Thread 类
目录
1、创建线程
2、Thread的常见构造方法
3、Thread的几个常见属性
4、启动一个线程 - start()
5、中断(终止)一个线程
1、创建线程
方法1:继承 Thread 类,重写 run(上节讲了)
方法2:实现 Runnable 接口,重写 run
1. 实现 Runnable 接口
2. 创建 Thread 类实例,调用Thread 的构造方法时将 Runnable 对象作为target参数
3. 调用 start 方法


说明:
1. Runnable 对象,表示一个 “可以执行的任务",就是一段要执行的代码,最终还是要通过 Thread 真正创建线程;把线程里要执行的代码,通过 Runnable 来表示,而不是通过直接重写 Thread run来表示
2. 和直接重写 Thread run 的区别,是看线程要执行的任务的定义,是需要放到 Thread 里面,还是放到外面(Runnable)
3. 把要执行的逻辑单独放到 Runnable 里,目的是为了解耦合。让要执行的任务本身,和线程这个概念,能够解耦合,从而后续如果变更代码,采用 Runnable 这样的方案,代码的修改会更简单(比如不通过线程执行这个任务,通过线程池、协程等其他方式)
4. 耦合:两个代码的关联越大,耦合就越大。我们不希望见到耦合太高,高耦合不利于修改代码,改一个代码可能会改坏一片
5. 内聚:一个项目中,有很多代码,有很多文件很多类,把有关联的各种代码,放到一起,只要和某个功能逻辑相关的东西,都放在这一块,这就是高内聚。如果某个功能的代码,这一块那一块,就是低内聚
6. 编写代码的基本原则:高内聚(一个模块之内,有关联的东西放一起),低耦合(模块之间,依赖尽量小,影响尽量小)
方法三(推荐):使用匿名内部类(本质上就是方法一 )

匿名内部类:Thread t = new Thread() { }
1. 创建了一个 Thread 的匿名子类
2. { } 里可以编写子类的定义代码(属性、方法、重写方法)
3. 创建了这个匿名内部类的实例,并且把实例的引用赋值给 t
一般如果某个代码是 “一次性” 的,就可以使用匿名内部类的写法,这样就可以少定义一些类了
方法四:使用 Runnable,匿名内部类
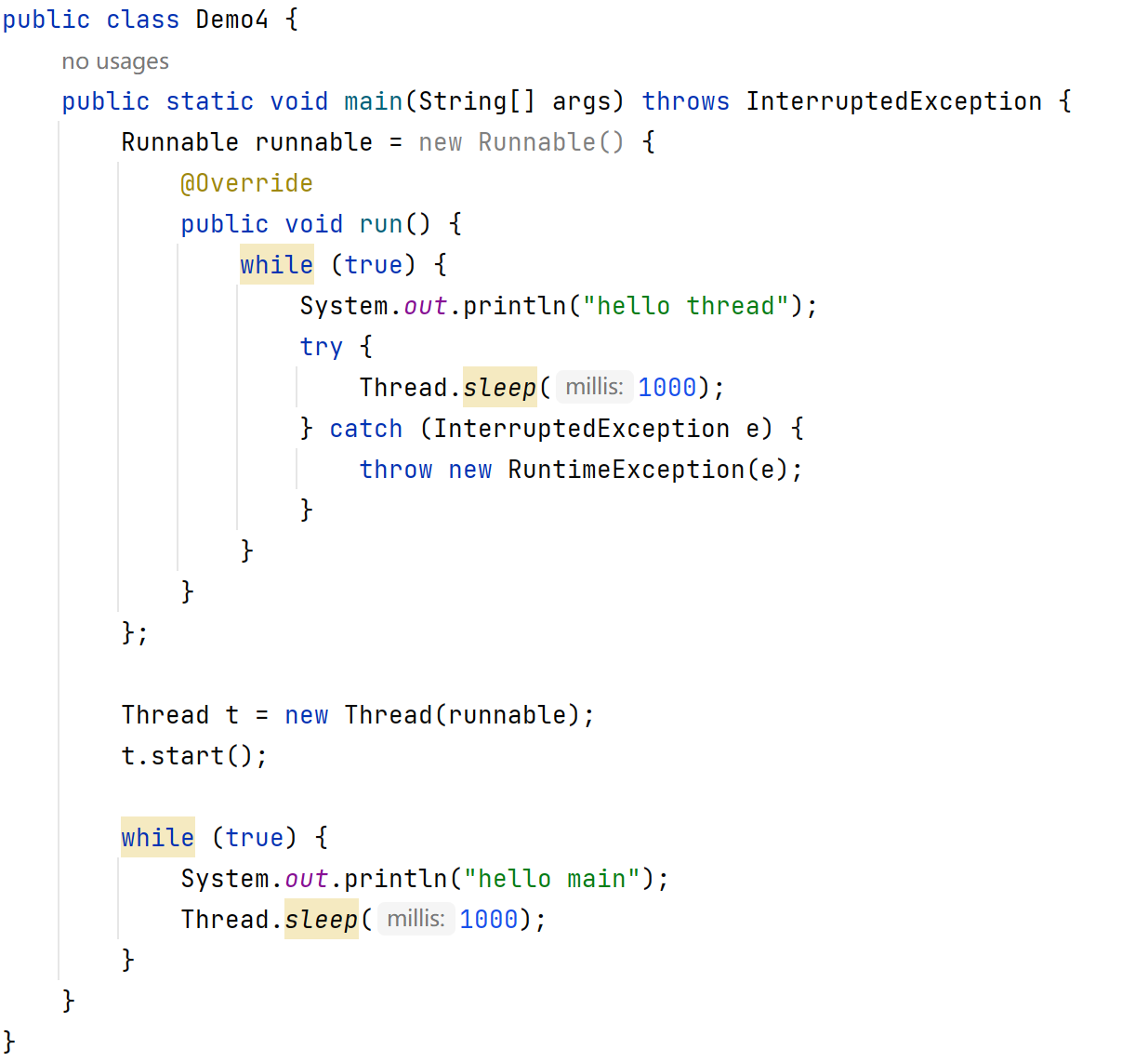
方法五:lambda表达式创建 Runnable 子类对象(针对三和四进一步改进)
lambda表达式本质上就是一个 “匿名函数”,最主要的用途,就是作为 “回调函数”

2、Thread的常见构造方法
