如音乐应用在后台播放音乐时,就是通过 Service 实现的。
广播接收器(BroadcastReceiver)用于接收和响应系统或应用发出的广播消息,是一种跨组件通信的机制。广播的发送者(如系统在网络状态变化时)通过 sendBroadcast 发送 Intent,注册了对应广播的接收器会收到消息并在 onReceive 方法中处理。注册方式有两种:静态注册(在 AndroidManifest.xml 中声明,应用未启动也能接收)和动态注册(在代码中通过 registerReceiver 注册,需在组件销毁前 unregisterReceiver,否则内存泄漏)。例如,手机电量低时,系统发送低电量广播,应用的接收器可接收到并提醒用户。
内容提供者(ContentProvider)用于跨应用共享数据,封装了数据访问接口,屏蔽了底层数据存储方式(如数据库、文件)。它通过 Uri(统一资源标识符)标识数据,其他应用可通过 ContentResolver 调用 CRUD(增删改查)方法访问数据,无需知道数据的具体存储位置。例如,系统的联系人应用通过 ContentProvider 暴露联系人数据,其他应用可通过它读取或修改联系人(需申请权限)。
记忆法:四大组件可用 “活服广内”(活动、服务、广播接收器、内容提供者)谐音记忆,各自功能对应 “界面交互、后台任务、消息传递、数据共享”,便于联想其核心作用。
Activity 的四种启动模式是什么?各自的应用场景有哪些?
Activity 的启动模式由 AndroidManifest.xml 中 activity 标签的 launchMode 属性或 Intent 中的标志(如 FLAG_ACTIVITY_NEW_TASK)指定,共四种,每种模式对应不同的任务栈管理规则:
standard(标准模式)是默认启动模式,每次启动 Activity 都会创建新实例并放入当前任务栈。无论任务栈中是否已有该 Activity 的实例,都会重复创建。这种模式下,谁启动了该 Activity,该实例就归属于谁的任务栈。例如,在 Activity A 中启动 Activity B(standard 模式),B 会被压入 A 所在的任务栈,位于 A 上方。其应用场景是大多数普通页面,如列表项点击打开的详情页,每次点击都需要新的页面实例展示不同内容。
singleTop(栈顶复用模式)启动时,若当前任务栈的栈顶已存在该 Activity 的实例,则不会创建新实例,而是调用其 onNewIntent 方法复用该实例;若栈顶不存在,则创建新实例并压入栈顶。例如,在浏览器的搜索页面,如果用户连续点击搜索按钮,使用 singleTop 可避免栈顶重复出现多个搜索页,节省内存。常见应用场景包括通知栏点击打开的页面(避免重复打开)、即时通讯的聊天页面(防止同一聊天窗口在栈顶重复创建)。
singleTask(栈内唯一模式)启动时,系统会先检查是否存在该 Activity 所属的任务栈:若不存在,则创建新任务栈并将新实例放入;若存在,且栈中已有该 Activity 的实例,则将该实例上方的所有 Activity 出栈(销毁),使该实例成为栈顶并调用其 onNewIntent 方法;若栈中不存在,则创建新实例放入该任务栈。这种模式确保整个任务栈中只有一个该 Activity 的实例。应用场景如应用的主页面(如微信首页),用户从其他页面返回首页时,无需重新创建,且会清除首页上方的所有页面,保证首页在栈底的唯一性;又如浏览器的主页,无论从哪个页面跳转回来,都只保留一个主页实例。
singleInstance(单实例模式)是一种特殊的 singleTask,其所在的任务栈中只能有这一个 Activity 实例,不允许其他 Activity 存在。当启动该 Activity 时,系统会为其创建新的任务栈,且整个系统中只有这一个实例。例如,系统的来电界面,无论从哪个应用启动,都只会有一个来电界面实例,且其任务栈独立,避免被其他页面干扰。此外,类似闹钟提醒页面、系统设置中的某些独立功能页面也可能使用这种模式。
记忆法:可通过“场景-行为”联想记忆,standard 对应“每次新建,普通场景”;singleTop 对应“栈顶不重复,通知/聊天页”;singleTask 对应“栈内唯一,主页面”;singleInstance 对应“全局唯一,独立任务,如来电”。
Activity 的生命周期是怎样的?
Activity 的生命周期是指从创建到销毁的整个过程,由系统根据用户操作和环境变化自动调用相关方法,主要包括以下方法,按执行顺序可分为完整生命周期、可见生命周期和前台生命周期:
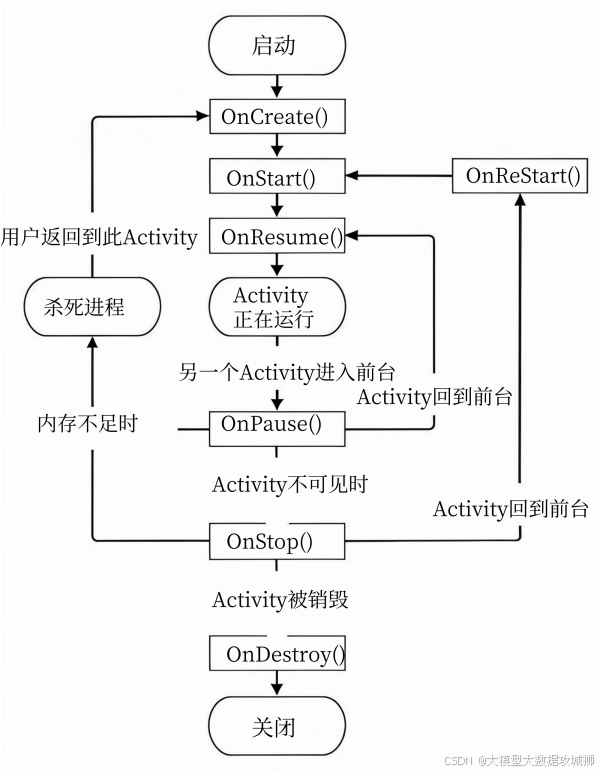
完整生命周期从 onCreate 开始,到 onDestroy 结束。onCreate 是 Activity 首次创建时调用,用于初始化操作,如设置布局(setContentView)、绑定控件、初始化数据等,此时 Activity 还未可见。例如,在 onCreate 中通过 findViewById 获取按钮并设置点击事件。
可见生命周期从 onStart 开始,到 onStop 结束。onStart 被调用时,Activity 进入可见状态,但尚未与用户交互(处于后台),此时用户可以看到界面但无法操作。随后调用 onResume,Activity 进入前台,变为可交互状态,用户可以点击按钮、输入文本等,此时 Activity 处于运行状态。
前台生命周期从 onResume 开始,到 onPause 结束。当其他 Activity 被启动、屏幕熄灭或应用被切换到后台时,当前 Activity 会调用 onPause,此时它失去焦点但仍部分可见(如被对话框遮挡时),应在此方法中暂停耗时操作(如动画、视频播放),保存临时数据。
当 Activity 完全不可见时(如被新的 Activity 完全覆盖),会调用 onStop,此时可释放不再需要的资源(如停止网络请求、注销广播),但需注意若 Activity 只是暂时不可见(如跳转到透明 Activity),可能不会执行 onStop。
当 Activity 即将被销毁时,调用 onDestroy,用于最终的资源释放,如解除绑定、关闭数据库连接等,此时 Activity 生命周期结束。
此外,当 Activity 从停止状态重新回到前台时,会先调用 onRestart(重新启动),再依次执行 onStart、onResume。例如,用户按下 Home 键将应用切到后台(执行 onPause→onStop),再点击应用图标返回,会执行 onRestart→onStart→onResume。
异常情况下(如屏幕旋转、内存不足被系统回收),Activity 会经历 onSaveInstanceState(保存状态,如输入框内容、列表滚动位置)和 onRestoreInstanceState(恢复状态),这两个方法分别在 onPause 之后和 onStart 之后调用,确保用户数据不丢失。
记忆法:可通过“状态变化流程”口诀记忆:“创建(onCreate)初始化,启动(onStart)见界面,恢复(onResume)可交互,暂停(onPause)失焦点,停止(onStop)全隐藏,销毁(onDestroy)清资源,重启(onRestart)再可见”。
启动活动 A 后,在 A 中启动活动 B,两者的生命周期会发生怎样的变化?如果 B 是透明的呢?此时再启动第三个活动 C,三个活动的生命周期又会如何变化?
