【C++】C++ 的入门语法知识1
本文主要讲解C++语言的入门知识,包括命名空间、C++的输入与输出、缺省参数以及函数重载。
目录
1 C++的第一个程序
2 命名空间
1) 命名空间存在的意义
2) 命名空间的定义
3) 命名空间的使用
3 C++的输出与输入
1) C++中的输出
2) C++中的输入
4 缺省参数
1) 缺省参数的定义
2) 缺省参数的使用
5 函数重载
1) 函数重载所解决的问题
2) 函数重载的条件
6 总结
1 C++的第一个程序
C++语言是兼容C语言的,所以C语言的程序在C++语言的程序中依然适用,比如输出"hello world":
#include<stdio.h>int main()
{printf("hello world\n");return 0;
}所以用C语言定义的文件只需要将后缀由 .c 变为 .cpp,那么这个文件就会由C语言变到了C++语言。虽然在C++文件中,C语言也可以兼容,但是C++语言有自己的一套输入输出。在C++语言中,输出"hello world"应该这样输出:
#include<iostream>using namespace std;int main()
{cout << "hello world" << endl;return 0;
}相信大家一上来学习C++语言,肯定是看不懂这段代码的,接下来我们依次来讲解。
2 命名空间
1) 命名空间存在的意义
在 C 语言中,函数都是存在全局域的,然后如果在全局再定义一个同名变量,那么其是会发生命名冲突的,进而就会报错。如:
#include<stdio.h>
#include<stdlib.h>int rand = 10;int main()
{//编译报错:"rand"重定义printf("%d\n", rand);return 0;
}在上面的程序中,首先包含了一个 stdlib.h 头文件,然后头文件里有一个 rand() 函数,包含了之后会将头文件的内容全部展开在全局域里面,之后又在全局定义了一个全局变量 rand,此时全局域有一个 rand() 函数,又有一个 rand 变量,此时就发生了命名冲突,printf 函数里面的 rand 不知道是全局变量还是函数,所以是会编译报错的。
C++ 中为了解决命名冲突的问题,引入了一个命名空间的概念,命名空间上本质是定义出了一个独立的命名空间域,此域与全局域和局部域相互独立,不同域里面是可以定义相同名字的变量和函数的,此时就不会发生命名冲突了。
2) 命名空间的定义
定义一个命名空间需要一个关键字 namespace,定义命名空间如下:
namespace 命名空间名
{}首先加一个命名空间关键字 namespace,然后在后面加上想要定义的名字,后面跟一对{},然后就可以在里面定义函数或者变量了,如在 L 命名空间里定义一个 rand 变量:
namespace L
{int rand = 10;
}命名空间存在的本质就是为了产生一个新的域,使其与全局域和局部域进行区分。此时 rand 变量就会存在在 L 命名空间里面,那么就不会与全局域中的 rand() 函数起冲突了,所以以下代码是可以编译通过的:
#include<stdio.h>
#include<stdlib.h>namespace L
{int rand = 10;
}int main()
{printf("%d\n", rand());return 0;
}运行结果:
定义命名空间时,需要有几个注意事项:
(1) C++中共有4个域:全局域、局部域、命名空间域、类域。域影响的是一个变量或者函数的查找规则(在C语言中默认现在局部域查找,局部域查找不到,再去全局域查找),所以命名就不会冲突了。但是全局域和局部域还会影响变量的生命周期(局部域里的变量出了函数就销毁了),命名空间域和类域不会影响生命周期。
(2) namespace 只能定义在全局,也可以嵌套定义。
(3) C++ 标准库都放在一个名叫 std 的命名空间中。