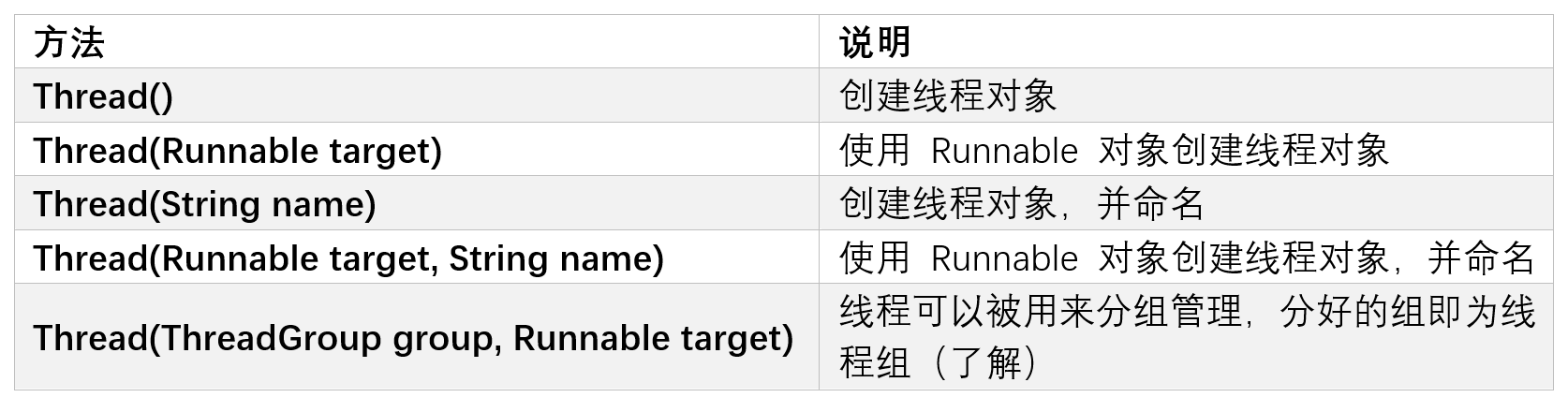
说明:
1. 使用不带参数的构造方法,必须要重写 Thread的 run 方法
2. 第三第四个构造方法,name 参数表示当前线程的名字,具体是什么样的名字,不影响线程的执行。命名的意义,就是通过名字描述线程,方便程序员调试
public class Demo6 {public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {while (true) {System.out.println("hello 1");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}},"t1");t1.start();Thread t2 = new Thread(() -> {while (true) {System.out.println("hello 2");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}},"t2");t2.start();Thread t3 = new Thread(() -> {while (true) {System.out.println("hello 3");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}},"t3");t3.start();}
