MYSQL:JDBC编程
文章目录
- MYSQL:JDBC编程
- 1. 本文简述
- 2. 什么是JDBC
- 2.1 JDBC的应用场景
- 2.2 JDBC工作原理
- 3. 为什么要使用JDBC
- 4. 使用JDBC
- 4.1 创建Maven工程并配置国内镜像
- 4.2 获取MySQL驱动包
- 4.3 修改pom.xml文件
- 4.4 建立数据库连接
- 4.5 创建Statement
- 4.6 执行SQL语句
- 4.7 处理结果集
- 4.8 释放资源
- 5. JDBC常用接口和类
- 5.1 `DriverManager` 和 `DataSource`
- 5.2 `DriverManager` 与 `DataSource` 的区别
- 5.3 `Connection`:数据库连接
- 5.4 `Statement` 对象家族
- 5.4.1 `Statement`
- 5.4.2 SQL注入
- 5.4.3 `PreparedStatement`
- 5.4.4 `CallableStatement`
- 5.4.5 `executeQuery()`
- 5.4.6 `executeUpdate()`
- 5.5 `ResultSet`:结果集
- 6. 完整示例:封装DBUtil并实现数据插入
- 6.1 创建数据库工具类 `DBUtil`
- 6.2 使用`DBUtil`实现数据插入
MYSQL:JDBC编程
1. 本文简述
- 掌握JDBC常用接口和类
- 熟练使用JDBC进行数据库交互
2. 什么是JDBC
JDBC(Java Data Base Connectivity, Java数据库连接)是Java程序与数据库之间的一座桥梁。它包含了一套由Java定义的、用于执行SQL语句的接口,使得开发者能够便捷地编写与数据库交互的程序。
JDBC的核心作用可以归纳为三点:
- 与数据库建立连接
- 发送SQL语句
- 处理数据库返回的执行结果
2.1 JDBC的应用场景
[图片占位]
2.2 JDBC工作原理
JDBC的工作原理可以简洁地概括为以下几个步骤:加载驱动、建立连接、创建Statement、执行SQL、处理结果以及关闭资源。