(4) 如果想要访问命名空间中的变量或者函数,需要一个操作符 ::(域访问限定符)。
(5) 不同文件的相同命名空间里的变量和函数会合并到一个命名空间中。
(4) 域访问限定符:
#include<stdio.h>
#include<stdlib.h>namespace L
{int rand = 10;int Add(int x, int y){return x + y;}struct Node{struct Node* next;int data;};
}int main()
{printf("%d\n", rand());//突破命名空间域访问,需要加::printf("%d\n", L::rand);printf("%d\n", L::Add(1, 2));//访问命名空间域中的类型是在名字前面加上::,而不是在类型前加上::struct L::Node* node = (struct L::Node*)malloc(sizeof(struct L::Node));return 0;
}如果在 namespace 里面有自定义类型的话,是需要在名字前面加上 :: 的,而不是在 struct 前加 :: 的,因为命名空间限定的是名字,并不是类型(其实这里的Node就可以是类型了,只不过这里不叫结构体了,而是类,在类与对象章节会进行讲解)。
(2) namespace 只能定义在全局,且可以嵌套定义
#include<stdio.h>
#include<stdlib.h>//命名空间可以嵌套定义
namespace L
{namespace T{int rand = 1;int Add(int x, int y){return x + y;}}
}int main()
{//访问的时候要依次突破命名空间域printf("%d\n", L::T::rand);printf("%d\n", L::T::Add(1, 2));return 0;
}3) 命名空间的使用
命名空间的使用共有三种方式:
a. 直接展开所有命名空间,需要使用 using 关键字,如:using namespace std。
b. 只将命名空间中的某个成员展开,也需要使用 using 关键字,比如展开 L 命名空间中的 rand 变量:using L::rand。
c. 指定命名空间访问,如使用 L 中的 rand 变量,L::rand。
当然,3种使用方式有好有坏, 平常练习的时候可以使用第一种方式,在项目中不推荐使用第一种方式,因为展开的所有的命名空间,就相当于将命名空间中的所有函数与变量暴露在全局,所以是非常容易出现命名冲突的;对于第二种方式,项目中经常访问的不存在冲突的成员推荐使用这种方式;在项目中最推荐使用的就是第三种方式了,第三种方式是最不会出现命名冲突的。
#include<stdio.h>namespace L
{int a = 0;int b = 10;
}void Test01()
{//指定命名空间访问printf("%d\n", L::a);
}//展开某个命名空间成员
using L::a;
void Test02()
{printf("%d\n", a);
}//展开所有命名空间
using namespace L;
void Test03()
{printf("%d\n", b);
}int main()
{Test01();Test02();Test03();return 0;
}在上面那段代码里面,首先展开了 L 中的 a 成员,在后面又展开了 L 整个命名空间,这样看来,应该引入了两次 a 变量,是会发生命名冲突的,但是编译器是会对这种情况做特殊处理的,对于重复引入同一个变量的情况,是不会报错的。
3 C++的输出与输入
在讲解C++的输入与输出之前,我们先来简单了解一下 iostream 库以及 endl 函数。
iostream库:
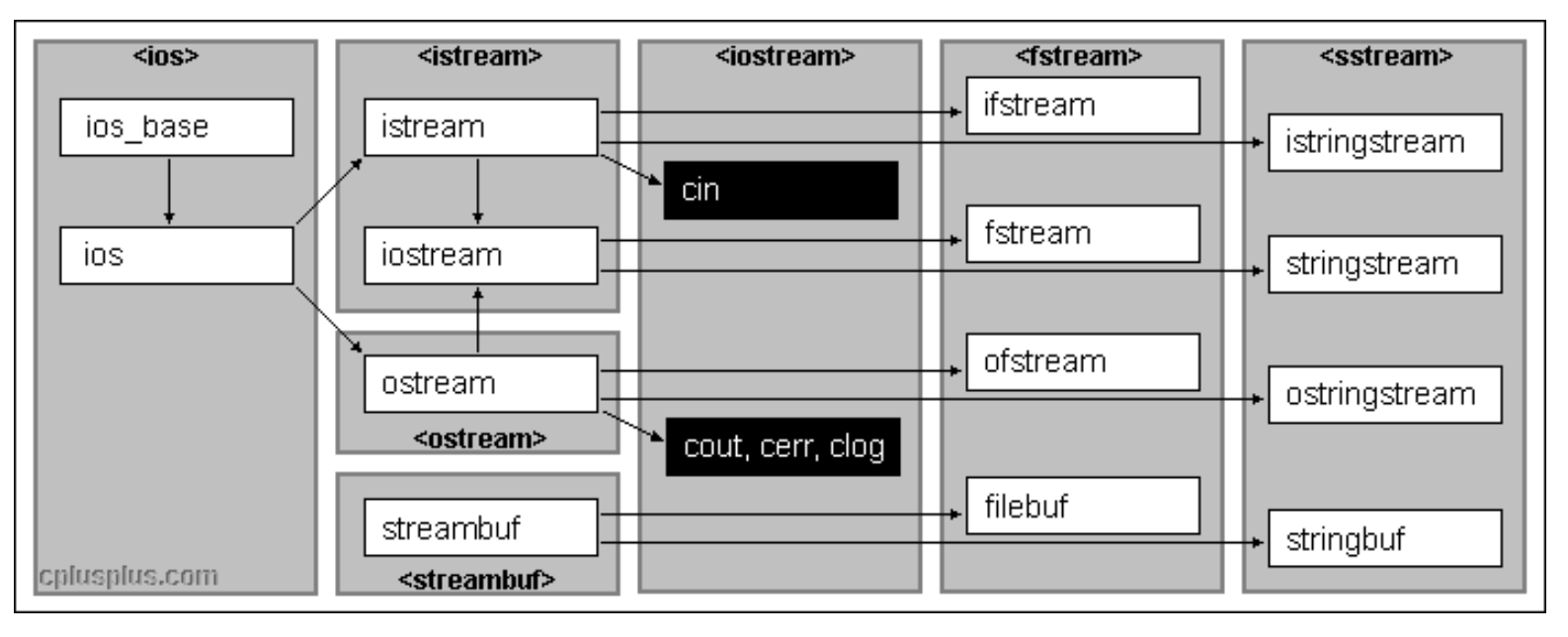