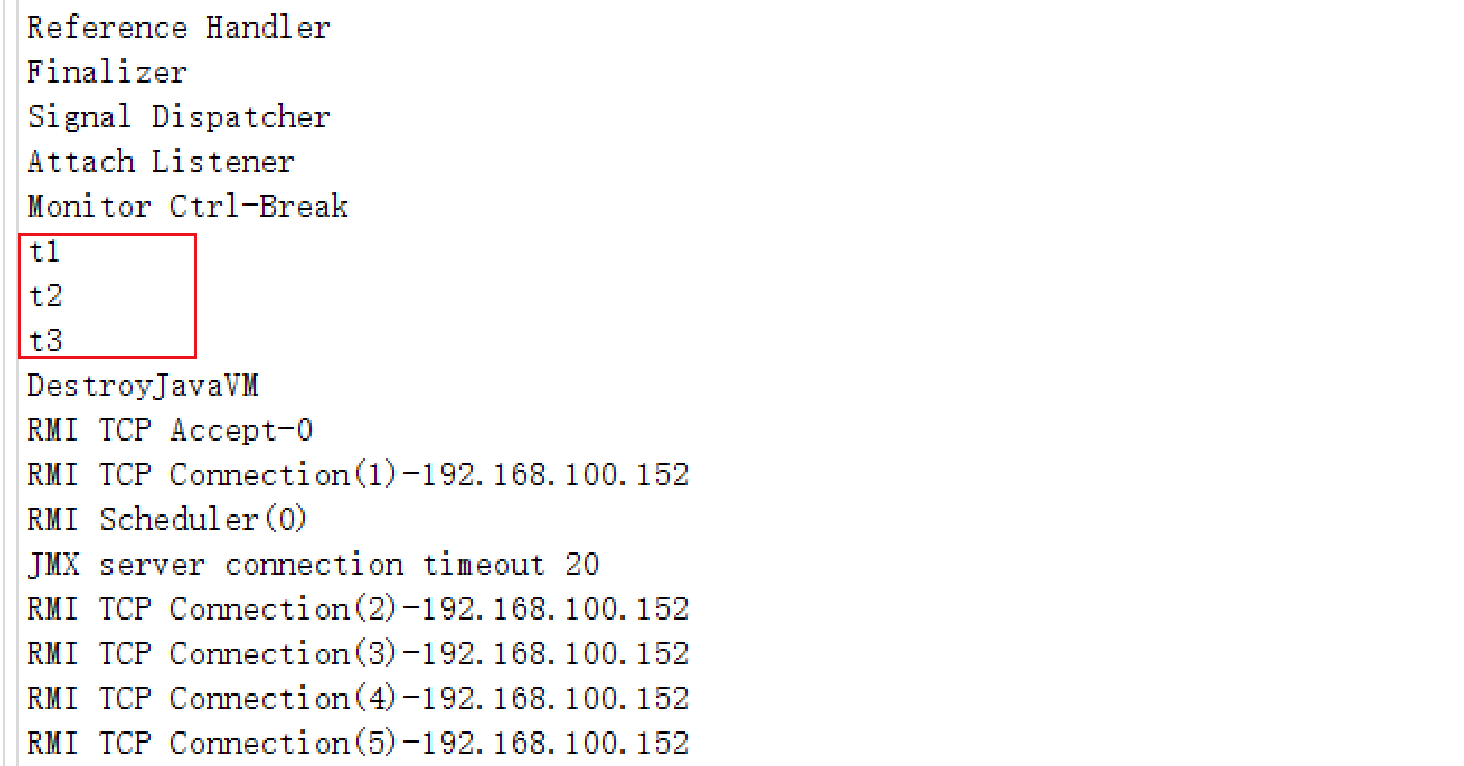
}上述代码中有 t1、t2、t3 三个线程,使用工具查看:
上图中,少了 main 线程。不是没有,是 main 方法在创建完 t1、t2、t3 三个线程后,就执行完毕了,main 方法执行完毕,主线程就结束了。
在以前,main方法执行完,程序就结束了(进程)。实际上,以前是只针对单线程程序的
前台线程:main 线程虽然结束了,但是 t1,t2,t3 还在,所以进程仍然存在,这样的线程,就称为 “前台线程”
后台线程:上图中除了 t1,t2,t3,其他的线程都是JVM自带的线程,他们的存在不影响进程结束(即使他们继续存在,如果进程要结束了,他们也随之结束了),这样的线程,就称为 “后台线程”
3、Thread的几个常见属性

1. ID 是线程的唯一标识,不同线程不会重复,类似 PID
2. 名称在各种调试工具能用到
3. 状态表示线程当前所处的一个情况
4. 优先级高的线程理论上来说更容易被调度到
5. 关于后台线程,需要记住一点:JVM会在一个进程的所有非后台线程结束后,才会结束运行。
Daemon:守护,守护线程 = 后台线程
