数新智能 CTO 原攀峰:DataCyber 面向 AI 时代的多模态数据湖设计与实践
嘉宾介绍:
原攀峰,北京航空航天大学计算机硕士,十余年大数据、隐私计算的行业研发经验,国内外发明专利20篇。前阿里巴巴集团大数据平台高级技术专家,阿里御膳房、阿里云数加、DataWorks创始团队核心领导,0-1完成阿里云隐私计算平台DataTrust产品研发及商业化落地。
以下内容为数新智能CTO原攀峰在中国计算机学会(CCF)、CCF CTO CLUB联合数新智能共同主办的“多模态数据融合技术创新与落地实战”活动中演讲全文:
我是数新智能 CTO 原攀峰,简单自我介绍一下:我毕业就加入阿里,参与了阿里的淘宝数据平台、商家数据平台、阿里云数据平台的开发和架构设计过程。在阿里工作的最后一个阶段是作为技术负责人主导完成了阿里云的隐私计算平台DataTrust从0到1的架构设计、研发以及商业化落地,之后离开阿里加入数新智能。
今天分享的主题是 DataCyber 多模态数据湖平台,这也是数新智能在大模型AI时代针对多模态数据所进行的相关产品设计以及技术研发的成果。

在 AI 时代,非结构化数据管理面临着诸多挑战,具体体现在采集、存储、管理、计算等多个环节:
采集:数新智能在服务企业客户时发现,多模态数据已成为企业内部的主要数据形态,涵盖文本、图片、音频、视频等多种形式。这些数据往往分散在不同系统中,有的存于本地硬盘,有的位于文件服务器或云存储,且各类数据的格式差异极大。如何以统一高效的方式采集这些数据,以及如何实时识别并采集增量更新的数据,是数据采集阶段面临的核心问题。
存储:大型企业内部的非结构化数据规模极为庞大,可能达到十亿甚至百亿级别以上,需要进行统一存储。而高可用冗余存储带来的成本增加,给存储系统带来了极大挑战。
管理:对于分散、异构的多模态数据,如何实现高效检索与访问以精准获取所需数据,如何建立统一的访问控制机制,以及如何实现数据全生命周期的统一管理,都是亟待解决的问题。
计算:非结构化数据通常噪声较多,导致数据清洗过程复杂多样,对算力的需求也极为庞大。
当前大模型AI时代对于多模态数据处理的场景以及需求也是越来越多,就采集、存储、管理、计算等挑战,我们需要构建一个面向企业级的多模态数据管理平台。
简单介绍一下数新智能在构建多模态数据管理平台的过程中所需要的数据管理相关技术。

统一存储系统:对于超大规模的企业级非结构化数据管理场景,传统的分布式存储(如:HDFS)无法很好地解决小文件管理问题,因此我们需要企业级高可用的对象存储系统,以解决不同类型的数据,实现高效采集和存储。我们还需要引入数据湖技术,数据湖可存储结构化、半结构化和非结构化数据,无需预先定义数据模型或转换格式,数据以原始格式保存,直到需要分析时才进行处理,降低预处理成本。与云存储相结合,可水平扩展支持PB级数据存储,通常比传统数据仓库成本更低。这种灵活性和扩展性能够支持实时数据分析和批处理,适应企业需求变化,覆盖多模态数据处理的场景。