启动活动 A 后,A 的生命周期会依次执行 onCreate→onStart→onResume,进入运行状态。
在 A 中启动活动 B(非透明)时,生命周期变化如下:首先 A 失去焦点,执行 onPause(此时 A 仍部分可见);接着 B 被创建,依次执行 B 的 onCreate→onStart→onResume(B 进入运行状态);最后 A 因被 B 完全覆盖而完全不可见,执行 onStop。此时栈中顺序为 A→B,B 在栈顶。
若 B 是透明的(如主题设置为 Theme.Translucent),启动 B 时,A 虽然被 B 覆盖,但由于 B 透明,A 仍部分可见(用户可透过 B 看到 A 的部分界面)。因此,A 只会执行 onPause(失去焦点),不会执行 onStop;B 则正常执行 onCreate→onStart→onResume。此时 A 处于暂停状态,B 处于运行状态,栈中顺序仍为 A→B。
在 B 是透明的情况下,从 B 启动第三个活动 C(非透明)时:首先 B 失去焦点,执行 onPause;接着 C 被创建,依次执行 C 的 onCreate→onStart→onResume(C 进入运行状态);由于 C 非透明,会完全覆盖 B,B 因完全不可见而执行 onStop;A 此时仍处于暂停状态(因 B 之前未让 A 执行 onStop,且 C 不直接影响 A)。此时栈中顺序为 A→B→C,C 在栈顶,A 暂停,B 停止,C 运行。
若 C 也是透明的,启动 C 时,B 执行 onPause(不执行 onStop,因 C 透明,B 仍部分可见),C 执行 onCreate→onStart→onResume,A 仍处于暂停状态。
整个过程的核心逻辑是:Activity 是否执行 onStop 取决于是否完全不可见,非透明 Activity 会导致前一个 Activity 完全不可见(执行 onStop),透明 Activity 则不会(仅执行 onPause)。
记忆法:用“可见性决定生命周期”原则记忆,完全不可见触发 onStop,部分可见仅触发 onPause,按栈顺序依次影响上层 Activity。
Fragment 的生命周期了解吗?
Fragment 的生命周期与 Activity 类似,但更复杂,因其依赖于所属 Activity 的生命周期,同时包含自身特有的布局创建和销毁过程,主要方法及触发时机如下:
关联阶段:当 Fragment 与 Activity 建立关联时,首先调用 onAttach(Context context),参数为所属 Activity,可在此获取 Activity 实例或传递数据,若 Fragment 与 Activity 解绑,后续方法不会再执行。
创建阶段:onCreate 在 onAttach 之后调用,用于初始化 Fragment 的非视图数据(如加载网络配置、初始化变量),此时还未涉及布局。接着是 onCreatedView,用于创建 Fragment 的布局视图,返回一个 View 对象(如通过 LayoutInflater 加载布局),是 Fragment 与界面关联的关键步骤,若返回 null 则表示无布局。之后调用 onActivityCreated,此时所属 Activity 的 onCreate 已执行完毕,可在此进行与 Activity 相关的 UI 操作(如获取 Activity 中的控件)。
运行阶段:与 Activity 同步,当 Activity 执行 onStart 时,Fragment 也执行 onStart(进入可见状态);Activity 执行 onResume 时,Fragment 执行 onResume(进入可交互状态)。
暂停与停止阶段:Activity 执行 onPause 时,Fragment 执行 onPause(失去焦点);Activity 执行 onStop 时,Fragment 执行 onStop(完全不可见)。
销毁阶段:首先是 onDestroyView,销毁 Fragment 创建的视图(释放布局资源,如解绑 View 监听),但 Fragment 实例仍存在。接着是 onDestroy,销毁 Fragment 自身的非视图资源(如关闭数据库连接)。最后是 onDetach,与 Activity 解除关联,Fragment 生命周期结束。
Fragment 的生命周期受 Activity 影响:若 Activity 暂停,所有依赖它的 Fragment 也会暂停;若 Activity 销毁,所有 Fragment 也会被销毁。但 Fragment 也可独立管理部分状态,例如在 ViewPager 中, Fragment 可能在不可见时仅执行 onPause/onStop,而非立即销毁。
此外,Fragment 还有一些回调方法,如 setUserVisibleHint(用于 ViewPager 中判断 Fragment 是否可见)、onSaveInstanceState(保存状态)等,用于处理特殊场景。
记忆法:按“关联-创建-运行-销毁”四阶段划分记忆,关联阶段(onAttach)、创建阶段(onCreate→onCreateView→onActivityCreated)、运行阶段(onStart→onResume)、销毁阶段(onPause→onStop→onDestroyView→onDestroy→onDetach),每个阶段对应具体的资源操作。
广播注册有哪些方式?