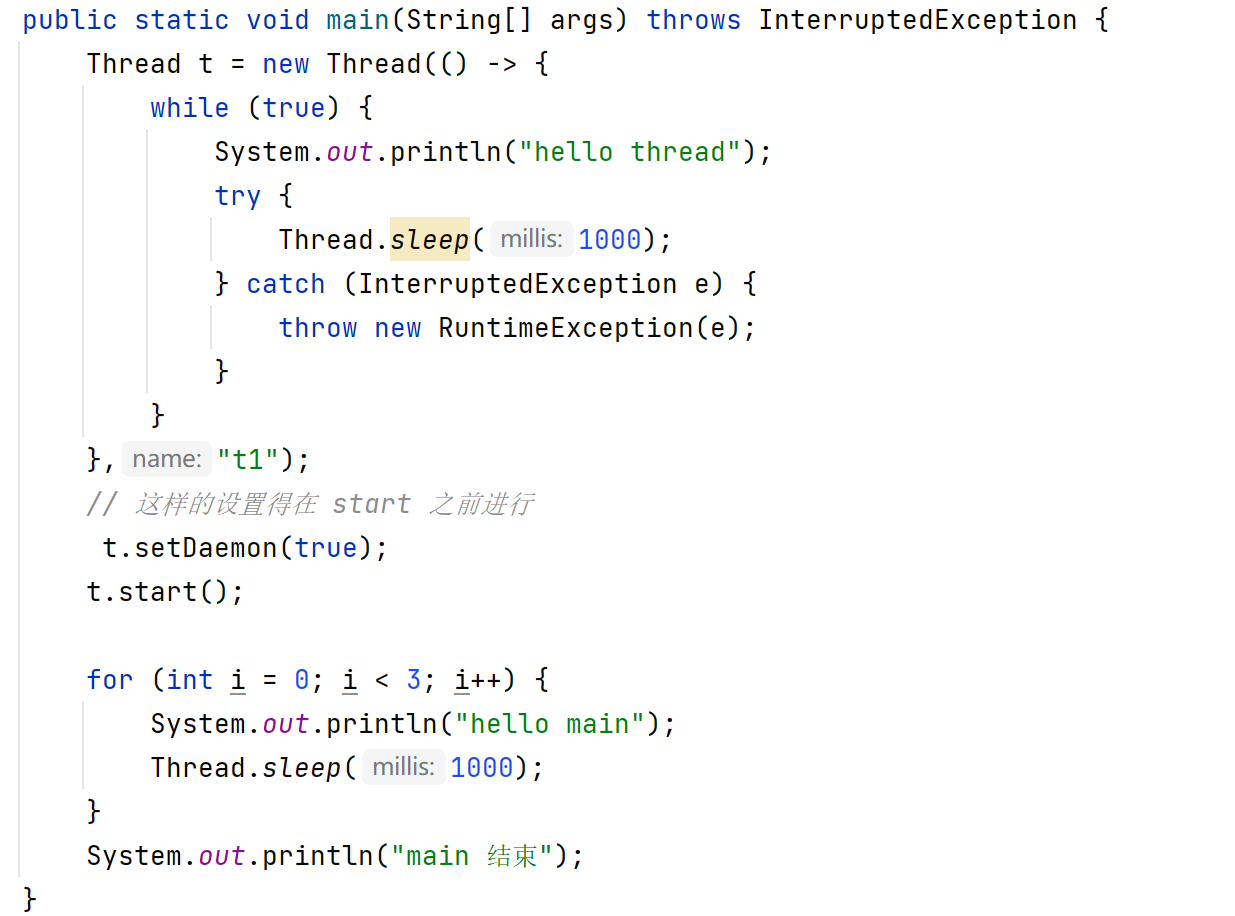
自己写的代码创建的线程,包括 main 主线程默认都是前台线程,可以通过 setDaemon 方法来修改,但必须在 start 之前修改
例如:
把 t1 这个线程设为了后台线程,它无力阻止进程结束

6. 是否存活,即简单的理解为run方法是否运行结束了
public class Demo8 {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {for (int i = 0; i < 3; i++) {System.out.println("hello thread");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}});// 这个结果一定是 false.// 此时还没有调用 start, 没有真正创建线程.System.out.println(t.isAlive());t.start();while (true) {System.out.println(t.isAlive());Thread.sleep(1000);}}
}线程的入口方法执行结束,系统中对应的线程就随之销毁了,但 t 引用的 Thread 对象仍然存在