3. 为什么要使用JDBC
分析思路:
在深入代码之前,我们先来回顾一下使用客户端工具(如Navicat、DBeaver)操作数据库的完整流程:
- 连接到数据库服务。
- 发送SQL语句。
- 获取并显示返回结果。
- 关闭连接。
实际上,我们的Java程序要操作数据库,也需要遵循同样的基本步骤。一个自然而然的想法是:我们可以自己编写代码来实现数据库连接、SQL发送、结果处理和连接关闭。
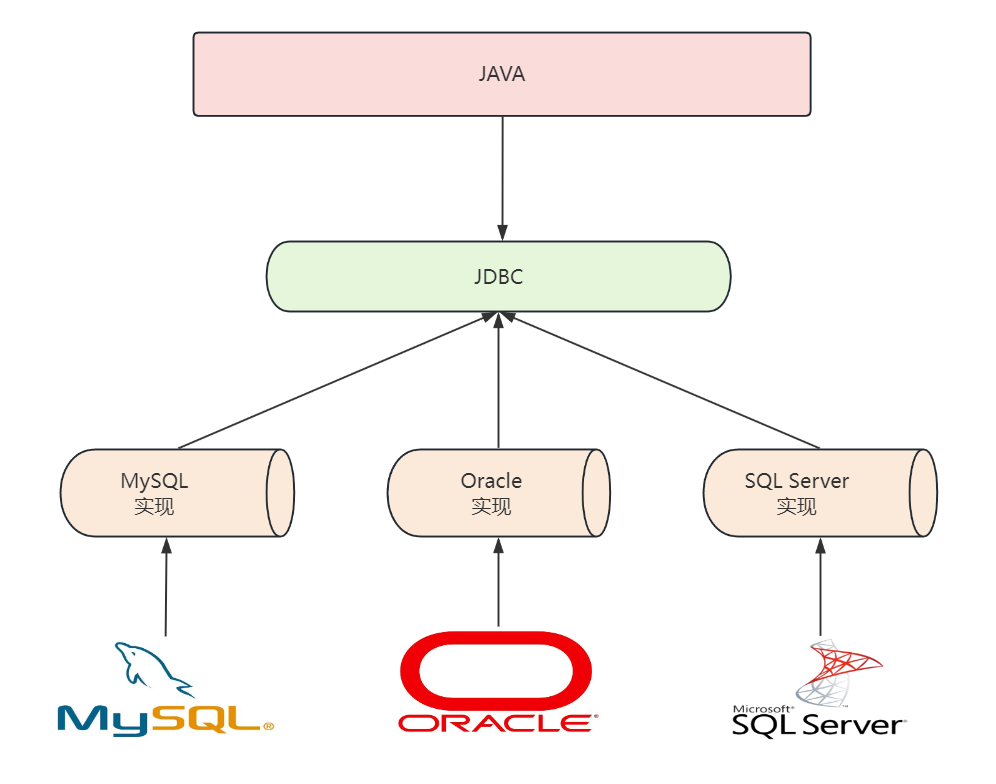
但这里有一个挑战:世界上有各式各样的数据库(MySQL, Oracle, SQL Server等),它们底层的通信协议和参数细节各不相同。如果让程序员为每一种数据库都编写一套专用的连接和操作代码,那么开发工作量和后期的维护成本将是巨大的。
为了解决这个问题,Java的设计者们采取了一种非常聪明的设计模式——面向接口编程。他们没有直接实现与特定数据库的通信代码,而是定义了一套标准的Java接口(即JDBC API),这套接口明确了数据库操作的各个环节(如建立连接、执行语句等)应该有哪些方法。
然后,将实现这些接口的具体任务交给了各大数据库厂商。厂商们会提供针对自己数据库产品的“驱动包(Driver)”,这个驱动包就是JDBC接口的具体实现类。
如此一来,作为Java程序员,我们只需要面向这套标准接口编程即可。无论底层使用的是MySQL还是Oracle,我们调用的都是JDBC中定义的相同方法。当需要更换数据库时,代码几乎不需要改动,只需在项目中替换相应厂商的驱动包依赖即可。这种设计极大地提高了代码的可移植性和可维护性。
因此,使用JDBC的完整过程可以概括为:
- 加载数据库厂商提供的驱动包。
- 通过JDBC API建立与数据库的连接。
- 创建
Statement对象用于承载和执行SQL。 - 执行SQL语句。
- 处理返回的结果集。
- 释放资源,关闭连接。
4. 使用JDBC
4.1 创建Maven工程并配置国内镜像
为了加快项目依赖的下载速度,我们推荐配置Maven使用国内的镜像仓库,例如阿里云。
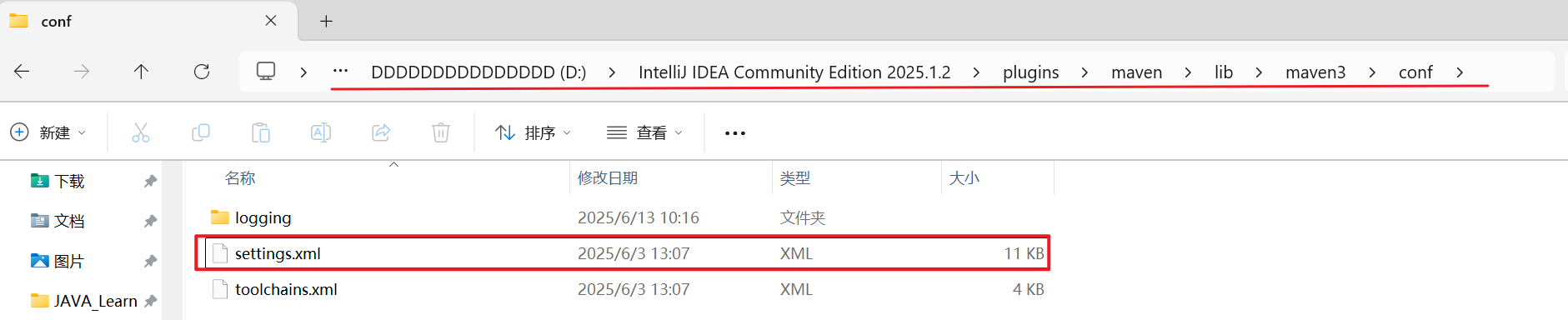