广播注册是 Android 中接收系统或应用内事件通知的方式,主要分为静态注册和动态注册两种,两者在注册时机、生命周期、适用场景等方面有显著区别:
静态注册是在 AndroidManifest.xml 中声明广播接收器(BroadcastReceiver),无需代码注册,具体方式是在清单文件中添加 <receiver> 标签,指定接收器类名和 intent-filter(过滤需要接收的广播动作)。例如,注册一个接收开机完成广播的接收器:
<receiver android:name=".BootCompleteReceiver" android:enabled="true" android:exported="true">
<intent-filter>
<action android:name="android.intent.action.BOOT_COMPLETED" /></receiver>静态注册的特点是:应用未启动时也能接收广播(系统会唤醒应用进程),但自 Android 3.1 起,系统对静态注册的广播添加了限制,若应用从未启动过,可能无法接收广播;注册后一直有效,直到应用被卸载;灵活性低,无法动态修改接收的广播类型。适用场景包括接收开机启动广播(初始化应用配置)、时区变化广播(更新时间显示)等需要在应用未运行时响应的事件。
动态注册是在代码中通过 Context 的 registerReceiver 方法注册,需在合适的时机(如 Activity 的 onStart)注册,在不需要时(如 Activity 的 onStop)通过 unregisterReceiver 取消注册。例如,在 Activity 中注册网络状态变化广播:
private NetworkChangeReceiver receiver;
@Override
protected void onStart() {
super.onStart();
IntentFilter filter = new IntentFilter();
filter.addAction("android.net.conn.CONNECTIVITY_CHANGE");
receiver = new NetworkChangeReceiver();
registerReceiver(receiver, filter);
}@Override
protected void onStop() {
super.onStop();
unregisterReceiver(receiver);
}动态注册的特点是:仅在注册后到取消注册前有效,受组件生命周期影响(如 Activity 销毁后需取消注册,否则会内存泄漏);灵活性高,可根据业务需求动态添加或移除 intent-filter;应用退出后(如进程被杀)无法接收广播。适用场景包括页面内的临时事件响应(如监听用户登录状态变化、实时更新数据)、需要根据用户操作动态开关的广播(如在设置页面开启/关闭消息通知)。
此外,两种注册方式都可能需要声明权限(如接收开机广播需声明 RECEIVE_BOOT_COMPLETED 权限),且动态注册的优先级高于静态注册(同一广播会先被动态注册的接收器接收)。
记忆法:通过“注册位置+生命周期”区分,静态注册“写在清单,常驻有效,未启动可接收”;动态注册“写在代码,随组件生灭,灵活可控”,简记为“静在清单,动在代码”。
事件分发机制是怎样的?
事件分发机制是Android中处理用户输入事件(如点击、滑动、触摸等)的核心流程,涉及三个关键方法:dispatchTouchEvent、onInterceptTouchEvent和onTouchEvent,这些方法在Activity、ViewGroup和View之间协作,决定事件最终由哪个组件处理。
从传递流程来看,事件首先到达Activity的dispatchTouchEvent方法,随后被传递给Activity内部的顶层ViewGroup。ViewGroup会先调用自身的dispatchTouchEvent方法,在此方法中,会判断是否需要拦截事件:若调用onInterceptTouchEvent返回true,则表示拦截事件,事件会直接交给ViewGroup的onTouchEvent处理;若返回false,则事件会继续向下传递给子View。子View收到事件后,同样通过自身的dispatchTouchEvent方法处理,若子View没有子节点,则直接调用其onTouchEvent方法。
如果某个组件的onTouchEvent返回true,说明该组件消费了事件,事件传递终止;若返回false,事件会向上回传,由父组件的onTouchEvent处理,直到Activity的onTouchEvent,若最终都未消费,事件则被丢弃。
需要注意的是,ViewGroup默认不拦截事件(onInterceptTouchEvent返回false),但可通过重写该方法改变行为,例如滑动控件(如ScrollView)会在特定情况下拦截事件以实现滑动逻辑。此外,View没有onInterceptTouchEvent方法,因为它是事件传递的最底层,无需拦截。
代码示例上,若自定义一个ViewGroup拦截事件:
public class MyViewGroup extends ViewGroup {@Overridepublic boolean dispatchTouchEvent(MotionEvent ev) {// 事件分发入口return super.dispatchTouchEvent(ev);}@Overridepublic boolean onInterceptTouchEvent(MotionEvent ev) {// 拦截事件,返回true表示拦截return true;}@Overridepublic boolean onTouchEvent(MotionEvent event) {// 处理拦截后的事件return true;}
}
记忆法可采用“三层传递+三方法”联想:将事件分发想象成“上级(Activity)→ 中层(ViewGroup)→ 下级(View)”的传递链,每层对应“分发(dispatch)→ 拦截(intercept)→ 处理(touchEvent)”三个动作,拦截则中断传递,处理则终止流程,以此记住核心逻辑。
AMS(Activity Manager Service)是什么?
AMS即活动管理器服务,是Android系统中非常核心的系统服务之一,运行在SystemServer进程中,主要负责管理Activity的生命周期、任务栈、应用进程以及权限验证等关键工作,是连接应用层与系统层的重要枢纽。
从具体功能来看,AMS的核心职责包括:首先,管理Activity的生命周期,所有Activity的启动、暂停、停止、销毁等状态切换都需要通过AMS协调,例如启动一个Activity时,应用会通过Binder向AMS发送请求,AMS会检查权限、调整任务栈,再通知应用进程执行相应的生命周期方法。其次,管理任务栈(Task Stack)和返回栈(Back Stack),AMS会按照用户操作将Activity组织到不同的任务栈中,确保应用切换和返回行为符合用户预期,例如长按Home键显示的最近任务列表就是由AMS维护的。
此外,AMS还负责应用进程的管理,当系统内存不足时,AMS会根据进程优先级(如前台进程、可见进程、服务进程等)决定终止哪些进程以释放资源;同时,它还会处理应用的启动请求,若目标进程未启动,会通过Zygote进程孵化新进程。另外,AMS还参与权限检查,当应用请求敏感操作时,AMS会验证其是否拥有相应权限。
AMS通过Binder机制与应用进程通信,应用进程中的ActivityManagerProxy是AMS的客户端代理,负责发送请求;而AMS内部通过ActivityStack等类管理Activity状态,通过ProcessRecord记录进程信息,形成了一套完整的管理体系。
记忆法可采用“大管家”类比:将AMS想象成Android系统的“活动大管家”,负责“管生命周期(Activity状态)、管任务(任务栈)、管进程(进程启停)、管权限(权限检查)”,以此串联其核心功能。
Handler机制是怎样的?