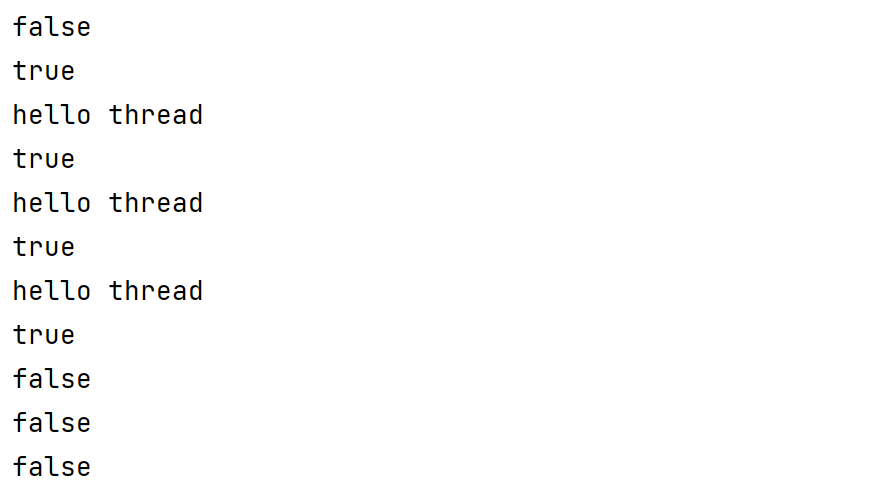
4、启动一个线程 - start()
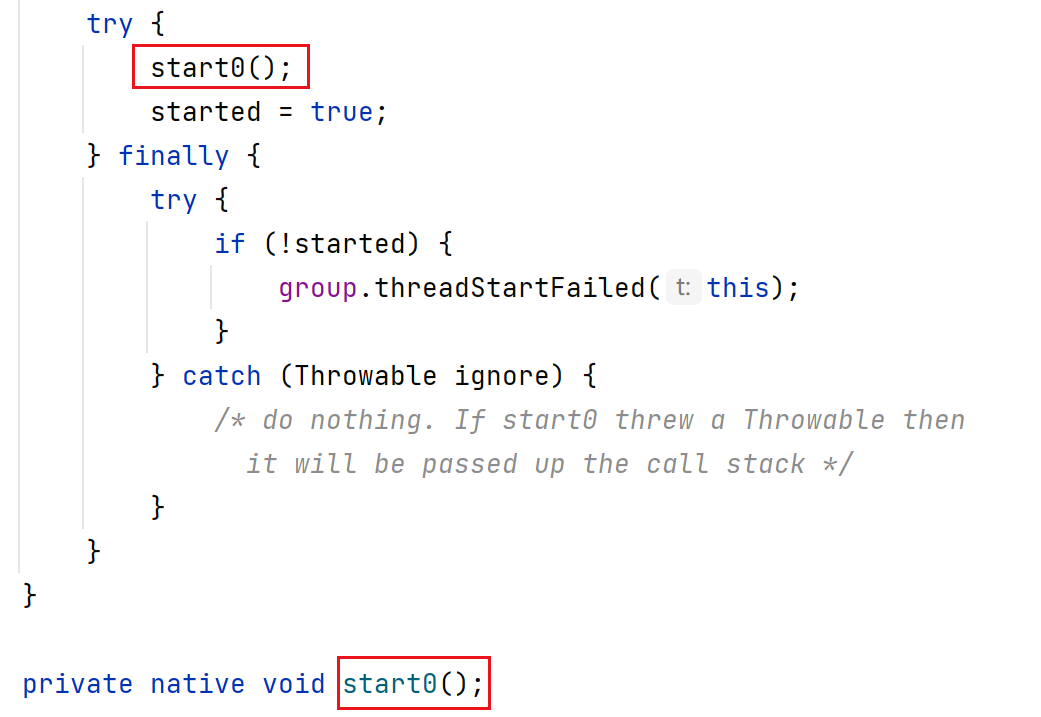
1. start() 是Java标准库 / JVM提供的方法,本质上是调用操作系统的 API
start 底层代码:
带有 native 的方法,是本地方法,其实现是在JVM内部,通过C++代码来实现的
2. Java 中期望,Thread对象和操作系统中的线程是一一对应的,所以每个Thread对象,都只能 start 一次。每次想创建一个新的线程,都要创建一个新的 Thread 对象(不能重复利用)
3. start 和 run 的区别:run是线程的入口方法,不需要手动调用;start是调用系统 api
4. 调用start方法,才真的在操作系统的底层创建出一个线程
5、中断(终止)一个线程
让线程的入口方法执行完毕,线程就随之结束了(run 方法尽快 return)
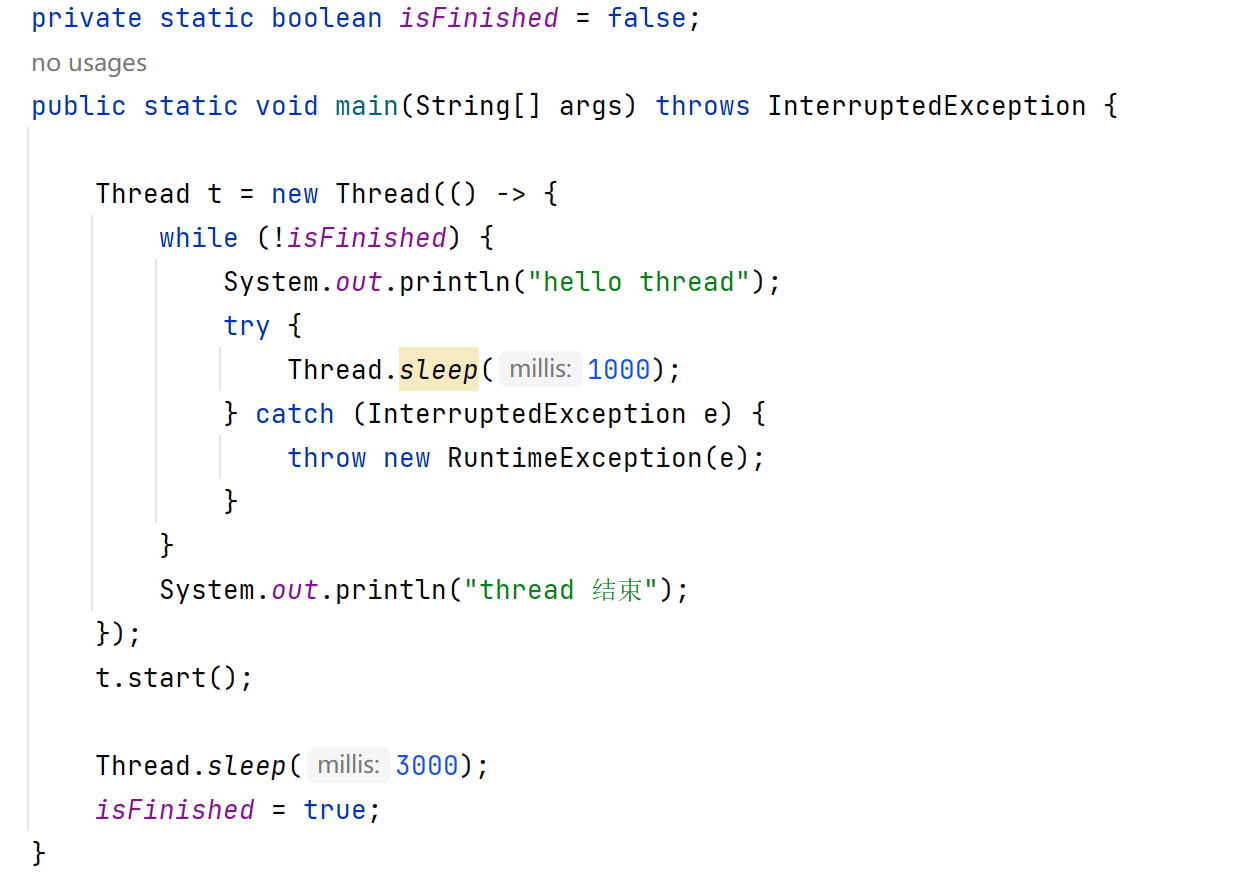

如果把 isFinished 定义成局部变量,是否可以? 不可以
在 lambda 表达式内,希望使用外面的变量,会触发 “变量捕获”
说明:
1. lambda是回调函数,操作系统真正创建出线程之后,才会执行。很有可能后续线程创建好了,当前 main 方法都执行完了,对应的isFinished 就销毁了
2. 为了解决这个问题,Java的做法是,把被捕获的变量给拷贝一份,拷贝到 lambda 内。外面的变量是否销毁,就不影响 lambda 里面的执行了
3. 拷贝,意味着这样的变量不适合进行修改,修改一方,另一方不会随之变化(本质上是两个变量)这种一个变,一个不变,可能给程序员带来困惑
4. 所以,Java的做法是,直接不允许对这个被捕获的变量进行修改
而 isFinished 作为 成员变量时,不是 “变量捕获” 语法,而是成 “内部类访问外部类的成员” 语法,
lambda 本质上是函数式接口,相当于一个内部类。isFinished 变量本身就是外部类的成员,内部类本来就能够访问外部类的成员
成员变量生命周期,是GC(garbage collection 垃圾回收)来管理的。在 lambda 内不用担心变量生命周期失效的问题,也就不必拷贝,不必限制 final 了

currentThread() 方法:
是Java Thread类的一个静态方法,它返回对当前正在执行的线程对象的引用。这个方法在多线程编程中,允许在运行的线程内部访问和控制该线程的状态和行为。