- 如果你是单独安装的Maven,配置文件路径通常在:
{Maven安装目录}/conf/settings.xml。 - 如果你使用的是IDEA自带的Maven,配置文件路径在:
{IDEA安装目录}/plugins/maven/lib/maven3/conf/settings.xml。
打开settings.xml文件,在<mirrors>标签内添加以下<mirror>节点:
<!-- 加入如下mirror节点 使用国内阿里云仓库镜像 开始 -->
<mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/public</url>
</mirror>
<mirror><id>central</id><mirrorOf>*</mirrorOf><name>aliyun central</name><url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror><id>spring</id><mirrorOf>*</mirrorOf><name>aliyun spring</name><url>https://maven.aliyun.com/repository/spring</url>
</mirror>
<!-- 加入如下mirror节点 使用国内阿里云仓库镜像 结束-->
4.2 获取MySQL驱动包
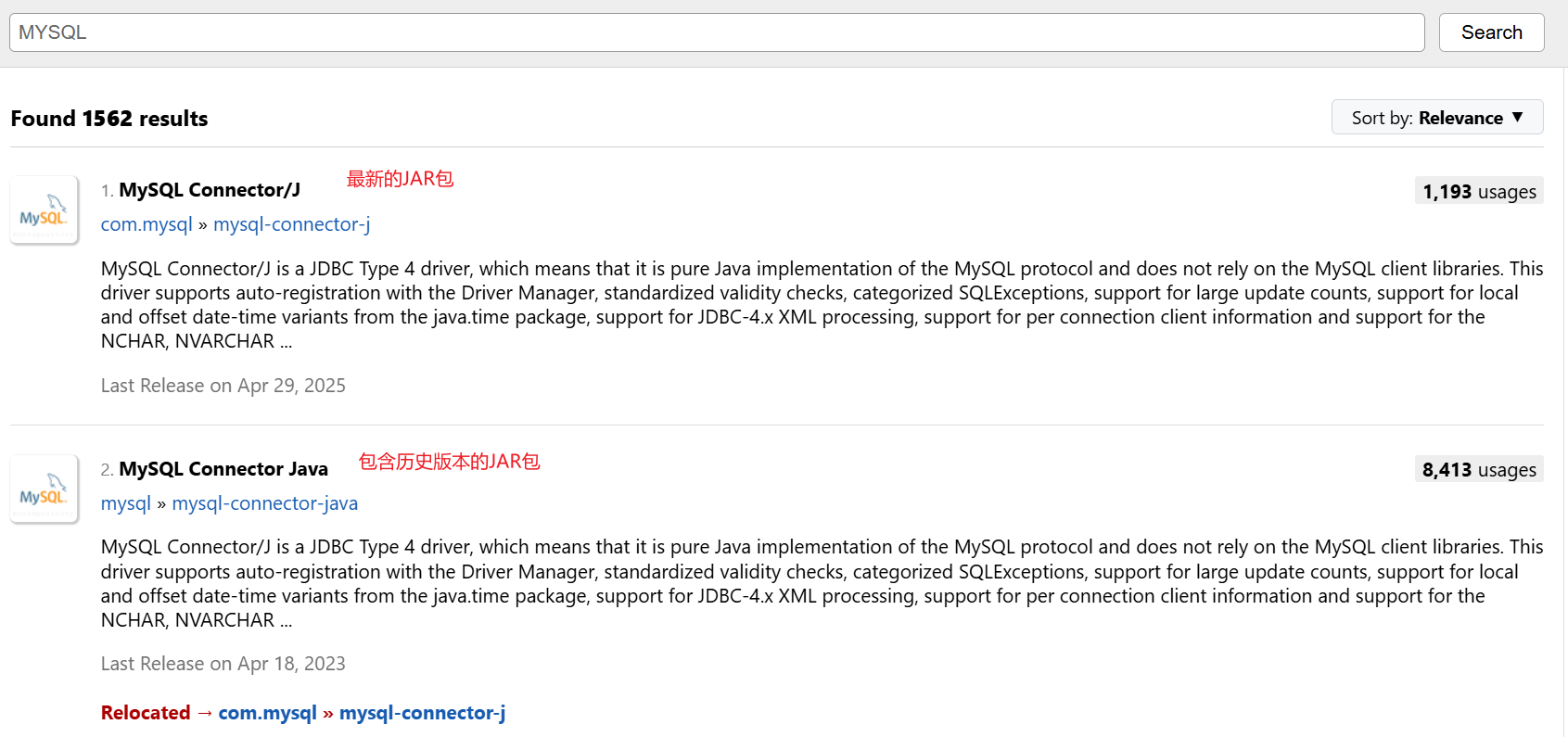
我们可以在 Maven中央仓库 网站上搜索“MySQL”,找到最新版本的驱动包依赖信息。
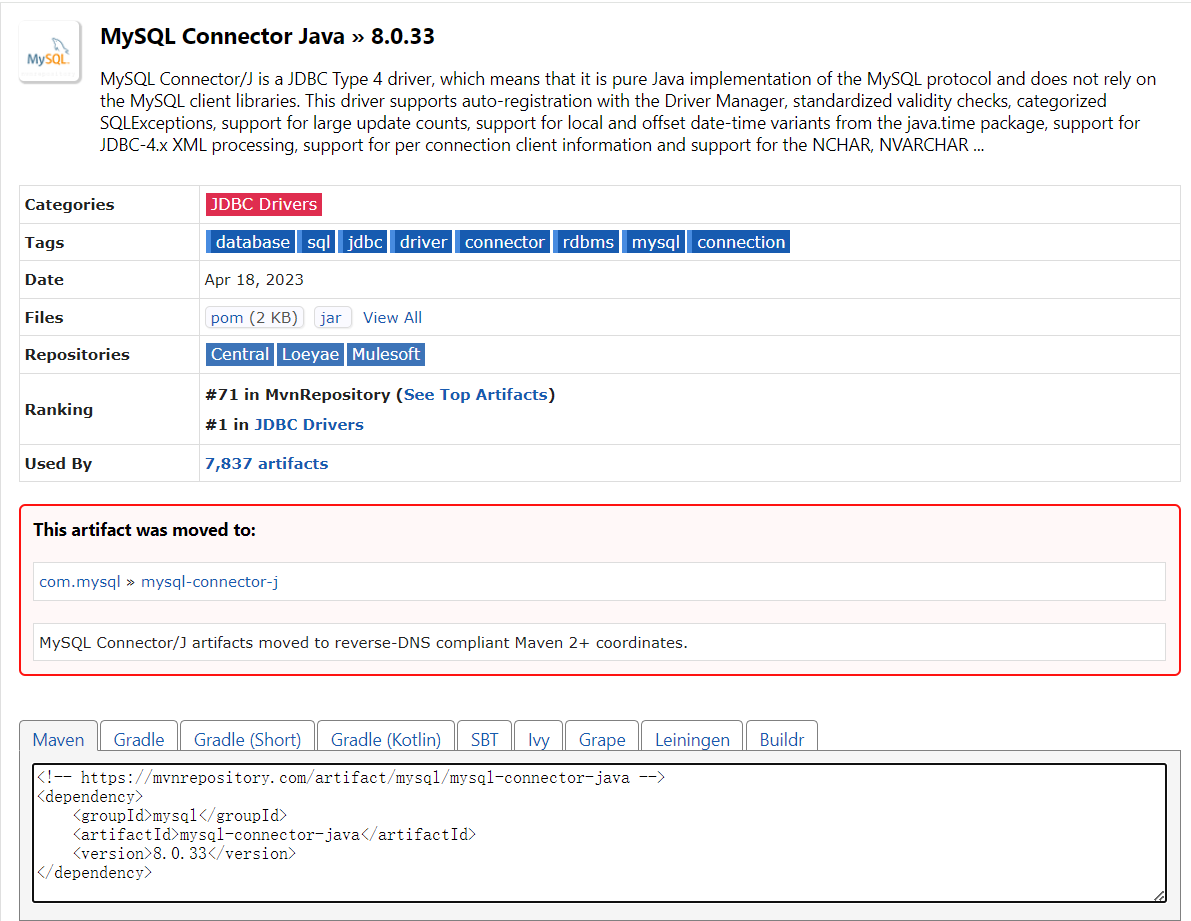
4.3 修改pom.xml文件
在你的Maven工程的pom.xml文件中,找到<dependencies>标签,并在其中添加MySQL驱动的依赖:
<dependencies><!-- MySQL 驱动包 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency>
</dependencies>
4.4 建立数据库连接
建立数据库连接主要有两种方式。