Handler机制是Android中用于解决线程间通信的核心机制,主要由Handler、Looper、MessageQueue和Message四个部分组成,用于实现子线程与主线程(UI线程)之间的消息传递,例如子线程执行耗时操作后通知主线程更新UI。
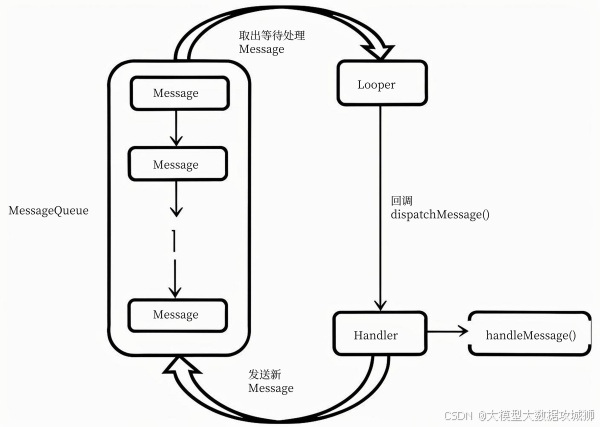
其工作原理如下:首先,Looper是每个线程的消息循环器,主线程默认会初始化Looper(通过ActivityThread的main方法),而子线程需要手动调用Looper.prepare()创建Looper,并通过Looper.loop()启动消息循环。Looper内部持有一个MessageQueue(消息队列),用于存储待处理的Message。
Handler负责发送和处理消息:发送消息时,Handler通过sendMessage()等方法将Message添加到MessageQueue中;处理消息时,Looper不断从MessageQueue中取出Message(通过loop()方法循环),并回调Message对应的Handler的handleMessage()方法。
具体流程为:1. 线程初始化Looper,创建MessageQueue;2. Handler在当前线程创建(与Looper绑定);3. 其他线程通过Handler发送Message(包含数据或任务);4. Message被加入MessageQueue;5. Looper循环取出Message,交给Handler处理。
需要注意的是,Handler必须与Looper绑定,而一个Looper对应一个线程和一个MessageQueue,因此Handler可以实现跨线程通信。例如,主线程的Handler在子线程中发送消息,消息会被加入主线程的MessageQueue,最终在主线程处理,避免UI操作在子线程执行导致的异常。
代码示例:
// 主线程创建Handler
private Handler mHandler = new Handler(Looper.getMainLooper()) {@Overridepublic void handleMessage(Message msg) {// 处理消息,更新UItextView.setText("收到消息:" + msg.obj);}
};// 子线程发送消息
new Thread(new Runnable() {@Overridepublic void run() {// 执行耗时操作String result = "耗时操作结果";Message msg = Message.obtain();msg.obj = result;mHandler.sendMessage(msg); // 发送到主线程处理}
}).start();
记忆法可采用“邮递系统”类比:Looper是“邮递员”,负责循环分发消息;MessageQueue是“邮局”,存储消息;Message是“信件”,包含内容;Handler是“发件人和收件人”,负责发送和处理信件,以此理解四者的协作关系。
项目中用到了Handler,说下Handler的原理是什么?
在项目中,Handler常用于实现线程间通信,例如子线程执行网络请求或数据库操作后,通过Handler通知主线程更新UI;也用于执行延迟任务(如sendEmptyMessageDelayed)或定时任务(如postDelayed)。其原理核心是通过Handler、Looper、MessageQueue和Message的协同,实现消息的发送、存储和处理。
从原理细节来看,首先,每个线程可以关联一个Looper(通过ThreadLocal存储),Looper的作用是不断从其持有的MessageQueue中取出消息并处理。主线程(UI线程)在启动时会自动初始化Looper(通过ActivityThread的main方法调用Looper.prepareMainLooper()和Looper.loop()),因此主线程默认支持Handler机制;而子线程若需使用Handler,需手动调用Looper.prepare()创建Looper,再调用Looper.loop()启动循环。
Handler在创建时会绑定当前线程的Looper(若未指定则绑定当前线程的Looper),并通过该Looper获取MessageQueue。当调用Handler的sendMessage()、post()等方法时,会将Message(或Runnable封装成Message)添加到MessageQueue中。MessageQueue是一个基于时间优先级的单向链表,Looper的loop()方法会不断循环调用MessageQueue的next()方法取出消息,然后调用Message的target(即发送该消息的Handler)的dispatchMessage()方法,最终回调Handler的handleMessage()方法(或Runnable的run()方法)。
这种机制确保了消息处理在Looper所在的线程执行,因此若Handler绑定主线程的Looper,消息就会在主线程处理,从而安全更新UI。例如项目中网络请求成功后,子线程通过Handler将结果发送到主线程,避免了UI操作在子线程的异常。
记忆法可采用“线程桥梁”模型:Handler是连接不同线程的“桥梁”,Looper是“桥梁的动力系统”(循环处理),MessageQueue是“桥梁上的传送带”(存储消息),Message是“传送的货物”,以此记住各部分的作用和协作关系。
Handler的内存泄露了解吗?如何避免?
Handler的内存泄露是Android开发中常见的问题,主要源于Handler与Activity(或其他组件)的生命周期不匹配,导致Activity无法被垃圾回收。
具体原因在于:在Activity中创建的Handler通常是匿名内部类或非静态内部类,这类内部类会隐式持有外部Activity的引用。当Handler发送延迟消息(如postDelayed)时,消息会被添加到MessageQueue中,而Message会持有Handler的引用(通过target字段)。此时若Activity因用户操作被销毁(如按返回键),但延迟消息尚未处理,Message→Handler→Activity的引用链就会一直存在,导致Activity无法被回收,从而产生内存泄露。
例如以下代码就存在内存泄露风险:
public class MainActivity extends AppCompatActivity {// 非静态内部类,持有MainActivity引用private Handler mHandler = new Handler() {@Overridepublic void handleMessage(Message msg) {// 处理消息}};@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);// 发送延迟消息,10分钟后处理mHandler.postDelayed(new Runnable() {@Overridepublic void run() {// 执行任务}}, 600000);}
}
当Activity被销毁后,延迟消息仍在队列中,导致Activity被持续引用,无法回收。
避免Handler内存泄露的核心是切断Handler对Activity的强引用,主要有两种方法:
使用静态内部类+弱引用:将Handler定义为静态内部类,静态内部类不会持有外部类的引用;同时在Handler中通过弱引用(WeakReference)持有Activity,既可以访问Activity的资源,又不会阻止其被回收。
在Activity销毁时移除未处理的消息:在Activity的onDestroy方法中,调用Handler的removeCallbacksAndMessages(null),移除所有未处理的消息和回调,切断Message→Handler→Activity的引用链。
改进后的代码如下:
public class MainActivity extends AppCompatActivity {// 静态内部类,不持有外部类引用private static class MyHandler extends Handler {// 弱引用持有Activityprivate WeakReference<MainActivity> mActivityRef;public MyHandler(MainActivity activity) {mActivityRef = new WeakReference<>(activity);}@Overridepublic void handleMessage(Message msg) {MainActivity activity = mActivityRef.get();if (activity != null) {// 安全访问Activity资源}}}private MyHandler mHandler;@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);mHandler = new MyHandler(this);mHandler.postDelayed(new Runnable() {@Overridepublic void run() {// 执行任务}}, 600000);}@Overrideprotected void onDestroy() {super.onDestroy();// 移除所有未处理的消息和回调mHandler.removeCallbacksAndMessages(null);}
}
记忆法可采用“两步骤”口诀:“静态类加弱引用,销毁时清消息”,通过简洁的口诀记住避免内存泄露的核心操作。
知道消息是怎么插入到消息队列的吗?