统一元数据管理:统一元数据是多模态数据管理的基础服务,通过采集元数据,建立元数据标准,可以实现不同模态数据的统一描述和关联关系,例如为图像数据添加文本标签,从而打破数据孤岛,促进跨模态的检索与分析。
CPU+GPU 资源调度:多模态数据处理对于算力资源的需求越来越大,我们需要基于云原生的弹性伸缩资源调度能力,支持CPU和GPU不同类型计算资源的统一调度和管理,这些是在资源调度层面需要引入相关技术。
DATA+AI混合计算负载:在计算层面,需要引入分布式的计算框架,针对不同类型数据、不同计算场景,需要不同的计算框架进行支持,解决Data和AI不同类型的计算负载任务,不同类型的多模态数据能够基于主流的开源框架,提供统一的平台支持数据和AI的分析。
目前对于多模态数据的管理业界有两种做法:一种是基于去中心化的架构,多模态数据以原始的分散方式存储和管理,处理后的结果仍然写回原始存储系统。这种模式的重心聚焦在数据的加工处理链路,但缺乏统一管理的机制。另一种是基于中心化的架构,构建一个统一的数据湖平台,把不同类型的多模态数据,统一入湖到数据湖平台,然后去进行管理和分析。
数新智能采用的是多模态数据湖平台方案,基于 Data+AI 一体化云原生湖仓架构,面向 AI-Native 构建数据基础设施。

基于非结构化数据处理面临的挑战,结合我们在技术上的规划与思考,这张图呈现的是 DataCyber 多模态数据湖的平台全景。整个平台由数新智能的两款产品构成,分别是 CyberData 和 CyberEngine。
平台架构最底层是基于多云开放式数据湖存储,适配支持了主流云厂商的对象存储系统。
中间层是多元异构数智引擎底座 CyberEngine,支持目前主流的数据湖存储格式,为客户提供统一的元数据服务,基于云原生的资源调度,支持了目前大数据和AI的主流计算框架,包括像Spark、Flink等大数据计算框架,以及Pytorch、Tensorflow、Ray等AI计算框架。
最上层是面向开发者提供的一体化数据开发治理平台CyberData,除了提供数据集成平台、离线数仓开发平台、实时数仓开发平台的能力,还支持多模态数据湖平台的能力。
这个多模态数据湖管理平台,就是我们重点面向非结构化数据场景所提供的能力。基于以上平台能力,能够统一处理结构化数据、非结构化数据以及半结构化数据。在此基础上,我们可以形成企业的全域资产管理和治理平台:多种类型的数据都可以在全域资产管理平台进行治理,我们可以结合大模型的能力,为客户提供开发助手、分析助手、治理助手等智能体Agent。
图片左侧是各种数据来源,覆盖了结构化数据、半结构化数据和非结构化数据。右侧是各种类型的数据应用,包括大模型、Agent以及BI的相关场景,平台为数据应用提供数据服务能力。
总结一下这个平台具有的关键特点:多模态数据的统一存储系统以及统一元数据管理;融合主流大数据和AI引擎框架,实现Data+AI混合计算负载;一体化平台覆盖主流的数据仓库和数据湖的开发模式。

上图展示的是 DataCyber 多模态数据湖的功能架构,包含以下模块:
湖存储:我们基于湖存储来提供统一的数据入湖能力,以及统一元数据管理能力。