方式一:使用DriverManager(不推荐)
这是一种较为传统的方式。DriverManager.getConnection()方法有多种重载形式,可以灵活传入连接参数。
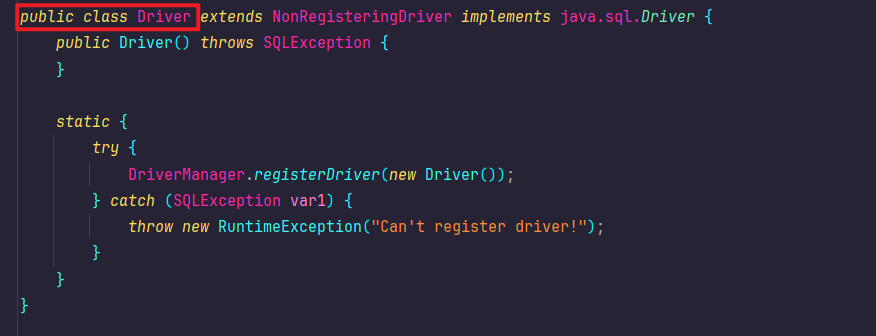
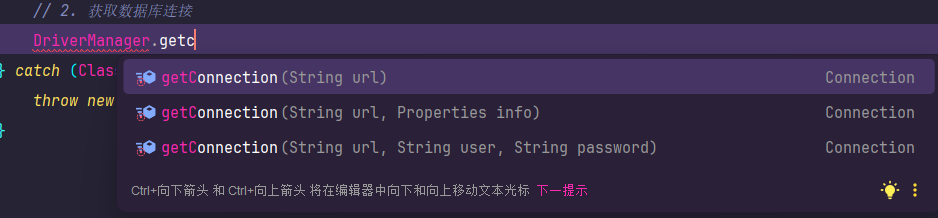
// 1. 注册驱动 (在现代JDBC中,此行可省略)
Class.forName("com.mysql.cj.jdbc.Driver");// 2. 获取数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/jobs_info_db?characterEncoding=utf8&allowPublicKeyRetrieval=true&useSSL=false","root","123456"
);
方式二:使用DataSource(推荐)
在实际开发中,我们更推荐使用DataSource(数据源)对象来获取连接,因为它提供了更好的连接管理和性能。
// 1. 创建并配置数据源对象
MysqlDataSource mysqlDataSource = new MysqlDataSource();
mysqlDataSource.setURL("jdbc:mysql://127.0.0.1:3306/jobs_info_db?characterEncoding=utf8&allowPublicKeyRetrieval=true&useSSL=false");
mysqlDataSource.setUser("root");
mysqlDataSource.setPassword("123456");// 2. 将其转换为标准的JDBC DataSource
DataSource dataSource = mysqlDataSource;// 3. 从数据源获取连接
Connection connection = dataSource.getConnection();
关于MySQL连接URL的说明:
jdbc:mysql://服务器地址:端口/数据库名?参数名=值&参数名=值...