消息插入到消息队列(MessageQueue)的过程由Handler发送消息触发,核心是通过MessageQueue的enqueueMessage方法完成,涉及消息封装、时间排序和队列维护等步骤,具体流程如下:
首先,Handler发送消息的各种方法(如sendMessage、post、sendEmptyMessage等)最终都会调用enqueueMessage方法。以sendMessage为例,该方法会将消息(Message)的target字段设置为当前Handler(确保消息处理时能回调正确的Handler),并计算消息的触发时间when(若为即时消息,when为当前时间;若为延迟消息,when为当前时间+延迟时间)。
接着,MessageQueue的enqueueMessage方法被调用,该方法的核心是将消息按when时间顺序插入到队列中。MessageQueue内部维护的是一个单向链表结构的消息队列,每个Message通过next字段指向后续消息。插入时,会从队列头部开始遍历,找到第一个when时间大于当前消息when的节点,将当前消息插入到该节点之前;若所有消息的when都小于当前消息,则插入到队列尾部。这种按时间排序的方式确保Looper能按顺序处理消息。
此外,插入过程中还需处理同步屏障(SyncBarrier)。同步屏障是一种特殊消息(what字段为-1,target为null),用于阻塞同步消息(有target的消息),优先处理异步消息(设置了async为true的消息)。当队列中存在同步屏障时,enqueueMessage会将异步消息插入到屏障之后,确保其优先被处理。
插入完成后,若消息是队列中的第一个消息,或插入的消息比当前正在处理的消息更早,会唤醒阻塞在MessageQueue.next()方法中的Looper(通过nativePollOnce唤醒),使其及时处理新插入的消息。
例如,当调用handler.postDelayed(runnable, 1000)时,Runnable会被封装成Message,when设为当前时间+1000ms,enqueueMessage会将其插入到队列中合适的位置,等待1秒后被Looper取出处理。
记忆法:可通过“封装→计时→排序→入队”四步记忆,消息先被Handler封装并设置时间,再由MessageQueue按时间顺序插入队列,核心是“按when排序,确保顺序执行”。
view.post 的原理是什么?为什么它会插入到消息队列的尾部?
view.post 的原理是通过View内部关联的Handler将任务(Runnable)发送到消息队列,最终在主线程执行,其核心是利用View的AttachInfo获取主线程Handler,实现UI线程的任务调度。
具体来说,View的post方法内部会先检查是否已关联到窗口(即mAttachInfo是否为null)。mAttachInfo是View被添加到Window时由ViewRootImpl设置的,包含了主线程的Handler(mHandler)等信息。若mAttachInfo不为null(View已附加到窗口),则直接调用mHandler.post(runnable),将Runnable封装成Message插入到主线程的消息队列;若mAttachInfo为null(View尚未附加到窗口),则将Runnable添加到View的内部队列(mRunQueue),待View附加到窗口时(触发onAttachedToWindow),再将队列中的任务通过mHandler发送到消息队列。
这一过程确保了无论View是否已显示,post的任务最终都会在主线程执行,避免了在子线程操作View的问题。例如,在Activity的onCreate中调用view.post(runnable),此时View尚未附加到窗口,任务会被暂存,待View显示后再执行,保证runnable中的UI操作(如获取View宽高)能正确执行。
view.post 的任务会插入到消息队列尾部,原因是其封装的Message的when字段被设置为0。MessageQueue插入消息时,会按when时间排序,when为0的消息会被视为“立即执行”,但会排在所有已有消息之后(因为已有消息的when通常大于等于当前时间)。此外,Looper处理消息时按顺序取出,因此尾部的消息会在前面的消息处理完成后才执行,这使得view.post的任务不会打断当前正在处理的消息,保证了消息队列的顺序性。
例如,若消息队列中已有两个消息(when分别为100ms和200ms),此时view.post的消息when为0,插入后会排在这两个消息之后,Looper会先处理100ms和200ms的消息,再处理view.post的任务。
记忆法:用“View借Handler,任务排队走”记忆,View通过AttachInfo获取主线程Handler,任务因when为0被排在队列尾部,遵循“先来后到”的顺序。
view.post 和 handler.post 的区别是什么?
view.post 和 handler.post 都用于在主线程执行任务,但两者在实现原理、依赖条件、使用场景等方面存在显著区别,具体如下:
从实现原理来看,view.post 内部依赖View的AttachInfo获取主线程Handler(即ViewRootImpl的mHandler),将Runnable封装成Message发送到消息队列;若View尚未附加到窗口(mAttachInfo为null),任务会暂存到View的内部队列,待View附加到窗口后再发送。而 handler.post 直接使用创建Handler时绑定的Looper对应的Handler(若未指定,默认绑定当前线程的Looper,主线程Handler绑定主线程Looper),直接将Runnable封装成Message发送到对应的消息队列,不依赖View的状态。
在依赖条件方面,view.post 依赖View被正确附加到窗口(即完成onAttachedToWindow),否则任务可能延迟执行(暂存到内部队列)或在某些极端情况下不执行(如View从未被添加到窗口)。例如,在Activity的onCreate中调用view.post,此时View尚未附加到窗口,任务会暂存,直到View显示后才执行。而 handler.post 仅依赖Handler绑定的Looper是否正常运行(主线程Looper默认运行),只要Handler有效,任务就能被发送到消息队列,与View状态无关。
在任务执行时机上,view.post 的任务若在View附加后发送,与 handler.post(主线程Handler)的任务一样,都会按消息队列顺序执行;但若View未附加,任务会延迟到View附加后,可能晚于 handler.post 的任务。此外,view.post 可以获取到View的最新状态(如宽高已测量),因为其任务执行时View通常已完成布局;而 handler.post 在早期生命周期(如onCreate)中执行时,可能无法获取View的宽高(尚未测量)。
使用场景上,view.post 适合需要在View准备就绪后执行的任务(如获取View宽高、更新View属性),确保操作时View已附加到窗口。handler.post 更通用,适合任何需要在主线程执行的任务(如延迟操作、子线程回调更新UI),尤其适用于不涉及View的场景(如数据处理后更新UI)。
代码示例对比:
// view.post:适合依赖View状态的操作
textView.post(new Runnable() {@Overridepublic void run() {int width = textView.getWidth(); // 能正确获取宽度}
});// handler.post:通用主线程任务
new Handler(Looper.getMainLooper()).post(new Runnable() {@Overridepublic void run() {updateUI(); // 不依赖View状态的UI更新}
});
记忆法:通过“依赖对象+适用场景”区分,view.post“依赖View,管View就绪后任务”;handler.post“依赖Looper,管通用主线程任务”,简记为“View靠绑定,Handler靠线程”。
Android 应用的启动流程是怎样的?
