Redis实战(5)-- 高级数据结构 HyperLogLog
PV:累计访客量
UV:实时在线人数
针对UV实时在线人数,即一个时间段内,当前用户反复进入页面只计作一次,这个可以使用Set和HyperLogLog实现,对比:
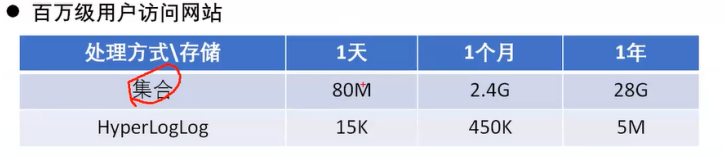
HyperLogLog明显消耗资源少。
介绍:
HyperLogLog是依据概率论中伯努利实验并且结合最大似然估算法与做分桶优化,形成的,其本质上也是一个字符串类型。
入门:
三个主要命令:pfadd,pfcount,pfmerge
pfadd添加进入HyperLogLog中元素,pfcount返回对应key中元素有多少个,pfmerge进行并集多个key返回不重复的元素值。
伯努利:
举个简单例子,抛硬币,七次时候得到正面硬币的概率计算如下:
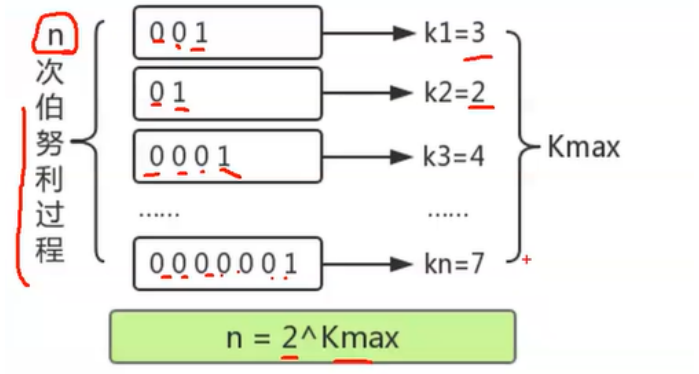
假设0是背面,1是正面:七次才到正面大概需要次数为2^7次(但是有误差,有可能1次就成功,也可能多于128次)。
分桶优化:
减少对应的误差,即多次实现,取平均值。但是平均也有问题,需要进行调和平均数,不会被大数所影响。
例如:
A工资:1000/月,B工资:30000/月
则平均 2/(1/1000+1/30000) 约等于1935.484。
实际逻辑:【核心存储逻辑】
HyperLogLog写入逻辑:
执行存入一个HyperLogLog中元素时候,会将字符串等数组转化为二进制的比特串
例如:
Wangjb -> 64bit的二进制字符串(在Redis中有16384个桶,进行分桶计算)
假设64位的字符串为 0010...0001
高位 低位
假设就拿低位的14位做分桶,那么剩余的50位用作计算(值被Hash算法进行分散)
所以对应的数据会存储到01的桶中,而计算部分是经过Hash运算得出一个值,找到最高位出现1的位置,后在桶中记录最高出现1的位数是哪个到,例如:
000100.... 最高位第10位出现1,则存入01桶的值就是10。
而此时插入另一个元素dgy,其值位 010000...0001,也被分到01桶,最高位出现1位置为12位,则比较最高位出现1位置,发现dgy字符串更高,则替换01桶中存储的数据,01桶中记录值改10为12.(桶内值只记录最大值)
【结论】由此可以得出,桶之中需要存储0-50即可,所以每个桶只需要一个6位空间即可存储一个元素,更省内存。
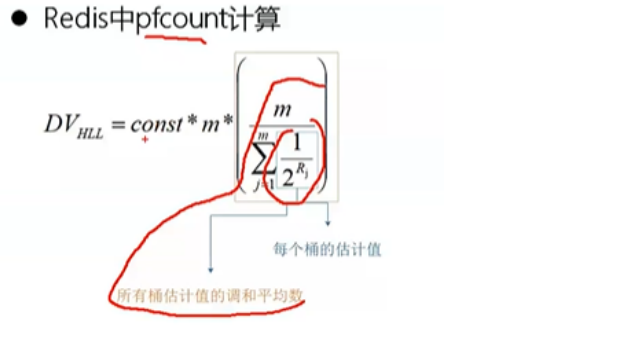
HyperLogLog统计逻辑:
获取16384个桶中元素,后进行:桶1+桶2+。。。。+桶16384
其中每个桶值都是2^k次方,k为桶中元素值。
后进行调和平均数计算,方法为:
实际使用:
(1)pfadd
pfadd key element [element …]
pfadd用于向HyperLogLog 添加元素,如果添加成功返回1:
例如:
pfadd u-9-30 u1 u2 u3 u4 u5 u6 u7 u8
(2) pfcount
pfcount key [key …]
pfcount用于计算一个或多个HyperLogLog的独立总数,例如u-9-30 的独立总数为8:

如果此时向插入一些用户,用户并且有重复

如果我们继续往里面插入数据,比如插入100万条用户记录。内存增加非常少,但是pfcount 的统计结果会出现误差。
(3)pfmerge
pfmerge destkey sourcekey [sourcekey ... ]
pfmerge可以求出多个HyperLogLog的并集并赋值给destkey,请自行测试。
可以看到,HyperLogLog内存占用量小得惊人,但是用如此小空间来估算如此巨大的数据,必然不是100%的正确,其中一定存在误差率。前面说过,Redis官方给出的数字是0.81%的失误率。