讲座|人形机器人多姿态站起控制HoST及宇树G1部署


目的:基于learnningbase 不需要依赖于预定义好的轨迹(No Predefined Motion),并且具有human size,High DoF,Posture Diversity
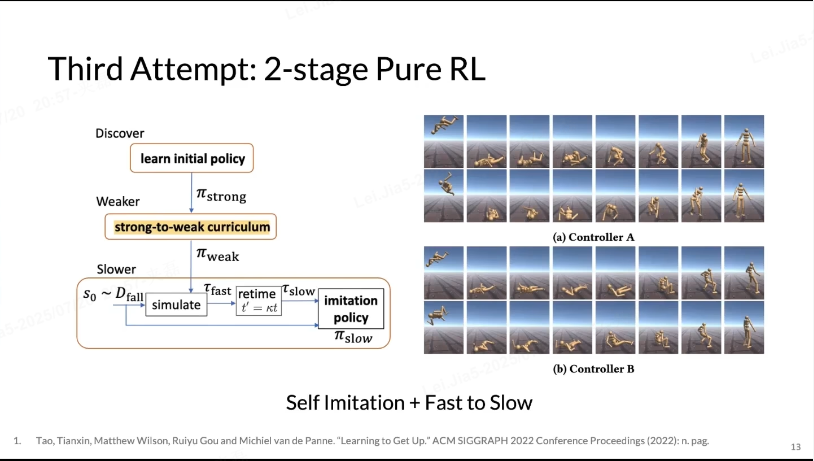
把剧烈运动进行了2阶段分解,但是第一阶段无法学到比较‘优雅’的policy
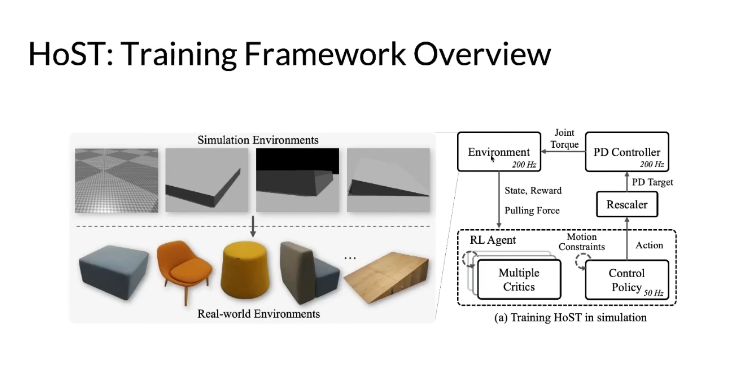
Framework Overview
Challenge1:violent and osillatory motion剧烈且抖动 motion
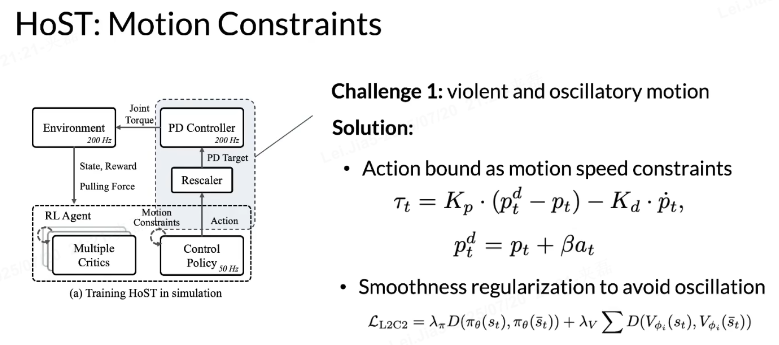
action bounds 和 scaler
- 动作边界约束(结合 PD 控制器公式 );

- 平滑正则化(L₂C₂损失函数 )。

- 动作边界 + PD:给 RL 的 “激进指令” 套上 “减速带”,让控制器的目标更温和,避免 “猛踩油门 / 刹车”;
- 平滑正则化:给 RL 的 “决策逻辑” 加上 “记忆”,让动作变化更连贯,避免 “朝三暮四”。
两者结合,就能让机器人(或智能体)的运动从 “抽风式乱动” 变成 “稳稳当当的可控运动”。
Challenge2:要是把motion speed限制的非常小,RLAgent探索非常难.所以需要“trade-off” 指 “权衡取舍”(两者间需平衡,优化一方往往以牺牲另一方为代价)。“探索新策略(exploration)” 和 “运动速度(motion speed)” 无法同时最优:
- 想多探索(让智能体试新动作)→ 动作可能很激进 → 运动容易失控(速度、姿态乱套);
- 想稳速度(动作平缓)→ 探索不足 → 学不到更优策略。
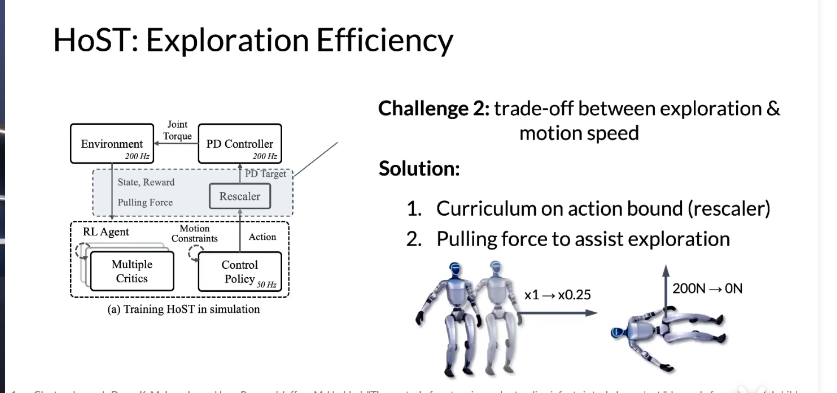
- 动作边界课程学习(Rescaler):逐步放宽动作幅度限制(如从 “动作幅度 ×1” 过渡到 “×0.25” ,让智能体先稳后大胆探索);
- 拉力辅助探索:训练初期施加外力(如图示 “200N→0N” ,类似 “辅助轮”,帮智能体保持姿态,逐步撤力自主探索)。
Challenge3:奖励设计繁琐(需协调多目标) + 策略优化难,由于站起这个动作是whole body且与地形接触
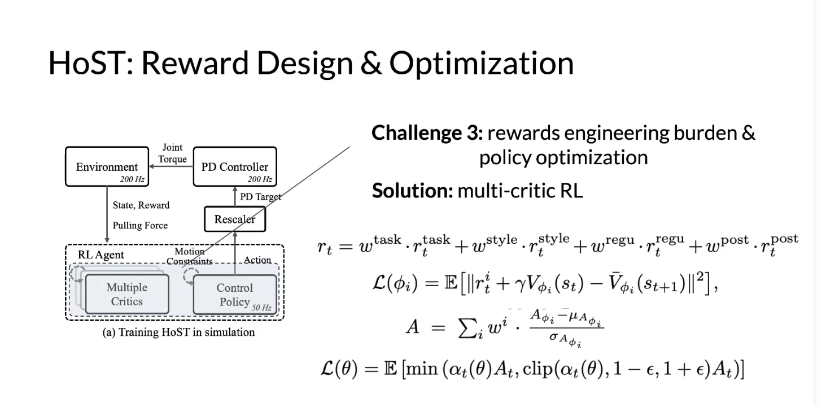
Task Reward Style Reward Regulariation Reward Post-task Reward
- 任务奖励(Wtask=2.5):定义起身核心目标(头部高度、基座朝向);
- 风格奖励(Wstytle=1):约束关节角度 / 姿态,规范起身动作;
- 正则奖励(Wregu=0.1):惩罚剧烈运动(加速度、力矩突变等),保障平稳;
- 任务后奖励(Wpost=1):起身成功后,约束基座运动 / 姿态,维持稳定。
- 奖励拆分:总奖励 = 任务、风格、正则、后任务奖励的加权和(w 为权重);
- 优化:通过多评价器损失和策略损失,平衡多目标,降低奖励设计成本。
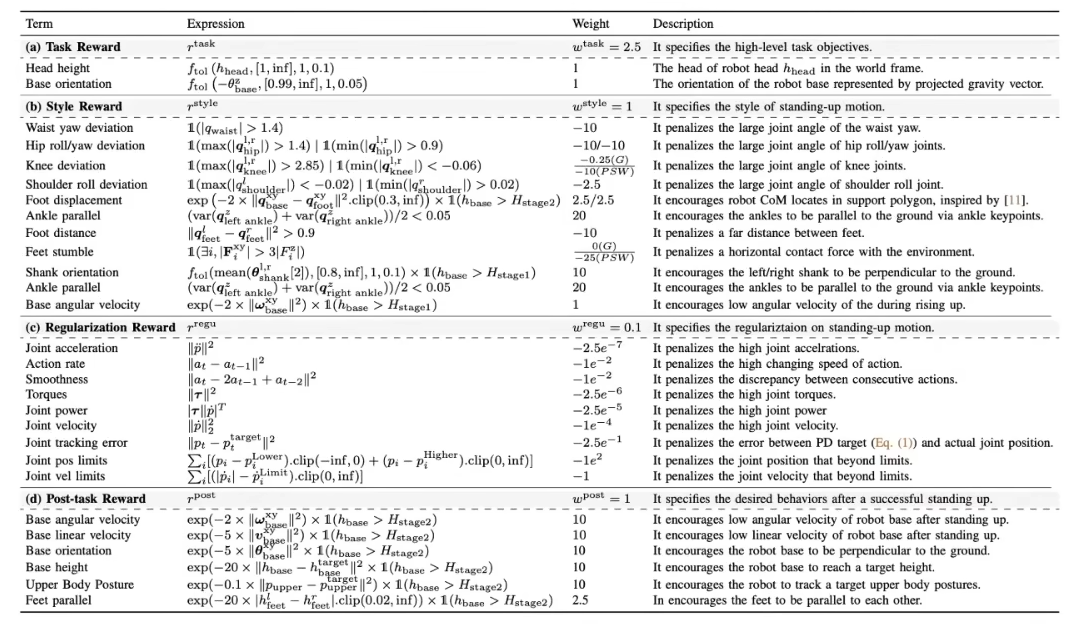
Challenge4:Sim-to-Real Transfer
评估指标维度:1)success rate 2)feet movement 3)smoothness 4)energy
Comparison methods 1)crtitics 2)exploration strategies 3)motion constraints 4)histrory length
真机轨迹观测 和 仿真轨迹观测 发现脚踝轨迹diff很大,最后用宇树官方脚踝的几个point进行仿真
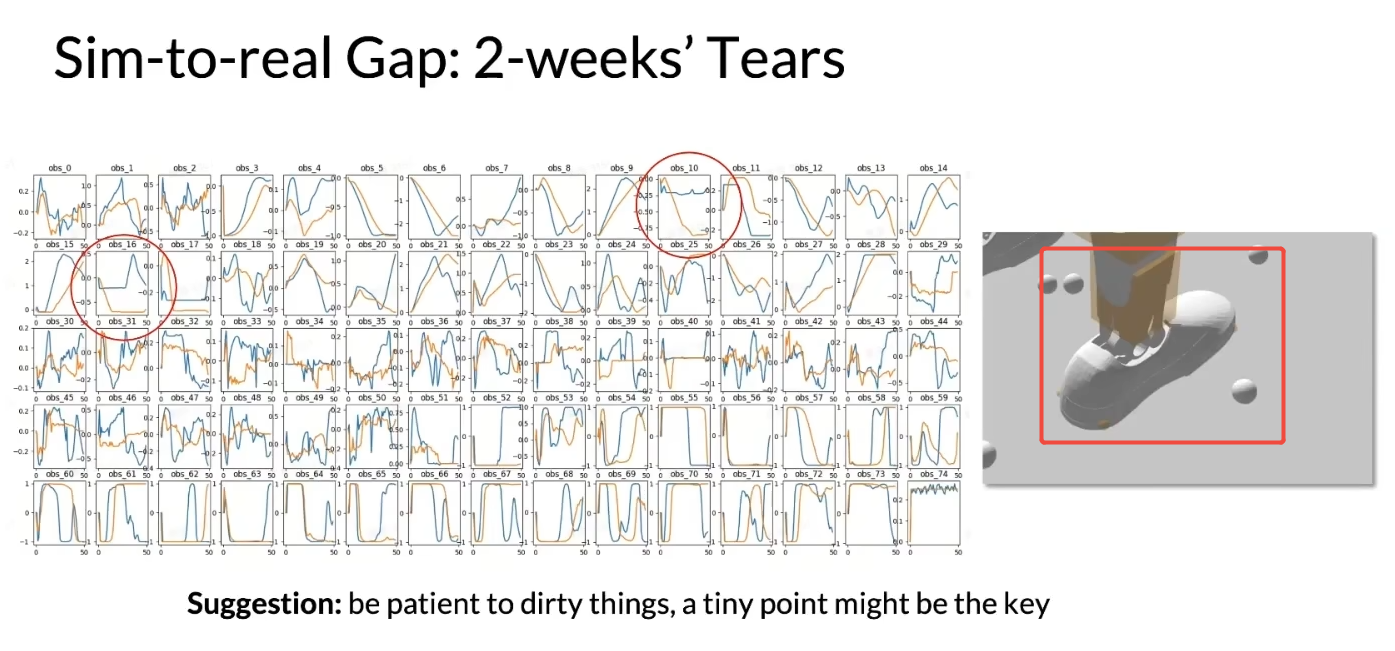
Suggestion:be patient to dirty things,a tiny point might be the key

1. Domain Randomization(领域随机化)
- 定义:仿真中故意随机改变环境 / 模型参数(如摩擦、质量、光照),让策略适应真实世界的不确定性。
- 举例:
仿真训练机器人走路时,随机让地面摩擦系数在 0.3~0.8 之间变化。这样,机器人不会只 “学懂” 某一种地面(比如光滑瓷砖),真实世界里不管是塑胶跑道(摩擦高)还是冰面(摩擦低),都能走稳。
2. CoM Offset(质心偏移)
- 定义:机器人质心(Center of Mass,CoM) 的实际位置与仿真假设位置的偏差(因零件误差、装配偏差等导致)。
- 举例:
仿真里假设机器人质心在身体正中间,但真实机器人因电池安装偏左,质心实际左移 2cm。如果仿真没考虑这种偏移,训练出的 “起身策略” 会让机器人往左边倒(因为质心计算错误,平衡控制失效)。
3. Torque Noise(力矩噪声)
- 定义:仿真中给关节力矩添加随机干扰,模拟真实电机的力矩输出误差(比如电机老化、电压波动导致力矩不准)。
- 举例:
仿真里让关节力矩随机 ±5% 波动(比如指令力矩是 10N・m,实际输出 9.5~10.5N・m)。训练出的策略会 “预留冗余”,即使真实电机力矩不准,机器人仍能稳定控制动作(比如走路时步幅不会突然失控)。
4. Control Delay(控制延迟)
- 定义:仿真中模拟真实系统的信号延迟(如传感器数据传输、控制器计算的时间差)。
- 举例:
真实机器人的控制指令需要 50 毫秒 才能执行(传感器→控制器→电机的延迟)。仿真里加入这 50ms 延迟,训练出的策略会 “提前预判”(比如更早调整关节力矩),避免延迟导致的动作滞后(比如本该及时刹车,却因为延迟摔倒是非)。
结论:CoM offset is important(质心偏移很重要)
对比实验中,“w/o CoM Offset(没补偿质心偏移)” 的机器人更容易摔倒 / 动作变形(如图中右上角组,机器人起身时歪倒)。这说明:
仿真必须准确建模 质心偏移,否则训练出的策略迁移到真实机器人时,会因质心计算错误导致平衡失控,无法完成任务(如起身、走路)。

与站起来相关的四个关节,仿真与真实机器人的 关节运动轨迹一致(相位图趋势重合),但 真实关节输出力矩不足(硬件或环境限制导致力矩未达仿真预期),结果:真机Kp弥补仿真中力矩不足,
1)缺少实时环境的感知
2)需要more diverse postures 缺少类似趴下来站起的姿态
3)未融合到现在humanoid systems
其他文章:

Takeaways:
Reward engineering is importang,but not all
Be patient to sim-to-real analysis
Be kind to the robot 优雅动作