Android应用的启动流程是一个涉及多个系统进程和组件协作的过程,从用户点击桌面图标到应用首页显示,主要包括以下步骤:
首先,用户在Launcher(桌面应用)点击应用图标,Launcher进程通过Binder向系统服务AMS(Activity Manager Service)发送启动请求(startActivity)。AMS运行在SystemServer进程中,负责管理Activity生命周期和任务栈。
AMS收到请求后,会进行一系列校验:检查应用是否已安装、启动权限是否足够、目标Activity是否在Manifest中声明等。校验通过后,AMS会判断目标应用进程是否已存在:若进程已存在,直接通知该进程启动Activity;若进程不存在,则需要创建新进程。
创建新进程时,AMS通过Socket向Zygote进程发送请求。Zygote是Android系统的根进程,负责孵化新应用进程,其内部预加载了常用类和资源,能快速创建进程。Zygote收到请求后,通过fork()系统调用创建新进程(应用进程),新进程会继承Zygote的资源,同时初始化自己的虚拟机和运行时环境。
新应用进程启动后,会创建ActivityThread实例(应用的主线程管理器),并调用其main方法。在main方法中,会初始化主线程的Looper(消息循环),创建Application对象,并通过AMS的attachApplication方法将应用进程与AMS绑定。
AMS绑定应用进程后,会将启动Activity的信息(如Activity组件名、Intent等)通过Binder传递给应用进程的ActivityThread。ActivityThread收到信息后,通过Handler(H类)将启动请求发送到主线程消息队列,触发Activity的创建流程。
接下来,ActivityThread会创建Activity实例,依次执行其onCreate→onStart→onResume生命周期方法:在onCreate中加载布局(setContentView),通过LayoutInflater解析XML布局文件为View树,由ViewRootImpl负责将View树绘制到屏幕上。当onResume执行完成后,应用首页可见并可交互,启动流程结束。
整个过程涉及多个进程间通信(Launcher→AMS→Zygote→应用进程),核心是AMS的协调和ActivityThread对组件生命周期的管理。例如,冷启动(首次启动)会经历完整的进程创建流程,而热启动(进程已存在)则跳过进程创建步骤,直接启动Activity,速度更快。
记忆法:可通过“用户点→Launcher传→AMS判→Zygote孵→进程启→Activity显”的流程口诀记忆,串联从用户操作到界面显示的关键步骤。
TCP 的三次握手是怎样的?为什么 TCP 是可靠的?什么是滑动窗口协议?
TCP的三次握手是建立连接的过程,通过客户端与服务器的三次报文交互确认双方的发送和接收能力,具体步骤如下:
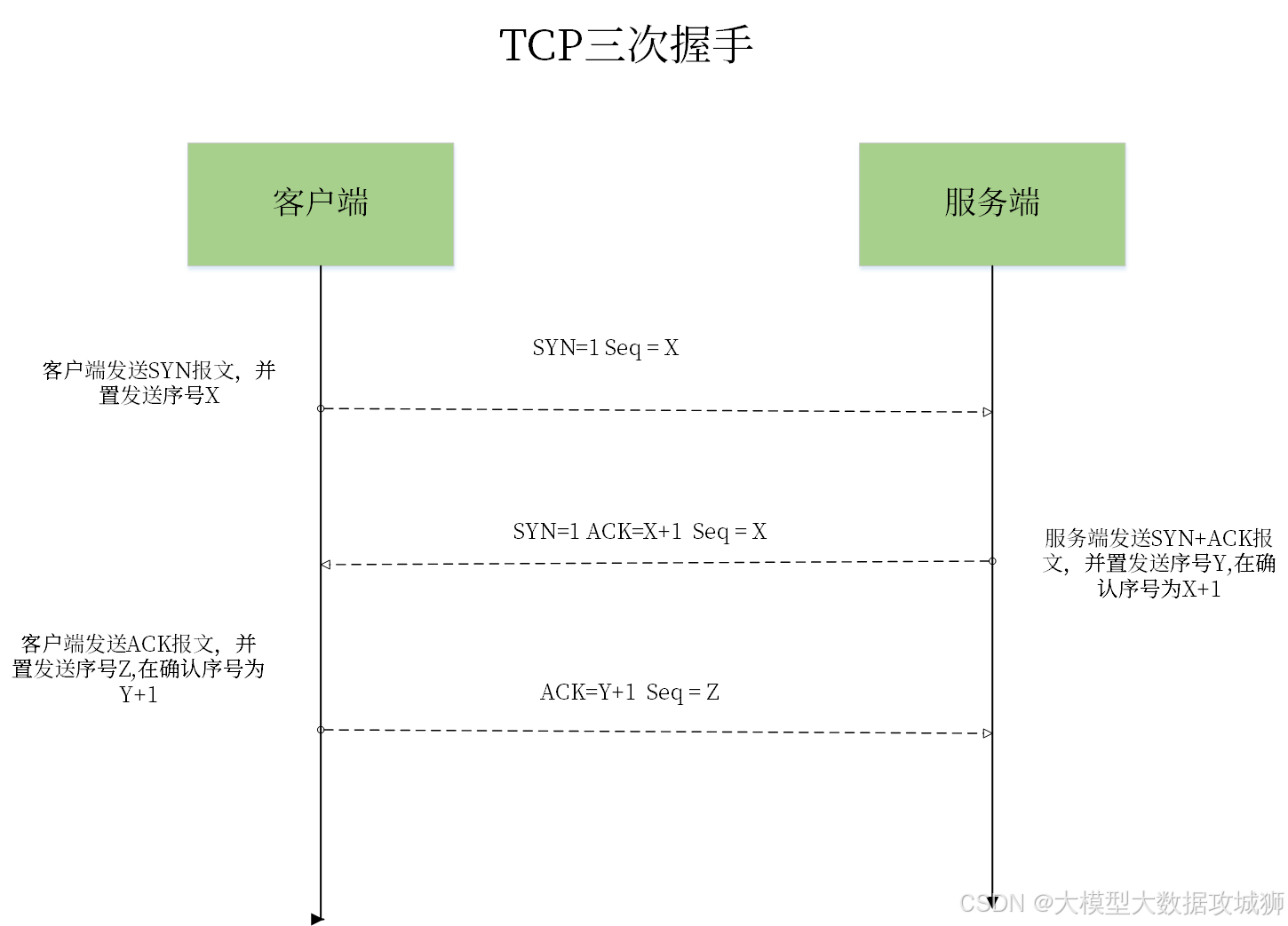
第一次握手:客户端主动打开连接,向服务器发送SYN报文(同步序列编号),报文包含客户端的初始序列号(ISNc),此时客户端进入SYN_SENT状态,等待服务器确认。
第二次握手:服务器收到SYN报文后,确认客户端的发送能力,回复SYN+ACK报文。该报文包含服务器的初始序列号(ISNs)和对客户端ISNc的确认号(ISNc+1),表示已收到客户端的SYN,此时服务器进入SYN_RCVD状态。
第三次握手:客户端收到SYN+ACK报文后,确认服务器的接收和发送能力,回复ACK报文,包含对服务器ISNs的确认号(ISNs+1),此时客户端进入ESTABLISHED状态;服务器收到ACK后,也进入ESTABLISHED状态,连接建立完成。
TCP被称为可靠传输,原因在于其采用了多种机制保证数据完整、有序到达:1. 确认机制:接收方收到数据后会发送ACK确认,发送方未收到确认则重传;2. 序列号与确认号:每个数据包都有序列号,接收方可按序号重组数据,确保顺序正确;3. 重传机制:发送方设置超时计时器,超时未收到确认则重传数据;4. 校验和:每个报文包含校验和,接收方通过校验检测数据是否损坏;5. 流量控制:通过滑动窗口限制发送方速率,避免接收方缓冲区溢出;6. 拥塞控制:通过慢启动、拥塞避免等算法调整发送速率,避免网络拥塞。
滑动窗口协议是TCP实现流量控制和高效传输的核心机制,分为发送窗口和接收窗口:接收方根据自身缓冲区大小设置接收窗口(rwnd),并通过ACK报文告知发送方;发送方的发送窗口大小取接收窗口和拥塞窗口(cwnd,反映网络拥塞状态)的最小值,确保发送的数据量不超过接收方的处理能力。窗口内的数据可连续发送,无需等待每个数据包的确认,只需等待窗口内最后一个数据包的确认,即可滑动窗口继续发送后续数据,大幅提高了传输效率。例如,接收窗口为3时,发送方可连续发送3个数据包,收到确认后窗口滑动,再发送接下来的3个数据包。
记忆法:三次握手记为“客发SYN→服回SYN+ACK→客回ACK”;TCP可靠机制记“确序重校控”(确认、序号、重传、校验、控制);滑动窗口记为“接收定窗口,发送限速率,连续传数据”。
HTTPS 的安全传输原理是怎样的?