jdbc:mysql://: 这是协议部分,固定写法。127.0.0.1:3306: 数据库服务器的IP地址和端口号。jobs_info_db: 要连接的具体数据库名称。?之后的是连接参数,常用的有:
characterEncoding=utf8: 指定字符编码,防止中文乱码。useSSL=false: 禁用SSL加密连接,在开发环境中常用。allowPublicKeyRetrieval=true: 允许客户端从服务器获取公钥,MySQL 8.0+版本可能需要。
4.5 创建Statement
获取到数据库连接Connection后,我们需要创建一个Statement对象,用它来执行SQL语句。
// 通过connection获取statement对象
Statement statement = connection.createStatement();
4.6 执行SQL语句
Statement对象提供了不同的方法来执行不同类型的SQL:
- 执行
SELECT查询:使用executeQuery()方法,它会返回一个ResultSet对象,其中包含了查询结果。
// 执行select语句, 并接收结果集
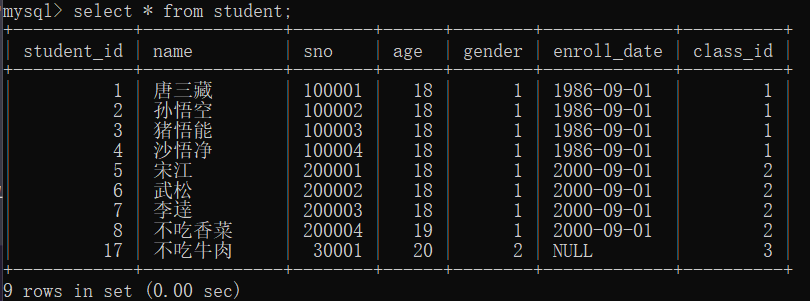
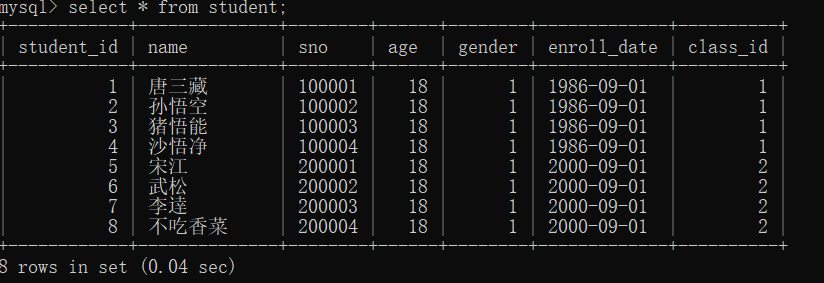
ResultSet resultSet = statement.executeQuery("select id, name, sno, age, gender, enroll_date, class_id from student");
- 执行
INSERT,UPDATE,DELETE操作:使用executeUpdate()方法,它会返回一个int类型的值,表示该操作影响的行数。
// 执行insert, update, delete语句,并接收受影响的行数
int row = statement.executeUpdate("update student set age = 20 where id = 2");
4.7 处理结果集
如果执行的是查询操作,我们需要遍历返回的ResultSet结果集,从中提取出每一行、每一列的数据。
// 遍历结果集获取数据
while (resultSet.next()) { // next()方法将光标移动到下一行,如果存在下一行则返回true// 通过列名或列索引(从1开始)获取数据// 编号long id = resultSet.getLong("id");// 姓名String name = resultSet.getString("name");// 学号String sno = resultSet.getString("sno");// 年龄int age = resultSet.getInt("age");// 性别byte gender = resultSet.getByte("gender");// 入学时间Date enrollDate = resultSet.getDate("enroll_date");// 班级编号long classId = resultSet.getLong("class_id");// TODO: 使用获取到的值进行后续处理...System.out.println("查询到学生:" + name);
}
4.8 释放资源
小提醒:
为了避免资源泄露,数据库访问过程中创建的所有资源对象,包括ResultSet、Statement和Connection,都必须在使用完毕后显式关闭。释放资源的顺序应该与创建它们的顺序相反,即 “后创建的先释放”。
一个健壮的资源释放代码块通常写在finally子句中,以确保无论程序是否发生异常,资源都能被尝试关闭。
// 释放结果集
if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}
}
// 释放statement
if (statement != null) {try {statement.close();} catch (SQLException e) {e.printStackTrace();}
}
// 关闭连接
if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}
}
5. JDBC常用接口和类
5.1 DriverManager 和 DataSource
DriverManager: 一个驱动管理类,用于管理JDBC驱动程序,并从中获取数据库连接。这是自JDK 1.1以来就存在的传统方式。DataSource: 数据源,是DriverManager的现代替代方案,自JDK 1.4引入。它是获取数据库连接的首选方法,我们强烈推荐使用。
5.2 DriverManager 与 DataSource 的区别
小提醒:
DriverManager和DataSource都可以帮助我们获取数据库连接,但它们在连接管理方式和资源利用效率上存在显著差异。
- 连接管理方式不同:
DriverManager像一个“一次性用品”的提供者。每次调用getConnection()方法,它都会向数据库发起请求,建立一个全新的物理连接。使用完毕后调用close(),这个物理连接就被真正地关闭和销毁了。这种方式在高并发场景下会频繁地创建和销毁连接,开销巨大,严重影响性能。DataSource则引入了**连接池(Connection Pool)**的技术,像一个“可循环使用的资源库”。在初始化时,DataSource会一次性创建一定数量的数据库物理连接,并把它们存放在连接池中。当程序需要连接时,并不是去创建新连接,而是从池中“借”一个空闲的连接。当调用close()方法时,连接也并不会被真正关闭,而是被“归还”到池中,以供其他线程后续复用。这种机制极大地减少了连接创建的开销,有效提高了资源利用率和系统性能。