iostream 是Input Output Stream(标准输入输出流库)的缩写,其中涉及了许多知识,包括继承等等,不过现在我们只需要了解 cin 和 cout 即可。
通过上图,我们可以看到 iostream 中包含 cin、cout、cerr、clog,cin 来源于 isream,cout 来源于 ostream(其实 istream 和 ostream 是C++标准库中定义的类,cin 和 cout 是这两个类的对象),cin 主要用于输入,cout 主要用于输出。
endl 函数:
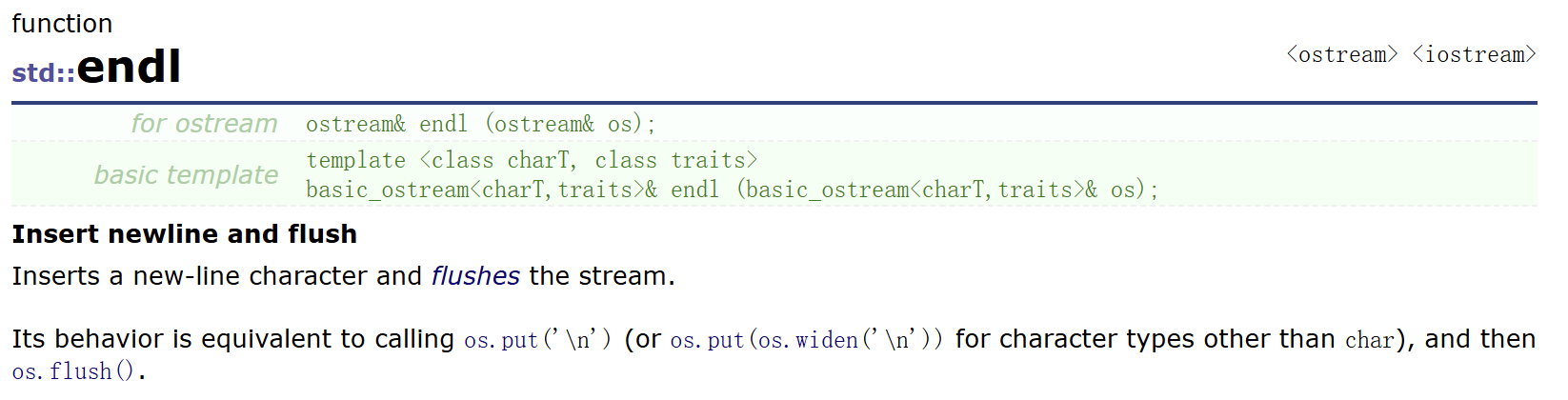
通过上图可以看到,endl 其实是一个函数,其参数是一个 ostream类型对象,返回值也是一个 ostream 类型的引用(这里看不懂没关系,等学完引用与类和对象后自然就懂了);再通过下面的解释,可以看到其行为就等于调用了ostream类 os 对象的 put 函数,实际上就相当于输出了一个 '\n' 字符,也就是执行了一个换行。所以在C++中如果想要换行,我们一般不会使用 '\n' 转义字符,而会使用 endl 函数来执行换行操作。
1) C++中的输出
在上面了解了 iostream 库与 endl 之后,我们知道了输出需要用到一个 ostream 类的对象 cout,所以在使用 cout 之前,我们需要先包含一个头文件 iostream,也就是引入 iostream 这个类,使得我们可以使用这个类实例化的一个对象 cout。在输出之前,我们还需要了解一个运算符叫做流插入运算符:<<。这个运算符的作用可以形象化的理解为会将要输出的对象流入 cout 中,然后 cout 帮你把对象打印在屏幕上。比如输出完 "hello world" 之后打印一个换行:
#include<iostream>using namespace std;int main()
{cout << "hello world";cout << endl;return 0;
}这里有一个需要注意的点,就是C++中的标准库都被封在了 std 的命名空间里面,要想使用C++中类和对象是需要展开命名空间 std 的,当然你也可以指定命名空间访问或者展开具体成员:
#include<iostream>//指定命名空间
int main()
{std::cout << "hello world";std::cout << std::endl;return 0;
}//展开具体成员
using std::cout;
using std::endl;
int main()
{cout << "hello world";cout << endl;return 0;
}但是C++中的 cout 与C语言中的 printf 最大的区别,也是我认为 cout 更加好用的一点是:cout 不用指定占位符,且可以连续输出不同的类型的对象(本质是函数重载,后面讲解完函数重载会更好理解)。如:
#include<iostream>using namespace std;int main()
{int x = 1;double y = 2.2;char ch = 'x';cout << "hello world" << ' ' << x << ' ' << y << ' ' << ch << endl;return 0;
}运行结果:
hello world 1 2.2 x2) C++中的输入
C++ 中的输入需要用到 istream 类的对象 cin,同样的在使用之间需要包含头文件 iostream 与展开命名空间 std、指定命名空间或者展开具体成员。与 cout 类似,在使用 cin 时,需要用到流提取操作符:>>,这个运算符可以形象化的理解为将屏幕中输入的值先交给 cin,cin 再通过 >> 将数据流入变量中,所以这里不需要对变量取地址的。同样,cin 也支持连续输入,如:
#include<iostream>using namespace std;int main()