HTTPS(超文本传输安全协议)通过在 HTTP 基础上加入 SSL/TLS(传输层安全层)加密协议,实现数据传输的机密性、完整性和身份认证,其安全传输原理核心是 “非对称加密交换密钥 + 对称加密传输数据 + 证书验证身份”,具体流程如下:
首先,客户端握手阶段(建立安全连接):客户端向服务器发起 HTTPS 请求,明确支持的 TLS 版本和加密套件(如 RSA、ECDHE 等);服务器收到请求后,选择合适的加密套件,并向客户端发送数字证书(包含服务器公钥、证书颁发机构 CA 信息、证书有效期等)。
接着,客户端验证证书合法性:客户端会检查证书的颁发机构是否可信(操作系统或浏览器内置可信 CA 列表)、证书是否在有效期内、证书中的服务器域名是否与请求域名一致等。若验证失败,客户端会提示风险;若验证通过,客户端从证书中提取服务器公钥。
然后,交换对称密钥:客户端采用对称加密效率高但密钥传输不安全,非对称加密安全性高但效率低,因此 HTTPS 结合两者优势。客户端生成一个随机的对称密钥(会话密钥),用服务器公钥加密后发送给服务器;服务器用自身的私钥解密密密文,获取会话密钥。此时,客户端和服务器都持有相同的会话密钥,后续数据传输将使用该对称密钥进行对称加密(如 AES 算法)。
最后,加密传输阶段:握手完成后,客户端和服务器使用会话密钥的会话密钥对传输后的数据进行对称加密,同时会对数据添加消息认证码(MAC),确保数据在传输过程中未被篡改。接收方解密后验证 MAC,若不一致匹配则说明数据完整可信。
此外,HTTPS 还通过证书链机制防止中间人攻击:证书由权威 CA 签发,CA 用自己的私钥对服务器公钥签名,客户端用 CA 的公钥钥验证签名,确保确保服务器公钥未被篡改,从而而中间人无法伪造证书。
记忆法:可通过 “验证→换钥→加密传” 三步记忆,验证证书书合法性实性,交换对称钥建立对称加密基础,最终用对称钥加密传输数据,核心是 “非对称护密钥,对称传数据”。
Jetpack 包中包括哪些内容?你熟悉其中的哪些(如 Compose:声明式 UI)?
Jetpack 是 Android 官方推出的组件库集合,旨在简化开发、提高代码质量,按功能可分为架构组件、UI 组件、行为组件和基础组件,具体内容及熟悉的部分如下:
架构组件:用于处理数据管理和生命周期,确保数据与 UI 分离。包括 Lifecycle(监听组件生命周期,避免内存泄漏,如通过 LifecycleObserver 监听 Activity 状态变化);ViewModel(存储与 UI 相关的数据,生命周期长于 Activity,配置变化(如屏幕旋转)时不销毁,方便数据留存);LiveData(可观察的数据持有者,能感知生命周期,自动在主线程更新 UI,避免内存泄漏);Room(基于 SQLite 的 ORM 框架,通过注解简化数据库操作,支持编译时 SQL 校验和协程,如用 @Dao 定义数据访问接口,@Entity 定义实体类);DataBinding(将布局 XML 与数据直接绑定,减少 findViewById 代码,支持双向绑定);WorkManager(管理后台任务,兼容不同 Android 版本,如定时同步数据、延迟执行任务,确保任务即使在应用退出后也能执行)。
UI 组件:用于构建用户界面。包括 Compose(声明式 UI 框架,用代码描述 UI,代替 XML 布局,通过函数组合构建界面,支持实时预览,如 Column、Row 等组件组合布局,状态驱动 UI 更新);Navigation(管理应用内页面跳转,通过导航图定义跳转关系,支持深层链接和动画,简化 Fragment 或 Activity 之间的切换);ViewPager2(基于 RecyclerView 实现的滑动容器,支持横向 / 纵向滑动、无限循环,比旧版 ViewPager 更灵活)。
行为组件:处理用户交互和系统集成。包括 NotificationCompat(兼容不同版本的通知 API,简化通知创建,支持渠道管理);MediaCompat(统一媒体操作接口,处理音频、视频播放,兼容不同设备);Slices(允许应用在系统界面(如搜索栏)展示部分内容,增强应用曝光)。
基础组件:提供核心功能支持。包括 AppCompat(确保低版本设备兼容高版本 UI 特性);Android KTX(为 Kotlin 提供扩展函数,简化代码,如 View 的扩展函数 doOnLayout)。
我熟悉的组件中,Compose 通过声明式语法大幅减少 UI 代码,例如一个简单的按钮:
@Composable
fun MyButton() {Button(onClick = { /* 点击事件 */ }) {Text("点击我")}
}
ViewModel 结合 LiveData 可实现数据与 UI 分离,例如:
class MyViewModel : ViewModel() {private val _data = MutableLiveData<String>()val data: LiveData<String> = _datafun loadData() {// 模拟网络请求_data.value = "加载完成"}
}
记忆法:按 “架构管数据,UI 构界面,行为控交互,基础保兼容” 分类记忆,核心组件可记 “生(Lifecycle)、数(LiveData)、视(ViewModel)、房(Room)、画(Compose)”。
如何处理一张比较大的 Bitmap?