5.3 Connection:数据库连接
Connection对象代表了Java应用程序与数据库之间的一个具体的连接(或称为会话)。所有的SQL执行和事务管理都是在这个连接的上下文中进行的。
5.4 Statement 对象家族
5.4.1 Statement
Statement接口用于执行静态的SQL语句。它的主要问题在于,当SQL语句中需要包含动态参数时(例如WHERE子句中的条件值),只能通过字符串拼接的方式来构建完整的SQL。
例如:
String sql = "select * from student where name = '" + name + "' and class_id = " + classId;
安全警示:
这种直接拼接字符串的方式存在严重的安全漏洞,即SQL注入(SQL Injection)。如果不对用户输入的参数(如name)进行严格的校验和过滤,攻击者就可以构造恶意的输入,篡改原始的SQL逻辑。
5.4.2 SQL注入
SQL注入是一种常见的网络攻击手段。攻击者通过在Web应用的输入字段中填入精心构造的SQL片段,欺骗服务器执行非授权的数据库操作,从而窃取、篡改或删除数据。
示例:
假设我们有一个查询,name和class_id是动态参数。
-- 正常的查询,没有符合的结果
mysql> select * from student where name = '宋江' and class_id = 1;
Empty set (0.01 sec)
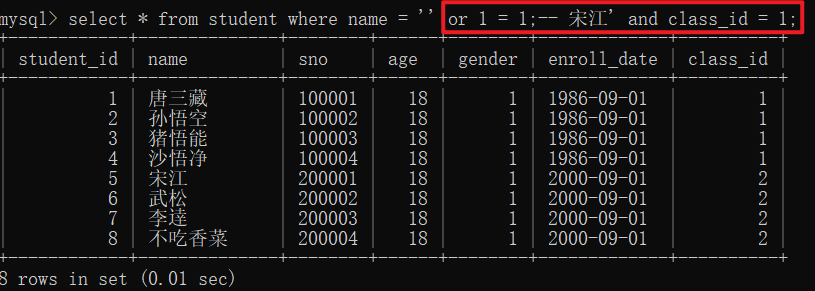
现在,一个攻击者在输入name的地方,填入了 ' or 1 = 1;-- 。拼接后的SQL语句就变成了:
mysql> select * from student where name = '' or 1 = 1;-- 宋江' and class_id = 1;
分析一下这条恶意SQL:
name = ''部分可能为假。or 1 = 1这个条件永远为真,导致WHERE子句的整个条件恒为真。--是SQL中的注释符,它后面的所有内容(包括原始的and class_id = 1)都被数据库忽略了。最终结果: 这条SQL查询出了
student表中的所有记录,造成了严重的数据泄露。
攻击者甚至可以构造更具破坏性的语句,比如插入、更新或删除数据:
-- 恶意输入: ';update student set age=19 where id=8; --
-- 拼接后的SQL:
mysql> select * from student where name = '';update student set age=19 where id=8; -- 宋江' and class_id = 1;
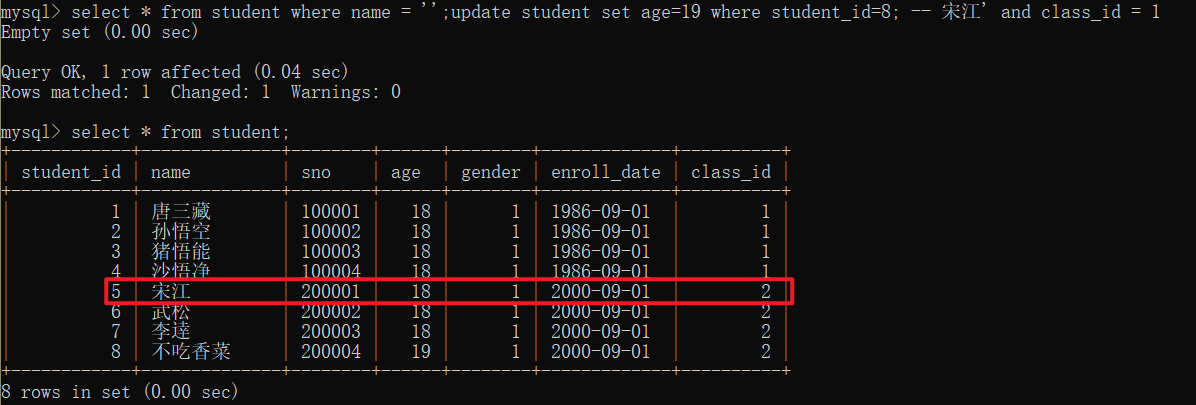
这条命令会先执行一个无效的查询,然后执行一个UPDATE操作,成功修改了id为8的学生年龄。
5.4.3 PreparedStatement
为了从根本上解决SQL注入问题,JDBC提供了PreparedStatement接口。它代表一个预编译的SQL语句。
工作原理:
- SQL模板与参数占位符:在创建
PreparedStatement对象时,我们提供的是一个带有?占位符的SQL模板。SQL的结构被预先编译并存储在对象中。 - 参数绑定:之后,我们通过调用
setXxx()系列方法(如setString(),setLong()),将真实的值安全地绑定到对应的占位符上。JDBC驱动在绑定时会自动处理特殊字符,使其作为纯粹的数据值传递给数据库,而不会被解释为SQL指令。
示例:
// 1. 创建PreparedStatement对象,使用?作为参数占位符
String sqlTemplate = "select id, name, sno, age, gender, enroll_date, class_id from student where name = ? and class_id = ?";
PreparedStatement preparedStatement = connection.prepareStatement(sqlTemplate);// 2. 为动态参数设置真实值,注意下标从1开始
preparedStatement.setString(1, "宋江"); // 第1个?被替换为字符串'宋江'
preparedStatement.setLong(2, 2); // 第2个?被替换为数字2// 3. 执行SQL语句 (此时不需要再传入SQL)
// select 操作
ResultSet resultSet = preparedStatement.executeQuery();
// insert, update, delete操作
int result = preparedStatement.executeUpdate();
使用PreparedStatement不仅可以有效防止SQL注入,还能因为SQL语句被预编译,在多次执行相同结构的SQL时获得更好的性能。
小提醒:IDE的SQL检查能完全防止注入吗?