湖管理:入湖和元数据的管理是构建多模态数据管理平台的基础,不同类型的多模态数据,经过多源采集、多种格式解析、元数据抽取,进入这个平台,为后续的分析提供数据来源。
湖引擎:数新智能自主研发的统一引擎网关CyberGateway,通过统一引擎网关,能够实现对于不同厂商、不同引擎的统一纳管以及统一接入。基于云原生的方式,向异构引擎提交大数据和AI计算任务。
数据处理:数新智能自主研发的统一任务调度CyberScheduler,这是我们构建面向大数据和AI场景的任务调度关键组件。在此基础上我们可以实现工作流编排、引擎管理、任务管理以及日志管理。在多模态的数据处理场景下,实现了算子开发平台,内置文档解析算子、图片解析算子、音频和视频解析算子。为了解决多模态数据处理逻辑差异大的问题,我们支持了自定义算子框架,能够方便扩展Python算子、Spark算子和Ray算子,从而极大扩展了平台对于非结构化类型数据的处理和解析能力。
数据治理:对于非结构化数据处理,我们引入数据集的概念,在数据治理中将其定义为数据资产。然后对数据资产进行相关元数据采集,以及对于管理资产目录挂载管理,并对资产打标分类、检索和资产血缘分析等能力,以便更好地为大模型AI和BI的相关场景提供数据服务。
图片右侧是整个平台需要依托的运维管理模块,提供云原生集群的集群管理、队列管理、组件管理、日志管理、监控告警等相关支撑服务。
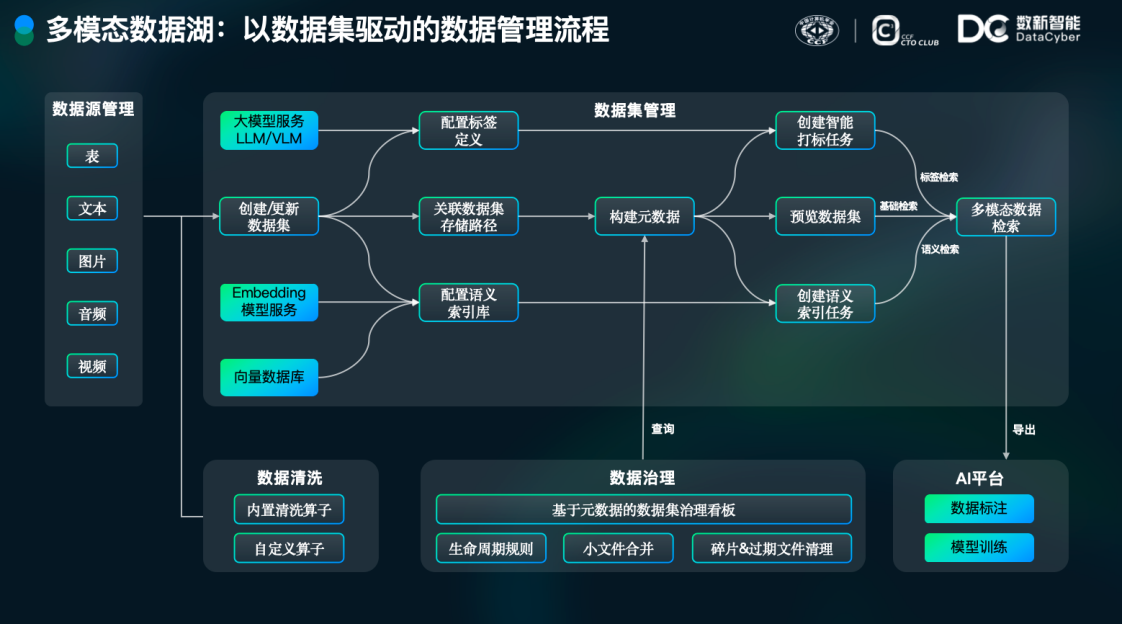
上图展示了数新智能的产品在落地过程中形成的以数据集驱动的非结构化数据管理流程。首先平台定义不同类型的数据源,这些数据源可以是结构化或者非结构化的。数据源被定义后,基于这些数据源可以创建和管理数据集。在数据集创建过程中,可以关联数据本身的存储路径,进一步采集后形成数据集的元数据基础信息。
为了丰富数据集的元数据信息,可以集成大模型服务能力,配置标签定义任务,从而创建智能化打标任务,利用大模型能力实现对非结构化数据的智能打标。可以集成 Embedding 模型能力,配置语义检索库,从而实现语义向量检索。
基于数据集的多维度元数据信息,我们可以实现数据集的治理过程。对于长期未使用的非结构化数据,可以设置合理的生命周期规则,并采用小文件合并等方式来实现数据集的治理优化。
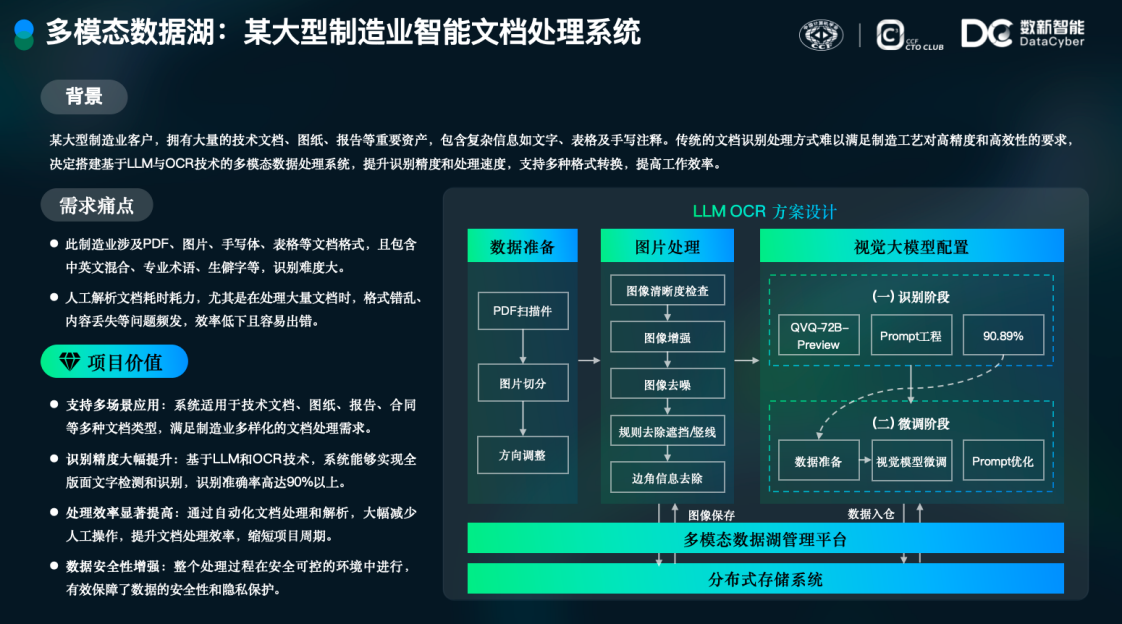
最后我们给大家分享某大型制造业智能文档处理系统的客户案例。该客户是传统制造业场景,拥有大量技术文档、图片报告等重要非结构化数据资产,这些资产包含文字表格和相关信息,传统方式提取这些信息的准确度和时效性存在很大问题。
数新智能基于多模态数据管理平台的能力,为客户构建一套多模态数据湖管理平台,在此平台上实现文档、图片等非结构数据的统一管理。进一步,我们基于大模型与OCR技术,实现图片和文档的处理过程。我们引入了千问的OCR模型和大语言模型,完成图片到文字识别过程,以及信息提取的过程。通过这些技术手段,最终使用效果达到了90%以上准确率,满足了客户要求。整体方案通过多模态数据湖平台完成,有效保障了非结构化数据的安全性。
谢谢大家!