处理大 Bitmap 的核心是避免内存溢出(OOM),需从加载、显示、回收等环节优化,具体方法如下:
首先,按需加载,避免加载原始尺寸。大 Bitmap(如 2000×3000 像素)直接加载会占用大量内存(ARGB_8888 格式下,每个像素 4 字节,该尺寸约 22MB),远超多数设备单应用内存限制。应根据显示控件尺寸计算合适的采样率(inSampleSize),通过 BitmapFactory.Options 加载缩小后的图片。计算方法:获取控件宽高(如 imageView.getWidth ()),与图片原始宽高比较,得到缩放比例,inSampleSize 取 2 的幂(如比例为 3,则取 4),确保加载的图片尺寸不超过控件需求。
代码示例:
public static Bitmap decodeSampledBitmap(String path, int reqWidth, int reqHeight) {// 第一次解码获取原始尺寸BitmapFactory.Options options = new BitmapFactory.Options();options.inJustDecodeBounds = true; // 不加载像素,仅获取尺寸BitmapFactory.decodeFile(path, options);// 计算inSampleSizeoptions.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);// 第二次解码加载缩小后的图片options.inJustDecodeBounds = false;return BitmapFactory.decodeFile(path, options);
}private static int calculateInSampleSize(BitmapFactory.Options options, int reqWidth, int reqHeight) {int height = options.outHeight;int width = options.outWidth;int inSampleSize = 1;if (height > reqHeight || width > reqWidth) {int halfHeight = height / 2;int halfWidth = width / 2;// 找到最大的inSampleSize(2的幂),使缩小后尺寸不小于需求while ((halfHeight / inSampleSize) >= reqHeight && (halfWidth / inSampleSize) >= reqWidth) {inSampleSize *= 2;}}return inSampleSize;
}
其次,加载部分区域。若只需显示大图片的局部(如地图、长图),可使用 BitmapRegionDecoder,仅加载可见区域的像素。例如:
InputStream is = getContentResolver().openInputStream(uri);
BitmapRegionDecoder decoder = BitmapRegionRegionDecoder.newInstance(is, false);
Rect rect = new Rect(0, 0, 500, 500); // 加载左上角500×500区域
Bitmap bitmap = decoder.decodeRegion(rect, new BitmapFactory.Options());
imageView.setImageBitmap(bitmap);
第三,及时回收内存。当 Bitmap 不再使用时,调用 bitmap.recycle () 释放内存,并置空引用,帮助 GC 回收。注意:Android 3.0 + 后 Bitmap 像素数据存储在堆内存,recycle () 仅释放原生内存,需结合引用管理(如使用弱引用)。
第四,使用缓存机制。通过 LruCache 缓存常用 Bitmap,限制缓存大小(如应用内存的 1/8),避免重复加载。例如:
int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
int cacheSize = maxMemory / 8;
LruCache<String, Bitmap> bitmapCache = new LruCache<String, Bitmap>(cacheSize) {@Overrideprotected int sizeOf(String key, Bitmap value) {return value.getByteCount() / 1024; // 以KB为单位计算}
};
最后,适配不同设备。根据设备分辨率和内存情况动态调整加载策略,例如低内存设备使用更低的采样率或 RGB_565 格式(每个像素 2 字节,内存减少一半)。
记忆法:用 “采区收缓配” 概括核心方法,采样加载(采)、局部加载(区)、及时回收(收)、缓存复用(缓)、设备适配(配)。
如何压缩 Bitmap?
压缩 Bitmap 的目的是减小其内存占用或文件大小,根据需求可分为内存压缩(减小像素数)和文件压缩(减小存储体积),具体方法如下:
内存压缩(尺寸压缩):通过减小 Bitmap 的宽高降低像素总数,直接减少内存占用,适用于显示场景(如列表图片)。核心是通过 Matrix 或 BitmapFactory.Options 的 inSampleSize 实现。
使用 Matrix 缩放:
Bitmap original = BitmapFactory.decodeFile(path);
int newWidth = original.getWidth() / 2;
int newHeight = original.getHeight() / 2;
Matrix matrix = new Matrix();
matrix.postScale(0.5f, 0.5f); // 缩放0.5倍
Bitmap scaledBitmap = Bitmap.createBitmap(original, 0, 0, original.getWidth(), original.getHeight(), matrix, true);
original.recycle(); // 回收原图
使用 inSampleSize(同处理大 Bitmap 的采样方法):通过计算合适的采样率,加载时直接缩小图片,内存占用按比例减少(如 inSampleSize=2,内存变为 1/4)。
文件压缩(质量压缩):不改变 Bitmap 的像素数和内存占用,通过降低图片质量(如 JPEG 的压缩率)减小存储文件大小,适用于图片上传、保存等场景。通过 Bitmap 的 compress () 方法实现,参数 format 指定格式(JPEG、PNG 等),quality(0-100)控制质量,100 为最高质量。
示例:
ByteArrayOutputStream baos = new ByteArrayOutputStream();
// 质量压缩为50%,格式为JPEG
original.compress(Bitmap.CompressFormat.JPEG, 50, baos);
byte[] bytes = baos.toByteArray();
// 保存或上传bytes
注意:PNG 是无损格式,quality 参数无效,压缩效果差,建议转 JPEG 或 WebP 格式。
格式转换压缩:使用更高效的图片格式(如 WebP),相同质量下文件大小比 JPEG 小 25%-35%,比 PNG 小 40%。Android 4.0 + 支持 WebP 编码,可通过 BitmapFactory 和 compress () 方法处理:
// 转为WebP格式,质量75%
original.compress(Bitmap.CompressFormat.WEBP, 75, baos);
综合压缩策略:显示时优先尺寸压缩(降低内存),保存 / 上传时结合质量压缩和格式转换(减小文件)。例如,列表图片先按控件尺寸缩放(尺寸压缩),再保存为 WebP 格式(格式压缩)。
注意:压缩需平衡质量和大小,过度压缩会导致图片模糊;质量压缩后若需再次显示,需重新解码 bytes 为 Bitmap,可能增加 CPU 开销。
记忆法:按 “内存靠缩尺,文件靠降质,格式换高效” 记忆,尺寸压缩减内存,质量压缩减文件,WebP 格式更优。