有的同学可能会发现,现代的IDE(如IntelliJ IDEA)非常智能,当我们试图用字符串拼接构造有风险的SQL时,它会给出警告。
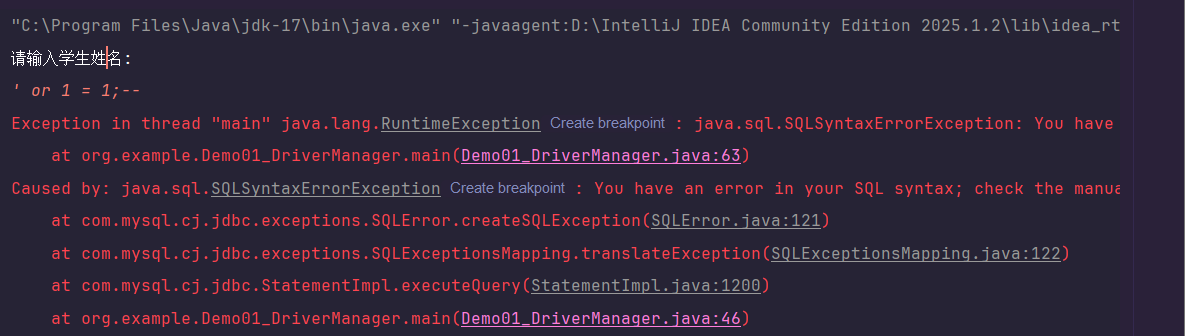
那么,这是否意味着我们可以依赖IDE的检查而高枕无忧了呢?答案是否定的。攻击者总能找到方法绕过一些简单的静态检查。例如,我们使用
/**/来代替空格,构造一个稍微变形的注入语句:'or/**/1=1;#。
在某些情况下,这种变形的SQL可能绕过IDE的检查,但依然能成功注入,查询出所有数据。
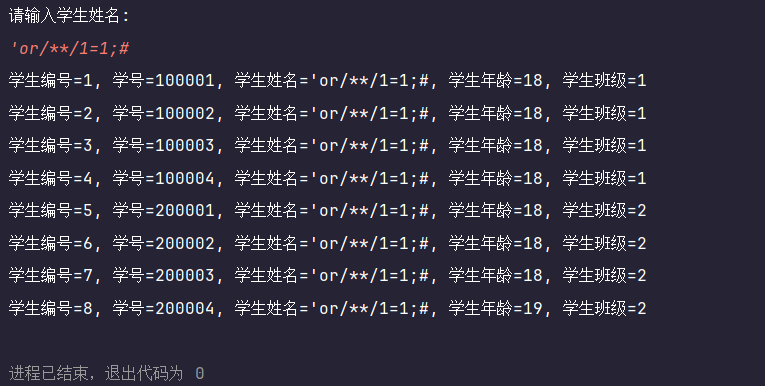
然而,当我们把这个恶意的字符串通过
PreparedStatement来处理时,情况就完全不同了。
PreparedStatement会将整个'or/**/1=1;#字符串作为一个普通的、完整的值去和name字段进行匹配,而不是将其中的一部分解释为SQL指令。数据库找不到name完全等于这个怪异字符串的记录,因此查询不到任何结果,从而成功地阻止了SQL注入攻击。结论: 永远不要信任用户的输入,也永远不要依赖客户端或IDE的检查。在处理带参数的SQL时,始终使用
PreparedStatement是最可靠、最安全的黄金法则。

5.4.4 CallableStatement
CallableStatement接口专门用于执行数据库中的存储过程。在此我们不做深入讨论。
5.4.5 executeQuery()
用于执行SELECT查询,返回一个ResultSet结果集。
5.4.6 executeUpdate()
用于执行INSERT、UPDATE、DELETE等数据修改操作,返回一个int值,表示受影响的行数。
5.5 ResultSet:结果集
ResultSet对象是一个数据表,它封装了数据库查询操作返回的所有行。
- 游标(Cursor):
ResultSet内部维护了一个指向当前数据行的游标。初始时,游标位于第一行之前。 - 遍历:我们通过调用
next()方法来移动游标。next()会将游标移动到下一行,如果下一行存在,则返回true;如果已经没有更多行,则返回false。这个特性使得我们可以很方便地在while循环中使用它来遍历整个结果集。 - 获取数据:
ResultSet接口提供了一系列getXxx()方法(如getBoolean(),getLong(),getString()等),用于从当前行检索列值。我们可以使用列的索引号(从1开始)或列的名称来指定要获取哪一列的数据。通常来说,使用列索引的效率会略高于使用列名。
6. 完整示例:封装DBUtil并实现数据插入
在实际开发中,我们很少会在每个需要数据库操作的地方都重复编写获取连接和释放资源的代码。这不仅繁琐,而且难以维护(比如,如果数据库密码变了,需要修改所有地方)。一个更好的做法是创建一个数据库工具类(Utility Class),将这些通用操作封装起来。
需求:
- 创建一个
DBUtil工具类,用于管理数据库连接的获取和释放。 - 编写一个
InsertExample程序,使用DBUtil来接收用户从控制台输入的学生信息,并将其插入到数据库。
6.1 创建数据库工具类 DBUtil
下面是一个DBUtil的实现。我们来分析一下它的设计:
- 单例模式(Singleton):
- 构造方法
private DBUtil()被私有化,防止外部通过new关键字创建多个实例。 dataSource被声明为private static,保证了整个应用程序中只有一个数据源实例。
- 构造方法
- 静态初始化:
- 使用
static { ... }代码块,在类加载到JVM时就执行数据源的初始化。这确保了数据源在第一次被使用前就已经准备就绪,并且这个初始化过程只会执行一次。
- 使用
- 静态方法:
getConnection()和close()都被声明为static,这样我们就可以直接通过类名调用(如DBUtil.getConnection()),而无需创建DBUtil的实例。
package org.example.utils;import com.mysql.cj.jdbc.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;/*** 数据库连接工具类 (采用单例模式)*/
public class DBUtil {// 数据源,整个应用共享一个实例private static DataSource dataSource = null;// 将数据库连接信息定义为常量private static final String URL = "jdbc:mysql://127.0.0.1:3306/java113?characterEncoding=utf8&allowPublicKeyRetrieval=true&useSSL=false";private static final String USER = "root";private static final String PASSWORD = "root";// 1. 私有化构造方法,防止外部创建实例private DBUtil() {}// 2. 