{int x;double y;char ch;cin >> x >> y >> ch;cout << x << ' ' << y << ' ' << ch << endl;return 0;
} 运行结果:
输入:1 2.2 x
输出:1 2.2 xcin 还可与 scanf 函数一样判断是否输入结束,但是 scanf 是通过返回值来判断的,如果读取成功,会返回读取成功的占位符个数,如果读取失败会返回 EOF,而 cin 是通过一个 operator bool() 的重载函数来实现的(这里可能难以理解,等后面仔细讲解完 iostream 类之后会比较容易理解),用法就是当读取成功时会返回 true,读取失败会返回 false。如:
#include<iostream>using namespace std;int main()
{int x = 0;while (cin >> x){cout << x << ' ';}return 0;
}运行结果:
输入:1 2 3 4 ctrl + z
输出:1 2 3 44 缺省参数
1) 缺省参数的定义
缺省参数也叫做默认参数,是在定义或者声明的时候给的参数的默认值。如果在调用参数的时候,不传递实参的话,就会默认使用缺省值,如果传递实参的话,就会使用传递的实参。
缺省参数分为全缺省与半缺省参数。全缺省就是所有的形参都给缺省值,半缺省就是部分形参给缺省值。
2) 缺省参数的使用
在参数中给默认参数的时候,需要遵循以下语法规则:
(1) 缺省参数必须从右向左连续缺省,不能跳跃给缺省值。
(2) 调用带缺省参数的函数,必须从左向右依次给实参,不能跳跃传参。
(3) 函数声明与定义分离时,只能在声明给缺省值,不能在定义给缺省值。
全缺省与半缺省:
#include<iostream>using namespace std;//缺省参数只能从右向左连续缺省
//半缺省
void Func1(int a, int b = 10, int c = 20)
{cout << a << ' ' << b << ' ' << c << endl;
}//全缺省
void Func2(int a = 10, int b = 20, int c = 30)
{cout << a << ' ' << b << ' ' << c << endl;
}int main()
{//不传参时默认使用缺省值Func1(10);Func2();//传参只能由左向右依次传参,不能跳跃传参//错误的//Func1(10, , 20);//正确的Func1(10, 20);return 0;
}运行结果:
输出:
10 10 20
10 20 30
10 20 20
声明与定义分离,只能在声明时给缺省值:
#include<iostream>using namespace std;//只能在声明时给缺省值
void Func(int a = 10, int b = 20, int c = 30);//定义不能给
void Func(int a, int b, int c)
{cout << a << ' ' << b << ' ' << c << endl;
} int main()
{ Func();return 0;
}运行结果:
输出:10 20 305 函数重载
函数重载是C++语言中一个特别重要的语法,在以后的讲解的类和对象以及STL中经常使用。
1) 函数重载所解决的问题
在 C语言中,同一作用域里是不能定义同名函数的,如要实现交换函数:
#include<stdio.h>void swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}void swap(double* x, double* y)
{double tmp = *x;*x = *y;*y = tmp;
}int main()
{int x = 10, y = 20;swap(&x, &y);double a = 1.1, double b = 2.2;swap(&a, &b);return 0;
}这种情况在C语言里是会报错的,但是在C++里面就不会报错了,函数重载就是为了解决同名函数的问题。
2) 函数重载的条件
两个函数如果想要构成函数重载,只需要一个条件,那就是两个函数参数不同,可以是参数个数不同或者类型不同。如:
#include<iostream>using namespace std;//1. 函数参数类型不同构成函数重载
int Add(int x, int y)
{cout << "Add(int x, int y)" << endl;return x + y;
}double Add(double x, double y)
{cout << "Add(double x, double y)" << endl;return x + y;
}//2. 函数参数个数不同构成函数重载
int Add(int x, int y, int z)
{cout << "Add(int x, int y, int z)" << endl;return x + y + z;
}//3. 函数参数类型顺序不同构成函数重载
void func(int x, double y)
{cout << "func(int x, double y)" << endl;
}void func(double x, int y)
{cout << "func(double x, int y)" << endl;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1.1, 2.2) << endl;cout << Add(1, 2, 3) << endl;func(1, 2.2);func(2.2, 1);return 0;
}运行结果:
输出:
Add(int x, int y)
3
Add(double x, double y)
3.3
Add(int x, int y, int z)
6
func(int x, double y)
func(double x, int y)函数重载,之所以能够构成函数重载,本质原因就是因为编译器能够通过参数去调用对应的函数,因而表现出了多态行为,所以不会因为命名相同而发生调用冲突。所以返回值不同是不构成函数重载的,因为编译器不知道去调用哪个函数:
#include<iostream>using namespace std;//函数返回值不同不构成函数重载
void func()
{cout << "void func()" << endl;
}int func()
{cout << "int func()" << endl;
}int main()
{//编译器不知道去调用哪个函数func();return 0;
}有了函数重载的相关知识,大家看下面这两个函数构不构成函数重载呢?
#include<iostream>using namespace std;void func()
{cout << "func()" << endl;
}void func(int a = 10)
{cout << "func(int a = 10)" << endl;
}int main()
{func(1);func();return 0;
}其实是构成函数重载的,因为两个 func 的参数个数不同,也就是参数不同,所以是可以构成函数重载的。但是有一个致命的缺陷,就是如果调用的是无参版本的 func 函数,编译器就会不知道去调用哪一个,因而会发生报错,这里的报错并不是因为函数重载的语法错误,而是因为编译器不知道去调用哪一个函数。
但是遇到这种情况,我们一般都会选择使用下面有缺省值的版本,因为写上面那个函数,就是为了无参也能调用函数,而下面那个函数因为有缺省值,所以无参也是可以调用的,而且还有缺省值,所以会选择下面的版本。
6 总结
以上我们讲解了C++中的一些基础的语法知识,虽然不是很难,但是是后面学习类和对象以及STL的基础,所以一定要认真学习,熟练掌握。当然我们也会结合后面具体的使用场景来继续加深对这些语法知识的理解。