使用静态代码块,在类加载时初始化数据源,且只执行一次static {MysqlDataSource mysqlDataSource = new MysqlDataSource();mysqlDataSource.setURL(URL);mysqlDataSource.setUser(USER);mysqlDataSource.setPassword(PASSWORD);dataSource = mysqlDataSource;}/*** 获取数据库连接* @return Connection对象* @throws SQLException*/public static Connection getConnection() throws SQLException {return dataSource.getConnection();}/*** 统一释放资源* @param resultSet 结果集 (可为null)* @param statement Statement或PreparedStatement对象 (可为null)* @param connection 连接对象 (可为null)*/public static void close(ResultSet resultSet, Statement statement, Connection connection) {// 采用从后往前的顺序关闭资源// 关闭结果集if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}}// 关闭Statementif (statement != null) {try {statement.close();} catch (SQLException e) {e.printStackTrace();}}// 关闭连接if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}
}
6.2 使用DBUtil实现数据插入
有了DBUtil工具类后,我们的业务代码就变得更加简洁和清晰了。InsertExample类不再关心如何创建连接和关闭资源的细节,只需调用DBUtil的静态方法即可。
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Scanner;public class InsertExample {public static void main(String[] args) {Connection connection = null;PreparedStatement statement = null;// 插入操作返回的是受影响的行数,所以不需要定义ResultSet对象。try {// 1. 通过工具类获取数据库连接connection = DBUtil.getConnection();// 2. 定义SQL模板,使用?作为占位符String sql = "insert into student (name, sno, age, gender, class_id) values (?,?,?,?,?)";// 3. 创建PreparedStatement对象statement = connection.prepareStatement(sql);// 4. 从控制台接收用户输入Scanner scanner = new Scanner(System.in);System.out.println("请输入学号:");String sno = scanner.next();System.out.println("请输入姓名:");String name = scanner.next();System.out.println("请输入年龄:");int age = scanner.nextInt();System.out.println("请输入性别(1-男/2-女):");int gender = scanner.nextInt();System.out.println("请输入班级编号:");int classId = scanner.nextInt();// 5. 使用用户输入的值填充SQL模板中的占位符statement.setString(1, name);statement.setString(2, sno);statement.setInt(3, age);statement.setInt(4, gender);statement.setInt(5, classId);// 6. 执行更新操作int row = statement.executeUpdate();// 7. 根据返回的行数判断操作是否成功if (row == 1) {System.out.println("插入成功!");} else {System.out.println("插入失败。");}} catch (SQLException e) {// 异常处理e.printStackTrace();} finally {// 8. 通过工具类统一释放资源DBUtil.close(null, statement, connection);}}
}
执行结果:

数据库验证: